NLP领域的首次Hard Label黑盒攻击! |
您所在的位置:网站首页 › 软标签是什么意思 › NLP领域的首次Hard Label黑盒攻击! |
NLP领域的首次Hard Label黑盒攻击!
|
文 | 阿毅编 | 小轶  背景 背景
前段时间已经和大家分享了两篇关于NLP Privacy的文章。今天,我们又来给大家推送优质论文了(公众号学习法)。其实,NLP与其他方向的跨界结合这段时间层出不穷,且都发表到了非常好的顶会上。目前有越来越多的 NLP 研究者开始探索文本对抗攻击这一方向,以 2020 年 ACL 为例,粗略统计有超过 10 篇相关论文。NLP Privacy可谓是NLP研究的下一个风口。 本次给大家介绍一篇文本对抗攻击和NLP结合的文章,目前该文章被AAAI’21接收,且代码已经开源(非常良心[19])! 
论文题目:Generating Natural Language Attacks in a Hard Label Black Box Setting (AAAI’21) 论文链接:https://arxiv.org/pdf/2012.14956.pdf Arxiv访问慢的小伙伴也可以在【夕小瑶的卖萌屋】订阅号后台回复关键词【0317】下载论文PDF~  论文概要 论文概要
首先,按照惯例,一句话总结论文:本文在NLP领域中的Hard Label黑盒环境下提出了一种使用遗传算法优化的基于决策的攻击策略。具体来说,该策略可以针对文本分类和包含任务生成高质量的对抗样本。本文提出的攻击策略利用基于种群的优化算法,仅通过观察目标模型预测的top标签来设计合理且语义相似的对抗样本。此外,在每次算法优化迭代中都允许进行单词替换,从而最大限度地提高原始文本和对抗文本之间的整体语义相似度。相比其他的攻击策略,本文的方法不依赖使用替代模型或任何种类的训练数据。我们重点关注上述加粗字体的字眼即可知本文的特色在于使用遗传算算法优化基于决策的攻击策略来解决hard label black box中攻击难以实施的问题。 最后本文全部的贡献总结如下: 作者提出了一种新颖的基于决策的攻击策略,并为文本分类任务生成了合理且语义相似的对抗样本。 作者设计的机制可以在不加标签的情况下成功生成对抗性样本而无需掌握任何训练数据知识或替代模型。 作者提出的攻击利用了基于种群的优化算法,该过程使原始文本和对抗文本之间的整体语义相似性最大化。 与以前的攻击策略相比,作者的攻击在较高的限制条件下也能实现更高的成功率和更低的干扰率。 Hard Label Black Box Settings [12]: 该设置一般在视觉领域中被研究[13],具体是指攻击者在不掌握模型的信息的情况下只能得到被攻击的机器学习系统提供的有限个输入查询相对应的预测结果。简言之,攻击者只能得到一些(数目很少)hard label的预测输出。本文还指出,这是首次在文本领域探究如何在该设置下设计对抗攻击策略。另外,遗传算法思想应用到对抗攻击当中最早要追溯到2018年,近几年的工作中有不少是关于此类方法的(具体可见[12]中的总结),究其原因是遗传算法非常适合来优化某个目标函数。本文的核心思想是使用种群优化算法优化文中的目标函数来设计的攻击策略。  问题定义 问题定义
简单来说,本文的目标的是要生成一段和真实语句 在语义上很接近的对抗语句 ,该对抗语句可以导致模型产生错误输出。从优化的角度来开看,我们需要 尽可能大的情况下,使得模型产生错误的输出。 详细的严谨定义如下所示: 注意, 是不连续的函数,因为模型仅输出硬标签。这也使得等式(2)中的目标函数不连续并且难以优化。  攻击策略 攻击策略
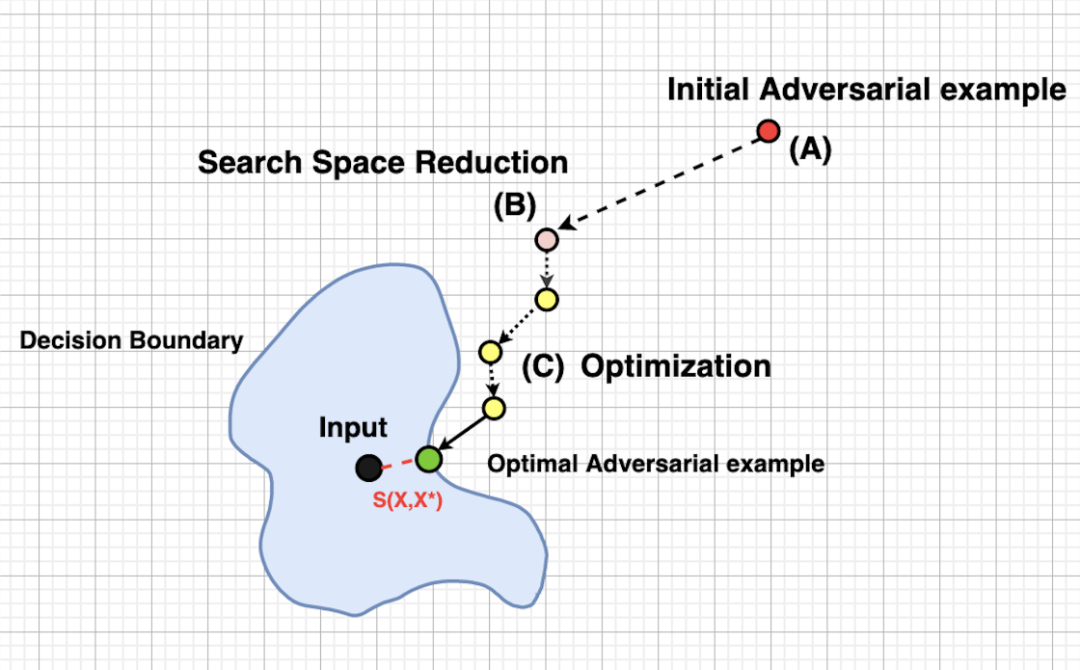
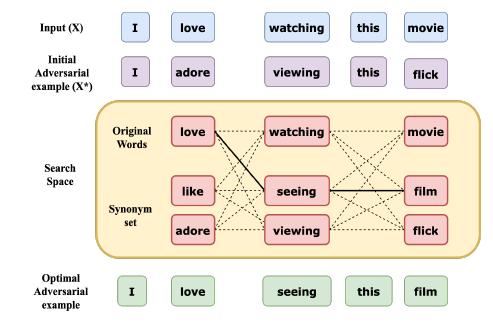
如图所示,本文设计了一个三步走的攻击策略:初始化、缩小搜索空间、种群优化。接下来我们详细介绍每个步骤设计的初衷和具体细节: 作者为了生成一个与原始输入 在语义上相似的对抗性示例 ,限制了每个单词在反向拟合嵌入空间中的前50个同义词的替换[14]。然后,作者过滤掉词性标签与原始单词不同的同义词,这样可以确保同义词符合上下文的语境并且句子在语法上是正确的,即原文中算法1中的3-7行。 缩小搜索空间因为作者使用X*替换很多的同义词,因此整体算法的搜索空间就会变得很大,这会增加优化算法的时间开销并会因为收敛很慢而导致很难寻到最优值。因此,在此步骤中,作者通过将一些同义词替换为各自的原始单词来减少 中的替换计数。以下步骤用于减少 中的替换计数: 给定初始化样本,其中 表示初始化期间 替换的同义词。每个同义词 被其原始的 代替(原文算法1,第8-10行)。 不符合对抗样本标准的文本将被过滤掉。从剩余的文本样本中,根据 和 之间的语义相似性对每个替换项(带有 的 )进行评分。所有替换项均基于该评分以降序排序(原文算法1,第11-13行)。
中的同义词将按照步骤2中确定的顺序用其原始对应语句替换回去,直到
满足对抗标准(原文算法1,第14-17行)。 对抗性样本 的搜索空间:虚线表示所有可能的组合。粗线显示所选的组合,该组合与X的语义相似度最高,并且满足对抗标准 。 这可以看作是将初始样本 移到目标模型的决策边界附近。此过程非常有效,因为它不仅可以加快优化算法的速度,而且还可以防止其收敛到局部最优。 种群优化算法作者使用种群优化算法来优化目标函数(2),其中最重要的两个步骤是:crossover(打篮球的小伙伴肯定异常兴奋啦)和mutation。该算法的一般步骤如下: 初始化:使用遗传算法从任意一组初始候选者开始寻优。 选择:使用fitness函数评估每个候选人。根据他们的fitness值选择两个候选人作为parents。 Crossover:选定的parents经过Crossover以产生下一组候选者。 Mutation:对新的候选者进行变异以确保多样性并更好地探索搜索空间。重复步骤2-4进行特定次数的迭代。 之所以使用使用遗传算法是因为它直接适用于离散的输入空间。此外,与其他基于整体的优化方法相比,遗传算法更直观,更易于应用。本文与其他相似方法[15]不同,作者是将两个文本序列之间的语义相似性最大化。接下来重点解析选择、crossover和mutation操作。 MutationMutation操作实际上就是为了挑选出高质量的对抗样本作为遗传算法的样本去进行变异(类似于细胞分裂),**那么问题来了:什么是高质量的对抗样本呢?**作者在文中给出了两个公式: 函数表示相似度判断函数,其作用是为了判断对抗样本和真实样本的语义相似度。在上述式子中 就是我们需要挑选进行变异的样本, 是全部对抗样本, 是正常样本,因此上述因子意味着所挑选的 不仅符合对抗样本的要求且相似度比初始化的对抗样本要大,因此我们只需要优化以下目标函数即可获得高质量的对抗样本 : 选择选择操作一开始是随机初始化的,但是随着上述Mutation操作的完成,选择就是一个技巧活了,如何选择两个候选者成为parents至关重要。作者把对抗样本与真实样本的语义相似度作为fitness函数,然后使用采样函数 来选择parents。具体来说, ,其中 是从上述Mutation操作中所挑选的candidate中按一定比例 采样得到的,因此这样可以得到相似度非常高的两个对抗样本作为parents: CrossoverCrossover操作,顾名思义,就是进行交叉重复操作。具体来说,给定 (即parents),然后从 中为候选单词的每个位置随机选择一个单词,以此交叉重复多次,以确保产生足够多的搜索空间中的各类组合。此操作的目的是将生成多种满足对抗样本标准的新候选文本序列。具体公式如下: 总结:该遗传算法最主要的目的就是在文本是离散的条件下依然可以通过迭代优化选择出所有对抗样本中语义相似度最高的那些高质量对抗样本,因此该算法可以找到与真实样本极其接近的所有对抗样本。  结论 结论
接下来,我们对文章进行优缺点总结。 优点: 首次在NLP领域中研究Hard Label 黑盒环境下的对抗攻击(话题很新,且该领域慢慢在火起来); 实验非常充分,baselines也很丰富(实验部分此次不在推文中介绍,感兴趣的同学可以自行去查看原文); 使用遗传算法优化的基于决策的黑盒攻击恰好克服了文本离散的数据特点,且可以生成语义相似度很高的对抗样本 缺点: 该对抗攻击的细粒度不够,更加探究更加细粒度的对抗攻击; 该对抗攻击非常依赖于Hard Label产生的输出的质量,不然也就无法寻优出高质量的对抗样本; 遗传算法的搜索效率仍然是一个挑战,因此如何高效地进行搜索可能是该类方法的一个瓶颈。 注意:本文部分内容参考了其他网站或者博客的总结,均在此表示感谢,并在引用处[16-18]引用,希望大家乐于分享知识,共同进步!
目前在澳洲读PhD,方向是Security and Privacy in Machine Learning,前腾讯天衍实验室实习生。一个热爱篮球但打球很菜的阳光小伙子,也很喜欢爬山。期待和对ML\FL\NLP安全和隐私问题感兴趣的小伙伴一起畅谈未来(微信号: Sea_AAo) 作品推荐 我拿模型当朋友,模型却想泄漏我的隐私?
加入卖萌屋NLP/IR/Rec与求职讨论群 后台回复关键词【顶会】 获取ACL、CIKM等各大顶会论文集!
|


 萌屋作者:阿毅
萌屋作者:阿毅 后台回复关键词【入群】
后台回复关键词【入群】

【本文地址】