论文笔记: Trajectory Clustering: A Partition |
您所在的位置:网站首页 › 轨迹最准确的运动手表软件 › 论文笔记: Trajectory Clustering: A Partition |
论文笔记: Trajectory Clustering: A Partition
|
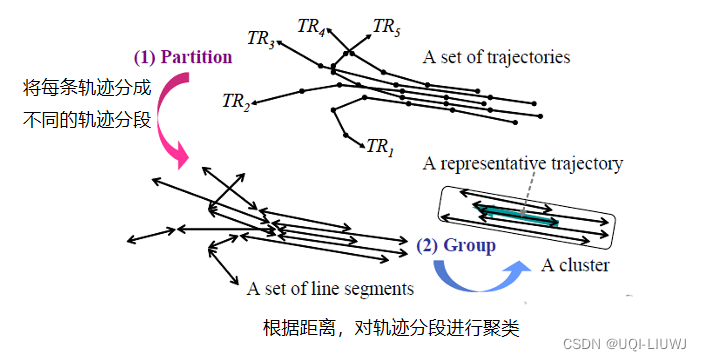
07 Sigmoid 使用类DBSCAN的思路对轨迹聚类 1 intro 1.1 轨迹聚类 现有的轨迹聚类算法是将相似的轨迹作为一个整体进行聚类,从而发现共同的轨迹。 但是这样容易错过一些共同的子轨迹(sub-trajectories)。而在实际中,当我们对特殊感兴趣的区域进行分析时,子轨迹就特别重要。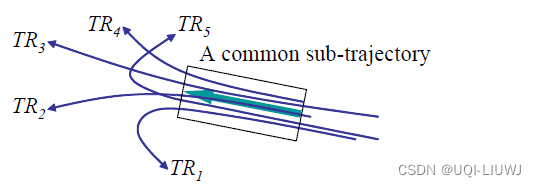 图中有五条轨迹,在矩形中有一个共同的行为,用粗箭头表示。如果我们将这些轨迹作为一个整体来聚类,我们就无法发现共同的行为,因为它们最终向完全不同的方向移动
——》作为一个整体来聚类会错过很多有价值的信息。
1.2 本文的思路
本文提出TRACLUS算法,先将轨迹分段成线段,然后再对线段进行聚类,可以更准确地发现子轨迹。算法步骤分为分段(partitioning)和归组(grouping)
分段利用最小描述长度(minimum description length MDL)原理实现轨迹分段,将每一条轨迹最优的分为一组线段,这些线段输入到下一阶段。归组利用基于密度的线段聚类算法实现相似线段聚类。设计了一个距离函数来定义线段的密度。
——>基于密度的聚类方法是最适合用于线段的,因为它们可以发现任意形状的聚类,并可以滤波出噪声。可以很容易地看到,线段簇通常是任意形状的,而轨迹数据库通常包含大量的噪声
图中有五条轨迹,在矩形中有一个共同的行为,用粗箭头表示。如果我们将这些轨迹作为一个整体来聚类,我们就无法发现共同的行为,因为它们最终向完全不同的方向移动
——》作为一个整体来聚类会错过很多有价值的信息。
1.2 本文的思路
本文提出TRACLUS算法,先将轨迹分段成线段,然后再对线段进行聚类,可以更准确地发现子轨迹。算法步骤分为分段(partitioning)和归组(grouping)
分段利用最小描述长度(minimum description length MDL)原理实现轨迹分段,将每一条轨迹最优的分为一组线段,这些线段输入到下一阶段。归组利用基于密度的线段聚类算法实现相似线段聚类。设计了一个距离函数来定义线段的密度。
——>基于密度的聚类方法是最适合用于线段的,因为它们可以发现任意形状的聚类,并可以滤波出噪声。可以很容易地看到,线段簇通常是任意形状的,而轨迹数据库通常包含大量的噪声
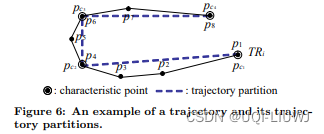 3.2.1 轨迹分段原则
一个轨迹的最优分段要具有两个属性:
准确性
轨迹与其一组轨迹分段之间的差异应该尽可能小
——>特征点不能太少。简洁性
轨迹分段的数量应该尽可能少这两个属性在确定特征点数目时是相互矛盾的,这就需要调整算法以达到平衡
3.2.2 最小描述长度原则(Minimum Description Length,MDL)
最小描述长度( MDL) 原理是通用编码领域研究的内容。
基本原理是对于一组给定的数据 D ,如果要对其进行保存 ,为了节省存储空间, 一般采用某种模型对其进行编码压缩,然后再保存压缩后的数据。同时, 为了以后正确恢复这些实例数据,将所用的模型也保存起来。——>所以需要保存的数据长度( 比特数) 等于 数据进行编码压缩后的长度 加上 保存模型所需的数据长度,将该数据长度称为总描述长度。最小描述长度( MDL) 原理就是要求选择总描述长度最小的模型MDL的代价有两部分L(H)和L(D|H)
H代表压缩模型,D代表数据L(H)是描述压缩模型(或编码方式)所需要的长度L(D∣H)是描述利用压缩模型所编码的数据所需要的长度类比到轨迹分段中,如下:
3.2.1 轨迹分段原则
一个轨迹的最优分段要具有两个属性:
准确性
轨迹与其一组轨迹分段之间的差异应该尽可能小
——>特征点不能太少。简洁性
轨迹分段的数量应该尽可能少这两个属性在确定特征点数目时是相互矛盾的,这就需要调整算法以达到平衡
3.2.2 最小描述长度原则(Minimum Description Length,MDL)
最小描述长度( MDL) 原理是通用编码领域研究的内容。
基本原理是对于一组给定的数据 D ,如果要对其进行保存 ,为了节省存储空间, 一般采用某种模型对其进行编码压缩,然后再保存压缩后的数据。同时, 为了以后正确恢复这些实例数据,将所用的模型也保存起来。——>所以需要保存的数据长度( 比特数) 等于 数据进行编码压缩后的长度 加上 保存模型所需的数据长度,将该数据长度称为总描述长度。最小描述长度( MDL) 原理就是要求选择总描述长度最小的模型MDL的代价有两部分L(H)和L(D|H)
H代表压缩模型,D代表数据L(H)是描述压缩模型(或编码方式)所需要的长度L(D∣H)是描述利用压缩模型所编码的数据所需要的长度类比到轨迹分段中,如下:
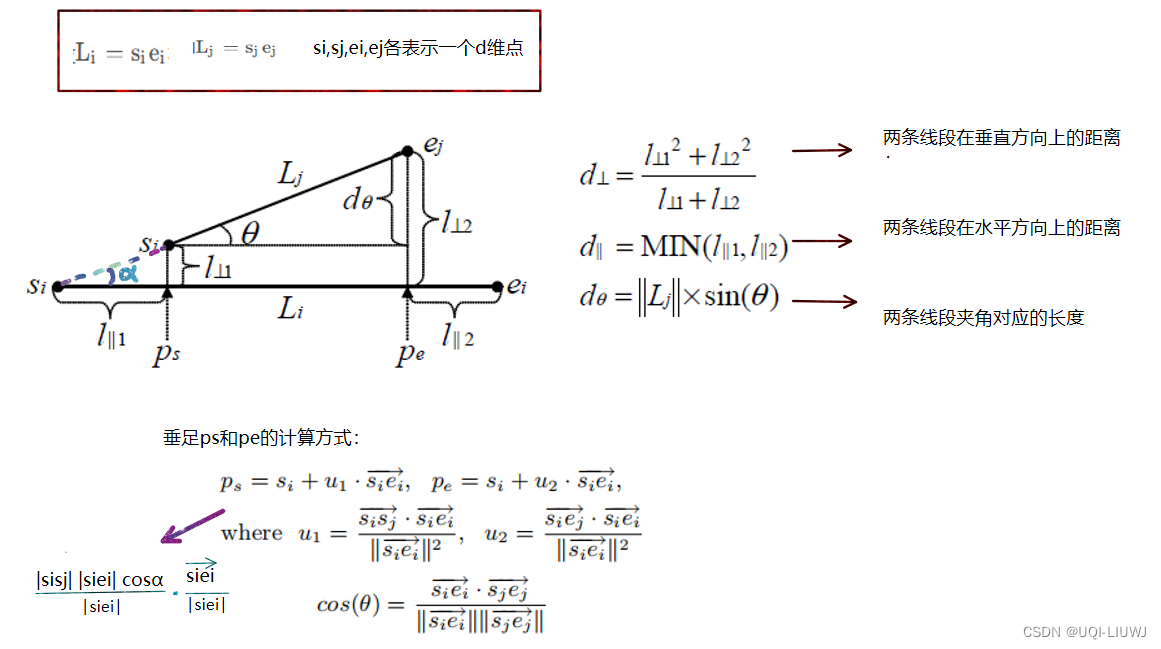
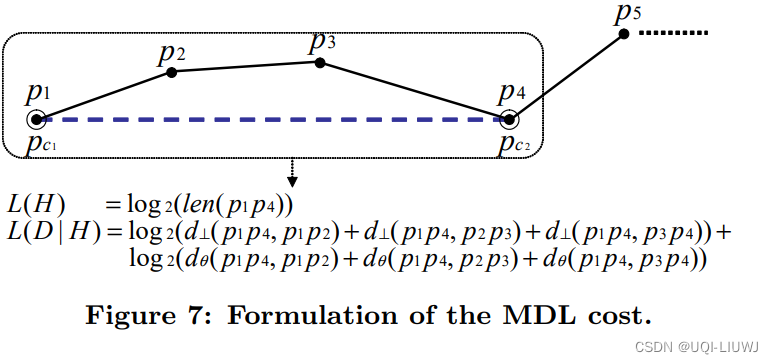 L(D|H)只考虑角度距离和垂直距离,不考虑平行距离 L(D|H)只考虑角度距离和垂直距离,不考虑平行距离 假设一条轨迹 L(H)表示为 L(D|H)表示为: ——>因此,要得到最优的分段策略,那就是要最小MDL= L(H)+L(D|H),这能够准确平衡简洁性和准确性 3.2.3 近似计算方法 但是因为要考虑到轨迹点的每一个子集,所以计算量是非常大 论文引入一个近似计算的方法,关键思想是将局部最优的集合视为全局最优记对比DBSCAN相应概念:
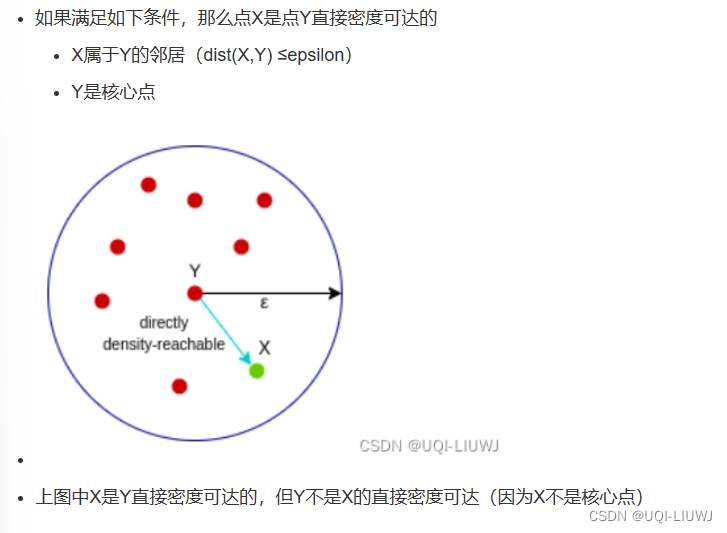
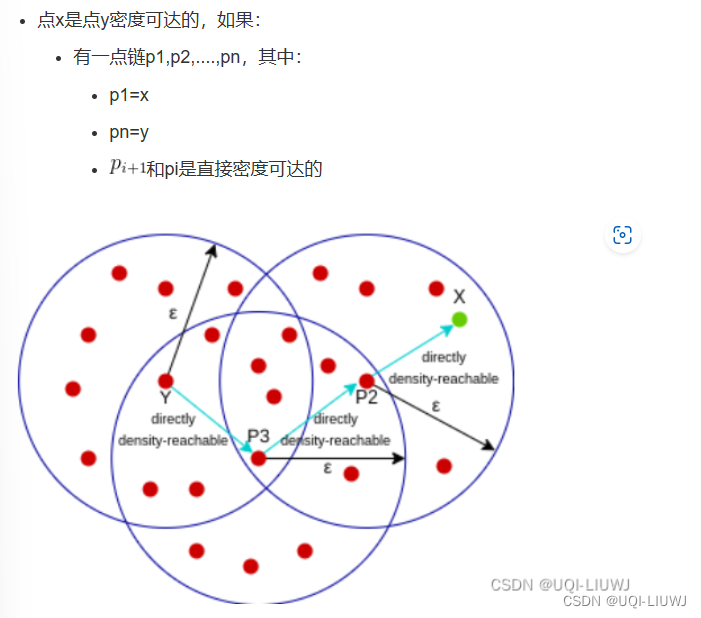
存在一组线段 其中Lk直接密度可达 那么Li密度可达Lj 对比DBSCAN相应概念:
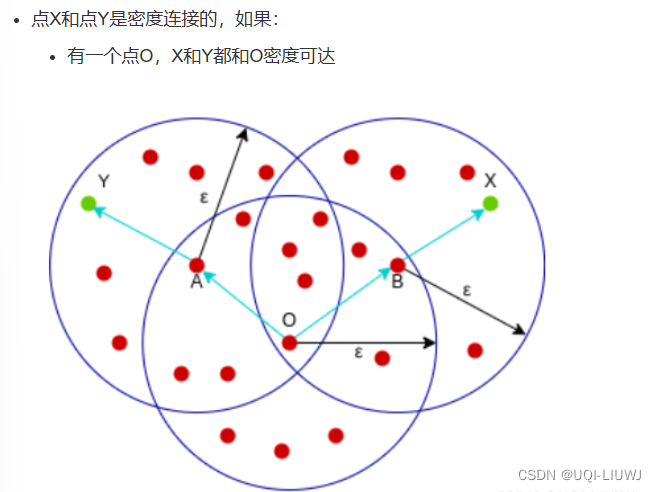
当存在一个核心点Lk,使得线段Li和线段Lj都密度可达Lk 那么Li 密度连接Lj 对比DBSCAN概念:
3.3.2 密度连接集
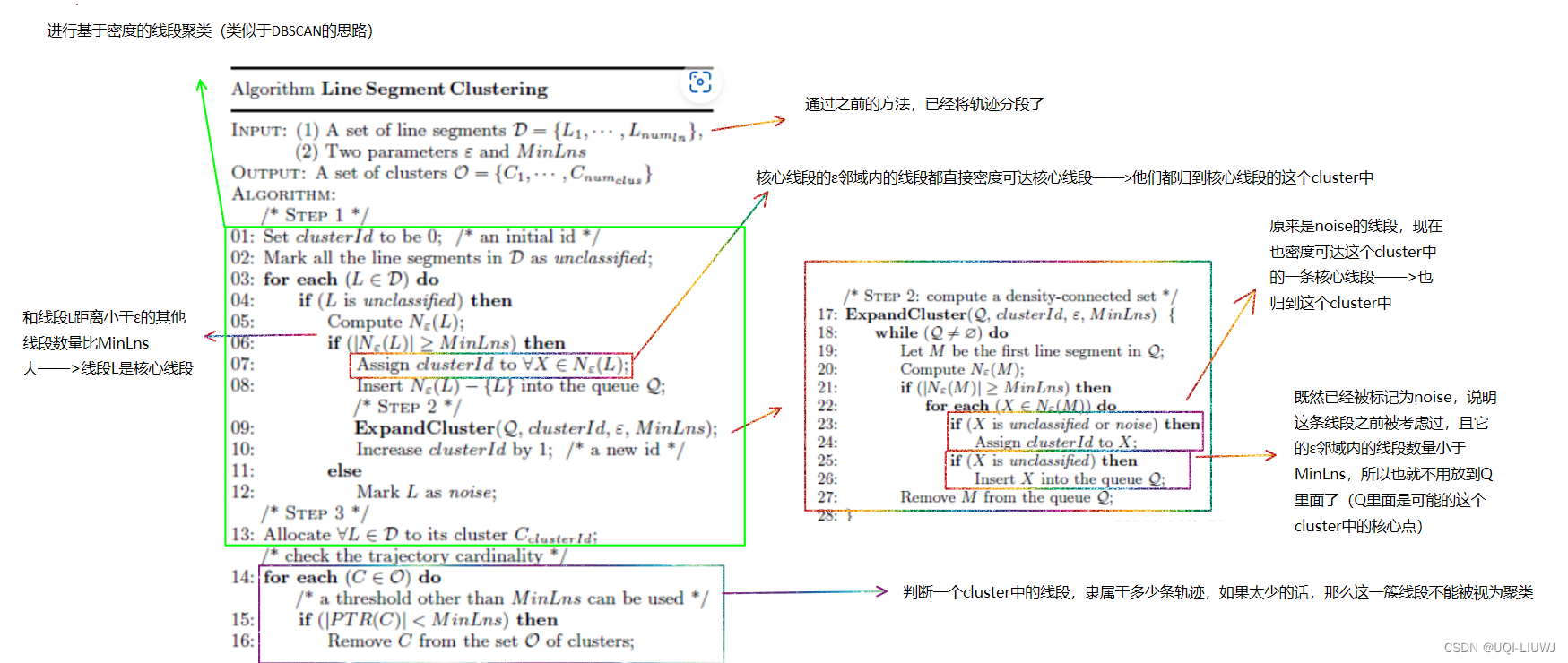 有别于DBSCAN的就是14~16行,即并非所有的密度连接集都是一个线段聚类
需要考虑这一簇的线段是从几条轨迹中得来的,如果小于阈值,那么这一簇线段不能被视为一个聚类
举一个极端情况,一个簇中所有的线段都是从一个轨迹中提取出来的——>14~16行就是校验一个簇中轨迹的基数
有别于DBSCAN的就是14~16行,即并非所有的密度连接集都是一个线段聚类
需要考虑这一簇的线段是从几条轨迹中得来的,如果小于阈值,那么这一簇线段不能被视为一个聚类
举一个极端情况,一个簇中所有的线段都是从一个轨迹中提取出来的——>14~16行就是校验一个簇中轨迹的基数
参考内容: GPS轨迹聚类算法TRACLUS介绍(一)_NieBP的博客-CSDN博客 GPS轨迹聚类算法TRACLUS介绍(二)_traclus-master_NieBP的博客-CSDN博客 GPS轨迹聚类算法TRACLUS介绍(三)_NieBP的博客-CSDN博客 GPS轨迹聚类算法TRACLUS介绍(四)_NieBP的博客-CSDN博客 |

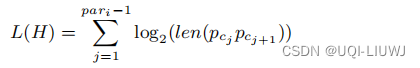
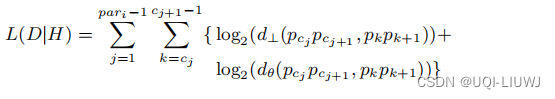
 ,mn
,mn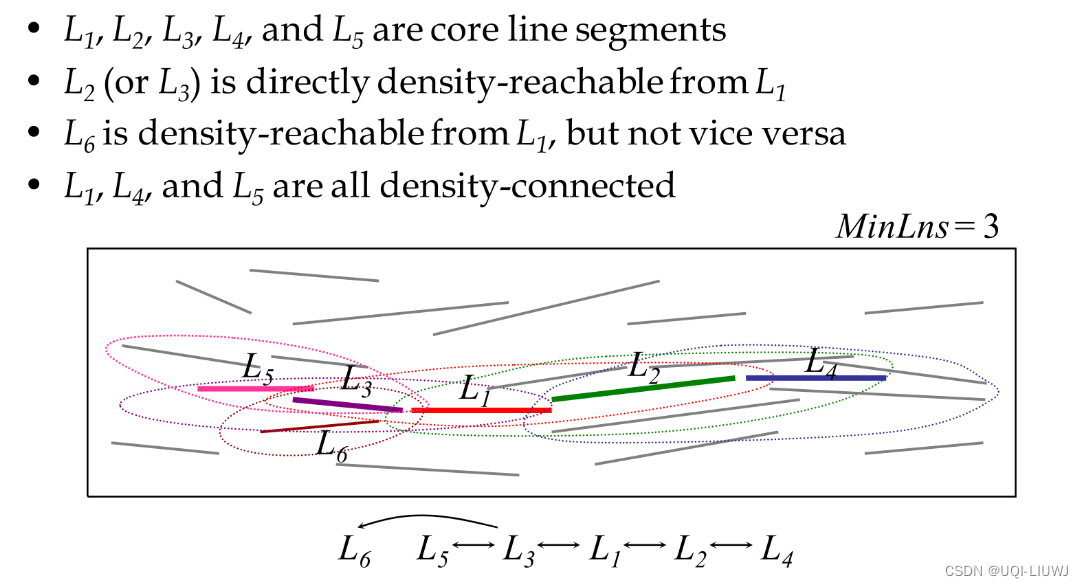

【本文地址】
今日新闻 |
推荐新闻 |