【教程】COCO 数据集:入门所需了解的一切 |
您所在的位置:网站首页 › 车辆结构图文解释 › 【教程】COCO 数据集:入门所需了解的一切 |
【教程】COCO 数据集:入门所需了解的一切
|
转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn] 本文为机器翻译,推荐直接看原文:COCO Dataset: All You Need to Know to Get Started 人工智能依赖于数据。 构建和部署人工智能和机器学习系统的过程需要大量且多样化的数据集。数据的可变性和质量在确定机器学习模型的能力和准确性方面发挥着至关重要的作用。 只有高质量的数据才能保证高效的性能。 获取高质量数据的最简单方法之一是使用预先存在的、完善的基准数据集。机器学习中常用的基准数据集(无论是用于研究还是实际应用)是 COCO 数据集。 在本文中,我们将深入探讨 COCO 数据集及其对计算机视觉任务的重要性。 我们将介绍以下内容: COCO数据集是什么?如何使用MS COCO?COCO 数据集格式 COCO数据集是什么?COCO(Common Objects in Context)数据集是一个大规模的 图像识别 用于对象检测、分割和字幕任务的数据集。 它包含超过 330,000 张图像,每个都注释有 80 个对象类别 和 5 个字幕 描述场景。 COCO 数据集广泛应用于计算机视觉研究,并已用于训练和评估许多最先进的对象检测和分割模型。 该数据集有两个主要部分:图像及其注释。 图像被组织成目录层次结构,顶级目录包含图像的子目录 训练集、验证集和测试集.注释以 JSON 格式提供,每个文件对应一个图像。数据集中的每个注释都包含以下信息: 图像文件名图像尺寸(宽度和高度)具有以下信息的对象列表: 对象类别(例如,“人”、“汽车”); 边界框坐标(x,y,宽度,高度); 分割掩模(多边形或RLE格式); 关键点及其位置(如果有)描述场景的五个标题COCO 数据集还提供附加信息,例如图像超级类别、许可证和 coco-stuff(除了 80 个对象类之外,还为东西类提供像素级注释)。MS COCO提供各种类型的注释, Object detection物体检测:具有 80 个不同对象的边界框坐标和完整分割掩模;Stuff image segmentation图像分割:像素图显示 91 个无定形背景区域;Panoptic segmentation全景分割:根据 80 个“事物”和 91 个“东西”类别识别图像中的项目;Dense pose:密集姿势 包含超过 39,000 张照片,包含超过 56,000 个标记人物,以及像素和模板 3D 模型之间的映射以及每张图像的自然语言描述;Keypoint关键点:为超过 250,000 人标注右眼、鼻子、左臀部等关键点;
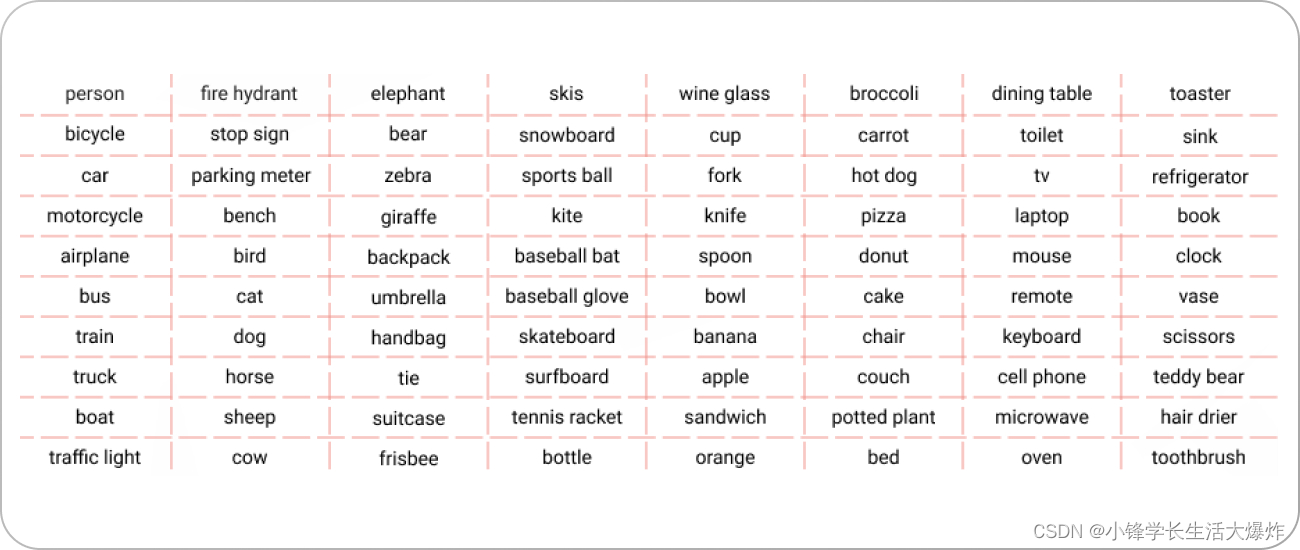
COCO(上下文中的通用对象)数据集类分为两个主要类别:"things" 和 "stuff"。 “Things”类包括容易拾取或处理的物体,例如动物、车辆和家居用品。 COCO 中“事物”类的示例是: Person人Bicycle自行车Car车Motorcycle摩托车“Stuff”类包括背景或环境项目,例如天空、水和道路。 COCO 中“stuff”类的示例是: Sky天空Tree树Road路下图展示了 COCO 提供的 80 个类的完整列表。
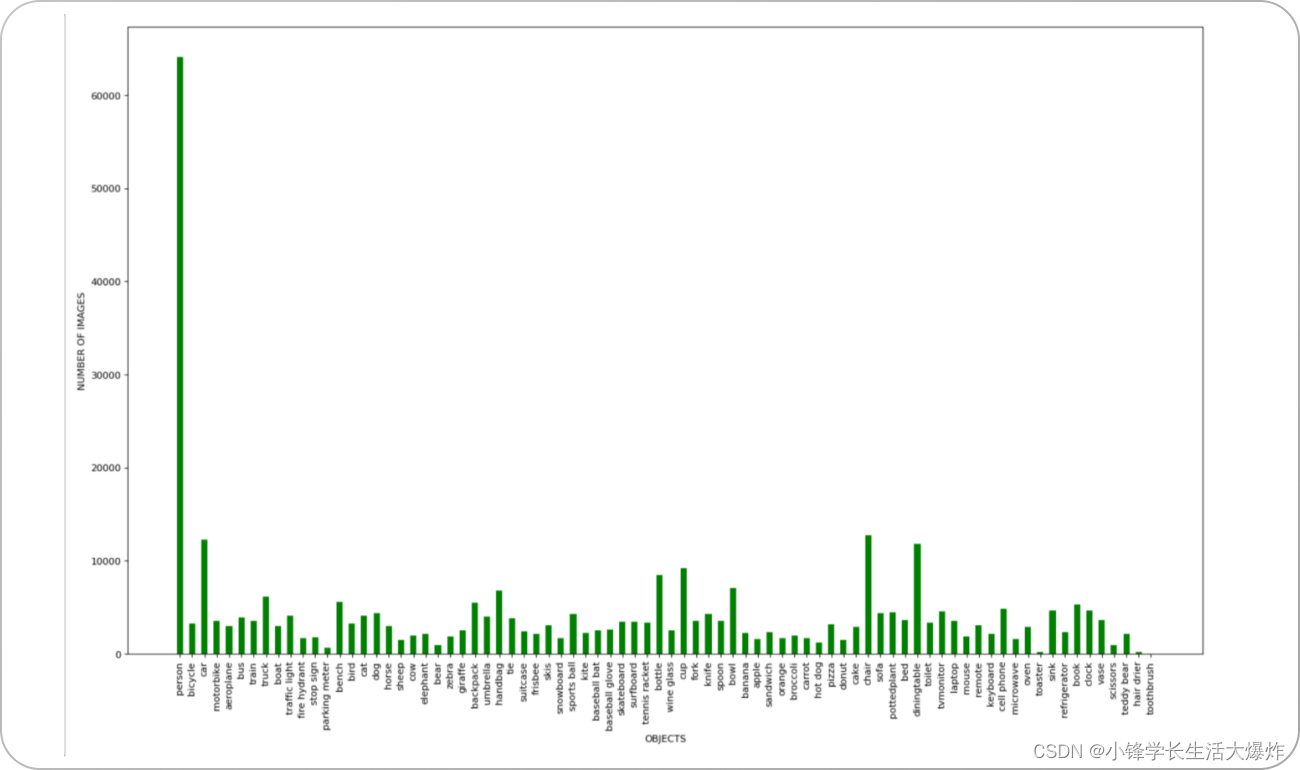
值得注意的是,COCO 数据集由于类别不平衡而存在固有偏差。当一类中的样本数量与其他类中的样本数量显着不同时,就会发生类不平衡。 在 COCO 数据集上下文中,某些对象的类比其他对象具有更多的图像实例。 类别不平衡可能会导致机器学习模型的训练和评估出现偏差。 这是因为模型接触到了更多频繁类别的示例,因此它学会了更好地识别它们。 因此,模型可能需要帮助来识别频率较低的类别并在其中表现不佳。 此外,数据集中的偏差可能会在多数类中导致 模型过拟合 ,这意味着它在这个类中表现良好,但在其他类中表现不佳。 可以使用多种技术来缓解类不平衡问题,例如过采样、欠采样和合成数据生成。
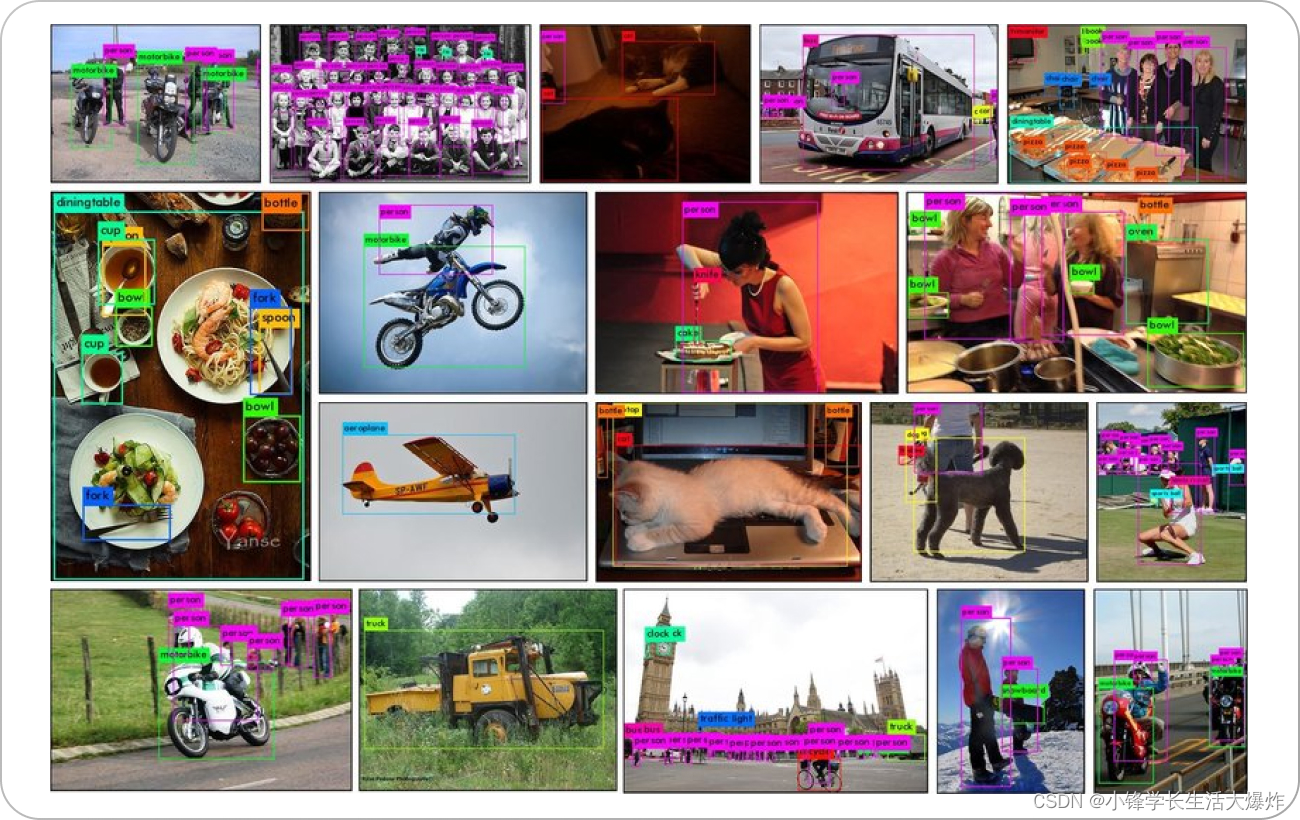
COCO 数据集作为 计算机视觉 训练、测试、微调和优化模型的基线,以实现注释管道的更快可扩展性。让我们看看如何利用 COCO 数据集来执行不同的计算机视觉任务。 Object detection物体检测物体检测 是最流行的计算机视觉应用程序。 它检测带有边界框的对象,以实现它们在图像中的分类和定位。 COCO 数据集可用于训练目标检测模型。 数据集为80 种不同类型物体的坐标提供 边界框 ,可用于训练模型来检测边界框并对图像中的物体进行分类。
实例分割 是计算机视觉中的一项任务,涉及识别和分割图像中的各个对象,同时为对象的每个实例分配唯一的标签。实例分割模型通常使用对象检测技术,例如边界框回归和非极大值抑制,首先识别图像中对象的位置。 然后,模型使用语义分割技术,例如 卷积神经网络 (CNN),对边界框中的对象进行分段,并为每个实例分配唯一的标签。 COCO 数据集包含实例分割注释,可用于训练此任务的模型。
语义分割是一项计算机视觉任务,涉及将图像中的每个像素分类为几个预定义的类别之一。 它与实例分割不同,实例分割侧重于将每个对象实例识别和分割为图像中的单独实体。为了训练语义分割模型,我们需要一个数据集,其中包含图像以及图像中每个类别的相应像素级注释。 这些注释通常以掩码的形式提供,其中每个像素都分配有一个标签,指示其所属的类。 例如,如果我们有一张城市图像,语义分割将涉及将图像中的每个像素分类为属于几个类别之一,例如道路、建筑物、树木、天空等。 COCO 非常适合语义分割,因为它包含许多图像,并且图像中每个类别都有相应的像素级注释。一旦数据集可用,就可以训练深度学习模型,例如全卷积网络 (FCN)、U-Net 或 Mask-RCNN。 这些模型旨在将图像作为输入并生成分割掩模作为输出。 训练后,模型可以分割新图像并提供准确详细的注释。
关键点检测,也称为关键点估计,是一项计算机视觉任务,涉及识别图像中的特定兴趣点,例如物体的角点或人身体的关节。 这些关键点通常用于表示图像中的对象或人。 它们可用于各种应用,例如对象跟踪、运动分析和人机交互。 COCO 数据集包含超过 200,000 张图像中超过 250,000 人的关键点注释。 这些注释提供了身体上 17 个关键点的 x 和 y 坐标,例如右肘、左膝和右脚踝。 研究人员和从业者可以在 COCO 数据集上训练深度学习模型,例如多人姿势估计 (MPPE) 或 OpenPose。 这些模型旨在将图像作为输入并生成一组关键点作为输出。
全景分割 是一项计算机视觉任务,涉及识别和分割图像中的所有对象和背景,包括“事物”(不同的对象)和“东西”(图像的非晶区域,例如天空、水和道路)。 它结合了实例分割和语义分割,其中实例分割用于分割对象,语义分割用于分割背景。 在 COCO 数据集的上下文中,全景分割注释提供完整的场景分割,根据 80 个“事物”和 91 个“东西”类别识别图像中的项目。 COCO 数据集还包括全景分割的评估指标,例如 PQ(全景质量)和 SQ(东西质量),用于衡量在数据集上训练的模型的性能。 为了使用全景分割模型,我们输入图像。 该模型生成全景分割图,该图像的分辨率与输入图像完全相同。 尽管如此,每个像素仍被分配一个标签,指示它属于“事物”还是“东西”类别,以及“事物”像素的实例 ID。
密集姿势是一项计算机视觉任务,用于估计图像中物体或人的 3D 姿势。 这是一项具有挑战性的任务,因为它不仅需要检测物体,还需要估计物体每个部分的位置和方向,例如头部、手臂、腿部等。 在 COCO 数据集的上下文中,密集姿势是指数据集中提供的注释,将人物图像中的像素映射到人体的 3D 模型。 这些注释为数据集中超过 39,000 张照片提供,并包含超过 56,000 个标记的人物。 每个人都会获得一个实例 ID、指示该人身体的像素之间的映射以及模板 3D 模型。 为了使用 COCO 数据集中的密集姿势信息,研究人员可以在该数据集上训练深度学习模型,例如 DensePose-RCNN。 密集姿态估计包括图像中人体每个部分的 3D 位置和方向。
语义类可以分为事物(具有明确定义形状的项目,例如人或汽车)或东西(无定形背景区域,例如草、天空)。 “Stuff”对象的类别很重要,因为它们有助于解释图像的重要部分,包括场景类型、特定对象存在的可能性以及它们可能位于的位置(基于上下文、物理特征、材料和场景的几何属性)。
COCO 数据集使用 JSON 格式,提供有关每个数据集及其所有图像的信息。 以下是 COCO 数据集结构的示例:
COCO数据集包括两种主要格式:JSON和图像文件。 JSON 格式包含以下属性: Info: 信息,有关数据集的一般信息,例如版本号、创建日期和贡献者信息Licenses: 许可证,有关数据集中图像的许可信息Images: 图片,数据集中所有图像的列表,包括文件路径、宽度、高度和其他元数据Annotations: 注释,每个图像的所有对象注释的列表,包括对象类别、边界框坐标和分割掩模(如果可用)Categories: 类别,所有数据集对象类别的列表,包括每个类别的名称和IDJSON 中的每个字段代表: info: 信息,有关数据集的元数据,例如版本、创建日期和贡献者信息licenses: 许可证,与数据集中的图像关联的许可证images: 图片,包含文件路径、高度、宽度和其他元数据等详细信息annotations: 注释,包含对象类别、边界框坐标和分割掩模categories: 类别,包含数据集中所有对象类别的名称和ID图像文件是与 JSON 文件中的图像对应的实际图像文件。 这些文件通常以 JPEG 或 PNG 格式提供,用于显示数据集中的图像。 让我们详细了解一下图像属性。 licenses许可证许可证部分提供有关数据集中包含的图像许可证的详细信息,以便您可以了解如何在工作中使用它们。 以下是许可证信息的示例。 "licenses": [ { "url": "https://creativecommons.org/licenses/by-nc-sa/4.0/", "id": 1, "name": "Attribution-NonCommercial-ShareAlike 4.0 International" }, { "url": "https://creativecommons.org/licenses/by-nc/4.0/", "id": 2, "name": "Attribution-NonCommercial 4.0 International" } ]在此示例中,“许可证”字段是包含多个许可证对象的数组。 每个许可证对象都具有三个字段:“url”、“id”和“name”。 “url”字段包含许可证的URL,“id”字段是许可证的唯一标识符,“name”字段包含许可证的名称。 categories类别COCO JSON 中的“categories”字段是定义数据集中对象的不同类别或类别的对象列表。 列表中的每个对象包含以下字段: "id": 类别的唯一整数标识符"name": 类别名称"supercategory":可选字段,指定比当前类别更广泛的类别例如,在包含不同类型车辆的图像的 COCO 数据集中,“类别”字段可能如下所示: "categories": [ { "id": 1, "name": "car", "supercategory": "vehicle" }, { "id": 2, "name": "truck", "supercategory": "vehicle" } ] images图片“images”字段是一个数组,其中包含有关数据集中每个图像的信息。 数组中的每个元素都是一个字典,包含以下键值对: "id": 整数,唯一的图像ID"width": 整数,图像的宽度"height": 整数,图像的高度"file_name": 字符串,图像的文件名"license": 整数,图片的许可id"flickr_url": 字符串,Flickr 上图像的 URL(如果有)"coco_url": 字符串,COCO网站上图像的URL(如果有)以下是 COCO JSON 文件中“images”字段的示例: "images": [ { "id": 1, "width": 640, "height": 480, "file_name": "000000397133.jpg", "license": 1, "flickr_url": "https://www.flickr.com/photos/adrianrosebrock/397133", "coco_url": "http://images.cocodataset.org/val2017/000000397133.jpg", "date_captured": "2013-11-14 17:02:52" }, { "id": 2, "width": 427, "height": 240, "file_name": "000000037777.jpg", "license": 1, "flickr_url": "https://www.flickr.com/photos/adrianrosebrock/37777", "coco_url": "http://images.cocodataset.org/val2017/000000037777.jpg", "date_captured": "2013-11-14 17:02:52" }, ... ], annotations注释COCO JSON 文件中的注释字段是注释对象的列表,提供有关图像中对象的详细信息。 每个注释对象都包含对象的类标签、边界框坐标和分割掩码等信息。 "annotations": [ { "id": 1, "image_id": 1, "category_id": 1, "segmentation": [ [ [ 56.97, 56.97 ], [ 56.97, 56.97 ], ... ] ], "area": 2351.45, "bbox": [ 56.97, 56.97, 56.97, 56.97 ], "iscrowd": 0 } ... ] bbox 边界框“bbox”字段是指图像中对象的边界框坐标。 边界框由四个值表示:左上角的 x 和 y 坐标以及框的宽度和高度。 这些值都是标准化的,将它们表示为图像宽度和高度的分数。 以下是 COCO JSON 文件中“bbox”字段的示例: { "annotations": [ { "id": 1, "image_id": 1, "category_id": 1, "bbox": [0.1, 0.2, 0.3, 0.4], "area": 0.12, "iscrowd": 0 }, { "id": 2, "image_id": 1, "category_id": 2, "bbox": [0.5, 0.6, 0.7, 0.8], "area": 0.42, "iscrowd": 0 } ] }在此示例中,第一个注释具有一个边界框,其左上角位于 (0.1, 0.2),宽度和高度分别为 0.3 和 0.4。 第二个注释有一个边界框,其左上角位于 (0.5, 0.6),宽度和高度分别为 0.7 和 0.8。 segmentation分割COCO JSON 中的分段字段是指图像的对象实例分段掩码。 分割字段是一个字典数组,每个字典代表图像中的单个对象实例。 每个字典都包含一个“分段”键,即表示该对象实例的逐像素分段掩码的数组数组。 JSON 中的分段字段示例: "annotations": [ { "segmentation": [ [ [x1, y1], [x2, y2], [x3, y3], ... ] ], "area": 1000, "iscrowd": 0, "image_id": 1, "bbox": [x, y, width, height], "category_id": 1, "id": 1 }, { "segmentation": [ [ [x1, y1], [x2, y2], [x3, y3], ... ] ], "area": 800, "iscrowd": 0, "image_id": 1, "bbox": [x, y, width, height], "category_id": 2, "id": 2 } ],在此示例中,图像中的两个对象实例由“annotations”数组中的字典表示。 每个字典中的“分段”键是一个数组数组,其中每个数组表示一组 x 和 y 坐标,这些坐标构成该对象实例的像素级分段掩码。 字典中的其他键提供有关对象实例的附加信息,例如其边界框、区域和类别。 Key takeaways要点COCO 数据集旨在通过将对象识别纳入更大的理解场景概念中来突破对象识别的界限。 COCO 是一个庞大的数据集,包括对象检测、分割和字幕。 它具有以下特点: 对象分割上下文中的识别分割物体的较小部分超过 330,000 张图像(> 200,000 张带标签)150 万个对象实例80 种不同的对象类别由于 COCO 数据集包含来自各种背景和设置的图像,训练后的模型可以更好地识别不同上下文中的图像。 |








【本文地址】
今日新闻 |
推荐新闻 |