【机器学习】决策树python实现 – python看看 |
您所在的位置:网站首页 › 趣味识字的教案 › 【机器学习】决策树python实现 – python看看 |
【机器学习】决策树python实现 – python看看
|
决策树理解:
所谓决策树,就是根据树结构来进行决策。 举个例子,小明的妈妈去上海人民公园相亲角为儿子物色相亲对象,广场上数百名适婚年龄男女的家长自发来到这里,手里拿着自家孩子的基本资料。小明妈为了选到一个理想的儿媳妇,在看到其他人手中的基本资料后,根据自己内心中各项情况的重要程度(从高到低分别是性别,学历,颜值,房子),依次进行判断: 性别是否是女孩子? 如果不是,就pass; 如果是,那学历是否是本科以上? 如果不是,那是否颜值过关且家中有房? 如果不是,则pass; 如果是,则是理想相亲对象; 如果是,那颜值是否过关? 如果不是,那家中是否有房? 如果不是,则pass; 如果是,则是理想相亲对象; 如果是,则是理想相亲对象; 就这样看过基本资料满意后,小明妈才会和对方家长交换资料… 由此我们可以得到一颗较为简单的决策树,对于每一个候选人,其标签是”Yes”和”No”,分别代表小明妈是否满意;属性有四个,“性别”“学历”“颜值”“房子”,即:
我们可以看出,实现这棵树的关键是小明妈心中的“重要程度”,有了这个我们才得以根据重要性依次筛选。而在生成一颗决策树时,我们从根结点出发,需要在所有属性中选择一个最重要的属性,之后来到下一个结点,我们要在剩余的所有属性中选择一个最重要的,以此类推。 也就是说,在每个结点就是要找到当前最重要的一个属性来进行划分,并且希望以此划分完的若干个分枝的样本尽量属于同一个类标签,称这种特性叫做结点的纯度. 最优划分属性:那么如何来判断每个属性的重要程度,或者说纯度呢? 采用不同的指标就会生成不同的算法,此处列举三个: 1.信息增益:人们提出了“信息熵”来度量样本集合的纯度。假设样本集合D 中,共有k类样本,第i种样本所占比例为pi则信息熵Ent为:
负号用来保证求和前每一项都是非负数,信息熵越小,纯度越高。 对于上述数据集D,其中的某一个属性α,假设有M个取值,则按该属性进行划分后,将形成M个结点,我们可以计算M个新结点的信息熵 Ent (Dm) ,并根据子结点样本数的比重进行加权求和,与D的信息熵进行比较,来确定使用属性α划分数据集D的信息增益:
属性的信息增益越大就意味着以用该属性进行划分所带来的纯度增加越大,在每个结点选择信息增益最大的属性进行划分而形成的算法是ID3算法. 2.增益率:增益率定义为: 其中
称为属性α的“固有值”.不难发现,属性 α取值数目越多(即M越大),则作为IV(α) 的值通常会越大. 因此,当有些属性取值过多时,可能会导致ID3算法误选取值较多的属性,此时使用增益率作为指标是一个很好的选择,这叫做C4.5决策树. 3.基尼指数基尼系数定义如下:
直观来说,基尼系数反映了从数据集 D 中随机抽取两个样本, 其类别标记一致的概率. 因此, Gini(D) 越小, 则数据集 D 的纯度越高.属性 α的基尼指数定义为:
以基尼指数作为划分依据的决策树算法称为CART决策树. 算法流程1.将数据集划分为训练集D与测试集T,得到属性集A; 2.判断D中样本是否 均为同一类别 或 所有属性取值相同: 如果是,则将根结点直接标记为叶结点,类别标记为D DD中样本数最多的类,程序结束; 如果不是,则继续生成树; 3.选择信息增益或其他最优划分属性指标,对于A中所有属性计算指标值,选择最优的一个作 为划分属性α∗ ; 4.对于属性α ∗ 的每一个取值α i∗ ,生成一个分支,样本子集为D i∗ 如果要进行预剪枝,则: 先暂时将各个分枝结点标记为样本子集D i∗ 中最多的类标签,如果为空,则以D中最多的类标签代替. 再根据对于分枝前后在测试集的准确率判断是否要剪枝: 如果分枝后准确率提高,则继续进行; 否则进行剪枝,保留暂时的标记标签; 5.判断D i∗ 是否为空: 如果为空,则类别标记为D中最多的类标签,程序结束; 否则以D i∗ 为新的训练集,A except α ∗ 为新的属性集回到步骤1 6.最终得到决策树. [若进行后剪枝,则: 从最后一层的结点依次根据对于分枝前后在测试集的准确率判断是否要剪枝: 如果分枝后准确率提高,则保留该分枝; 否则进行剪枝,用叶结点代替子树] 代码实现:基于西瓜数据集(共100条数据):
D_keys = { '色泽': ['青绿', '乌黑', '浅白'], '根蒂': ['蜷缩', '硬挺', '稍蜷'], '敲声': ['清脆', '沉闷', '浊响'], '纹理': ['稍糊', '模糊', '清晰'], '脐部': ['凹陷', '稍凹', '平坦'], '触感': ['软粘', '硬滑'],}keys = ['是', '否'] 根据留出法将数据集分为相斥的测试集与训练集,比例为3:7,为了保证均匀取出好瓜和坏瓜,采用分层抽样,即分别在好瓜和坏瓜的集合中随机取样。 #划分训练集&测试集,留出法,比例为7:3,分层抽样def traintest(dataSet): dataSet0 = dataSet[dataSet['好瓜'] == '是'] dataSet1 = dataSet[dataSet['好瓜'] == '否'] list0 = dataSet0.sample(frac=0.7) list0 = list0.append(dataSet1.sample(frac=0.7)) rowlist = [] for indexs in list0.index: rowlist.append(indexs) list1 = dataSet.drop(rowlist, axis=0) return list0,list1编写在生成树时会用到的子函数: 1:用信息增益划分: # 计算按key划分的信息增益值def calc_Gain_D(D, D_no_nan, key, Ent_D): Ent = 0.0 D_size = D['power'].sum() D_nan_size = D_no_nan['power'].sum() for value in D_keys[key]: Dv = D.loc[D[key] == value] Dv_size = Dv['power'].sum() Ent_Dv = calc_Ent(Dv) Ent += Dv_size / D_nan_size * Ent_Dv return D_nan_size / D_size * (Ent_D - Ent) def GainEnt_max(X, y, d): ''' 计算选择属性attr的最大信息增益,X为样本集,y为key,d为一个维度,type为int ''' ent_X = entropy(y) X_attr = X[:, d] X_attr = list(set(X_attr)) X_attr = sorted(X_attr) Gain = 0 thre = 0 for i in range(len(X_attr) - 1): thre_temp = (X_attr[i] + X_attr[i + 1]) / 2 y_small_index = [i_arg for i_arg in range( len(X[:, d])) if X[i_arg, d] thre_temp] y_small = y[y_small_index] y_big = y[y_big_index] Gain_temp = ent_X - (len(y_small) / len(y)) * \ entropy(y_small) - (len(y_big) / len(y)) * entropy(y_big) ''' intrinsic_value = -(len(y_small) / len(y)) * math.log(len(y_small) / len(y), 2) - (len(y_big) / len(y)) * math.log(len(y_big) / len(y), 2) Gain_temp = Gain_temp / intrinsic_value ''' # print(Gain_temp) if Gain < Gain_temp: Gain = Gain_temp thre = thre_temp return Gain, thre
2:用增益率作为划分: # 计算按key2划分的信息增益值与熵的比值def calc_Gain_D(D, D_no_nan, key, Ent_D): Ent = 0.0 D_size = D['power'].sum() D_nan_size = D_no_nan['power'].sum() for value in D_keys[key2]: Dv = D.loc[D[key] == value] Dv_size = Dv['power'].sum() Ent_Dv = calc_Ent(Dv) Ent += Dv_size / D_nan_size * Ent_Dv return D_nan_size / D_size * (Ent_D - Ent)/Ent3:使用基尼指数作为划分: def Gini(y): ''' 计算基尼指数,y为labels ''' category = list(set(y)) gini = 1 for label in category: p = len([label_ for label_ in y if label_ == label]) / len(y) gini += -p * p return gini def Gini_index_min(X, y, d): ''' 计算选择属性attr的最小基尼指数,X为样本集,y为label,d为一个维度,type为int ''' X = X.reshape(-1, len(X.T)) X_attr = X[:, d] X_attr = list(set(X_attr)) X_attr = sorted(X_attr) Gini_index = 1 thre = 0 for i in range(len(X_attr) - 1): thre_temp = (X_attr[i] + X_attr[i + 1]) / 2 y_small_index = [i_arg for i_arg in range( len(X[:, d])) if X[i_arg, d] thre_temp] y_small = y[y_small_index] y_big = y[y_big_index] Gini_index_temp = (len(y_small) / len(y)) * \ Gini(y_small) + (len(y_big) / len(y)) * Gini(y_big) if Gini_index > Gini_index_temp: Gini_index = Gini_index_temp thre = thre_temp return Gini_index, thre
# 叶节点选择其类别为D中样本最多的类def choose_largest_example(D): count = D['好瓜'].value_counts() return '是' if count['是'] > count['否'] else '否' # 测试决策树的准确率def test_Tree(Tree, data_test): accuracy = 0 for index, row in data_test.iterrows(): result = dfs_Tree(Tree, row) if result == row['好瓜']: # print(row.values, Tree) accuracy += 1 return accuracy / data_test.shape[0] # 判断D中的样本在A上的取值是否相同def same_value(D, A): for key in A: if key in D_keys and len(D[key].value_counts()) > 1: return False return True # 计算给定数据集的熵def calc_Ent(dataSet): numEntries = dataSet['power'].sum() Count = dataSet.groupby('好瓜')['power'].sum() Ent = 0.0 for key in keys: # print(Count[key]) if key not in Count: Ent -= 0.0 else: prob = Count[key] / numEntries Ent -= prob * math.log(prob, 2) return Ent # 生成连续值属性的候选划分点集合Tdef candidate_T(D, key, n): L = set(D[key]) T = [] a, Sum = 0, 0 for value in L: Sum += value a += 1 if a == n: T.append(Sum / n) a, Sum = 0, 0 if a > 0: T.append(Sum / a) return T # 计算样本D基于划分点t二分后的连续值属性信息增益def calc_Gain_t(D, D_no_nan, key, t, Ent_D): Ent = 0.0 D_size = D['power'].sum() D_nan_size = D_no_nan['power'].sum() Dv = D.loc[D[key] t] Dv_size = Dv['power'].sum() Ent_Dv = calc_Ent(Dv) Ent += Dv_size / D_nan_size * Ent_Dv return D_nan_size / D_size * (Ent_D - Ent) # 计算样本D基于不同划分点t二分后的连续值属性信息增益,找出最大增益划分点def calc_Gain_C(D, D_no_nan, key, Ent_D): n = 2 T = candidate_T(D, key, n) max_Gain, max_partition = -1, -1 for t in T: Gain = calc_Gain_t(D, D_no_nan, key, t, Ent_D) if max_Gain < Gain: max_Gain = Gain max_partition = t return max_Gain, max_partition # 从A中选择最优的划分属性值,若为连续值,返回划分点def choose_best_attribute(D, A): max_Gain, max_partition, partition, best_attr = -1, -1, -1, '' for key in A: # 划分属性为离散属性时 if key in D_keys: D_no_nan = D.loc[pd.notna(D[key])] Ent_D = calc_Ent(D_no_nan) Gain = calc_Gain_D(D, D_no_nan, key, Ent_D) # 划分属性为连续属性时 else: D_no_nan = D.loc[pd.notna(D[key])] Ent_D = calc_Ent(D_no_nan) Gain, partition = calc_Gain_C(D, D_no_nan, key, Ent_D) if max_Gain < Gain: best_attr = key max_Gain = Gain max_partition = partition return best_attr, max_partition
生成树: # 函数TreeGenerate 递归生成决策树,以下情形导致递归返回# 1. 当前结点包含的样本全属于一个类别# 2. 当前属性值为空, 或是所有样本在所有属性值上取值相同,无法划分# 3. 当前结点包含的样本集合为空,不可划分def TreeGenerate(D, A): Count = D['好瓜'].value_counts() if len(Count) == 1: return D['好瓜'].values[0] if len(A) == 0 or same_value(D, A): return choose_largest_example(D) node = {} best_attr, partition = choose_best_attribute(D, A) D_size = D.shape[0] # 最优划分属性为离散属性时 if best_attr in D_keys: for value in D_keys[best_attr]: Dv = D.loc[D[best_attr] == value].copy() Dv_size = Dv.shape[0] Dv.loc[pd.isna(Dv[best_attr]), 'power'] = Dv_size / D_size temp1 = test_Tree(choose_largest_example(D),data_test) if Dv.shape[0] == 0: node[value] = choose_largest_example(D) else: new_A = [key for key in A if key != best_attr] node[value] = TreeGenerate(Dv, new_A) temp0 = test_Tree(node[value],data_test) if temp1 > temp0: node[value] = choose_largest_example(D) # 最优划分属性为连续属性时 else: # print(best_attr, partition) # print(D.values) left = D.loc[D[best_attr] partition].copy() Dv_size = right.shape[0] right.loc[pd.isna(right[best_attr]), 'power'] = Dv_size / D_size right_key = '> ' + str(partition) temp1 = test_Tree(choose_largest_example(D), data_test) if right.shape[0] == 0: node[right_key] = choose_largest_example(D) else: node[right_key] = TreeGenerate(right, A) temp0 = test_Tree(node[right_key], data_test) if temp1 > temp0: node[right_key] = choose_largest_example(D) # plotTree.plotTree(Tree) return {best_attr: node} # 获得下一层子树分支def get_next_Tree(Tree, key, value): if key not in D_keys: partition = float(list(Tree[key].keys())[0].split(' ')[1]) if value count['否'] else '否' else: next_Tree = get_next_Tree(Tree, key, value) return dfs_Tree(next_Tree, row) else: return Tree
主函数: if __name__ == '__main__': # 读取数据 filename = '/Users/haoranjiang/Documents/machine learning/111111111/tree.txt' dataSet = loadData(filename) dataSet.drop(columns=['编号'], inplace=True) # 考虑缺失值 dataSet['power'] = 1.0 data_train,data_test = traintest(dataSet) # 决策树训练 A = [column for column in data_train.columns if column != '好瓜'] Tree = TreeGenerate(data_train, A) # 决策树测试 print('准确度:',test_Tree(Tree, data_test)*100,'%') print(Tree)
代码运行截图:
|





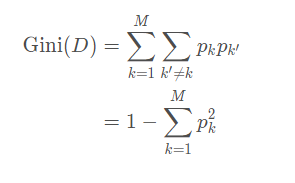

 输入离散变量的取值集合与标签,并读取数据:
输入离散变量的取值集合与标签,并读取数据:
【本文地址】
今日新闻 |
推荐新闻 |