CIKM'23 |
您所在的位置:网站首页 › 贵仁模型热启动 › CIKM'23 |
CIKM'23
 1.导读 1.导读本文主要尝试将大模型LLM用于多领域推荐模型,常见的多任务模型包含共享层和特定任务的层来训练模型。本文提出采用LLM来提取域不变特征,并使用门控融合各个特征,包括域不变特征,特定任务的特征以及其他ID特征等,从而得到查询和item的表征。并且,使用域自适应模块训练多个场景的样本,得到多领域基础模型,然后可以通过预训练微调的方式将多领域基础模型用于冷启动场景。 本文的特点: 用LM提取查询和item的文本特征,缓解冷启动时缺乏ID类特征的问题通过门控融合在融合样本中不同方面特征(文本,ID类特征,稀疏特征等)的同时,加入域信息(随机初始化的域emb),使得得到的最终emb中融合了每个域各自的信息在多任务学习阶段和以往的方式类似,在得到基础模型后,针对下游的任务,作者提出可以采用微调的方式,即在得到多任务模型后,再针对单场景进行微调2.方法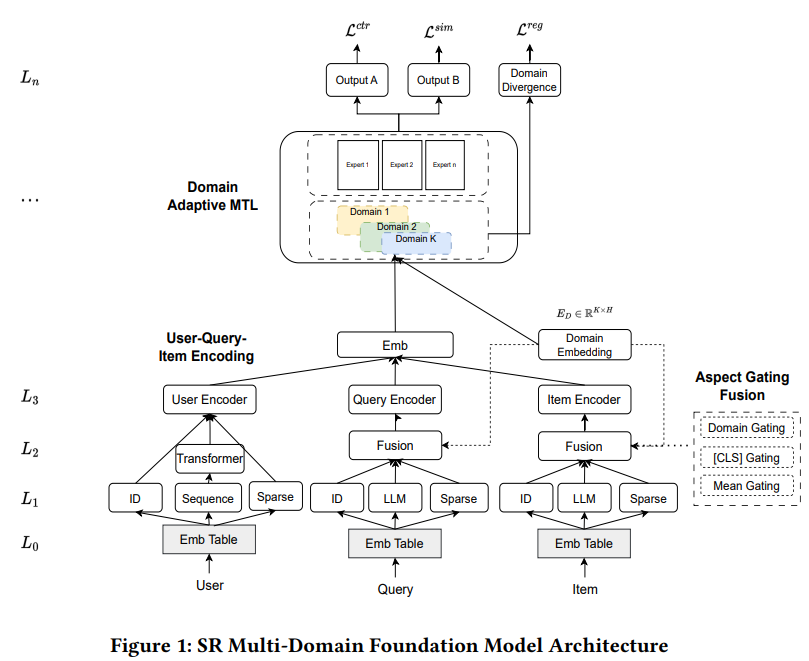 如图所示,本文所提方法主要包含三部分,分别是编码(user-query-item encoding),门控融合(aspect gating fusion)和域自适应多任务模块(domain adaptive mtl)。 首先,用户、查询和item的原始特征通过emb层,提取ID emb、token级文本emb和稀疏特征emb。用LLM提取查询和item的域不变文本特征,这最大限度地减少了特征在多个域之间的分布差异。其次,门控融合模块用于合并不同组的ID、文本、稀疏特征的emb。融合网络是为了平衡ID、文本和稀疏特征的相对重要性。在冷启动的时候,样本中包含的ID特征会比较少,导致他们的表征是不足的,可以通过本文特征来增强表征。最后,将用户、查询和item的级联emb提供给域自适应MTL模块进行ctr预估和查询item相关性预测。损失函数包含三部分,点击率预估损失L^{ctr},相关性损失函数 L^{sim}和域自适应正则项 L^{reg}2.1 编码层正如前文所述,结合框架图,可以发现,对于用户特征,我们可以考虑用户本身具有的特征和用户的历史交互序列数据,经过emb和transformer后得到用户的emb;对于查询和item在考虑其自身特征外,通过LLM提取文本特征。 2.1.1 LLM作为域不变特征提取器使用bert,gpt等预训练好的语言模型从查询和item中提取域不变的文本特征,表示为 \phi_{lm}(Q)=\phi_{lm}(e_q^{Token}) \in \mathbb{R}^{L_q \times D}和 \phi_{lm}(I)=\phi_{lm}(e_i^{Token}) \in \mathbb{R}^{L_i \times D},首先查询和item共享相同的词汇表,对查询和item分词后可以得到各自的token和对应的emb,查询的token emb表示为 e_q^{Token}=[e_q^1,...,e_q^{L_q}],对于item也同理可以得到 e_i^{Token}。 经过平均池化和线性映射后得到域不变的本文特征,公式如下(以查询为例),需要注意的是,W和 \phi_{lm}在对查询和item操作的时候是共享的。同样也对ID类特征做先行映射,使他们具有相同的维度,表示为 E_{ID}(Q)和 E_{ID}(I),对于稀疏特征经过MLP得到同样为度的 E_S(Q)和 E_{S}(I)E_{lm}(Q)=W_{lm} \times MEAN(\phi_{lm}(e_q^{Token})),W_{lm} \in \mathbb{R}^{H\times D}考虑提取文本特征的原因是,冷启动的时候,新的item和查询会缺乏ID类特征,而通过语言模型提取文本信息有助于产出有效的表征。而LLM是预训练好的,不受训练推荐模型的各个域的数据的影响,因此有助于提取域不变特征。 2.2 门控融合在通过编码层得到对应的emb后,从不同方面融合查询和item的emb。每个方面 E_a表示一些细粒度的属性,如ID类特征,文本特征和稀疏特征。对于这三方面的emb,进行加权求和,从而融合三方面的信息,表达如下,a表示不同的方面,即上面说的ID,稀疏特征和文本特征,w为权重,E为对应的emb。 E(Q)=\sum_{a}{w_a(Q)E_a(Q)},E(I)=\sum_{a}{w_a(I)}{E_a(I)}而权重可以通过以下几种方式 平均:如果像上面一样考虑三个方面,则权重为1/3[CLS]-门控策略:和bert类似,这里也设置一个[CLS]token作为分类标志,可以分别得到查询和item的E_{CLS}(Q)和 E_{CLS}(I),结合各自的emb通过softmax计算权重 w_a = \frac{e^{E_{CLS}E_a}}{\sum_{a}{e^{E_{CLS}E_a}}} 域门控策略:为每个域初始化一个emb得到E_D=[E_{D_1},...,E_{D_K}],K为域的个数,后续的计算方式和[CLS]门控策略类似 w_a = \frac{e^{E_{D_k}E_a}}{\sum_{a}{e^{E_{D_k}E_a}}} 2.3 域自适应多任务学习将编码层得到的用户,查询和item的emb拼接后作为域自适应多任务学习模块的输入 x,常用的多任务学习方法包括MMoE,PLE等,他们都是通过共享层来捕获不同域之间的相似性,然后再用独立分支来捕获任务特定的信息。多领域模型常见的问题就是域偏移(domain shift)问题,即不同域的数据分布存在差异。 本文将域自适应层添加到输入特征 , 将来自多个域的输入映射到公共向量空间。对于第k个域的输入数据,将门控策略中得到的域的emb E_{D_k}与输入 x_i拼接后经过线性变换得到域自适应的表征,公式为 \hat{x}_i=W_i(x_i\oplus E_{D_i})同样基于之前的工作,本文的方法也在多任务学习中加入了JS散度来约束不同域之间的分布 L^{reg}=\sum_{i,j\in\{1,..,K\}}{JS(p(\hat{x_i})\|p(\hat{x_j}))},整体结构采用现有的方案,如MMoE。 每个域分支的输入为前面所述的用户,查询和item的emb,输出是对点击率ctr和查询-item相关性的预测。 2.4 下游任务有监督微调经过预训练的基础模型可以以预训练微调的方式使下游任务受益。下游模型从基础模型中恢复参数,冻结部分参数并微调其余层。作者试验了不同的冻结微调拆分方式。 冻结预训练好的emb(图1中的L0),其余层进行微调冻结emb和编码层参数,其余层进行微调3.结果表2反映不同方法之间的对比结果,最后两个方法是本文所题方法,即MMoE作为多任务模块,结合域自适应(DA)和分布约束MMD或JS散度 表3反映文本提取的语言模型和下游微调的实验结果 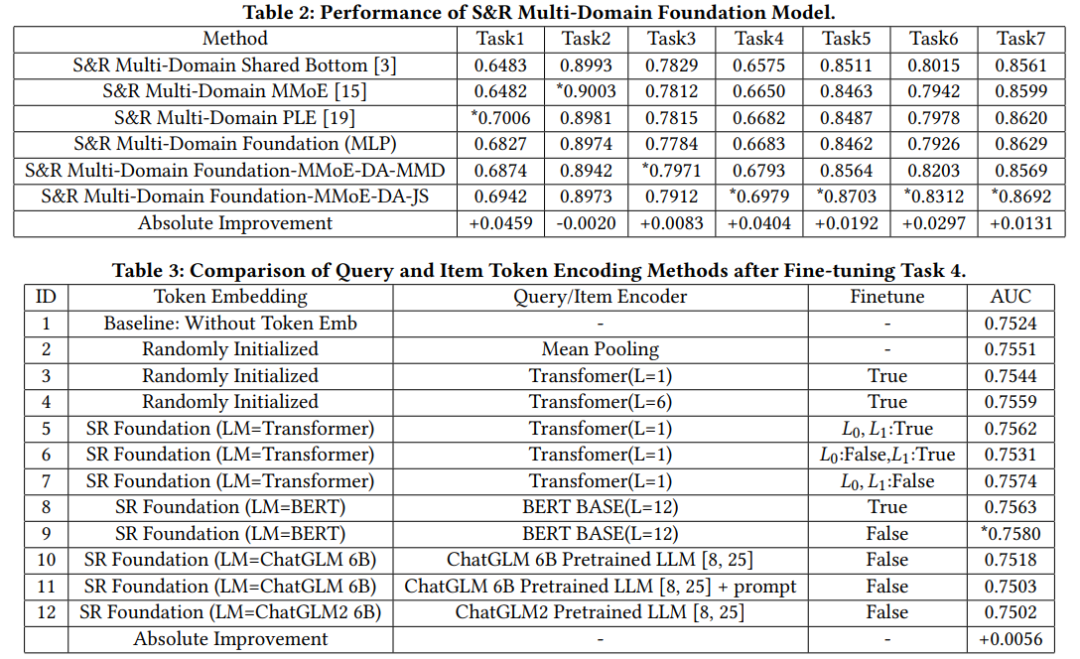 往期推荐 HAMUR:为多域推荐(MDR)设计适配器缓解参数干扰和分布差异的影响 SATrans:多场景CTR预估,场景地适应的特征交互方式 MemoNet:用codebook记住所有的交叉特征来做CTR估计 |
【本文地址】