机器学习 |
您所在的位置:网站首页 › 购物平台推荐算法实现代码 › 机器学习 |
机器学习
|
一、关联规则
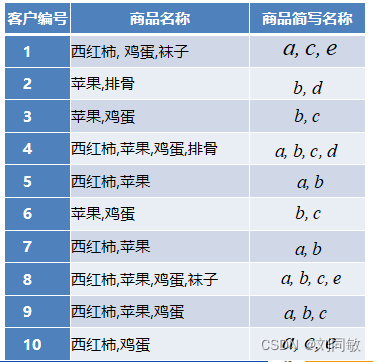
关联规则经常用于智能推荐。像平时大家购物的过程中,我们买了手机,根据关联关系,购物平台就会推荐耳机,手机保护套等配件给我们。类似还有,通过社交平台外卖平台知道你的很多朋友都爱吃辣的,那么根据你和朋友的关联关系,外卖就会推荐一些辣的菜品给你。 为了更好的理解关联规则。我们下面通过一个简单购物案例来讲解几个概念。现在有10个顾客到超市买了西红柿,鸡蛋,袜子,苹果,排骨这五种商品,如下表:
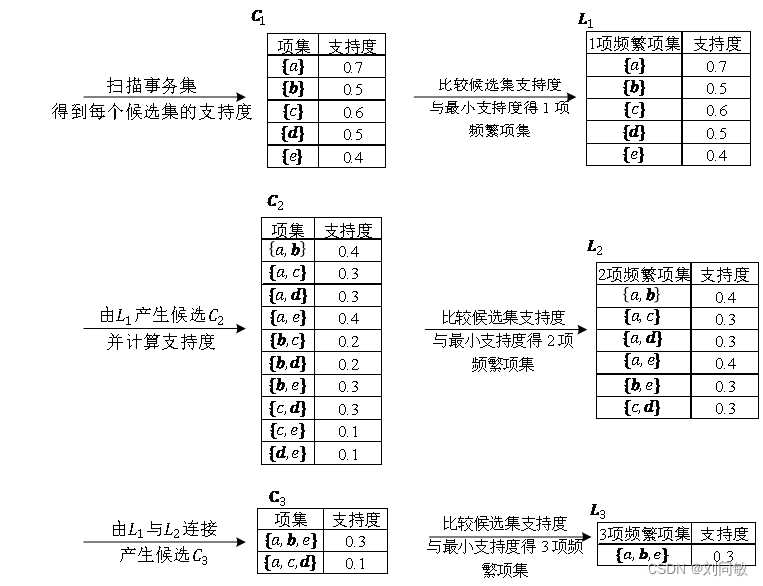
表1-1 通过表1-1我们现在希望得到一些关联规则,比如顾客买了西红柿的情况下,会不会大概率买苹果呢?比如顾客买了苹果的时候会不会大概率买鸡蛋呢?像这里讨论的这些关系,就是一系列的关联关系。这些关联关系的集合我们把他叫做关联规则。 那什么样的关联关系是我们想要得到了呢?比如即买西红柿又买排骨的这种情况在购买记录中只有1次,显然这种情况下西红柿和排骨的关联关系我们统计的没有任何。因为他发生的概率太小,堆后期去做推荐没有参考价值。我们把这种西红柿和排骨同时购买在总体购买中的占比叫支持度。显然,我们要筛选出来的关联关系都是要大于一定支持度的。所以在开发过程中我们要指定一个最小支持度阈值,大于他的关联关系才考虑。那除了支持度外,关联关系还要考虑什么问题呢? 我们观察表1-1,我们现在想知道顾客在购买西红柿的情况下会不会购买苹果呢?我们通过对表1-1记录的统计。购买记录中有西红柿的记录有7次,购买记录中在买了西红柿的前提下,购买苹果的记录有4次,4/7,比例还是比较高的。那么我们就认为顾客在购买西红柿的情况下大概率会购买苹果。这个4/7我们把他叫做置信度。置信度越大,关联关系越强。在开发过程中我们要指定一个最小置信度阈值。 所以,如果我们想从一堆数据中,找出关联规则。需要两个步骤:一、筛选出支持度高的关联关系,二、在上面的基础之上筛选出置信度高的关联关系。 上面去介绍的时候,我们举例在购买西红柿的情况下,购买苹果的概率大不大。我们用表达式来表达。用A代表西红柿,B代表苹果。那么就可以使用 表1-1种共有5种商品,如果取出任意两种出来表达关联关系(不考虑顺序差异)共有 表2-1 如果我们设定最小支持度是3/10,最小置信度是3/7。这样我们就筛选出来的关联比较强的规则{a,b}和{a.c} 表2-1中有个表头叫2项频繁项集,这个概念后面介绍的时候可能用到。我们观察表,2项频繁项集其实指的的在2种商品的情况下,每种关联关系出现的频次。整个表便是所有2种商品出现频次的集合。那类似的1项频繁项集,3项频繁项集,k项频繁项集就不难理解了。 这种一对一的关联规则在实际应用中并不常见,反而多对一关联规则比较常见。比如 在实际应用中,记录数是庞大的。那么我们如何找出我们需要的那些强关联规则呢?我们常用的一种算法是Apriori Apriori通过两步找出所有的这些可能关联关系(数据里面蕴含的1对1,2对1,3对1,等等)。1.找出所有大于最小支持度的k(2,3,4,...)项频繁项集,2.在1的基础上筛选出大于最小置信度的关联关系。最小支持度(比如3/10)和最小置信度(比如0.5)人为按经验确定。 1.找出最大k项频繁项集在找的过程中,k项包括两种数据集,一种是待选项C,另外一种确定项L。从字面意义我们就可以看出。C是初步的数据集,当大于规定的最小支持度才可能作为确定项L,注意哦,是可能。我们看下推导过程:
图3-1 图3-1从C1到L1是比较好懂的,因为支持度都大于最小支持度0.3,所以全部确定下来。C2也不难懂,从5种商品选出2种,可不就是10种情况嘛。但真是情况不止这样哈,这10种情况只有在表1-1种存在才有意义。所以C2的结果其实是从所有可能的10种组合中再筛选出数据表1-1中有的才保留下来。C2到L2应该也不难。因为支持度大于最小支持度0.3的被保留了下来。L2到C3很多人可能就看不懂了。L1和L2连接,那不就是选3种商品组合情况嘛, 我们来总结下待选项C,他根据1还是2还是3,使用组合方式算出来。比如 通过上述过程不断的迭代,我们最终可以符合最小支持度要求的k项频繁项集,比如{a,b},{a,c},{a,b,e}这只是考虑到了这些关联关系在整个记录种出现的频次,还没考虑a出现条件下,b可能出现的概率。所以还有置信度需要求解。 2.由频繁项集产生关联规则这一步理论就没那么复杂。比如我们上面举的例子{a,b},{a,c},{a,b,e},我们先计数a和a,b在表1-1中出现的次数。再在这个条件下分别计算出b,c还有e出现的次数。然后计算出置信度。把大于最小置信度的关联规则保留下来就完成了整个关联规则的筛选过程。 |
【本文地址】