基于Flink的实时风控解决方案 – 货拉拉技术 |
您所在的位置:网站首页 › 货拉拉运营专员主要做什么 › 基于Flink的实时风控解决方案 – 货拉拉技术 |
基于Flink的实时风控解决方案 – 货拉拉技术
|
一、 Flink背景
大数据领域的数据处理从大的分类看有批处理和流式处理,分别应对两种不同的数据计算需求。这两层加上服务层构成了大数据领域经典的Lambda架构,如图1 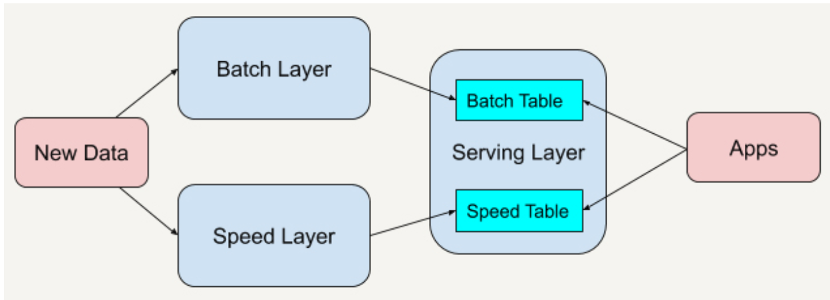
图1.Lambda架构 Batch layer 和Speed Layer两层能做的事情和对技术组件的要求大相径庭。批处理能处理大量的历史数据,日报表、月报表、年报表等。时效性不高,一般是天级别、小时级别,对它的要求是支持高吞吐、高效处理,在这个领域具有代表性的是hadoop、spark;流处理能快速处理当前产生的每一条记录,适合处理实时报表、异常监控、对它的要求是低延迟、精确处理,这个领域具有代表性的是storm、flink。而spark-steaming采用微批处理来近实时的处理数据,严格来划分还是属于批处理系统,批与批之间的间隔较短,可以认为近似实时的批处理。 Flink是目前大数据实时计算领域最流行的一款开源产品,它的设计初衷是同时面向流数据处理和批量数据处理的分布式计算开源框架。目前的主流的大厂几乎都完成了早期流行的实时计算框架storm、spark-streaming往flink的迁移。已知的包括阿里巴巴、美团、滴滴都在重度使用Flink构建实时数据处理系统,走在前沿的阿里已经开始试水使用Flink进行批处理。 那么Flink的优势是什么呢?早期的经典实时计算框架storm,设计了最简化的spout、bolt的流处理单元,通过这两种单元的组合构建实时处理流水线,一个负责接入数据源,一个负责处理数据,构建了一套灵活高效的任务拓扑图,定义了流式计算处理模式。如图2 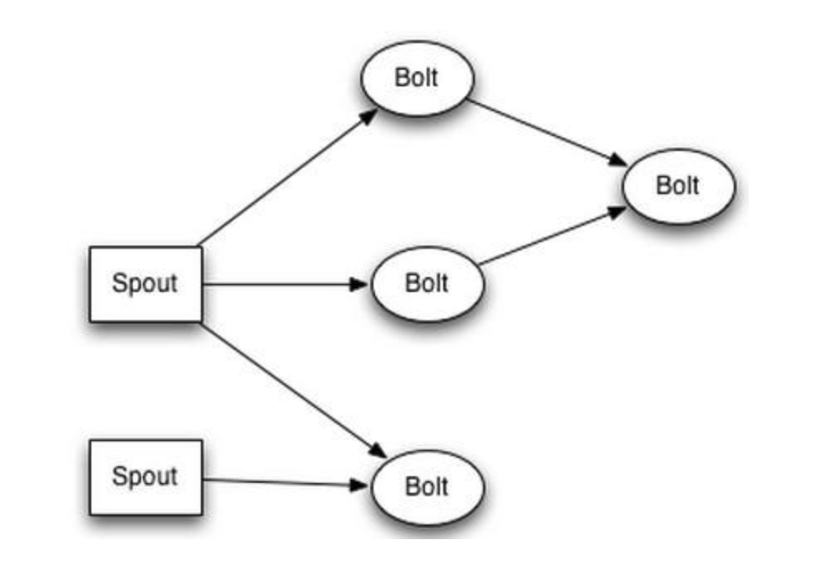
图2.Storm 任务拓扑 Storm的架构让数据处理像管道处理水流一样,在线上数据处理过程中,业务运行过程源源不断产生的数据就是Spout的数据源头,Spout根据不同的分发规则往下游的处理单元Bolt中发送数据流,而Bolt对接受到的数据流做相应的处理,例如count计数、sum统计、group by统计等等,不方便的点是这些算子包含的复杂逻辑例如时间窗口、key聚合等都需要程序员自行写代码实现和维护。 Flink继承并发展了Storm的流处理架构,提供了更多的预定义高级算子来替代Spout和Bolt。Flink中的Source作为数据来源组件,Sink作为数据输出组件,中间的map、flatMap、keyBy,window等一系列丰富的算子能很好的处理流计算中间的一些聚合,分组,映射操作,如图3所示。 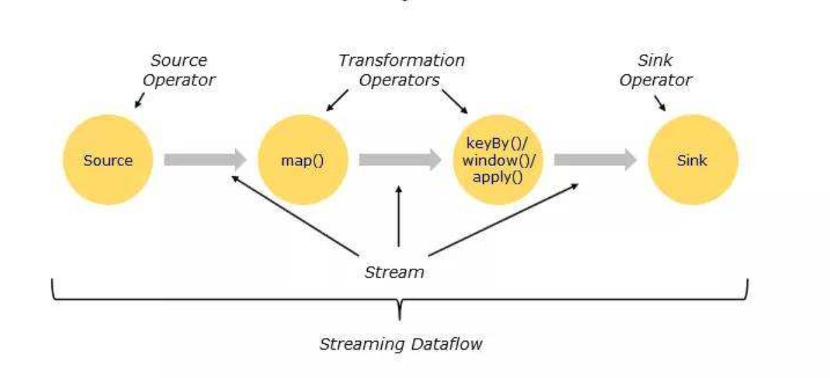
图3.Flink 任务拓扑 除此之外,Fink引入了checkpoint概念,能做很好的保障数据容错;消息投递支持Exactly Once的精确执行;状态后端保存提供了内存、文件系统、RocksDB等存储系统支持;丰富的窗口操作(滑动窗口、翻滚窗口、翻滚计数窗口、会话窗口等)。 这些特点让Flink在易用性、稳定性、功能丰富性上大幅提升,站上了实时计算系统选型的舞台中央。 二、 风控业务货拉拉目前的风控业务围绕平台上的一些非正常交易以及扰乱破坏平台秩序的行为展开,核心目标是降低各类风险事件的发生。而一个风险事件的发生从时间上来看可以分为事前、事中、事后。 这里讲一则故事来做比喻,魏文王问名医扁鹊说:“你们家兄弟三人,都精于医术,到底哪一位医术最好呢?”扁鹊回答说:“大哥最好,二哥次之,我最差。”文王再问:“那为什么你最出名呢?”扁鹊答说:“我大哥治病,是治病于病情发作之前。由于一般人不知道他事先能铲除病因,所以他的名气无法传出去,只有我们家里的人才知道。我二哥治病,是治病于病情刚刚发作之时。一般人以为他只能治轻微的小病,所以他只在我们的村子里才小有名气。而我扁鹊治病,是治病于病情严重之时。一般人看见的都是我在经脉上穿针管来放血、在皮肤上敷药等大手术,所以他们以为我的医术最高明,因此名气响遍全国。” 如果把风险事件当成平台的疾病,我们所做的就是在事前(未病)进行预防;在事中(初病)进行阻断;在事后(重病)进行追责和惩处。扁鹊自谦地将自己医术排在最后,实际这三部分缺一不可,互为支撑,互为补充,构建一套完整的人体/平台健康体系。 事后追责和惩处需要对历史数据进行离线批量分析,对风险事件分类定义和立法,严格的人工审核SOP,定时准确的产出违规名单并分级打击已经发生的违规行为,这部分是基本功,同时也为平台积累黑白样本库,给事前、事中打下基础。那么如何做到事前预防和事中的阻断呢,关键要做到两点: 1、掌握风险事件发生前的征兆; 2、风险事件发生时能快速检测并及时做出响应。 拿刷单场景举例,什么是刷单时间发生的前兆:一个刷单的用户,他为了逃避平台打击需要注册多个账号(逃避打击)、发货和司机接单距离较近(方便串通)、订单距离较小(刷单成本低)、历史用券金额高(刷单倾向)等。这些都是一些比较明显的行为特征,我们通过机器学习模型对这些特征进行建模,虽然这些特征单独都无法判定这个人会刷单,但是基于多种关联行为特征,结合机器学习模型就可以给出一个刷单事件发生的概率。 风险事件发生时如何快速检测并及时做出响应呢,这就需要使用到实时计算系统Flink了,需要用它做两件事情: 1、通过收集用户在平台上的各种行为并计算来形成每个用户特有的特征; 2、通过用户可能的风险操作节点来触发检测。 三、 整体架构一套好的业务系统需要在实时性、准确性、稳定性、可扩展性方面达到较高的技术水准,风控算法组基于lambda架构设计了以下的实时+离线的风控技术架构。如图4 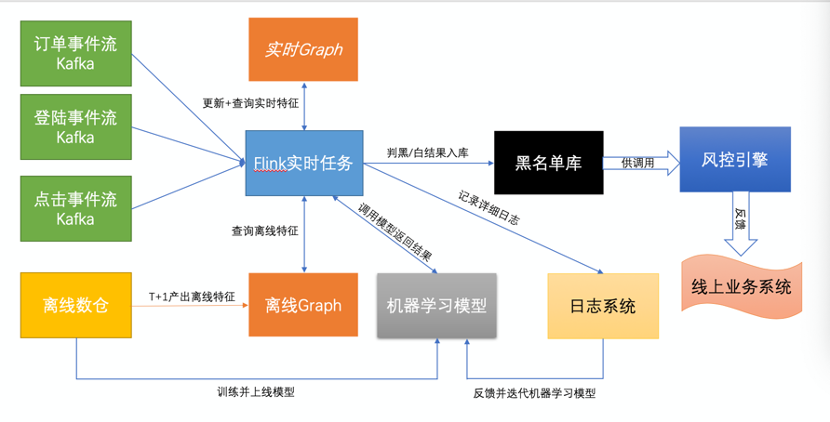
图4.FLink实时风控架构图 1、Kafka事件流:通过线上日志、线上数据库记录的用户/司机的活动数据,包括 用户下单、取消单、完成单等等;用户登陆平台、注册账号;用户在平台上的各种点击事件;2、离线数仓:大数据平台每天归档的平台历史数据,进行离线加工后形成的用户行文统计类数据包括 司机大宽表,包含了业务积累的司机行为标签和统计计数,叠加风控的历史违规记录用户大宽表,包含了用户的行文标签和各类统计计数,叠加风控的历史违规记录订单聚合表、包含了各类订单的地理位置、时间、用户人群的统计3、离线/实时Graph:这是一套存储用户、司机各类关系图谱的图数据库,能够挖掘司机和司机、用户和用户、司机和用户账号之间的各类关系,物以类聚、人以群分。通过关联为机器学习模型提供更多的判断依据。这里的Graph采用了HBase数据库,所以既可以存储关联图数据,也可以存储普通的kev-value_list特征,在一套架构内完成,减少了系统复杂性。 分为离线和实时Graph:离线Graph方便回溯数据,以及添加新节点、新边,恢复容易,可供离线BI分析以及模型训练使用;实时Graph的时效性好,缺点是维护复杂,添加新节点开发代价高,供线上Flink实时判定使用。 目前离线图、实时图互为补充,相互验证,且离线图作为实时图的备份,可以在实时图故障时快速恢复,提供了冷备的数据存储安全方案。 4、机器学习模型 机器学习模型基于离线数据训练得到,通过回溯特征在训练集、测试集、验证集上进行严格的数据验证,得到模型的精确度。模型好坏的衡量标准是如何在对正常用户影响面最小的情况下尽量多的打击异常订单、异常司机/用户。 模型真正上线前还需要经过真实数据的simulation,以确定模型效果符合预期,模型产生的black_list进入风控引擎后也会以观察模式运行,观察模式符合预期后才会真正在线上生效。 5、日志系统 对于模型判定的日志,建立了效果大盘,每天可以统计模型的打击效果。除此之外风控是一种对抗类业务,随着风控手段的升级,平台上的案犯作案手段也会升级,一旦原有模型效果不佳就需要进行迭代升级,加强模型效果。长期积累沉淀的日志是旧模型跟踪和新模型构建的重要依据。 6、黑名单库 Flink实时数据流和风控引擎在数据交互接口上是异步进行的,中间的介质就是黑名单,包括司机黑名单、用户黑名单、订单黑名单三大类。每一类里面又划分是判定的结果是刷单或是别的风险类别。如表1所示: 表1.黑名单种类 刷单……司机黑名单Driver_brush_black_list……用户黑名单………订单黑名单………黑名单库也采用HBase,和Graph共用一套存储引擎,让架构设计尽量简单。黑名单库支持增加和删除,随着用户行为、时间、模型迭代的变化,黑名单库不断更新 7、Flink任务 Flink任务是整套架构的核心与骨架,他串联起来了整个的实时风控架构,其余各个组件几乎都有交互,这里重点展开一下。Flink的各个计算阶段可以展开为一张流式拓扑图,如图5: 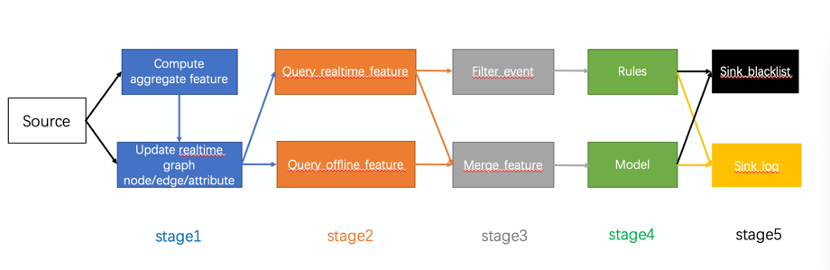
图5.Flink各阶段任务拓扑 数据源kafka的日志接入之后,Flink任务分为5个阶段: Stage1:这一阶段承载的是对新采集的数据特征进行计算并持久化存储的工作 compute aggregate feature: 对于需要做聚合计算的实时特征,flink提供了window的算子,比如计算最近一天、最近一小时的用户完单数、用户领券数。利用window可以得到精确的结果。Flink提供了各种不同类型的window来进行统计类计算,如图6。最常用的还是Tumbling Time Window以及Sliding Time Window,前者是翻滚时间窗口,固定一个窗口时间,数据流运行到当前窗口尾部,对该窗口内数据做统计操作;后者是滑动窗口,窗口时间固定,但是窗口是往前移动的,例如1小时的窗口,每次只取当前时间点往前推一小时内的数据,窗口移动的速度可选择。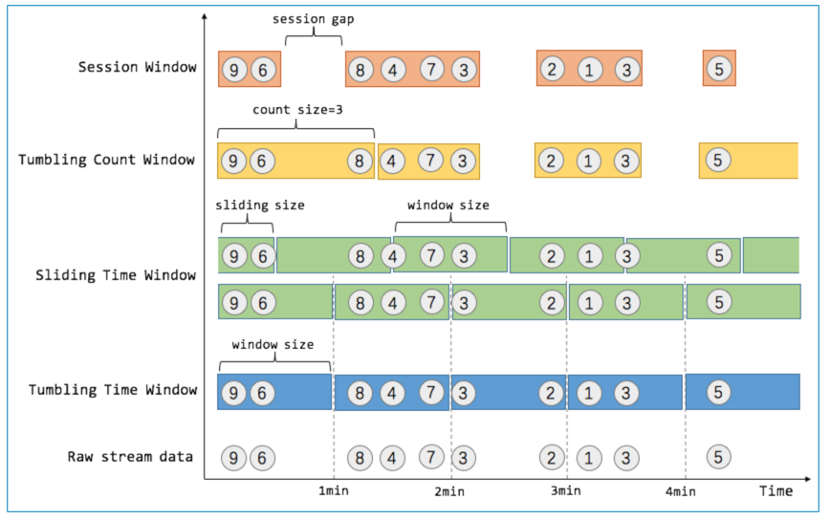
图6.Flink各类window比较 update realtime graph node/edge/attribute:对于(1)中已经聚合计算好的实时特征attribute,以及日志中记录的新增用户、新增关联关系产生的图的node、edge以及其静态attribute,在这里进行统一的持久化。使用Graph的SDK写入HBase图数据库Stage2:这一阶段承载的是查询实时、离线图特征,为后续判定准备数据的工作 query realtime feature: 查询实时图的特征,包括静态或者已聚合过后的attribute,还包括graph embedding后的图特征。query offline feature: 查询离线图的特征,主要是离线T+1准备好的静态attribute,离线查询和实时查询做了解耦,分别查询两张不同的表。Stage3:对实时离线特征进行整合,对数据进行分流和过滤 merge feature:这一步是对实时/离线混合特征进行merge,例如计算最近30天内的用户完单数,我们的做法是将当前日期T-1的离线计算完单数+通过Flink window聚合统计的T-1天0点到当前时间的计数进行累加得到最终完整的实时离线混合特征。这个部分的设计有一定瑕疵,离线计算T-1的特征不可能在前一天结束后一天开始的00:00一次计算好,这个时候就会产生数据的空洞(00:00-00:06),无法准确计算混合特征值。这个空洞出现在凌晨,平台流量相对较小,只涉及离线实时混合类特征,影响面不高。预计在下一版本中计算离线T-2的数据,实时特征采用-2天的00:00作为窗口起点,彻底解决这个问题。filter event:在filter event中对用户数据进行过滤,去除掉一些较和用户事件无关的操作日志,并根据特征的查询结果将人群/订单进行简单分类,一类送到规则处理单元进行判定,一类送到模型中进行判定。Stage4:对上一步分流过来的数据进行相应的判定,规则/模型 Rules:通过一些非常简单的规则判定该用户或订单异常,例如司机和货主实际在同一张关系图中,很明显的自己发单自己接。那么就把当前的司机、货主、订单判为黑,加入到后续黑名单中Model:对于无法简单判断的情况,将前几步中查询的离线实时特征送入机器学习模型,模型返回一个危险概率,通过概率大小将对应的账户写入黑名单中。Stage5:运行结果输出 Sink blacklist:将模型或者规则判定的异常账号、订单写入到HBase存储,这一步需要对数据来源进行分类打标,并和风控引擎约定一个通用的数据格式对所有结果进行标准化。目前我们通过账号+分数+时间+模型名称进行区分Sink log:将模型或者规则的每一条判定结果进行打印并输出到kafka。记录的内容包括特征、分数、判定时间、模型名称、模型版本号。通过kafka再同步到HIve以做离线分析,未来会同步到Phoenix/Druid做实时分析。 四、 线上应用技术驱动业务,是一个成熟的科技公司始终应该坚持做的事情。以上模型已经运用到货拉拉线上风控业务中的预防营销资损环节。关于模型的效果我们建立了数据观察大盘。如图7所示 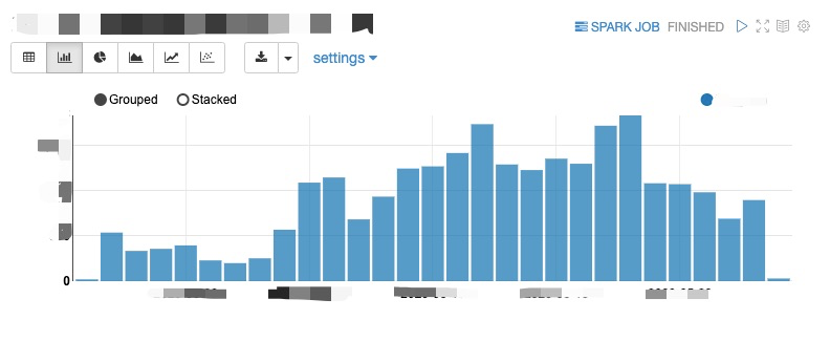
图7.日粒度统计大盘 上图每一根柱子代表这一周期内我们拦截的危险事件的数量。目前大盘是通过离线数据导入hive中查询出来,可以支持周粒度、月粒度大盘。对于目前的分析和统计已经足够。 实时系统应用到业务中比较重要的一点就是数据准确性。数据准确性决定了这套架构的上限效果,数据延迟决定了模型能够多大程度将风险提前发现并控制。 数据准确性保障: 严格的上线流程:实时、离线特征、模型、规则等代码review、测试、预发布、观察模式一些列保障措施。使用Flink和HBase自有的数据保障恢复能力,checkpoint等,离线数据为实时数据做冷备。实时监控:一旦流量掉底或者异常(同、环比)发出报警,数据延迟发出报警,相应开发运维同学上线进行处理。如图8所示: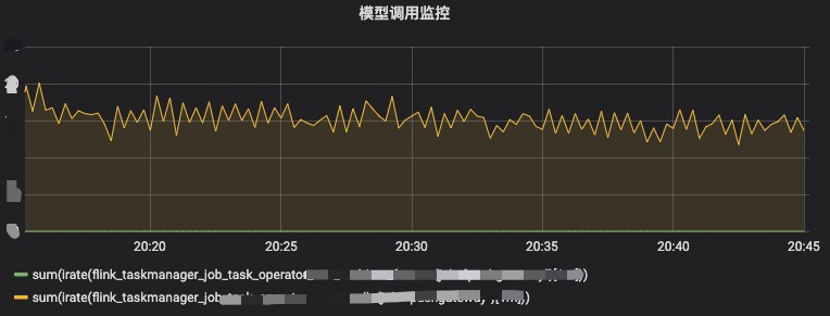
图8.模型调用监控 定时巡检:检测程序对实时、离线特征进行定期比对抽查,避免数据上的错漏大盘指标反馈:如果整套系统的某一个环节出问题,最终会反应到大盘上,通过对大盘的监控反推问题,解决线上可能出现的bug。 五、 总结展望目前这套Flink实时风控架构已经完成了从0到1的构建,本文重点介绍了Flink部分涉及的内容。在整套架构中,我们的关系图谱数据库、机器学习模型、以及风控中台引擎也都起到了重要的作用。 当前这套架构还存在的不足是: 数据质量检测的机制还未完整建立起来。离线实时特征的计算分开之后可能存在的数据不一致问题。目前大数据领域提出的最新Kappa架构,以及google提出的dataflow架构,将批流计算都集成到一个计算引擎中。开源界Flink目前也朝着批流一体的方向在发展,这套架构的难度相对经典lambda架构实现难度更大,但也极具价值。 除了这些传统大数据实时/离线计算、机器学习之外,目前我们团队还在探索和推进的AI类应用,比如图片、声音、文字等内容的基于深度学习的分析。后续都会围绕这套架构进行扩展,更好的服务风控业务。 作者介绍: 袁康(kira.yuan),货拉拉高级大数据专家 |
【本文地址】
今日新闻 |
推荐新闻 |