python 数据分析 |
您所在的位置:网站首页 › 财务数据预估 › python 数据分析 |
python 数据分析
|
说明:
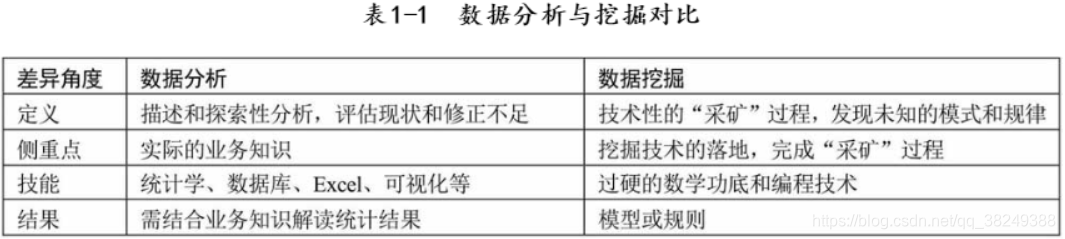
本文用途只做学习记录: 参考书籍:从零开始学Python数据分析与挖掘/刘顺祥著.—北京:清华大学出版社,2018 数据下载:链接:https://pan.baidu.com/s/1VhnNfUNgNLICIFRyrlteOg提取码:m1dl首先看一下刘老师介绍的数据分析和数据挖掘的区别:
通过Excel工具打开income文件,可发现该数据集一共有 32 561条样本数据,共有15个数据变量,其中9个离散型变量,6个数值型变量。数据项主要包括:年龄,工作类型,受教育程度,收入等,具体可见下面两个图:
实验目的:因此,基于上面的数据集,需要预测居民的年收入是否会超过5万美元? 2. 导入数据集,预处理数据在jupyter notebook中导入相应包,读取数据,进行预处理。在上述数据集中,有许多变量都是离散型的,如受教育程度、婚姻状态、职业、性别等。通常数据拿到手后,都需要对其进行清洗,例如检查数据中是否存在重复观测、缺失值、异常值等,而且,如果建模的话,还需要对字符型的离散变量做相应的重编码。 import numpy as np import pandas as pd import seaborn as sns # 下载的数据集存放的路径: income = pd.read_excel(r'E:\Data\1\income.xlsx') # 查看数据集是否存在缺失 income.apply(lambda x:np.sum(x.isnull())) age 0 workclass 1836 fnlwgt 0 education 0 education-num 0 marital-status 0 occupation 1843 relationship 0 race 0 sex 0 capital-gain 0 capital-loss 0 hours-per-week 0 native-country 583 income 0 dtype: int64从上面的结果可以发现,居民的收入数据集中有3个变量存在数值缺失,分别是居民的工作类型(离散型)缺1836、职业(离散型)缺1843和国籍(离散型)缺583。缺失值的存在一般都会影响分析或建模的结果,所以需要对缺失数值做相应的处理。 缺失值的处理一般采用三种方法: 1.删除法,缺失的数据较少时适用; 2.替换法,用常数替换缺失变量,离散变量用众数,数值变量用均值或中位数; 3.插补法:用未缺失的预测该缺失变量。根据上述方法,三个缺失变量都为离散型,可用众数替换。pandas中fillna()方法,能够使用指定的方法填充NA/NaN值。 函数形式: fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs) 参数: value:用于填充的空值的值。(该处为字典) method: {'backfill', 'bfill', 'pad', 'ffill', None}, default None。定义了填充空值的方法, pad/ffill表示用前面行/列的值,填充当前行/列的空值, backfill / bfill表示用后面行/列的值,填充当前行/列的空值。 axis:轴。0或'index',表示按行删除;1或'columns',表示按列删除。 inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操作,返回值为None。 limit:int,default None。如果method被指定,对于连续的空值,这段连续区域,最多填充前 limit 个空值(如果存在多段连续区域,每段最多填充前 limit 个空值)。如果method未被指定, 在该axis下,最多填充前 limit 个空值(不论空值连续区间是否间断) downcast:dict, default is None,字典中的项,为类型向下转换规则。或者为字符串“infer”,此时会在合适的等价类型之间进行向下转换,比如float64 to int64 if possible。 # 缺失值处理,采用众数替换法(mode()方法取众数) income.fillna(value={'workclass':income['workclass'].mode()[0], 'ouccupation':income['occupation'].mode()[0], 'native-country':income['native-country'].mode()[0]}, inplace = True) 3. 探索数据背后的特征对缺失值采用了替换处理的方法,接下来对居民收入数据集做简单的探索性分析,目的是了解数据背后的特征如数据的集中趋势、离散趋势、数据形状和变量间的关系等。首先,需要知道每个变量的基本统计值,如均值、中位数、众数等,只有了解了所需处理的数据特征,才能做到“心中有数”。 3.1 数值型变量统计描述 # 3.1 数值型变量统计描述 income.describe() age fnlwgt education-num capital-gain capital-loss hours-per-week count 32561.000000 3.256100e+04 32561.000000 32561.000000 32561.000000 32561.000000 mean 38.581647 1.897784e+05 10.080679 1077.648844 87.303830 40.437456 std 13.640433 1.055500e+05 2.572720 7385.292085 402.960219 12.347429 min 17.000000 1.228500e+04 1.000000 0.000000 0.000000 1.000000 25% 28.000000 1.178270e+05 9.000000 0.000000 0.000000 40.000000 50% 37.000000 1.783560e+05 10.000000 0.000000 0.000000 40.000000 75% 48.000000 2.370510e+05 12.000000 0.000000 0.000000 45.000000 max 90.000000 1.484705e+06 16.000000 99999.000000 4356.000000 99.000000上面的结果描述了有关数值型变量的简单统计值,包括非缺失观测的个数(count)、平均值(mean)、标准差(std)、最小值(min)、下四分位数(25%)、中位数(50%)、上四分位数(75%)和最大值(max)。 3.2 离散型变量统计描述 # 2. 离散型变量统计描述 income.describe(include= ['object']) workclass education marital-status occupation relationship race sex native-country income count 32561 32561 32561 30718 32561 32561 32561 32561 32561 unique 8 16 7 14 6 5 2 41 2 top Private HS-grad Married-civ-spouse Prof-specialty Husband White Male United-States |
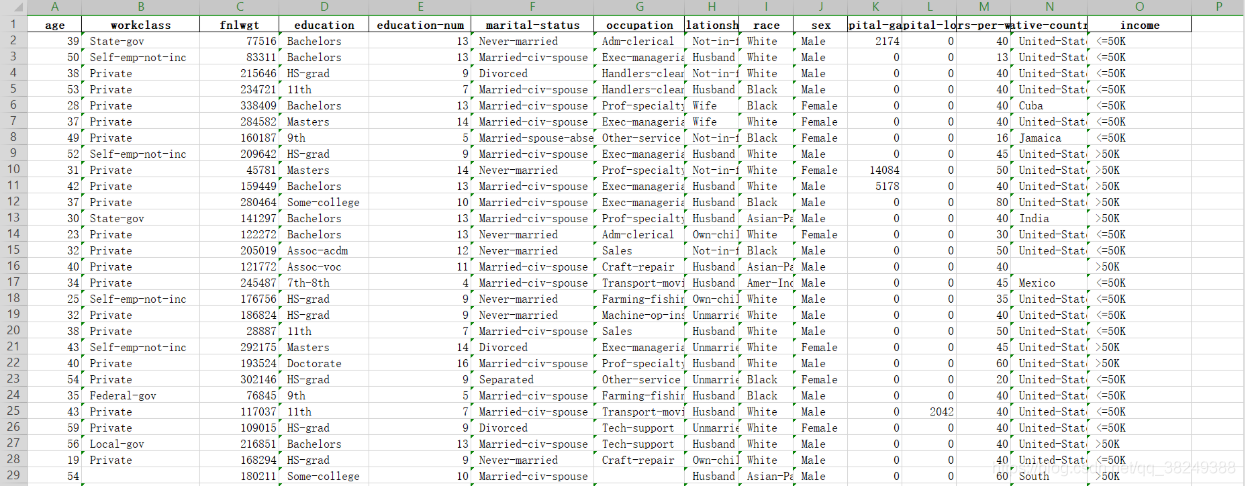
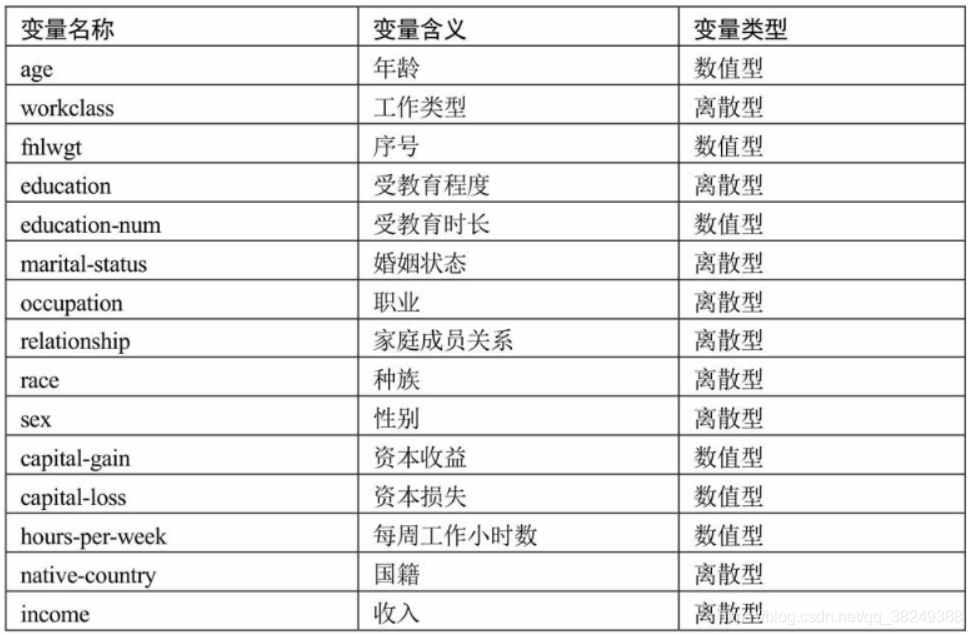 拿到上面的数据集,我们观察这些数据都有什么用,想一想这张数据表中income比较特殊,有分析价值,其他变量的不同会对income产生一定的影响。
拿到上面的数据集,我们观察这些数据都有什么用,想一想这张数据表中income比较特殊,有分析价值,其他变量的不同会对income产生一定的影响。【本文地址】
今日新闻 |
推荐新闻 |