socket负载均衡的几种方式 |
您所在的位置:网站首页 › 负载均衡的几种方式是 › socket负载均衡的几种方式 |
socket负载均衡的几种方式
|
回忆一下你刚开始学习socket编程的场景:先创建类型为STREAM的socket,再调用listen、accept、read方法,把程序运行起来后,就完成了最简单的,以单进程的方式运行TCP服务器。当然,这样的服务器性能是很差的,只能用于响应数量极少的情况。 实际的应用场景需要服务器响应更多的请求,因此需要对原始的服务器进行扩展。通常来说,这种扩展并不困难,最容易想到的办法是增加工作进程的数量。这种通过增加工作进程数量来提升服务器负载能力的模型容易扩展,很多流行的HTTP服务器,比如Apache,NGINX或者Lighttpd都采用了这种模型。 增加工作进程数量方法能够有效利用多核处理器来提升网络服务器的负载能力,但是会带来一个新问题。 就性能而言,通常有三种设计TCP服务器的方法。 单个工作进程监听单个套接字 多工作进程监听单个套接字 多工作进程,每个进程监听单独的套接字。第一种方法如下图所示。 
这是最简单的模型,该模型只会使用到单个CPU。单个工作进程执行accept()方法以接受新连接并处理请求。这是使用Lighttpd推荐的设置。 第二种方法如下图所示。 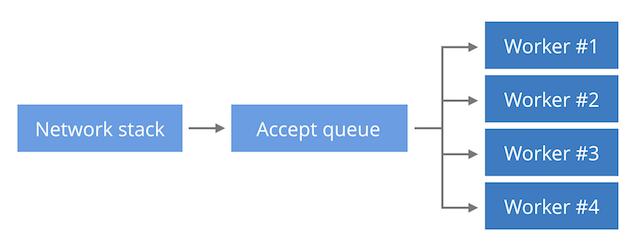
父进程新建套接字后,调用listen创建连接。父进程创建多个子进程,子进程调用accept,处理请求。这个模型可以使多个请求分散到多个CPU中。这是NGINX的标准模型 第三种方法如下图所示。 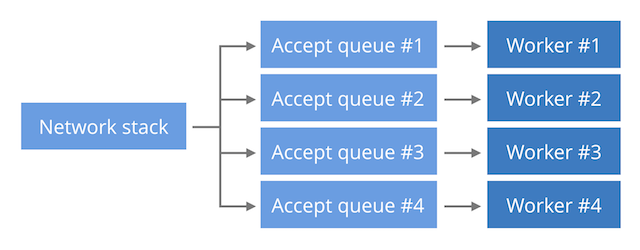
通过socket的SO_REUSEPORT,可以为每个工作进程创建专用的监听套接字。这样可以避免多个进程竞争使用套接字,也可以更好地实现负载均衡。 有两种方式可以通过accept方法实现在多个进程中处理新的连接。比如下面的这段Python代码,文件命名为block-accept.py # coding=utf-8 import os import socket sd = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sd.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) sd.bind(('127.0.0.1', 1024)) sd.listen(10) for i in range(3): if os.fork() == 0: while True: cd, _ = sd.accept() cd.close() print('worker %d' % i) os.wait()这段代码同时在多个进程中调用阻塞的accept()方法,来跨进程共享一个接受队列,我们将这个方法称为“阻塞accpet”方法。 还有一种方法,我们称之为“epoll-accept”方法。能在Linux系统上运行的代码如下(文件命名为epoll-and-accept.py): # coding=utf-8 import os import select import socket sd = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sd.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) sd.bind(('127.0.0.1', 1025)) sd.listen(10) sd.setblocking(False) for i in range(3): if os.fork() == 0: ed = select.epoll() ed.register(sd, select.EPOLLIN) while True: try: ed.poll() except IOError: continue try: cd, _ = sd.accept() except socket.error: continue cd.close() print('worker %d' % i) os.wait()上面的代码中,每个工作进程都有自己的epoll。只有当epoll报告新连接到来时,才会调用accept()方法。 上面两段代码看起来非常相似,不过工作的效果却有细微的差别。可以用nc命令来对服务器做一些测试 $ python blocking-accept.py & $ for i in `seq 6`; do nc localhost 1024; done worker 0 worker 1 worker 2 worker 0 worker 1 worker 2 $ python epoll-and-accept.py & $ for i in `seq 6`; do nc localhost 1025; done worker 2 worker 1 worker 1 worker 2 worker 2 worker 2采用blocking-accept模型的服务器将连接均分给了所有的工作进程,每个进程都正好分配到了两个连接;采用epoll-accpet模型的服务器则更倾向于将新连接分配给最后一个工作进程。 也就是说,针对不同的模型,Linux会执行不同的负载均衡策略。 在blocking-accept模型中,Linux执行round-robin负载均衡。每个阻塞在accept()的工作进程会被加入到某个队列中,然后按先进先出的顺序处理连接。 在epoll-accept模型中,Linux似乎会优先选择最后加入的工作进程,顺序是后进先出。最后被加入队列的进程会先获得新连接。因此最忙的工作进程会获取做多的工作量,因为新进的连接总是优先分配给它。 Linux提供了一个套接字选项用于解决这个问题--SO_REUSEPORT。使用该选项后,新建的连接被拆分为多个单独的接受队列。一般情况下,这意味着每个工作进程只有一个专用队列。 由于Linux通过简单的哈希逻辑分散负载,并且多个工作进程不共享队列,因此每个工作进程能获得大致相同数量的连接,以期达到更好的负载均衡效果。 不过在某些场景中,这种工作模式可能会导致问题。假设有A,B,C三个工作进程,分别对应a,b,c三个接受队列。当一个工作进程被某个工作卡住的时候,对应的队列也会被卡住,三分之一的工作都会受到影响。如果使用的第二种模式的话,就不会出现这样的问题。 当前并没有一种完美做法能将请求分布到多个工作进程中。使用第二种模式很好扩展并且有利于保持最大延迟,但是无法让多个工作进程中均衡地承担工作量。第三种模式能很好地平衡工作负载,但是在高负载情况下,会增加服务的最大延迟。 |
【本文地址】
今日新闻 |
推荐新闻 |