负对数似然 交叉熵 mse mae的区别 |
您所在的位置:网站首页 › 负对数换算 › 负对数似然 交叉熵 mse mae的区别 |
负对数似然 交叉熵 mse mae的区别
|
交叉熵的介绍见https://blog.csdn.net/jzwei023/article/details/115496906?spm=1001.2014.3001.5501 交叉熵 vs 二阶Loss函数逻辑回归一些简单的网络中,我们会使用MSE(均方误差mean-square error)这样的二阶Loss函数。然而二阶loss函数,会存在一个问题。 ANN被设计的一个最大优势在于可以根据误差进行学习来调整参数。误差越大,则希望调整的幅度越大,从而收敛速度越快。而二阶loss函数则有可能误差越大,参数调整的幅度可能更小,训练更缓慢。 MSE的公式定义:
对于一个样本,其损失函数简化为:
调参的方式采用梯度下降算法(Gradient descent),沿着梯度方向调整参数大小。 w和b的梯度推导如下:
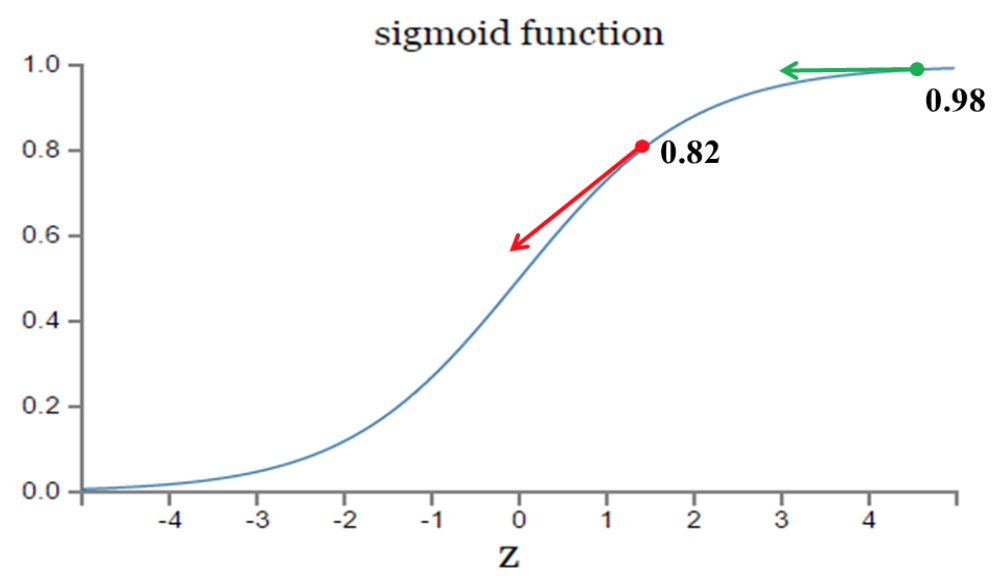
其中z是神经元的输入。从以上公式可以看出,w和b的梯度跟sigmoid函数的梯度成正比,sigmoid函数的梯度越大,w和b的梯度也越大,即大小调整得越快,训练收敛得就越快。 我们知道sigmoid函数的曲线如下:
从上图中我们可以看到,对于误差大的值(比如误差是0.98:输出值是0.98,真实值是0),相比误差小的值(比如误差是0.82:输出值是0.82,真实值是0)的下降速度更慢。 那我们看下当个样本中交叉熵中w和b的梯度:和
(见https://blog.csdn.net/jasonzzj/article/details/52017438) 可以看到二阶loss函数的w梯度公式中的σ'(z)没有了。σ(z)-y表示输出值与实际值之间的误差。所以,当误差越大,梯度就越大,参数w和b调整得越快,训练速度也就越快。 实际情况也证明,交叉熵代价函数带来的训练效果往往比二次代价函数要好。 mse和mae的区别 https://www.jianshu.com/p/1ff7ae7ea9ef 为什么分类问题不能使用mse损失函数? 1. 在线性回归中用到的最多的是MSE(最小二乘损失函数),这个比较好理解,就是预测值和目标值的欧式距离。 而交叉熵是一个信息论的概念,交叉熵能够衡量同一个随机变量中的两个不同概率分布的差异程度,在机器学习中就表示为真实概率分布与预测概率分布之间的差异。交叉熵的值越小,模型预测效果就越好。以交叉熵本质上是概率问题,表征真实概率分布与预测概率分布差异,和几何上的欧氏距离无关,在线性回归中才有欧氏距离的说法,在分类问题中label的值大小在欧氏空间中是没有意义的。 所以分类问题不能用mse作为损失函数。 2. 分类问题是逻辑回归,必须有**函数这个非线性单元在,比如sigmoid(也可以是其他非线性**函数),而如果还用mse做损失函数的话:
mse已经是非凸函数了,有多个极值点,所以不适用做损失函数了。 3. mse作为损失函数,求导的时候都会有对损失函数的求导连乘运算,对于sigmoid、tanh,有很大区域导数为0的,导致容易梯度消失。 梯度消失问题存在2个地方: 1.损失函数对权值w求导,这是误差反向传播的第一步,mse的损失函数会在损失函数求导这一个层面上就导致梯度消失;而使用交叉熵损失函数则在这一步不会导致梯度消失 2.误差反向传播时,链式求导也会使得梯度消失。使用交叉熵损失函数也不能避免反向传播带来的梯度消失,此时规避梯度消失的方法有使用ReLU、输入归一化、层归一化等。 |
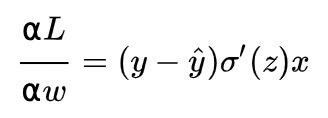
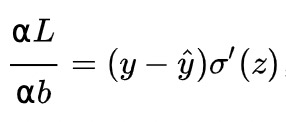
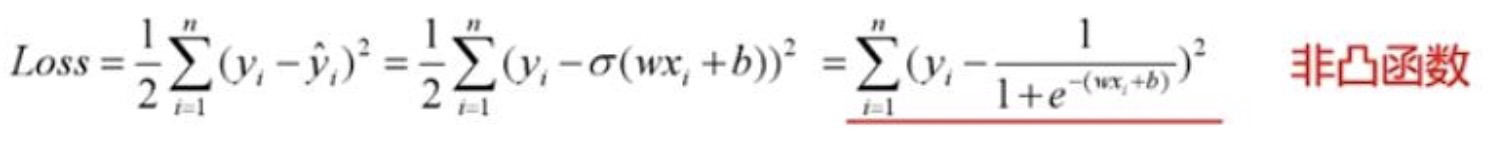
【本文地址】
今日新闻 |
推荐新闻 |