【Python毕设 |
您所在的位置:网站首页 › 豆瓣评论电影的特点 › 【Python毕设 |
【Python毕设
|
基于Python的豆瓣电影数据分析与可视化系统(获取方式访问文末官网)
一、项目简介二、开发环境三、项目技术四、功能结构五、运行截图六、功能实现七、数据库设计八、源码获取
一、项目简介
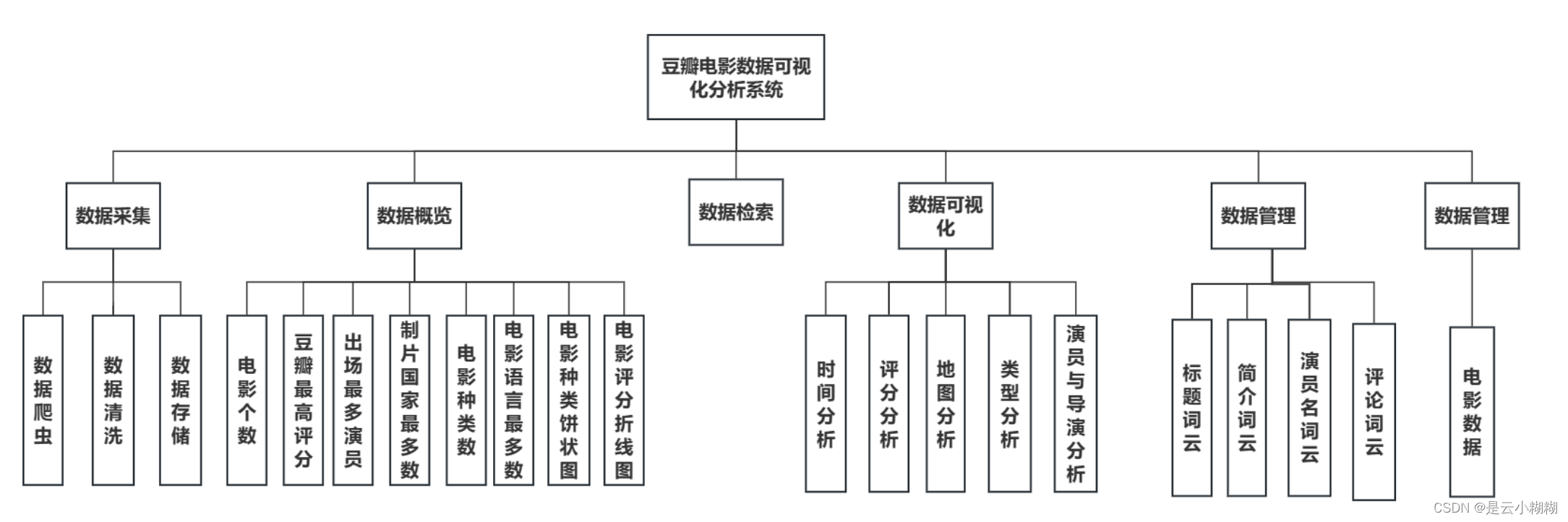
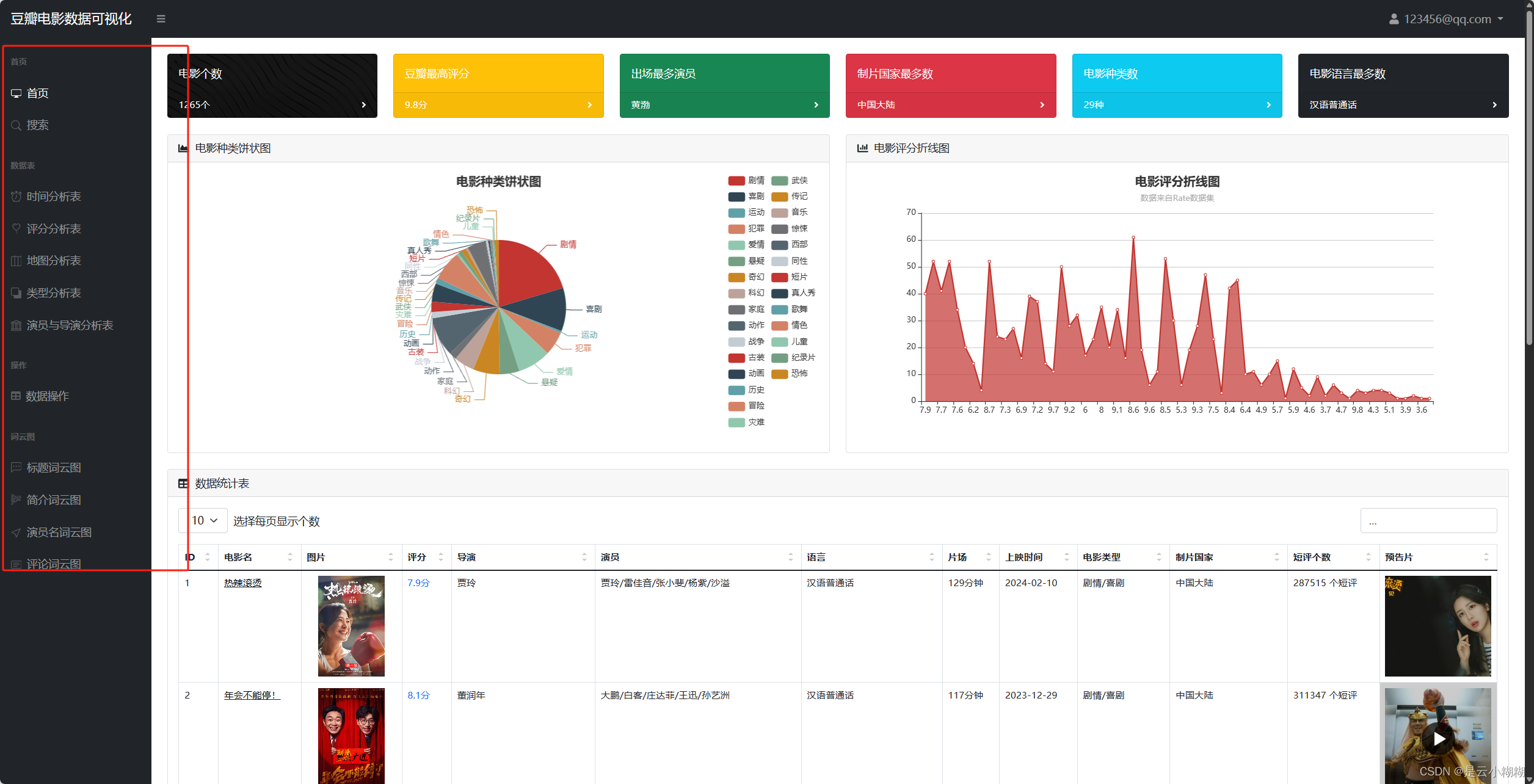
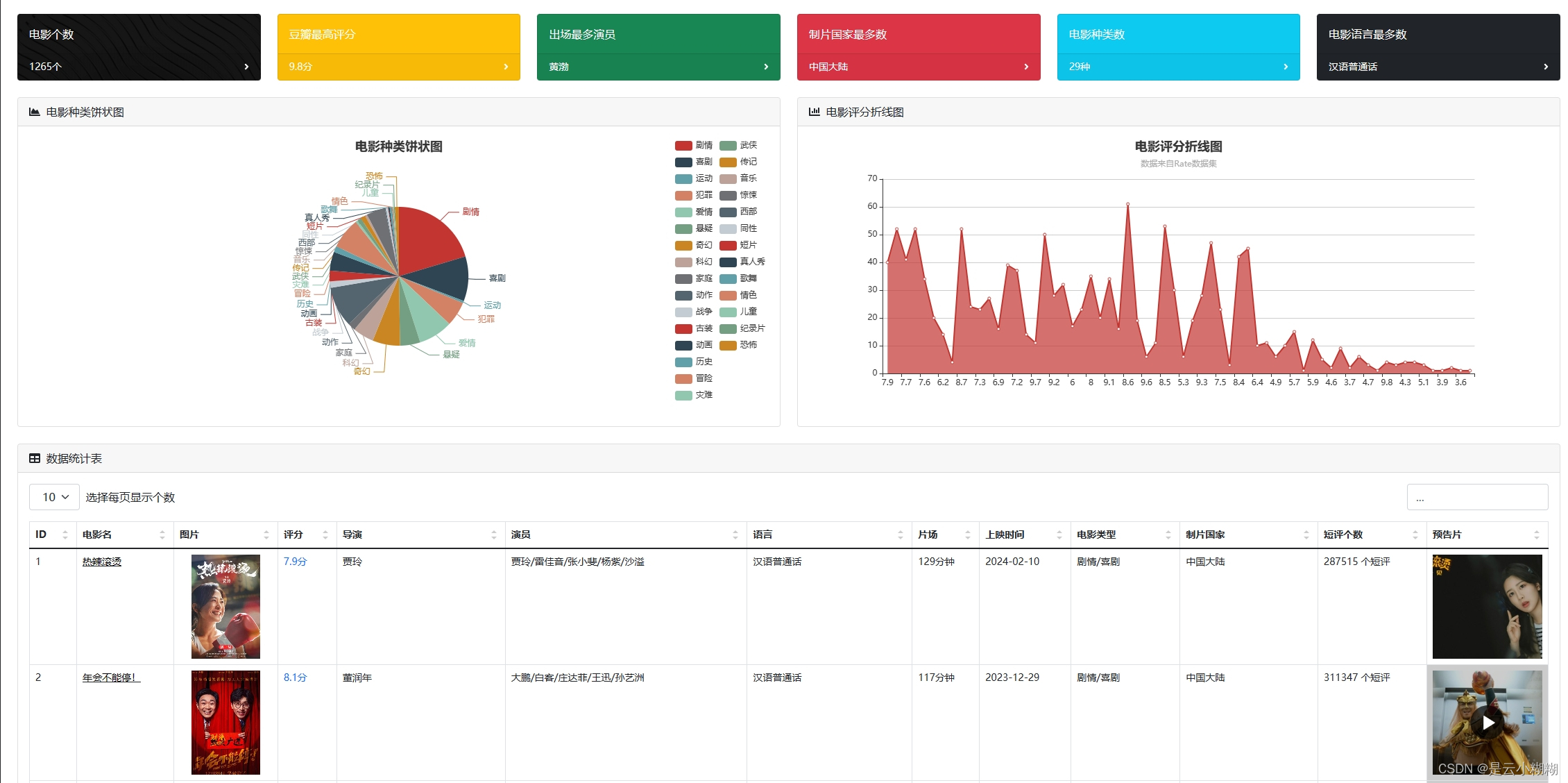
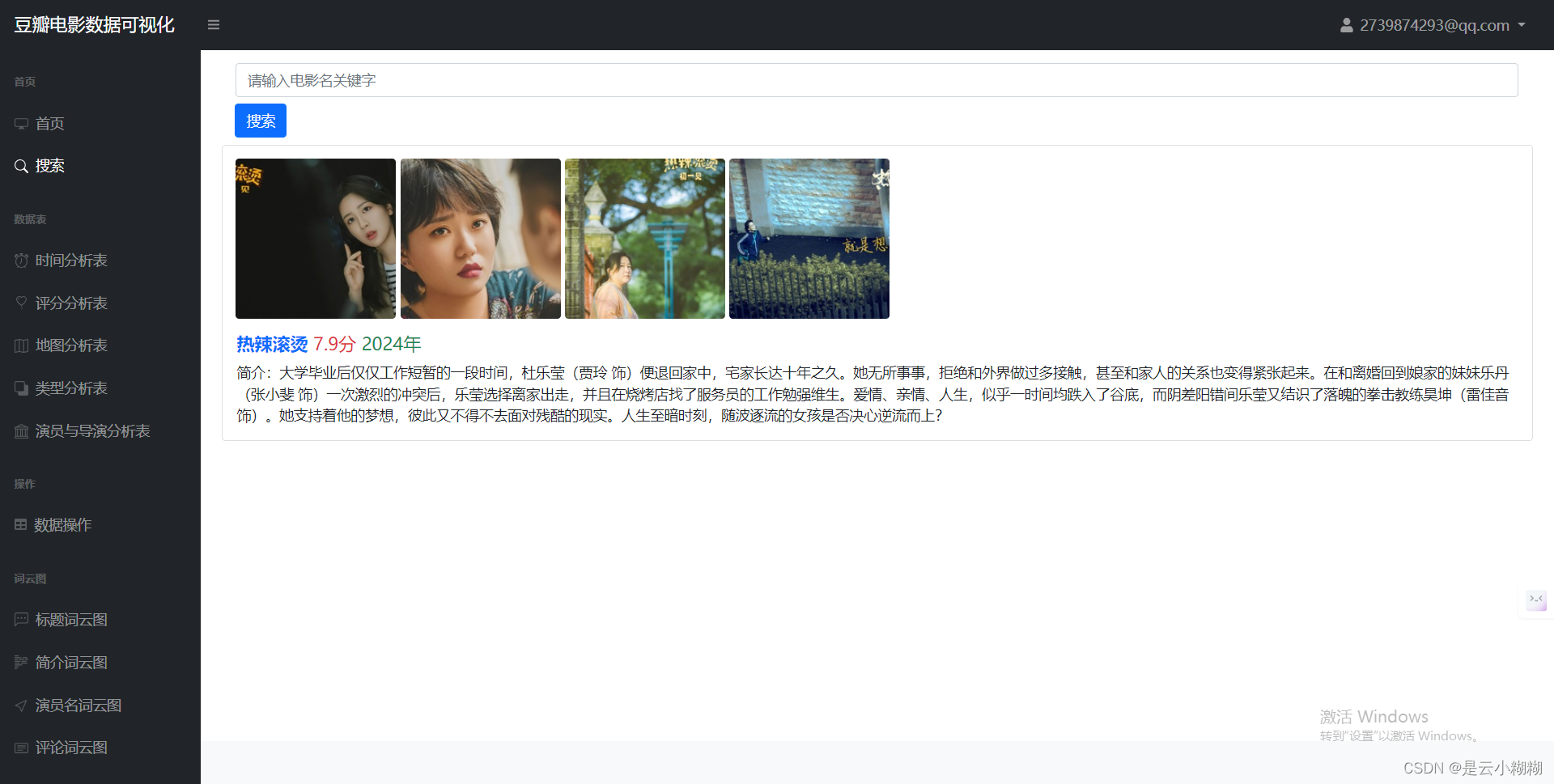
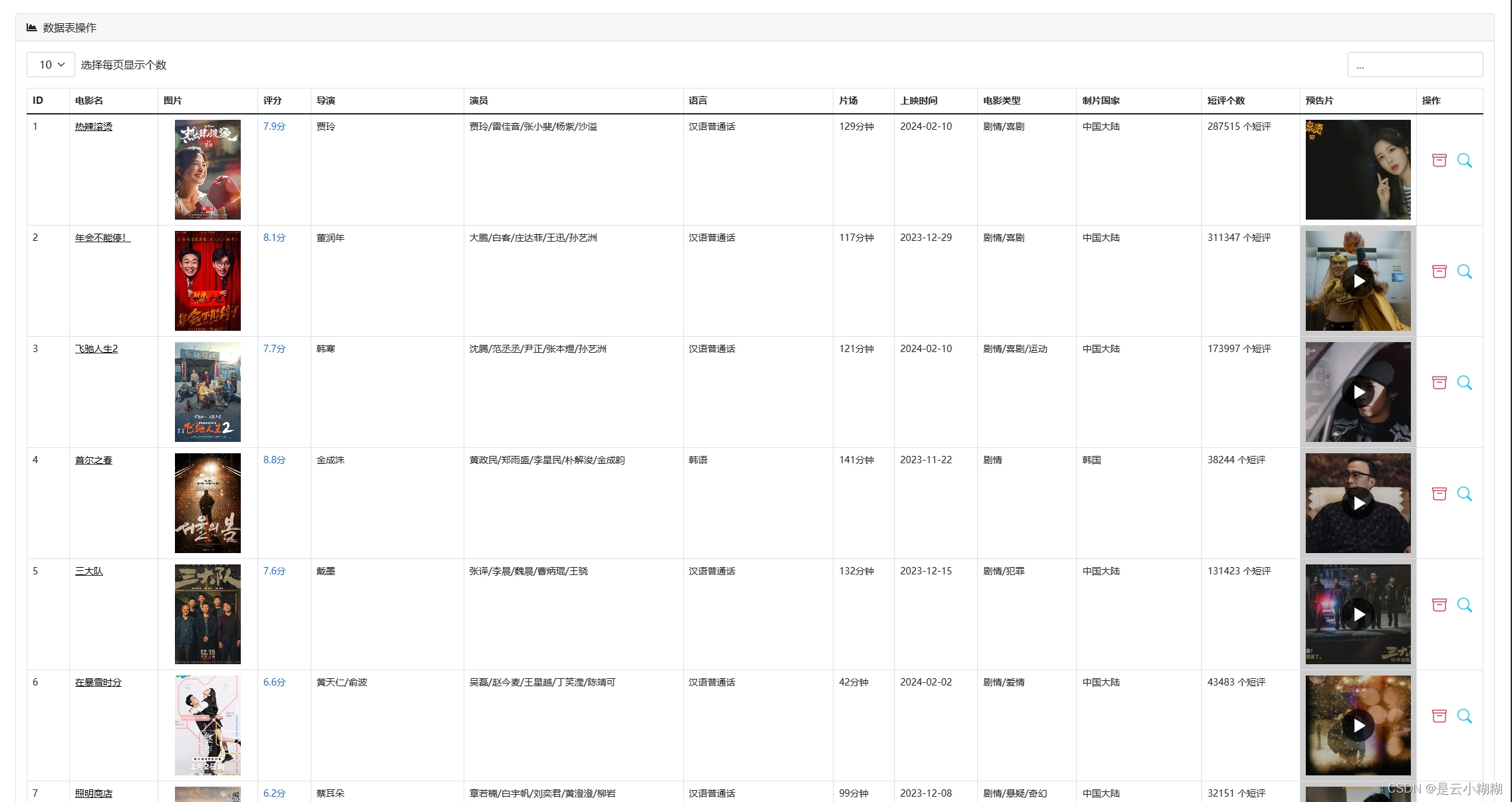
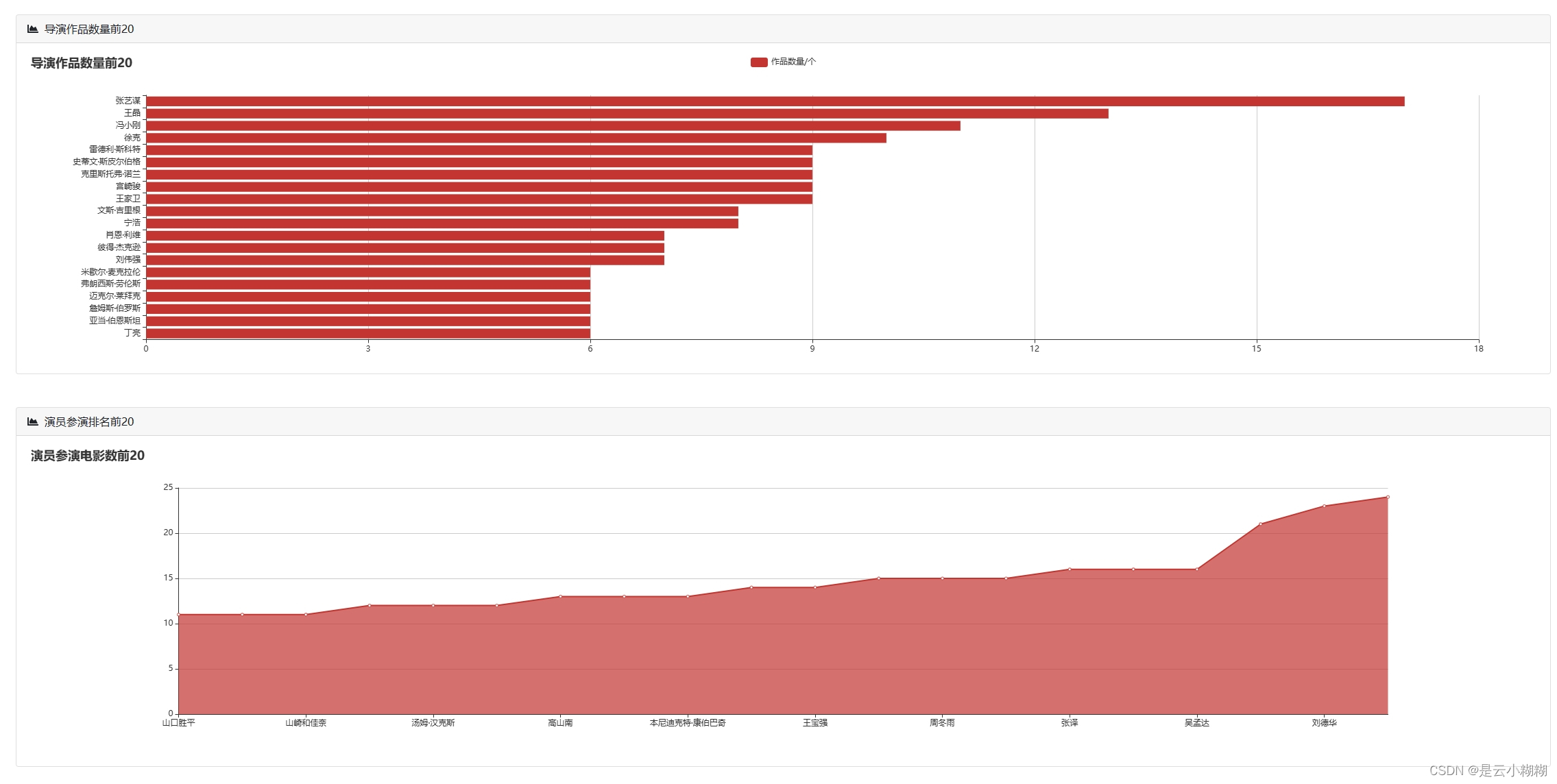
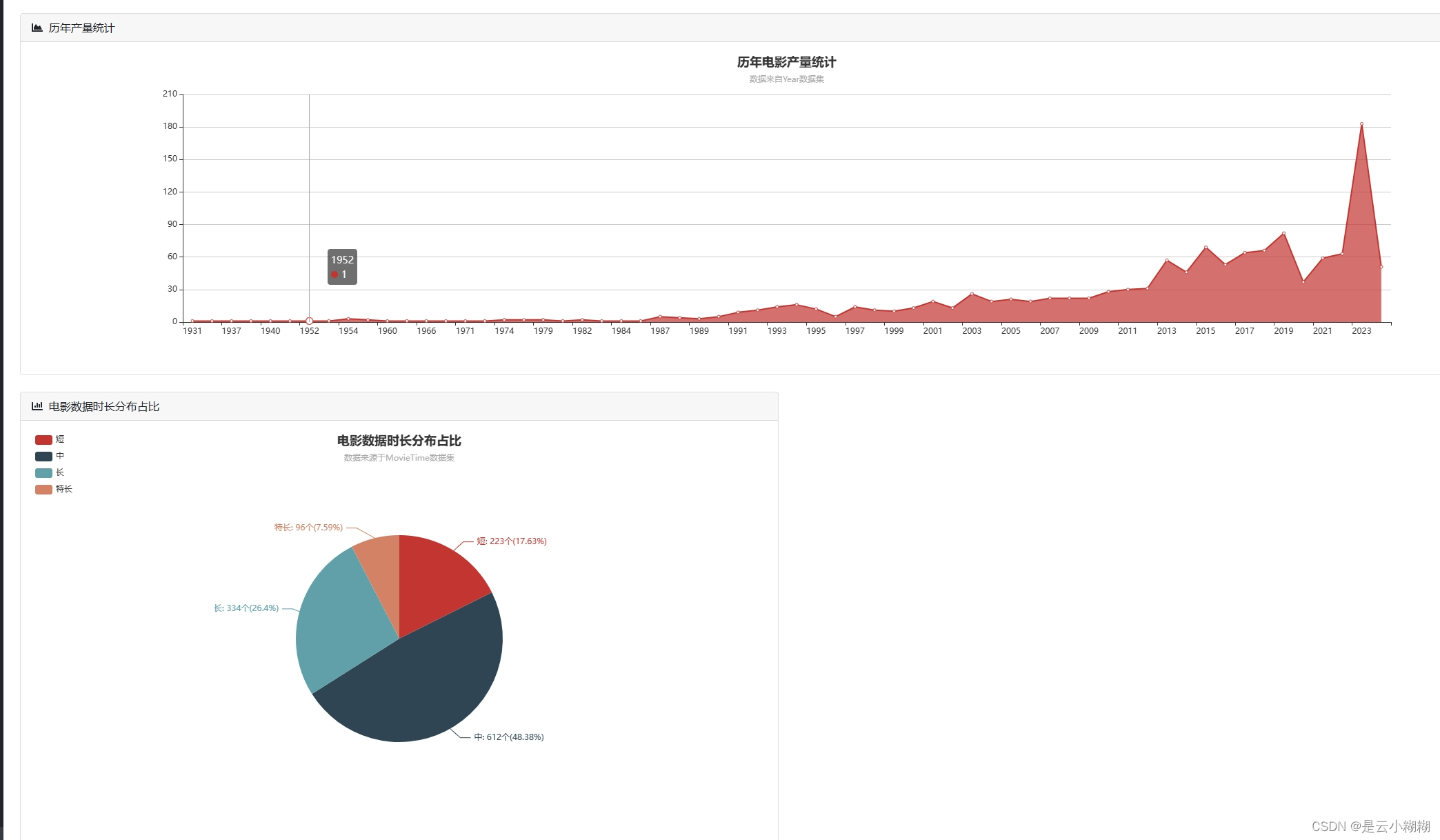
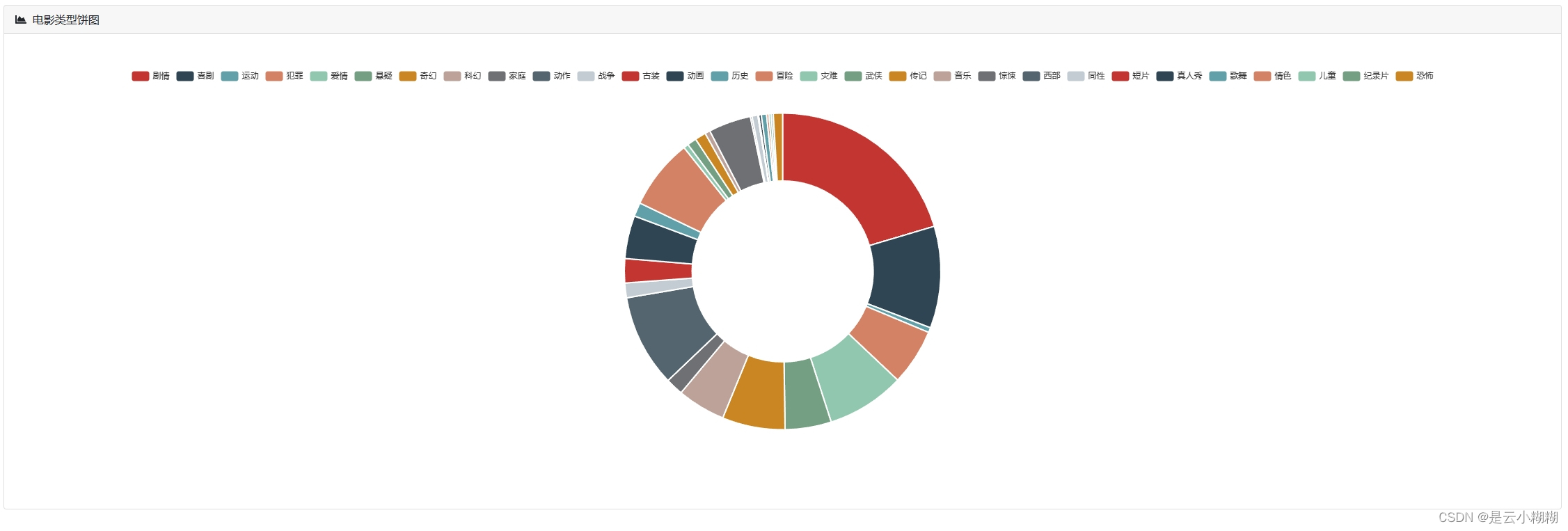
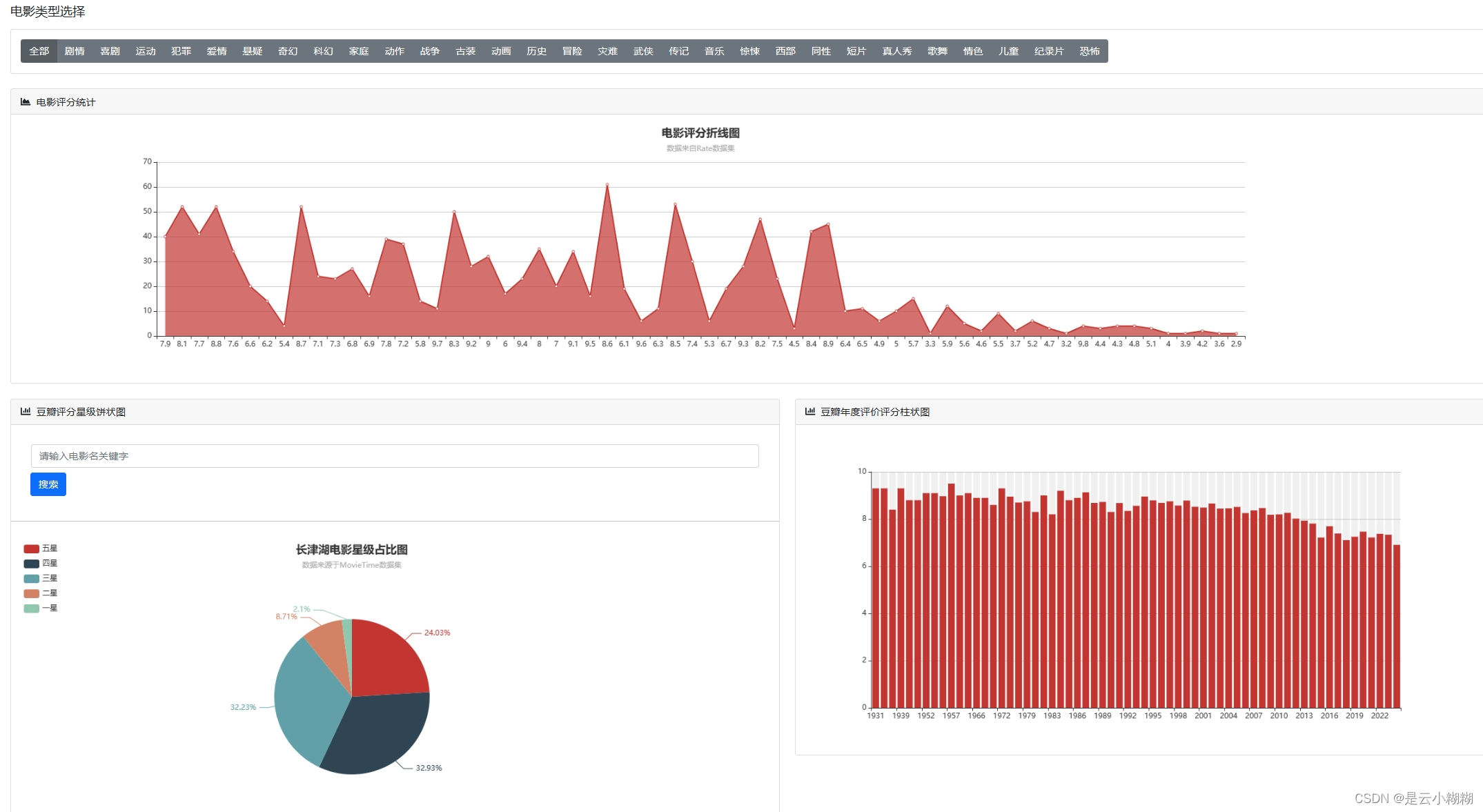
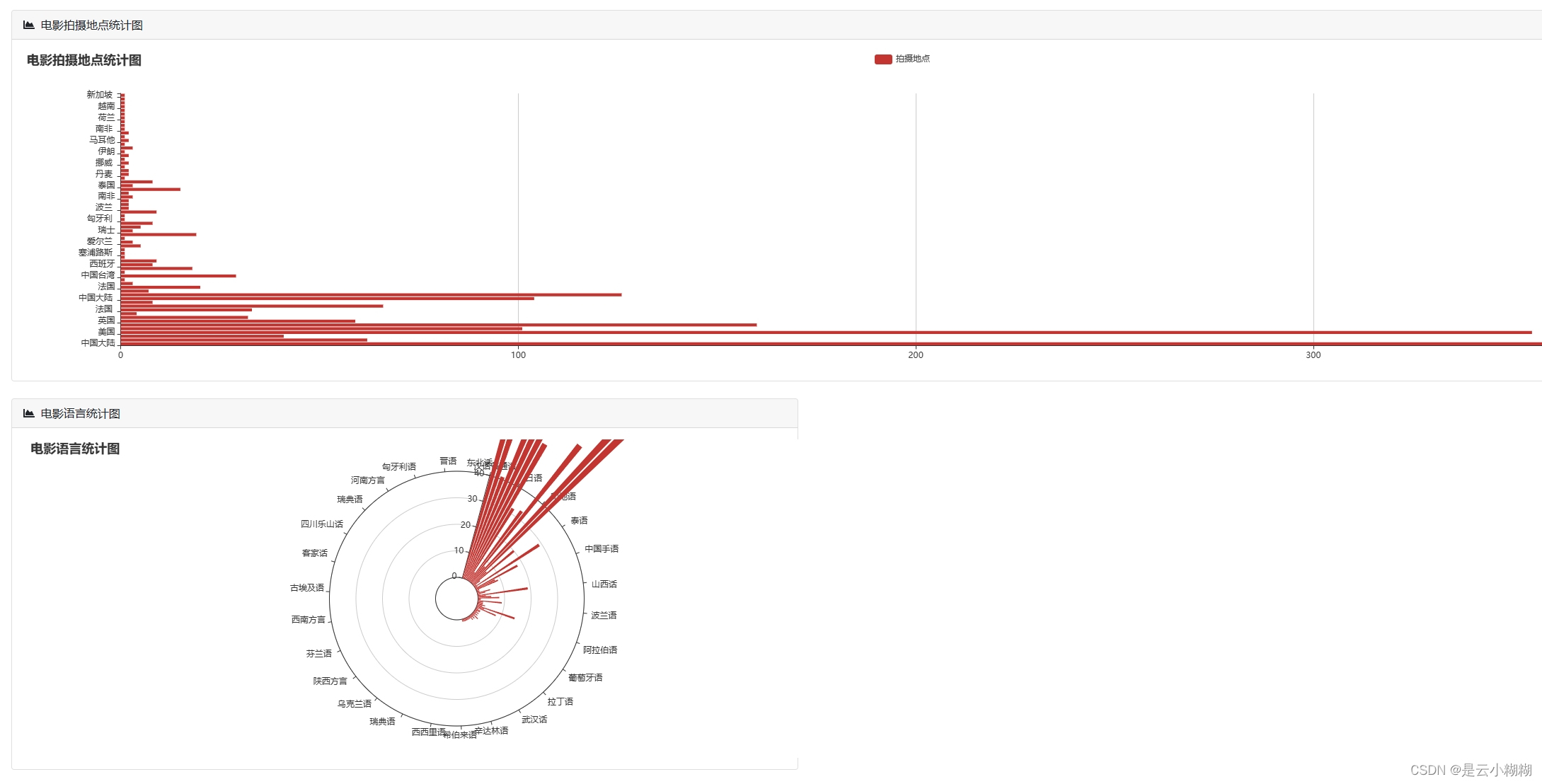
在大数据与人工智能技术蓬勃发展的背景下,我们精心打造了一款基于Python的豆瓣电影数据分析与可视化系统,致力于为电影爱好者与专业人士提供全方位、个性化的观影服务体验。现今,人们对电影欣赏的需求已超越单一的娱乐诉求,转而追求个性化推荐、深度解读及社区互动的综合体验。 该系统构筑了涵盖数据采集、数据概览、电影检索、数据管理、词云分析及多维可视化六大支柱的立体服务矩阵。首先,系统从豆瓣电影平台抓取包括影片详情、评分、评论、标签等在内的丰富信息,确保数据获取的针对性与合规性。 系统对所采集的电影数据进行整合与梳理,生成简洁明了的数据概览报告,概述整体数据集的特征,如平均评分、热门类型、高分导演与演员等关键指标。同时,用户可利用强大且灵活的查询功能,依据影片名称、关键词、导演、演员、类型、上映年份等多维度条件,快速定位感兴趣的内容。 平台提供电影数据的精细化管理功能,用户可对已获取的数据进行编辑操作,便于个性化整理与长期跟踪。此外,系统引入词云图这一可视化工具,生动呈现电影标题、演员、评分、简介等文本数据中的高频词汇与主题热点,直观揭示观众关注焦点与市场趋势。 系统集成了一系列深度可视化的组件,对电影数据进行全方位、多层次的解析与展示如时间序列分析、地理分析、类型分析、导演与演员分析等 通过整合Python的Flask框架、MySQL数据库以及NumPy、Pandas、Matplotlib等数据分析与可视化库,我们的豆瓣电影数据分析与可视化系统不仅具备强大的数据处理与分析能力,还能够为用户提供流畅、直观且富有洞察力的交互体验,让电影爱好者与专业人士在轻松的浏览过程中,深度感知电影市场的脉动与趋势。 综上所述,基于Python的豆瓣电影数据分析与可视化系统,凭借数据采集、数据概览、电影查询、数据管理、词云图展示以多维度可视化分析,构建了一个满足用户个性化需求、促进深度参与的电影数据探索平台。无论是资深影迷还是偶尔观影的大众用户,都能在这个系统中发掘电影世界的新视角,深化对电影艺术与市场的认知。 二、开发环境 开发环境版本/工具PYTHON3.6.8开发工具PyCharm操作系统Windows 10内存要求8GB 以上浏览器Firefox (推荐)、Google Chrome (推荐)、Edge数据库MySQL 8.0 (推荐)数据库工具Navicat Premium 15 (推荐)项目框架FLASK 三、项目技术后端:Flask、PyMySQL、MySQL、urllib 前端:Jinja2、Jquery、Ajax、layui 四、功能结构数据采集:利用Python编程技术对抓取豆瓣电影数据,包括影片基本信息(如标题、年份、类型)、主创团队、评分、评论、简介等多元信息。 数据概览:收集的电影数据经过清洗、整合后,平台自动生成详尽的数据概览报告,包括但不限于最高评分、评分折线图、最受欢迎类型、电影种类数、热门演员等统计摘要。这些概览有助于用户快速理解数据集的整体特征与市场趋势。 信息检索:平台提供用户友好的搜索接口,支持用户根据影片名称、关键词条件进行精确或模糊查询,迅速定位目标电影及相关信息,满足个性化研究与兴趣探索需求。 数据管理:对已获取的电影数据进行删除功能,以及对电影的图片、主演等属性的管理。 词云分析:平台运用词云图技术,动态展示电影标题、演员、评分、简介等文本数据中的高频词汇,直观呈现热门话题、明星影响力、观众情感倾向等文本特征。 数据可视化:平台搭载丰富多样的可视化图表,对电影数据进行深度解析。 时间分析:通过折线图展示历年电影产量统计随年份的变化趋势;通过饼状图展示电影数据时长分布占比。 评分分析:通过选择不同的类型,展示该类型电影评分统计;豆瓣年度评价评分柱状图;豆瓣电影中外评分分布图;不同的电影豆瓣评分星级饼状图 地图分析:通过柱状图展示电影拍摄地点统计,通过饼状图展示电影语言统计 类型分析:通过饼图展示各电影类型在总数据中的占比。 导演与演员分析:通过柱状图展示导演作品数量前20,通过折线图展示演员参演排名前20 项目论文结构图如下所示 登录首页: 功能菜单: 首页可视化: 信息检索: 数据管理: 数据可视化: 词云分析:
检索模块的实现 @app.route("/search/",methods=['GET','POST']) def search(searchId): email = session['email'] allData = getAllData() data = [] if requesthod == 'GET': if searchId == 0: return render_template( 'search.html', idData=data, email=email ) for i in allData: if i[0] == searchId: data.append(i) return render_template( 'search.html', data=data, email=email ) else: searchWord = dict(request.form)['searchIpt'] def filter_fn(item): if item[3].find(searchWord) == -1: return False else: return True data = list(filter(filter_fn,allData)) return render_template( 'search.html', data=data, email=email )评分可视化的实现 @app.route("/time_t",methods=['GET','POST']) def time_t(): email = session['email'] row,column = getTimeList() moveTimeData = getMovieTimeList() return render_template( 'time_t.html', email=email, row=list(row), column=list(column), moveTimeData=moveTimeData )评分选择类型的实现 @app.route("/rate_t/",methods=['GET','POST']) def rate_t(type): email = session['email'] typeAll = getTypesAll() rows,columns = getMean() x,y,y1 = getCountryRating() if type == 'all': row, column = getRate_t() else: row,column = getRate_tType(type) if requesthod == 'GET': starts,movieName = getStart('长津湖') else: searchWord = dict(request.form)['searchIpt'] starts,movieName = getStart(searchWord) return render_template( 'rate_t.html', email=email, typeAll=typeAll, type=type, row=list(row), column=list(column), starts=starts, movieName=movieName, rows = rows, columns = columns, x=x, y=y, y1=y1 ) 七、数据库设计表名:comments 字段名称数据类型是否必填注释idint是评论idmovieNamevarchar否电影名字commentContentvarchar否电影评论表名:movie 字段名称数据类型是否必填注释idint是电影iddirectorsvarchar导演名yearvarchar年份typesvarchar类型countryvarchar国家langvarchar语言timevarchar上映时间moveiTimevarchar时长comment_lenvarchar评论人数startsvarchar不同评级summaryvarchar简介commentstext评论imgListvarchar图片链接movieUrlvarchar视频链接detailLinkvarchar详细链接字段名称数据类型是否必填注释idint(11)是留言contentlongtext否留言内容contactvarchar(255)否联系方式namevarchar(255)否称呼create_timedatetime否留言时间statusint(11)否状态(0未处理,1已处理)表名:user 字段名称数据类型是否必填注释idint是评论idmovieNamevarchar否电影名字commentContentvarchar否电影评论 八、源码获取源码、安装教程文档、项目简介文档以及其它相关文档已经上传到是云猿实战官网,可以通过下面官网进行获取项目! |

 注册页面:
注册页面: 


【本文地址】