自动化测试 |
您所在的位置:网站首页 › 谷歌浏览器审查元素前的对勾取消 › 自动化测试 |
自动化测试
|
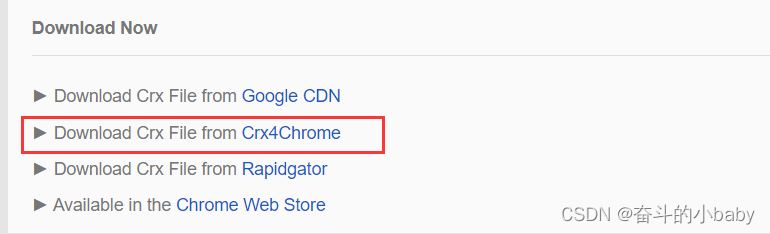
自动化测试就是用程序(脚本)测试程序 安装Selenium IDE1.使用谷歌安装,下载地址:Download Selenium IDE 3.17.2 CRX File for Chrome - Crx4Chrome
2. 直接打开谷歌浏览器,打开右上角扩展程序,手动将下载的crx文件拖到页面上
3.点击图标即可运行
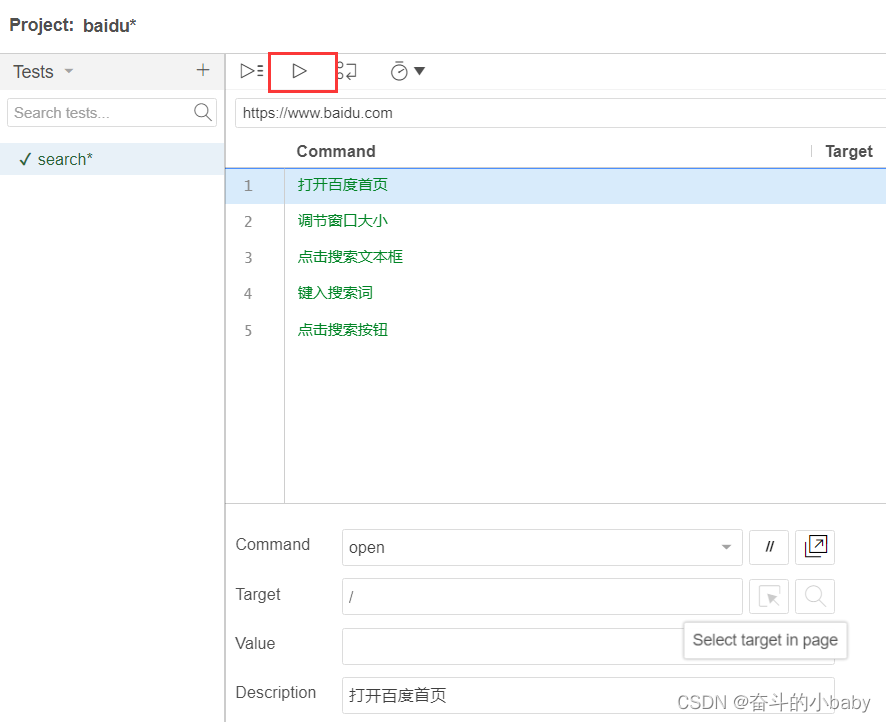
1.在新项目中记录新测试
2.测试名称
3. 录制好屏幕后,添加功能名称 4.创建好项目后,可添加对应步骤描述,然后点击运行
可以将多余的步骤删除:
5.一个完整的测试用例,应该包括:步骤(command、 target.、value) 、断言(预期和 实际对此)。 添加断言: 1)点击空白行
2)添加内容: 在Command处选择assert text 选项;在Target处使用选择目标箭头在页面上选择元素在页面上复制预期的某个结果添加描述
注:以下第一个按钮是选择目标箭头(执行一遍程序后才能使用此项),第二个按钮是将选择的目标重新定位在页面中。
6.添加好断言后,重新运行程序,如果程序通过,则断言文本文字变成绿色:
如果程序未通过,则断言文本文字变成红色:
断言要求:不需要多,一个就够了,只要能够唯一确定你的脚本是通过的即可。 安装kataon1.使用谷歌安装,下载地址:Download Katalon Recorder 5.9.0 CRX File for Chrome - Crx4Chrome
2. 直接打开谷歌浏览器,打开右上角扩展程序,手动将下载的crx文件拖到页面上
3.点击图标可运行
1.创建测试用例
2.点击Record录制屏幕
3.添加断言(需要先执行一遍程序)
使用以下按钮选择Target
如果测试通过,断言文本文字变成绿色:
如果测试未通过,断言文本文字变成红色:
3.导出文件
选择以下选项
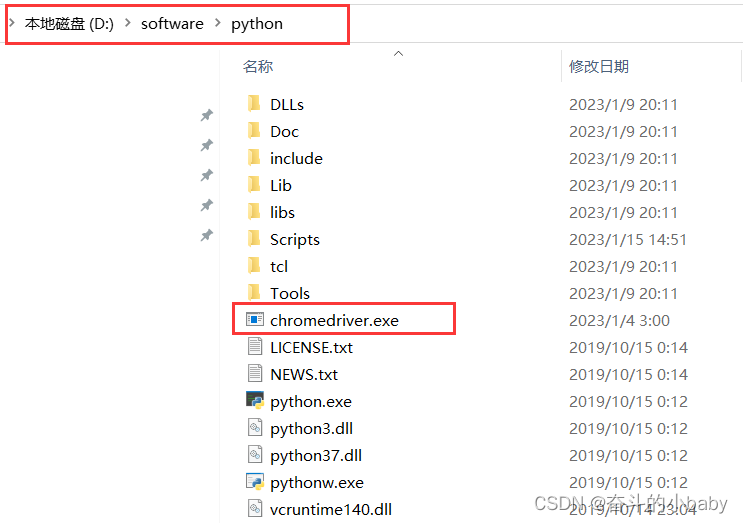
1.安装selenium(在pycharm中安装): 1)检测python位置:where python 2)安装:pip3 install selenium 2.下载chromeDriver驱动:https://chromedriver.chromium.org/ 选择接近谷歌版本的chromeDriver: 选择对应操作系统的下载:
将下载的文件解压后放在python安装目录:
第一个自动化脚本 ''' 需求:百度文本框输入selenium . 点击百度一下 1、百度文本框 2、百度一下 使用ID属性定位: 1、确定要操作的对象 2、获取id属性(kw\su) 3、其他操作 ''' # 导包 from selenium import webdriver import time from selenium.webdriver.common.by import By # 创建浏览器对象 driver = webdriver.Chrome() # 打开百度首页 driver.get("https://www.baidu.com") # 在搜索框输入关键字selenium driver.find_element(By.ID, "kw").send_keys("selenium") # 时间延迟两秒 time.sleep(2) # 点击搜索按钮 driver.find_element(By.ID, "su").click() time.sleep(2) # 关闭浏览器 driver.quit() webdriver api学习 定位元素的方式 from selenium.webdriver.common.by import By # 1.使用id定位 find_element(By.ID,"kw") # 2.使用name定位 find_element(By.NAME,"wd") # 3.使用class定位 find_element(By.CLASS_NAME,"s_ipt") # 4.使用标签定位 find_element(By.TAG_NAME,"input") # 5.使用link_text定位 find_element(By.LINK_TEXT,"新闻") # 6.使用partial_link_text定位 find_element(By.PARTIAL_LINK_TEXT,"新") # 7.通过XPATH定位 # 1)使用绝对路径:从根节点(html)开始从上往下找,同一层级相同标签用排名表示,如div[1]、div[2],第一个标签可不用排名,直接写div。 driver.find_element(By.XPATH, '/html/body/div/div/div[5]/div/div/form/span/input').send_keys("selenium") # 2)利用元素属性定位:固定格式://input[@] driver.find_element(By.XPATH, '//input[@name="wd"]').send_keys('selenium') # 3)利用父子关系以及元素属性定位 # * 表示所有 不确定是什么标签的时候使用 # driver.find_element(By.XPATH, '//*[@id="form"]/span/input').send_keys('selenium') # 确定了标签就直接写标签名 # driver.find_element(By.XPATH, '//form[@id="form"]/span/input').send_keys('selenium') # 4)使用逻辑运算符以及元素属性定位 使用and或or # driver.find_element(By.XPATH, '//input[@id="kw" and @name="wd"]').send_keys('selenium') driver.find_element(By.XPATH, "//input[@id='kw' or @name='wd']").send_keys('selenium') # 8.使用css定位 find_element(By.CSS_SELECTOR,"span.bg s_btn_wr>input#su")css定位说明 选择器: . 类选择器# id选择器* 通配符选择器tag 标签选择器> 儿子选择器+ 兄弟选择器[name='kw'] 属性选择器CSS与XPATH的类似功能对比:
1. clear() 清除文本。 # 定位百度搜索框 driver.find_element(By.ID, "kw").send_keys("selenium") # 清楚百度搜索框 driver.find_element(By.ID, 'kw').clear() # 点击搜索按钮 driver.find_element(By.ID, 'su').click()2. send_keys (value) 模拟按键输入。 3. click() 单击元素。例如按钮操作。 4.current_url 返回当前页面的url地址,用来做断言,判断是否符合预期结果。 # 导包 from selenium import webdriver import time from selenium.webdriver.common.by import By # 创建浏览器对象,并打开百度首页 driver = webdriver.Chrome() driver.get("https://www.baidu.com") # 点击百度首页上的新闻按钮,要获取跳转后页面的url地址,并且判断是否符合预期结果 driver.find_element(By.LINK_TEXT, '新闻').click() # 新闻跳转后会重新打开一个页面,需要增加一条语句 driver.switch_to.window((driver.window_handles[1])) # 获取跳转后新闻页的url url = driver.current_url print(url) # https://news.baidu.com/ # 添加断言 if url == 'https://news.baidu.com/': print('跳转成功') else: print('跳转失败') # 关闭浏览器 time.sleep(3) driver.quit()5. title 返回当前页面的title。 # 获取跳转页面后的title title = driver.title print(title) # 百度新闻——海量中文资讯平台6. text 获取页面(提示框、警告框)显示的文本 # 获取百度首页文本:换一换 txt = driver.find_element(By.XPATH, '//*[@id="hotsearch-refresh-btn"]/span').text print(txt) # 换一换7. get_attribute() 获得属性值,文本框中的值使用value属性名。 # 获取百度输入框的name和class # value1 = driver.find_element(By.ID, 'kw').get_attribute('name') # print(value1) # wd value1 = driver.find_element(By.ID, 'kw').get_attribute('class') print(value1) # s_ipt # 获取百度输入框的值 value2 = driver.find_element(By.ID, 'kw').get_attribute('value') print(value2) # 1238. is_displayed() 判断该元素是否可见;is_enabled() 判断元素是否可用;is_selected() 判断是否选中,一般用复选框或者单选框的判断。 # 判断百度首页是否有搜索按钮 res = driver.find_element(By.ID, 'su').is_displayed() print(res) # True # 判断百度首页搜索按钮是否可用 res = driver.find_element(By.ID, 'su').is_enabled() print(res) # True 浏览器操作1.控制浏览器窗口大小 # 设置打开的窗口为1920*600 driver.set_window_size(1920, 600) # 最大化显示窗口 driver.maximize_window() # 最小化窗口 driver.minimize_window()2.控制浏览器前进、后退 # 点击百度首页的新闻 driver.find_element(By.LINK_TEXT, '新闻').click() driver.switch_to.window((driver.window_handles[1])) time.sleep(2) # 后退到首页 driver.back() time.sleep(2) # 又前进到新闻页 driver.forward() time.sleep(2)说明:句柄 driver.switch_to.window((driver.window_handles[1])) 只要打开新窗口,就需要添加对应窗口的句柄。所有句柄是一个列表,需要取对应窗口句柄值就使用下标取值。 获取句柄:driver.window_handles 绑定句柄到对应窗口:driver.switch_to.window 3.刷新页面 driver.refresh()4.屏幕截屏 driver.find_element(By.LINK_TEXT, '新闻').click() # 新闻跳转后会重新打开一个页面,需要增加一条语句 driver.switch_to.window((driver.window_handles[1])) # 跳转到新闻页后截屏 三种方式 # driver.save_screenshot(r"D:\software-test\auto_test\news.png") # driver.get_screenshot_as_file(r"D:\software-test\auto_test\news1.png") driver.get_screenshot_as_file("{}.{}".format(r'D:\software-test\auto_test\news3', 'png'))说明: print("{ }.{ }".format(1, 2) // 1.2 { }.{ } 表示格式,. 表示拼接符,format 里面的参数表示数据,会一一对应到{ }中。 5.关闭浏览器 # 不管有几个窗口,都会关闭 # driver.quit() # 只关闭一个窗口,第一个 driver.close() 鼠标操作导包:from selenium.webdriver.common.action_chains import ActionChains perform(): 执行所有ActionChains中存储的行为,常见方法: 1.context_click() 右击 2.double_click() 双击 3.drag_and_drop() 拖动 4.move_to_element() 鼠标悬停 # move_to_element 鼠标悬浮 # context_click(txt) 鼠标右击 # 导包 from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.action_chains import ActionChains import time # 创建浏览器对象,并打开百度首页 driver = webdriver.Chrome() driver.get("https://www.baidu.com") time.sleep(3) driver.maximize_window() # 将鼠标悬浮到百度首页文本“设置”上 setBtn = driver.find_element(By.XPATH, '//*[@id="s-usersetting-top"]') ActionChains(driver).move_to_element(setBtn).perform() time.sleep(3) # 在百度文本框中鼠标右键 txt = driver.find_element(By.ID, 'kw') ActionChains(driver).context_click(txt).perform() driver.quit() 键盘操作导包:from selenium.webdriver.common.keys import Keys 1.send_keys(Keys.Back_SPACE) 删除键 2.send_keys(Keys.SPACE) 空格键 3.send_keys(Keys.TAB) 制表键 4.send_keys(Keys.ESCAPE) esc键 5.send_keys(Keys.ENTER) 回车4.键 6.send_keys(Keys.CONTROL , 'a’) 全选 7.end_keys(Keys.CONTROL, 'c') 复制 8.send_keys(Keys.CONTROL, ' x’) 剪切 9.send_keys(keys.CONTROL, 'v’) 粘贴 ''' 键盘事件案例: 1、百度搜索框输入“seleniumm” 2、删除多输入的m 3、再输入" 教程” 4、ctrl+a,全选文本框内容 5、 ctrl+x,剪切选择的内容 6、ctrl+v。粘贴复制的内容 7、回车代替单击,完成搜索 8、退出浏览器 ''' # 导包 from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys import time # 创建浏览器对象,并打开百度首页 driver = webdriver.Chrome() driver.get("https://www.baidu.com") # 1、百度搜索框输入“seleniumm” driver.find_element(By.ID, 'kw').send_keys('seleniumm') time.sleep(1) # 2、删除多输入的m driver.find_element(By.ID, 'kw').send_keys(Keys.BACK_SPACE) time.sleep(1) # 3、再输入 " 教程” ,再次输入字符串是拼接,而不是覆盖!! driver.find_element(By.ID, 'kw').send_keys(' 教程') time.sleep(1) # 4、ctrl + a,全选文本框内容 driver.find_element(By.ID, 'kw').send_keys(Keys.CONTROL, 'a') time.sleep(1) # 5、 ctrl + x,剪切选择的内容 driver.find_element(By.ID, 'kw').send_keys(Keys.CONTROL, 'x') time.sleep(1) # 6、ctrl + v 粘贴复制的内容 driver.find_element(By.ID, 'kw').send_keys(Keys.CONTROL, 'v') time.sleep(1) # 7、回车代替单击,完成搜索 driver.find_element(By.ID, 'kw').send_keys(Keys.ENTER) time.sleep(1) # 8、退出浏览器 driver.quit() 警告窗口处理在WebDriver中处理JavaScript所生成的alert、confirm、prompt,具体做法是使用switch to.alert。 方法定位到 alert/confirm/prompt后,可以使用: text 获取 alert/confirm/prompt 中的文字信息。accept() 接受现有警告框。dismiss() 放弃现有警告框。send_keys(keysToSend) 发送文本至警告框。 # 导包 from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.action_chains import ActionChains import time # 创建浏览器对象,并打开百度首页 driver = webdriver.Chrome() driver.get("https://www.baidu.com") driver.maximize_window() # 定位到文本”设置“ set = driver.find_element(By.XPATH, '//*[@id="s-usersetting-top"]') # 鼠标移动到“设置”上,显示下拉框,目的是将文本“搜索设置”显示出来 ActionChains(driver).move_to_element(set).perform() time.sleep(2) # 点击“搜索设置” ,操作元素之前,必须先使元素显示出来!! driver.find_element(By.XPATH, '//*[@id="s-user-setting-menu"]/div/a[1]/span').click() time.sleep(2) # 点击保存设置按钮 driver.find_element(By.XPATH, '//*[@id="se-setting-7"]/a[2]').click() time.sleep(2) # 将弹框交给浏览器 dd = driver.switch_to.alert # 获取弹框文本信息 txt = dd.text print(txt) # 已经记录下您的使用偏好 # 确认弹框 dd.accept() # 放弃弹框 # dd.dismiss() driver.quit()注:操作元素之前,必须先使元素显示出来!! 多表单处理在Web应用中经常会遇到 frame/iframe 表单嵌套页面的应用,WebDriver 对于 frame/iframe 表单内嵌页面上的元素无法直接定位。就需要通过switch_to.frame() 方法将当前定位的主体切换为 frame/iframe 表单的内嵌页面中。 有两种解决方式: 默认可以给iframe标签的id或name可以传参iframe的元素对象 ''' 多表单〔在一个窗口上) : 在一个页而中可以嵌套另外一个页面,如frame/iframe技术,这是现在很多web应用中使用的一种方式, webdriver对象只能在页画〈外层是默认的)中定位元素, 需要一种方式将driver对象从外层切换给内层使用才能对内层的对象进行处理。 webdriver中提俱APi: driver.switch_to.frame(实现 案例: 1.打开腾讯首页: http://www.qq.com 2.点击部箱图标; 3.输入用户名: 4.输入密码; 5.点击登录; 6.关闭浏览器。 ''' # 导包 from selenium import webdriver from selenium.webdriver.common.by import By import time # 创建浏览器对象,并打开腾讯qq首页 driver = webdriver.Chrome() driver.get('https://www.qq.com') driver.maximize_window() time.sleep(2) #2.点击邮箱图标,跳转到登录界面(新窗口); driver.find_element(By.XPATH, '//*[@id="top-login"]/div[2]/a').click() driver.switch_to.window(driver.window_handles[1]) # 句柄 time.sleep(2) # 3.输入用户名: # 先切换到账号密码登录 不能定位到该文本,涉及到多表单的处理,使用driver.switch_to.frame()解决 # 第一种方式:默认可以给iframe标签的id或name # driver.switch_to.frame('login_frame') # 第二种方式,可以传参iframe的元素对象 obj = driver.find_element(By.XPATH, '//*[@id="login_frame"]') driver.switch_to.frame(obj) # 定位文本“账号密码登录” driver.find_element(By.XPATH, '//*[@id="switcher_plogin"]').click() # 输入用户名 driver.find_element(By.XPATH, '//*[@id="u"]').send_keys('3600262327') # 4.输入密码; driver.find_element(By.XPATH, '//*[@id="p"]').send_keys('123456') time.sleep(2) # 5.点击登录; driver.find_element(By.XPATH, '//*[@id="login_button"]').click() time.sleep(2) # 6.关闭浏览器。 driver.quit() 元素等待如今很多web都在使用AJAX技术,运用这种技术的软件当浏览器加载页面时,页面上的元素可能不会被同步加载完成,因此,webDriver提供了三种元素等待方式 1.强制等待(休眠): time.sleep(2)。直接让线程休眠。 2.隐式等待:driver.implicity_wait(2)。在脚本创建driver对象之后,给driver设置一个全局的等待时间,对driver的整个生命周期(创建到关闭)都起效,所有元素都等待。如果在设置等待时间(超时时间)内,定位到了页面元素,则不再等待,继续执行下面的代码。如果超出了等待时间,则抛出异常。 方法: webDriverwait(driver,timeput, poll_frequency=0.5,ignored_exceptions=None),第二个参数:超时时间;第三个参数:频率,即多长时间刷新一次;第四个参数:默认值。util(method ,info): 直到满足某一个条件,返回结果,等不到就抛错until(EC.presence_of_element_located(locator)) 判断某个元素是否定位到了 ;locator-->By.ID, By.NAME from selenium import webdriver driver = webdriver.Chrome() driver.implicitly_wait(10) # 等待十秒3.显示等待:就是明确的要等到某个元素的出现或者是某个元素的可点击等条件,等不到,就一直等,除非在规定的时间之内都没找到,那么就跳出Exception。(简而言之,就是直到元素出现才去操作,如果超时则报异常) 注意: 若同时设置了隐式等待和显示等待,则以隐式等待为第一优先级,也就是说,若隐式等待时间大于显示等待,显示等待时间设置无效,因为driver若找不到元素,会先等待隐式等待的时间。对time.sleep()没有影响。只要执行到这句代码,就会等待。 # 导包 from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By import time driver = webdriver.Chrome() driver.get('https://www.baidu.com') # 隐式等待 # driver.implicitly_wait(10) # 等待十秒 # 显示等待 ''' WebDriverWait(driver, 10, 0.5, ignored_exceptions=None) util(method ,info): 直到满足某一个条件,返回结果,等不到就抛错 until(EC.presence_of_element_located(locator)) 判断某个元素是否定位到了 locator-->By.ID, By.NAME 需求: 使用显示等待的方式去等百度首页的百度一下按钮显示出来, 如果出来就点击,否则print() ''' searchBtn = WebDriverWait(driver, 10, 0.5, ignored_exceptions=None).until(EC.presence_of_element_located((By.ID, 'kw')), '报错') if searchBtn: searchBtn.send_keys('selenium') time.sleep(2) else: print(searchBtn) time.sleep(2) driver.quit()
|



 3.添加url,然后点击START RECORDING按钮开始录制屏幕
3.添加url,然后点击START RECORDING按钮开始录制屏幕

















【本文地址】
今日新闻 |
推荐新闻 |