数据结构Huffman树及赫夫曼(哈夫曼)编码的C语言实现 |
您所在的位置:网站首页 › 读取文件中的字符,统计其英文字母个数 › 数据结构Huffman树及赫夫曼(哈夫曼)编码的C语言实现 |
数据结构Huffman树及赫夫曼(哈夫曼)编码的C语言实现
|
实验要求
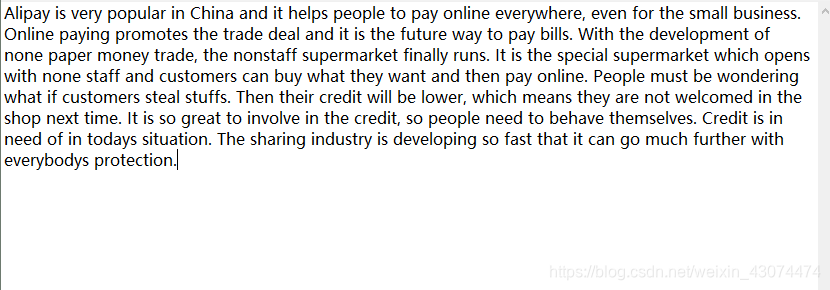
1.输入一段100~200字的英文短文,存入一文件a中。 2.写函数统计短文出现的字母个数n及每个字母出现的次数。 3.写函数以字母出现的次数作权值,建Haffman树(n个叶子),给出每个字母的Huffman编码。 4.用每个字母编码对原短文进行编码,码文存入文件b中。 5.用Huffman树对b中码文进行译码,结果存入文件c中,比较a,c是否一致,以检验编码、译码的正确性。 程序分析●从实验要求中可以看到,此程序需要涉及到文件的读和写操作。读操作用fgetc函数实现,写操作用fputc函数实现。 ●在程序中定义一个字符数组,此数组用来存储文章中所有可能出现的字符。再定义一个整形数组,此数组用来存储每个字符在文章中出现的次数。字符数组的下标与整形数组的下标一一对应。比如说字符数组character[0] == ‘a’,字符’a’在数组中的下标为0,那么每当从文章中读出的字符是’a’时,相应的整型数组第零个元char_freque[0]自加,如果当文件读到末尾时,发现文章中一共有5个字符’a’,那么char_freque[0]的值就应该是5。 ●统计总共出现过多少个不同的字符n(因为文章比较短,可能会有个别字母未在文章中出现),统计过程就是对数组char_freque遍历,当发现数组元素的值不为0时,就让n自加(n的初值为0)。 ●每一个结点用结构体定义,里面包含此结点的权值weight,父结点parent,左孩子lchild,右孩子rchild。 ●可以证明,对于有n个叶子结点的Huffman树,一共需要m = (2 * n - 1)个结点。动态分配m+1个结点类型的存储空间,首地址赋值给节点类型的指针HT,之所以不分配m个,是因为数组下标为0的结点不使用。再动态分配n + 1个字符型数据的存储空间(同理。第0号元素不使用),首地址给字符型指针ture_form,用来存储在文章中实际出现过的字符。 ●初始化树的每一个结点。数组下标为1到n的这n个节点用来表示叶子结点,他们的权值为n个字符出现的次数。也就是说把数组char_freque中n个不为0的元素分别赋值给前n个节点的weight。除这n个节点之外的其余m - n个节点的weight都为0,所有节点的parent,lchild,rchild都为0。在此函数中,同时初始化ture_form数组。初始化原则如下: 若第i个叶子结点的weight是由数组char_freque中的第j个元素来初始化的,则说明第i个节点对应的字符为character[j],那么就把character[j]赋值给ture_form[i]。比如说HT[5].weight = char_freque[7],下一条语句应该执行ture_form[5] = character[7]。 ●由m个结点创建哈夫曼树。创建的过程实际上是把n个叶子结点的parent赋上值,其余m-n个结点的lchild、rchild和parent(根结点除外,根结点parent为0)赋上值。假设现在正处理第i个节点(i从n+1开始),那么需要从前i - 1个节点中找parent为0 (parent为0说明此结点为一棵树的根,它可以作为其它结点的孩子结点)且权值最小的两个结点。这两个结点分别作为第i个结点的左右孩子,第i结点则为这两个结点的双亲。当i的值为m之后,整个树就建立起来了,而且第m个结点为此哈夫曼树的根结点。 ●对n个字符进行编码。采用逆序编码的方法,即从叶子结点出发,寻找根结点。例如第i个叶子结点中存储着它的双亲信息,访问第i个叶子节点的双亲p(注:双亲其实就是教材中的父节点,它是一个节点,而不是两个),判断此叶子结点是它双亲结点的左孩子还是右孩子,若为左孩子,则编码为0,右孩子编码为1。下一步继续往上访问,直到访问到根结点结束。这n个字符的编码用一个二维数组(实际上是二重指针进行了内存的分配)TC(Huffman Code的首字母缩写)存储。 ●读取文章,生成此文章的Huffman编码。每读到一个字符,先判断此字符的编码在数组HC中位置,再把编码写入到文件b.txt中。 ●读取编码,进行译码过程。从b.txt文件中读取编码,每次读取一个字符(此字符为0或1),并把此字符存放在一个临时数组中。判断当前数组中的字符是否为有效的Huffman编码,若是,则翻译此编码,并把翻译得到的字符写到文件c.txt中,清空临时数组,继续读取b.txt中的下一个字符。若不是有效编码,则继续读取b.txt中的下一个字符。 程序演示首先在自己创建的工程目录下新建一个名为“a”的文本文档,里面输入一段文章,我输入的文章内容如下: Alipay is very popular in China and it helps people to pay online everywhere, even for the small business. Online paying promotes the trade deal and it is the future way to pay bills. With the development of none paper money trade, the nonstaff supermarket finally runs. It is the special supermarket which opens with none staff and customers can buy what they want and then pay online. People must be wondering what if customers steal stuffs. Then their credit will be lower, which means they are not welcomed in the shop next time. It is so great to involve in the credit, so people need to behave themselves. Credit is in need of in todays situation. The sharing industry is developing so fast that it can go much further with everybodys protection. 文件位置如图所示 ●文章中只能含有52个大小写字母,逗号,空格,句号这55种常用字符。其余的符号太多,我没写进程序中。 ●文章不能太长,因为我默认所有字符的权值不超过2000,Huffman编码长度不超过9位。 ●VS2017编译器可以成功运行此代码,其余编译器未测试。 更新说明●有些电脑会自动在文件的末尾添加一个换行符,因此会出现非法字符的问题。本次更新解决了此问题,只需把文件结束的标志从EOF改为’\n’即可。 ●为了避免a.txt文件加错位置而引发断点,更新后的程序中添加了判断文件是否成功打开的代码,若文件打开失败,则输出提示信息,并退出程序的执行。 ●判断是否在文件末尾自动添加了换行符的方法。 打开a.txt文件,将光标移至文件的末尾,如图所示。 |
 运行程序之后,可以看到多出了两个文件,分别为b和c,查看c文件的内容是否与a文件的内容相同。
运行程序之后,可以看到多出了两个文件,分别为b和c,查看c文件的内容是否与a文件的内容相同。 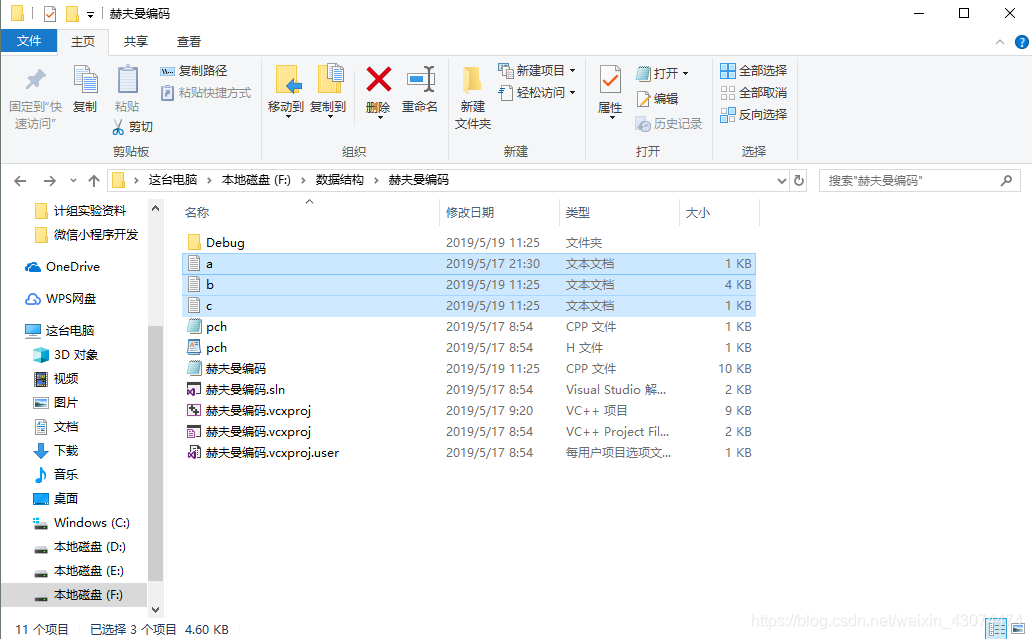
 此时按键盘上的右方向键,若光标的位置能移动到下一行,则说明文件末尾有一个换行符,此时只需按Backspace键即可删除此换行符,删除之后别忘了保存一下。 重要:如果文件末尾有换行符,一定要删去
此时按键盘上的右方向键,若光标的位置能移动到下一行,则说明文件末尾有一个换行符,此时只需按Backspace键即可删除此换行符,删除之后别忘了保存一下。 重要:如果文件末尾有换行符,一定要删去【本文地址】
今日新闻 |
推荐新闻 |