说话人识别中的Temporal pooling(时序池化) |
您所在的位置:网站首页 › 说话结构公式 › 说话人识别中的Temporal pooling(时序池化) |
说话人识别中的Temporal pooling(时序池化)
|
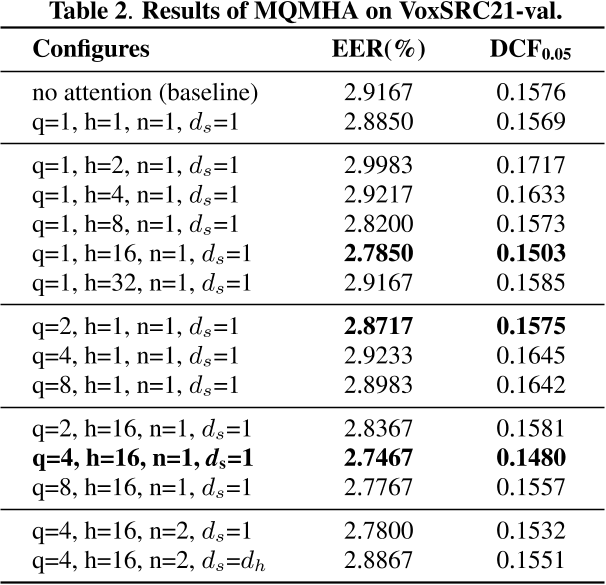
MQMHASTP(Multi-query multi-head attention pooling)是2022年提出的,带有多查询多头注意力的时序池化 输入特征图仍然记为h,假设维度为 ( b s , 5120 , T ) (bs,5120,T) (bs,5120,T) 将h在特征维度上均等划分为 n - h e a d s n \text{-} heads n-heads份,每一份是一个head,上图的 n - h e a d s = 4 n \text{-} heads=4 n-heads=4,也就是得到了h1,h2,h3,h4四个特征图,每个特征图的维度为 ( b s , d h , T ) (bs,d_h,T) (bs,dh,T), d h = 5120 / / n - h e a d s d_h=5120//n \text{-} heads dh=5120//n-heads,实际使用时,输入特征图的特征维度应确保能被 n - h e a d s n \text{-} heads n-heads整除 对h1,h2,h3,h4每个特征图都进行1维卷积,即上图的 W × h + b W\times h+b W×h+b,得到对应的Attention分数a1,a2,a3,a4,这一部分的运算可以重复 n - l a y e r s n \text{-} layers n-layers次 当 n - l a y e r s = 1 n \text{-} layers=1 n-layers=1,1维卷积只进行一次,参数为 ( i n = d h , o u t = d s , k s i z e = 1 ) (in=d_h,out=d_s,ksize=1) (in=dh,out=ds,ksize=1),因此每个Attention分数的维度为 ( b s , d s , T ) (bs,d_s,T) (bs,ds,T),卷积后不接激活函数当 n - l a y e r s = 2 n \text{-} layers=2 n-layers=2,1维卷积进行两次,激活函数进行一次 第一次卷积参数为 ( i n = d h , o u t = d k , k s i z e = 1 ) (in=d_h,out=d_k,ksize=1) (in=dh,out=dk,ksize=1),因此每个Attention分数的维度为 ( b s , d k , T ) (bs,d_k,T) (bs,dk,T),本次卷积会减少特征维度,因此 d k ≤ d h d_k \le d_h dk≤dh,通常取 d k = 64 d_k=64 dk=64接tanh激活函数第二次卷积参数为 ( i n = d k , o u t = d s , k s i z e = 1 ) (in=d_k,out=d_s,ksize=1) (in=dk,out=ds,ksize=1),因此每个Attention分数的维度为 ( b s , d s , T ) (bs,d_s,T) (bs,ds,T) d s = { 1 , 则 A t t e n t i o n 分数,对每个 h e a d 为一个向量,长度等于 T d h , 则 A t t e n t i o n 分数,对每个 h e a d 为一个矩阵,形状等于 ( d h , T ) d_s=\left\{\begin{aligned} &1,则Attention分数,对每个head为一个向量,长度等于T\\ &d_h,则Attention分数,对每个head为一个矩阵,形状等于(d_h,T) \end{aligned}\right. ds={1,则Attention分数,对每个head为一个向量,长度等于Tdh,则Attention分数,对每个head为一个矩阵,形状等于(dh,T)每个Attention分数的形状都为 ( b s , d s , T ) (bs,ds,T) (bs,ds,T),接下来在frame维度,接softmax激活函数,此时Attention分数的每一行,求和都等于1。可以将Attention分数作为权重,计算每个head的Attention均值和标准差,计算公式如下,与上述的ASTP公式类似 μ = ∑ t = 1 T α t h t σ = ∑ t = 1 T α t h t ⊙ h t − μ ⊙ μ \begin{aligned} \mu&=\sum_{t=1}^{T} \alpha_t h_t \\ \sigma&=\sqrt{\sum_{t=1}^{T} \alpha_t h_t \odot h_t-\mu \odot \mu} \end{aligned} μσ=t=1∑Tαtht=t=1∑Tαtht⊙ht−μ⊙μ 每个head的Attention均值和标准差的维度都为 ( b s , d h ) (bs,d_h) (bs,dh),按照head的顺序,交替地将mean和std串联起来,输出维度为 ( b s , n - h e a d s ∗ d h ∗ 2 ) = ( b s , 5120 ∗ 2 ) (bs,n \text{-} heads*d_h*2)=(bs,5120*2) (bs,n-heads∗dh∗2)=(bs,5120∗2) 对于上述的划分head、计算每个head的Attention分数、计算每个head的Attention统计量、串联每个head的Attention统计量,四个步骤,会进行 n - q u e r i e s n \text{-} queries n-queries次,每次的输出维度都是 ( b s , 5120 ∗ 2 ) (bs,5120*2) (bs,5120∗2),因此MQMHASTP的最终输出维度为 ( b s , n - q u e r i e s ∗ n - h e a d s ∗ d h ∗ 2 ) = ( b s , n - q u e r i e s ∗ 5120 ∗ 2 ) (bs,n \text{-} queries*n \text{-} heads*d_h*2)=(bs,n \text{-} queries*5120*2) (bs,n-queries∗n-heads∗dh∗2)=(bs,n-queries∗5120∗2) 关于
n
-
q
u
e
r
i
e
s
,
n
-
h
e
a
d
s
,
n
-
l
a
y
e
r
s
,
d
s
n \text{-} queries,n \text{-} heads,n \text{-} layers,d_s
n-queries,n-heads,n-layers,ds这几个超参数,原论文有给出一些消融实验,如下图所示(
q
,
h
,
n
q,h,n
q,h,n分别为本文所述的
n
-
q
u
e
r
i
e
s
,
n
-
h
e
a
d
s
,
n
-
l
a
y
e
r
s
n \text{-} queries,n \text{-} heads,n \text{-} layers
n-queries,n-heads,n-layers),可供参考 |

【本文地址】