|
文章目录
题目第一问分析完整解析
第二问分析
第三问分析
第四问分析
第五问
题目
校园供水系统是校园公用设施的重要组成部分,学校为了保障校园供水系统的正常运行需要投入大量的人力、物力和财力。随着科学技术的发展,校园内已经普遍使用了智能水表,从而可以获得大量的实时供水系统运行数据。后勤部门希望基于这些数据,通过数学建模和数据挖掘及时发现和解决供水系统中存在的问题,提高校园服务和管理水平。 附件是某校区水表层级关系以及所有水表四个季度的读数(以一定时间为间隔,如15分钟)与相应的用水数据。请利用这些信息和数据,建立数学模型,讨论以下问题:
统计、分析各个水表数据的变化规律,并给出校园内不同功能区(宿舍、教学楼、办公楼、食堂等)的用水特征。结合校区水表层级关系,建立水表数据之间的关系模型,并利用已有数据分析模型误差。输水管网的漏损是一个严重问题。资料显示,在维护良好的公共供水网络中,平均失水在5%左右;而在比较老旧的管网中,失水则会更多。请利用附件提供的数据,建立数学模型,分析该校园供水管网的漏损情况。地下水管暗漏不容易被发现,需要花费大量人力对供水管道的漏损进行检测及定位,如果能够从水表的实时数据及时发现并确定发生漏损的位置,将极为有益。请帮助学校解决这个问题。管网维修需要一定的人工费和材料费,但同时可以降低管网漏损程度。请根据以上结果和你了解的水价及维修成本确定管网漏损的最优维修决策方案。
第一问
统计、分析各个水表数据的变化规律,并给出校园内不同功能区(宿舍、教学楼、办公楼、食堂等)的用水特征。
分析
对数据进行描述性统计,比如缺失值、异常值等缺失值异常值的处理分析不同功能区的特征(可视化)
完整解析
读取数据表:
import pandas as pd
data1=pd.read_excel('附件_一季度.xlsx')
data2=pd.read_excel('附件_二季度.xlsx')
data3=pd.read_excel('附件_三季度.xlsx')
data4=pd.read_excel('附件_四季度.xlsx')
data1
如下:  查看一季度的统计描述: 查看一季度的统计描述:
data1.describe()
如下可以得到一季度的最大值、最小值、平均值等信息 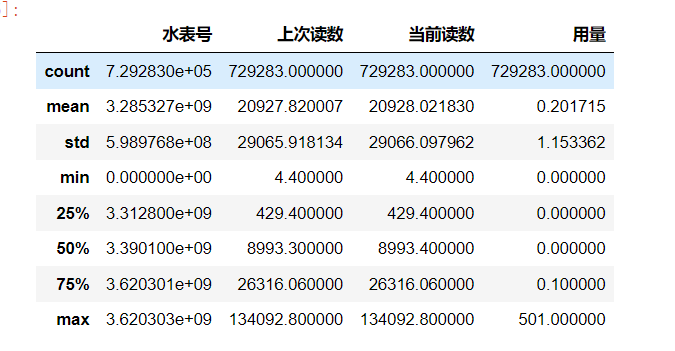
data1.info()
如下: 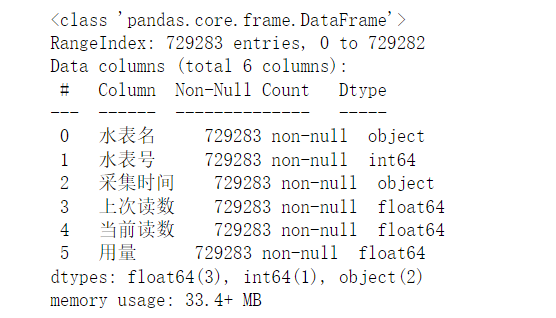 缺失值查看: 缺失值查看:
data1.isnull().sum()
如下:  查看水表名有哪些不同的类型: 查看水表名有哪些不同的类型:
data1['水表名'].unique()
如下:  读取水表层: 读取水表层:
lever_table = pd.read_excel("附件_水表层级.xlsx")
lever_table
如下:  查看水表有哪些不同类型: 查看水表有哪些不同类型:
lever_table['水表名'].unique()
如下:  查看四个季度水表名数量: 查看四个季度水表名数量:  给数据表添加上具体季度更方便观察: 给数据表添加上具体季度更方便观察:
import numpy as np
# 合并数据
data1['季度'] = pd.Series(["一季度" for i in range(len(data1.index))])
data2['季度'] = pd.Series(["二季度" for i in range(len(data2.index))])
data3['季度'] = pd.Series(["三季度" for i in range(len(data3.index))])
data4['季度'] = pd.Series(["四季度" for i in range(len(data4.index))])
data1
如下:  添加合并: 添加合并:
data = data1.append([data2,data3,data4],ignore_index=True) # 添加合并
data
如下:  再查看表数量: 再查看表数量:  按照水表名分类,统计总用量 按照水表名分类,统计总用量
use_water = data.groupby(by='水表名')['用量'].sum() # 按照水表名分类,统计总用量
use_water
如下: 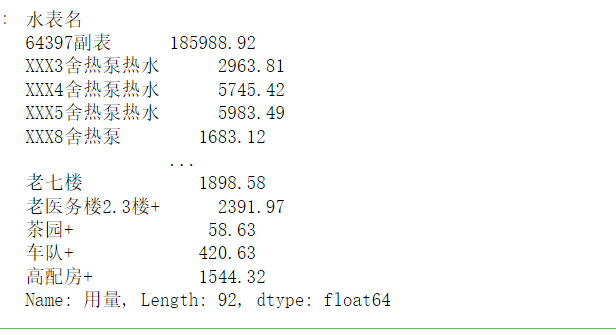 从高到低排序下: 从高到低排序下:
use_water.sort_values(ascending=False)
如下: 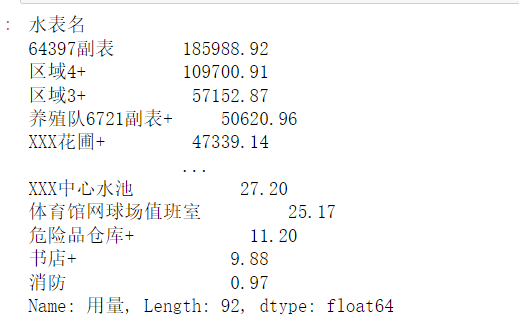 根据使用绘制直方图: 根据使用绘制直方图:
use_water.plot.hist()
如下: 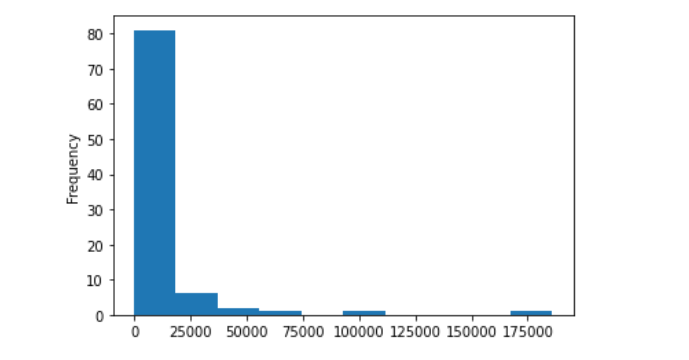 对这些功能区的类型进行分析: 对这些功能区的类型进行分析:
# 全部水表
list_table_name = list(data['水表名'].unique())
# 找到所有学生楼的水表
list_home = []
list_teaching_build = []
list_teacher_build = []
for name in list_table_name.copy():
if name.find("学生宿舍") != -1 or name.find("留学生楼") != -1:
list_home.append(name)
list_table_name.remove(name)
list_home
如下:  同理: 同理:
for name in list_table_name.copy():
if name.find("XX") != -1 and name.find("楼") != -1:
print(name)
list_teaching_build.append(name)
list_table_name.remove(name)
list_teaching_build
如下: 
list_agritural = []
for name in list_table_name.copy():
if name.find("养殖") != -1 or name.find("养鱼") != -1 or name.find("大棚")!=-1 or name.find("花")!=-1:
list_agritural.append(name)
list_table_name.remove(name)
list_agritural
如下: 
for name in list_table_name.copy():
if name.find("楼")!= -1:
list_teaching_build.append(name)
list_table_name.remove(name)
list_table_name
如下:  类型添加上去·: 类型添加上去·:
list_backup = list_table_name
name_list = data['水表名'].tolist()
type_list = []
for name in name_list:
if name in list_backup:
type_list.append("后勤")
elif name in list_agritural:
type_list.append("农业")
elif name in list_home:
type_list.append('宿舍')
elif name in list_teacher_build:
type_list.append("活动地方")
else:
type_list.append('教学楼')
data['类型'] = pd.Series(type_list)
data
如下: 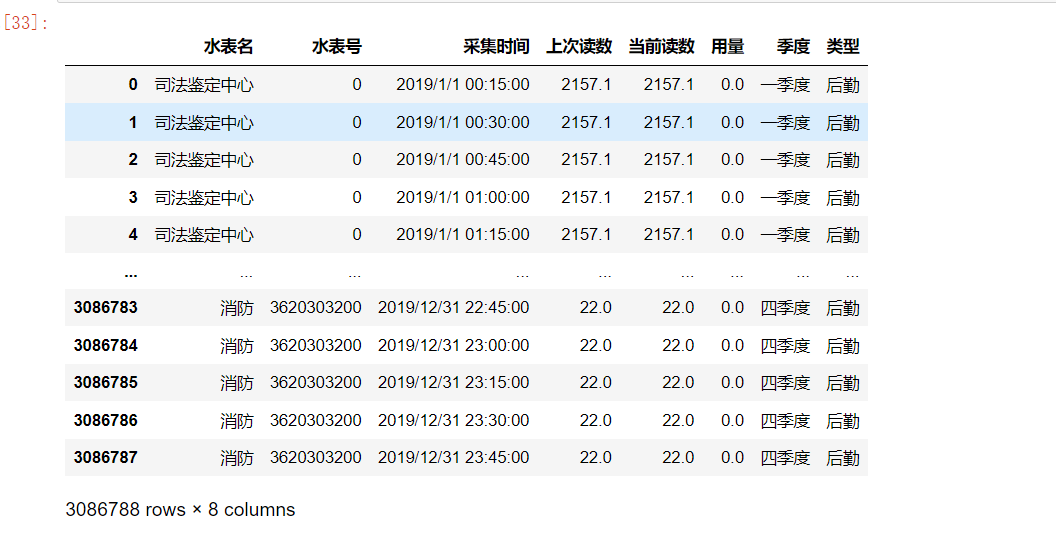 不同类型的用量: 不同类型的用量:
type_sum = data.groupby(by='类型')['用量'].sum()
type_sum
如下: 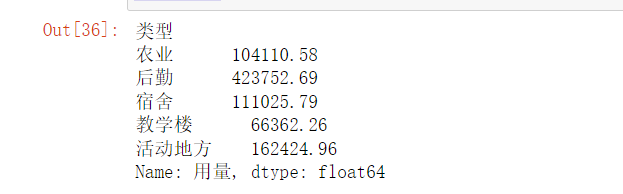 对不同类型可视化: 对不同类型可视化:
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
type_sum.plot.barh(alpha=0.7)
df_group_two = data.groupby(by=['类型'])
from matplotlib import pyplot as plt
i = 0
plt.figure(figsize=(25, 35), dpi=100)
for types ,group in df_group_two:
i += 1
plt.subplot(3,2,i)
group.groupby(by='水表名').sum()["用量"].plot.barh(title=types,color='blue',alpha=.5)
plt.show()
如下:   分析完把合并后的数据保存起来: 分析完把合并后的数据保存起来:
data.to_csv('total.csv',index=False)
按照时间聚合:
data['timeStamp'] = pd.to_datetime(data['采集时间'])
data.set_index("timeStamp", inplace=True)
data_quarter = data.resample("Q") # 时间聚合采样
data_quarter
具体可以参考: 
接下来分析每个季度变化:
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
data_quarter.sum()["用量"].plot.line(style="r*-.",alpha=0.5,title="用水量随着季度变化趋势")
如下: 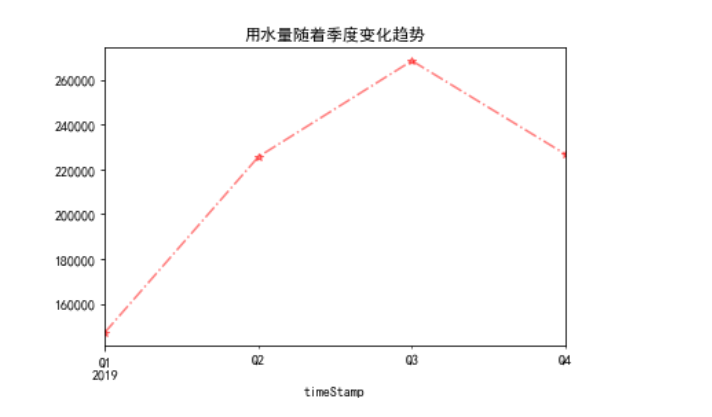 月份变化规律: 月份变化规律:
data_month = data.resample('M').sum()["用量"].plot.line(style="r*-.",alpha=0.5,title="用水量随着月份变化趋势")
如下: 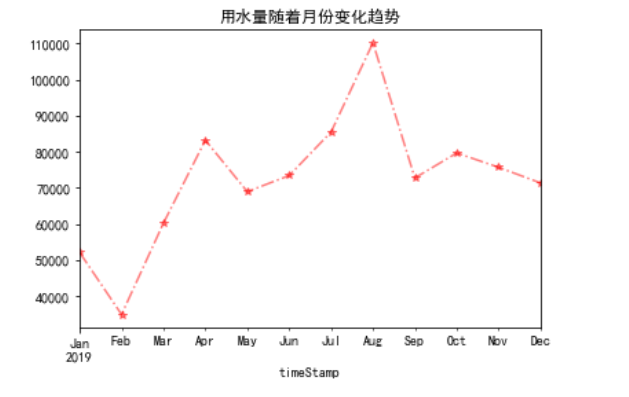 添加具体时间: 添加具体时间:
data['hour'] = pd.to_datetime(data['采集时间']).dt.hour
data['day'] = pd.to_datetime(data['采集时间']).dt.day
data
如下:  用水量一天随着小时变化规律: 用水量一天随着小时变化规律:
data.groupby(by='hour').sum()['用量'].plot.line(style="r*-.",alpha=0.5,title="用水量随着时间变化趋势")
plt.grid()
如下: 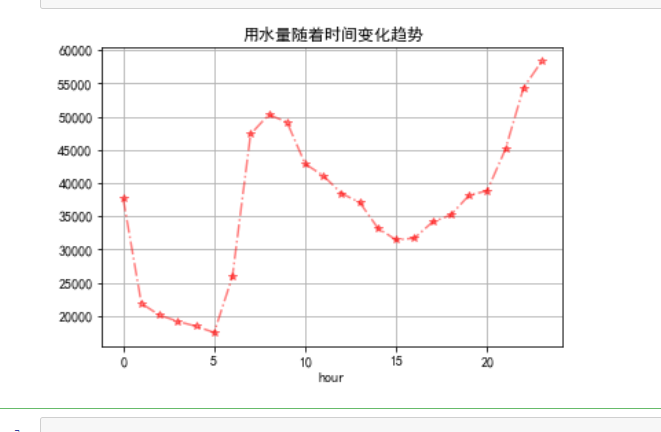 一个月内用水量随着天数变化: 一个月内用水量随着天数变化:
data.groupby(by='day').sum()['用量'].plot.line(style="r*-.",alpha=0.5,title="用水量随着天变化趋势")
plt.grid()
如下: 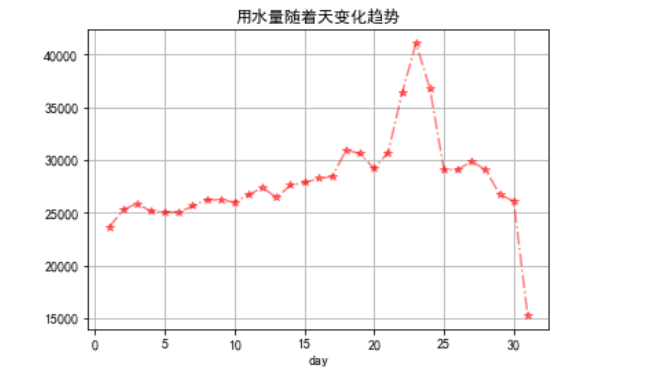 不同区域的特征: 不同区域的特征:
# 不同区域用水特征
# 不同区域随着季度用水变化
i = 0
plt.figure(figsize=(20, 20), dpi=100)
for index,group in data.groupby(by='类型'):
i += 1
plt.subplot(3,2,i)
group.resample("Q").sum()['用量'].plot.line(style="r*-.",alpha=0.5,title="{}用水量随着季度变化趋势".format(index))
plt.show()
如下: 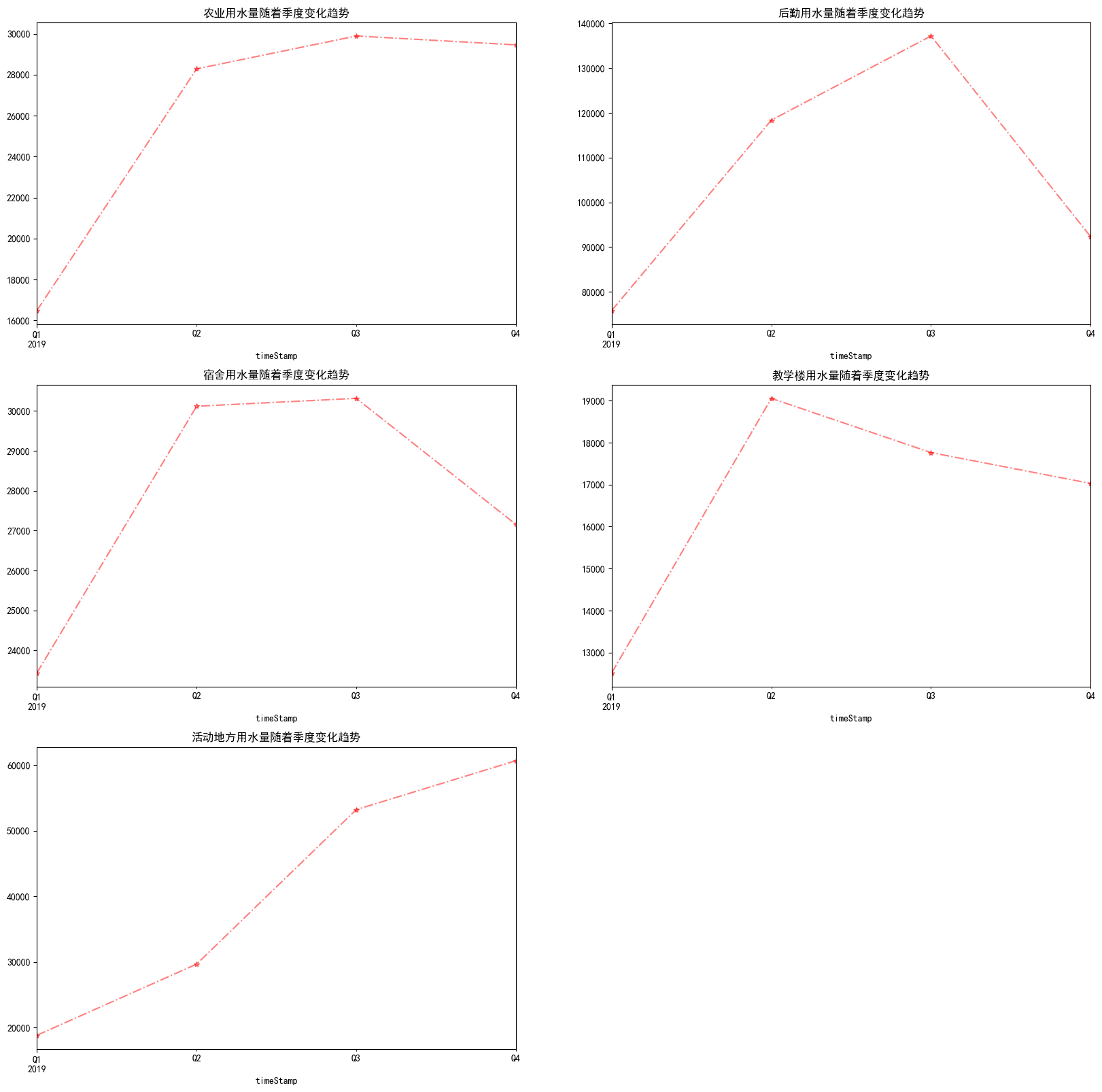 不同区域随着月份用水变化 不同区域随着月份用水变化
# 不同区域随着月份用水变化
i = 0
plt.figure(figsize=(20, 20), dpi=100)
for index,group in data.groupby(by='类型'):
i += 1
plt.subplot(3,2,i)
group.resample("M").sum()['用量'].plot.line(style="r*-.",alpha=0.5,title="{}用水量随着月份变化趋势".format(index))
plt.show()
如下: 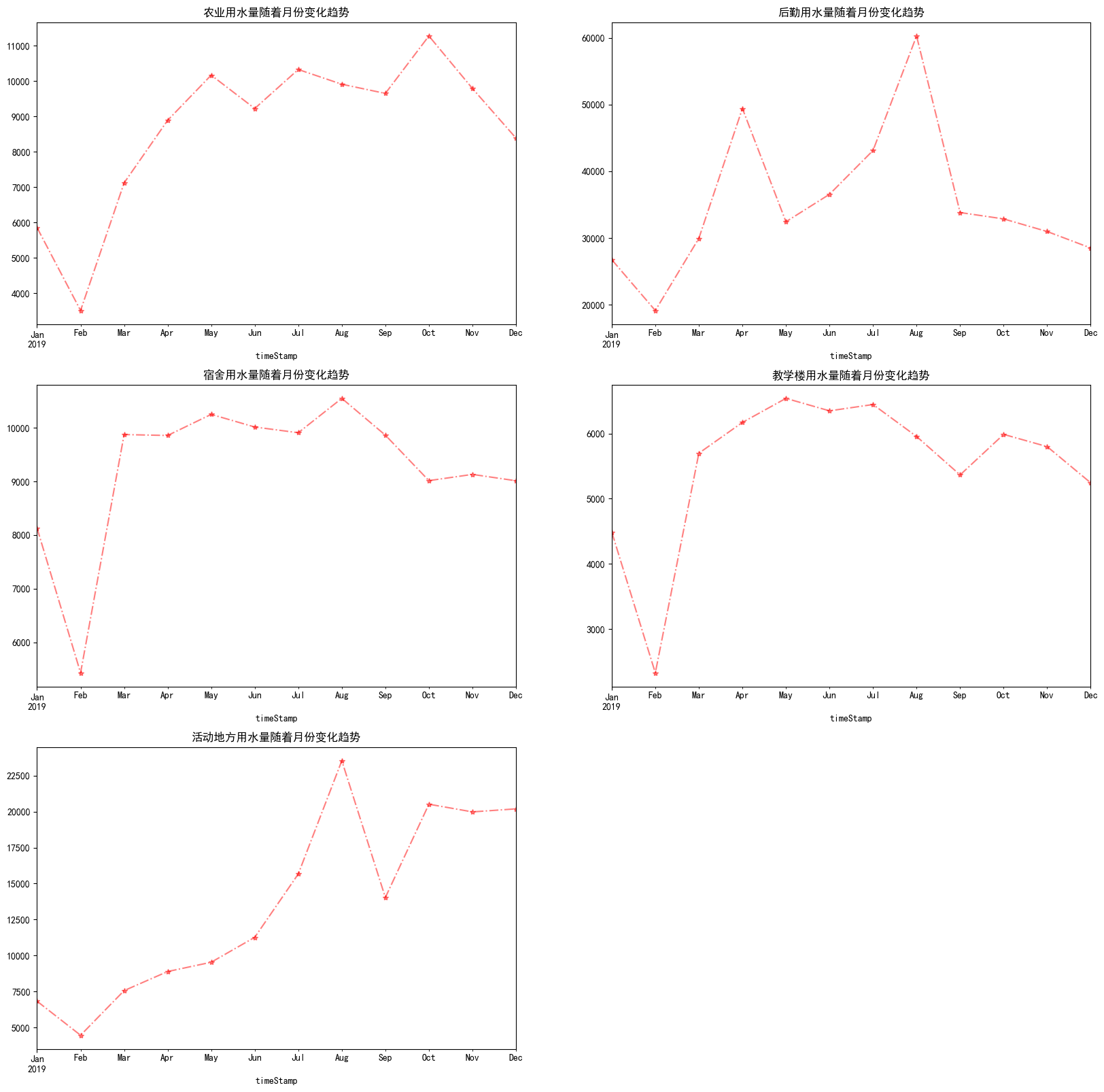 不同区域随着每月的天数用水变化 不同区域随着每月的天数用水变化
# 不同区域随着每月的天数用水变化
i = 0
plt.figure(figsize=(20, 20), dpi=100)
for index,group in data.groupby(by='类型'):
i += 1
plt.subplot(3,2,i)
group.groupby(by='day').sum()['用量'].plot.line(style="r*-.",alpha=0.5,title="{}用水量随着天数变化趋势".format(index))
plt.grid()
如下: 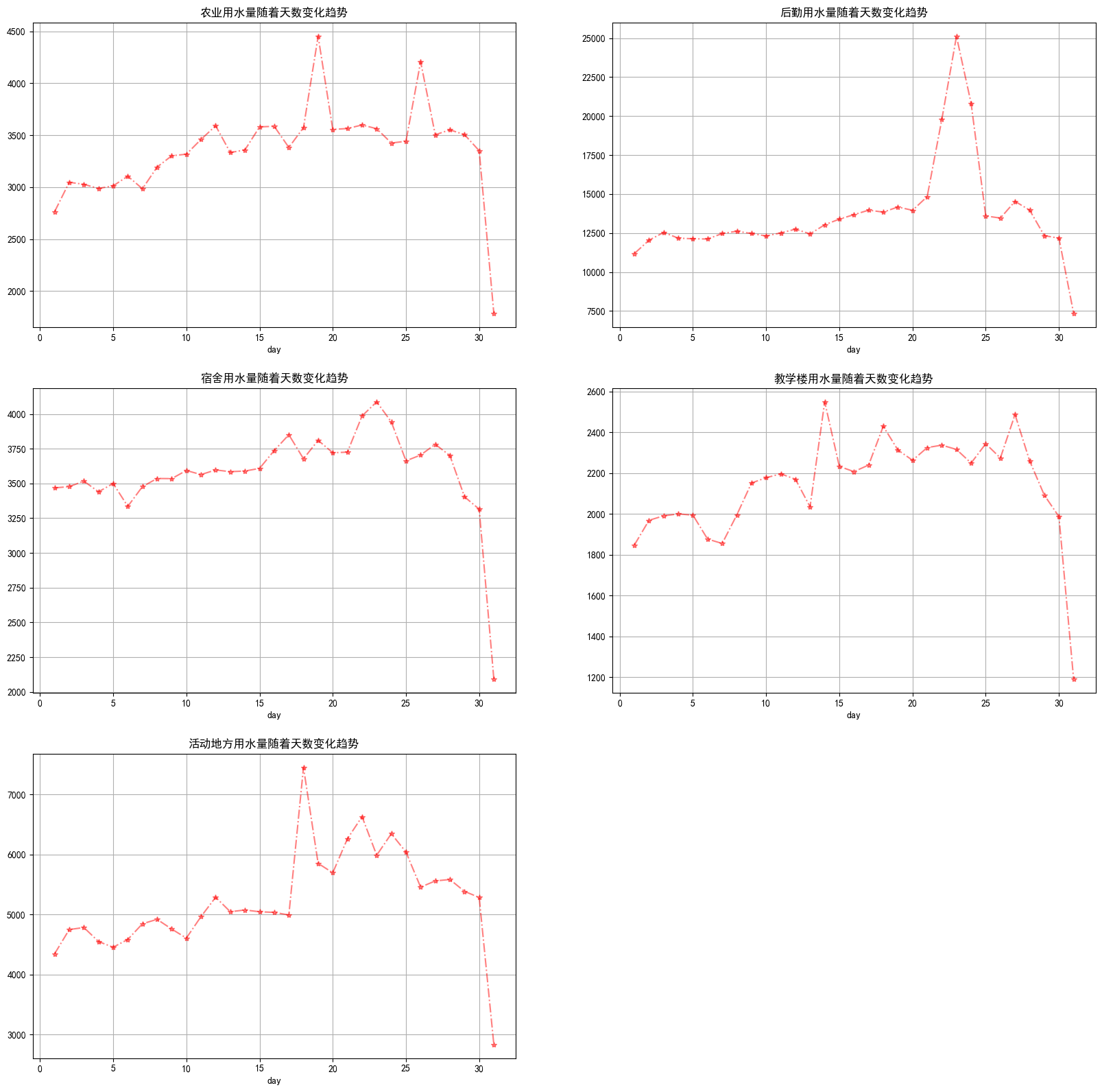 不同区域随着每天的时辰用水变化 不同区域随着每天的时辰用水变化
# 不同区域随着每天的时辰用水变化
i = 0
plt.figure(figsize=(20, 20), dpi=100)
for index,group in data.groupby(by='类型'):
i += 1
plt.subplot(3,2,i)
group.groupby(by='hour').sum()['用量'].plot.line(style="r*-.",alpha=0.5,title="{}用水量随着时辰变化趋势".format(index))
plt.grid()
plt.show()
如下: 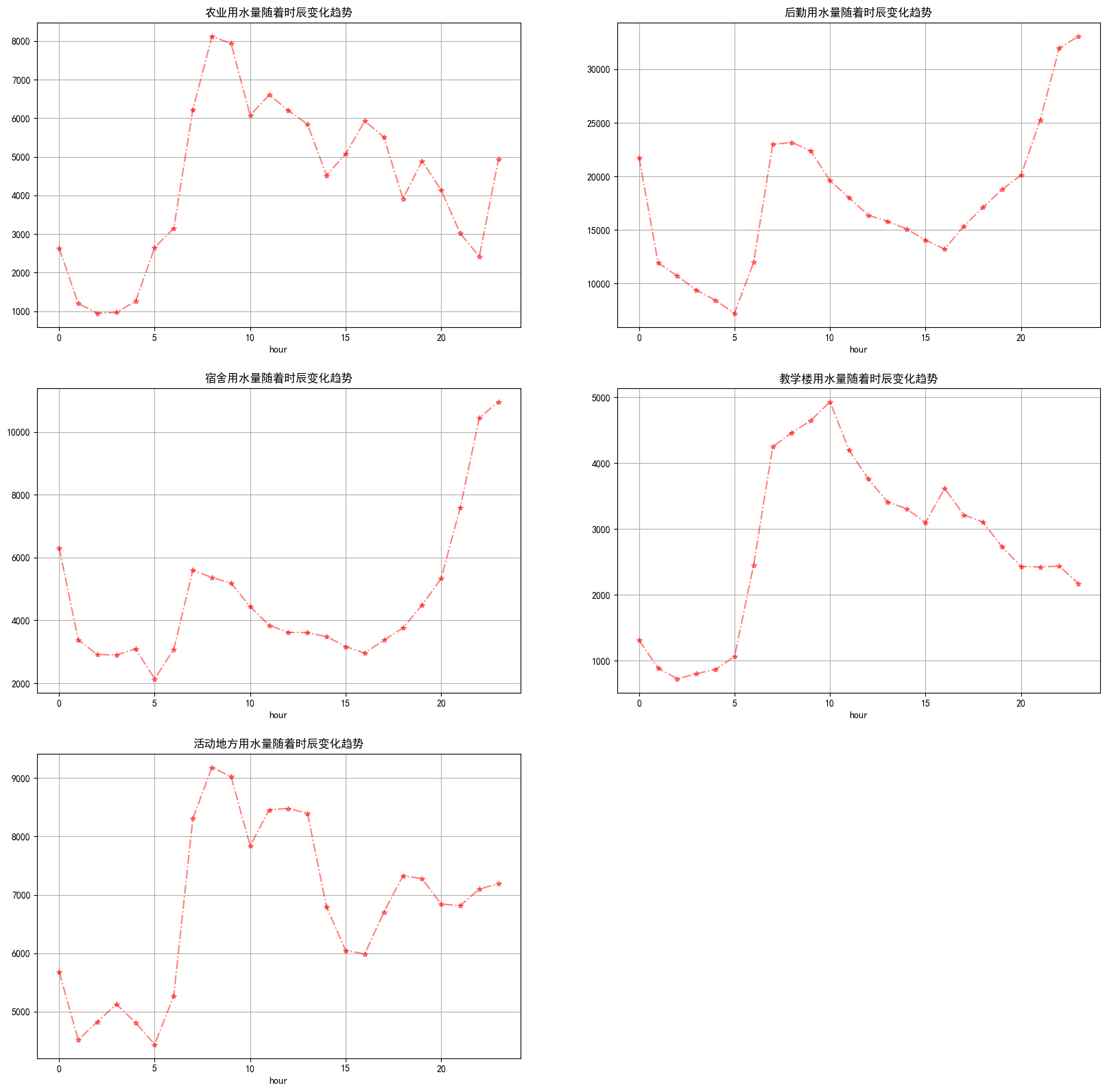 分析完毕~把数据保存起来: 分析完毕~把数据保存起来:
data.to_csv('all.csv',index=False)
第二问
结合校区水表层级关系,建立水表数据之间的关系模型,并利用已有数据分析模型误差。
分析
关联数据平均相对误差MRE的计算方法为: 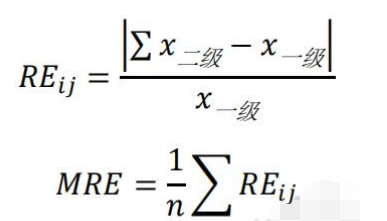 一级水表与二级水表的误差 一级水表与二级水表的误差 
第三问
输水管网的漏损是一个严重问题。资料显示,在维护良好的公共供水网络中,平均失水在5%左右;而在比较老旧的管网中,失水则会更多。请利用附件提供的数据,建立数学模型,分析该校园供水管网的漏损情况。
分析
在第一问基础上,做一下异常值检测分析,比如使用箱型图等。首先利用时间点左右各5个点对其本身进行样条插值平滑预测,利用预测值与原始值的差值估计漏损量,总漏损量为32215,总漏损率为9.8%,该校园漏损率低于全国的平均漏损率,此外还分析评估了各水表漏损情况。
漏损率: 
第四问
地下水管暗漏不容易被发现,需要花费大量人力对供水管道的漏损进行检测及定位,如果能够从水表的实时数据及时发现并确定发生漏损的位置,将极为有益。请帮助学校解决这个问题。
分析
这个问题在于发现水表之间水管的漏损。通过上下级水表读数做差,分析异常点,如问题二。
也可以根据上一问的估计结果,以9.8%为阈值,漏损率超出阈值则标记一次漏损事故,结合各水表处的漏水量情况,按照漏损次数对水表进行漏损等级评定,得到几个水表漏水可能性较高
第五问
管网维修需要一定的人工费和材料费,但同时可以降低管网漏损程度。请根据以上结果和你了解的水价及维修成本确定管网漏损的最优维修决策方案。
查询相关文献进行描述~
|