ACL2024 |
您所在的位置:网站首页 › 语音与语言处理 › ACL2024 |
ACL2024
|
流式零样本语音转换(streaming zero-shot voice conversion)是指能够实时的将输入语音转换成任意说话人的语音,且仅需要该说话人一句语音作为参考,且无需额外的模型更新。现有的零样本语音转换方法通常是为离线系统设计,难以满足实时语音转换应用对于流式能力的需求。近期基于语言模型(language model, LM)的方法在零样本语音生成(包括转换)上展现出卓越的性能,但是需要整句处理而局限于离线场景。 近期,西工大音频语音与语言处理研究组(ASLP@NPU)与抖音合作的论文 “StreamVoice: Streamable Context-Aware Language Modeling for Real-time Zero-Shot Voice Conversion” 被计算语言学和自然语言处理领域顶会ACL 2024接收,该论文针对零样本语音转换在流式场景上的局限开展了深入研究。该论文提出了StreamVoice,一个新的基于流式LM的零样本语音转换模型,实现针对任意说话人和输入语音的实时转换。具体来说,为了实现流式能力,StreamVoice 使用上下文感知的完全因果LM以及时序无关的声学预测器,同时自回归过程中交替处理语义和声学特征消除了对完整源语音的依赖。为了解决流式场景下不完整上下文所导致的性能下降,通过两种策略来增强 LM 对于未来和历史的上下文感知能力:1)教师引导的上下文预知(teacher-guided context foresight),通过教师模型来总结当下和未来准确的语义来指导模型对缺失上下文的预测;2)语义掩蔽策略,鼓励模型从先前损坏的语义输入实现声学预测,增强对于历史上下文的学习能力。现对该论文进行简要的解读和分享。
论文题目:StreamVoice: Streamable Context-Aware Language Modeling for Real-time Zero-Shot Voice Conversion 作者列表:王智超,陈远哲,王新升,谢磊,王玉平 发表会议:ACL 2024 合作单位:抖音 预印版:https://arxiv.org/abs/2401.11053
发表论文截图
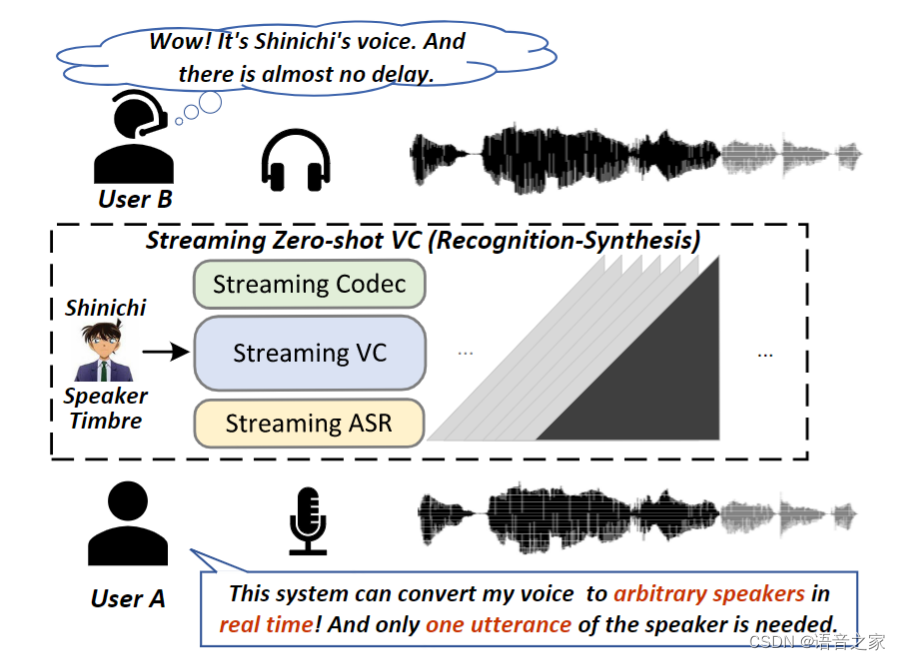
扫码直接看论文 背景动机语音转换(Voice Conversion,VC)是一个在不改变语音内容的前提下,改变语音中说话人音色的一项技术,通常需要目标说话人的大量语音进行系统构建。仅使用目标说话人的一句话作为参考来实现语音转换,即零样本 VC(Zero-shot VC),在近年来获得了极大关注。然而,大多数零样本 VC 都是针对离线系统设计的,难以满足实时 VC 应用中对流式能力的需求。在本工作中,我们主要关注于流式的零样本语音转换,原理如图1所示。此外,实验室之前也推出了流式VC方案即DualVC系列。 ICASSP2024 | DualVC 2:基于动态掩蔽卷积的流式与非流式统一语音转换模型 Interspeech2023 | DualVC—基于模型内蒸馏与混合预测编码的双模语音转换模型
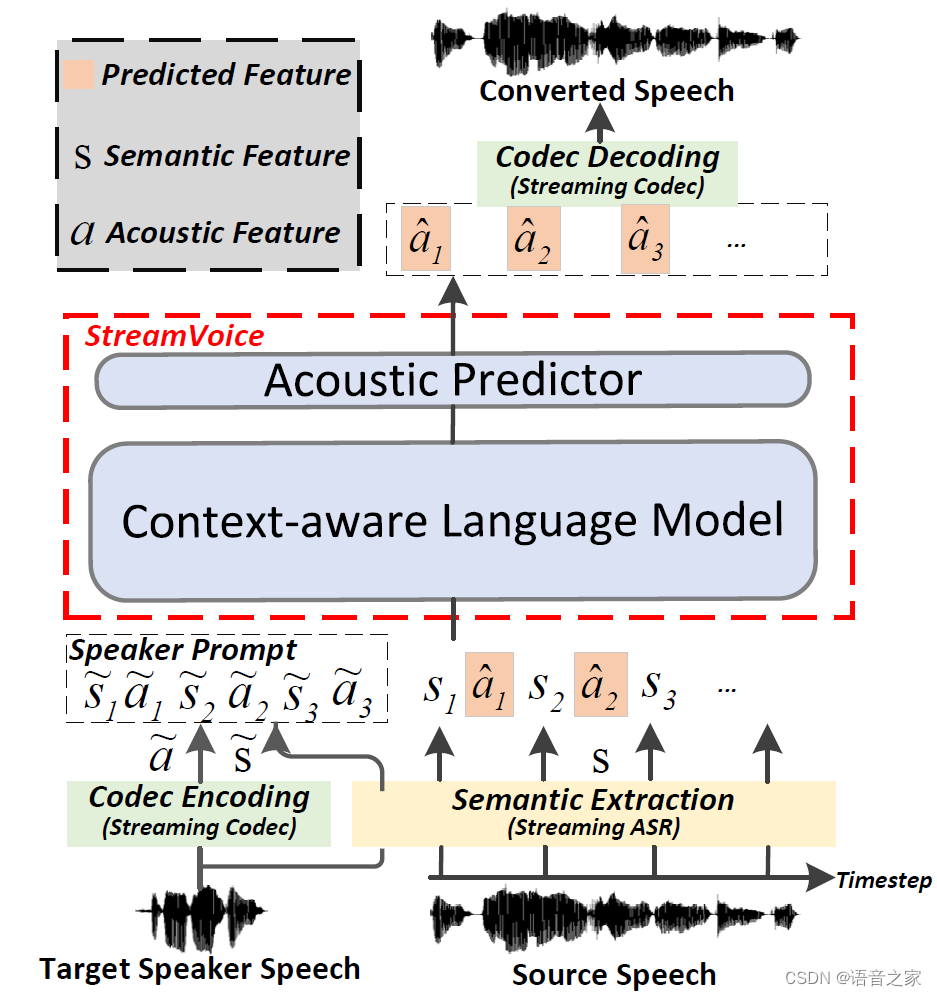
图1 零样本流式语音转换示意图(识别-合成语音转换框架 [1]) 实现零样本语音转换的关键是将语音分解成不同的成分,比如语义内容和说话人音色等[2]。最近, 借助于LM的建模能力和训练数据规模的提升,基于LM的语音转换模型[3]取得了出色的零样本转换性能,但是目前基于 LM 的 VC 模型只能用于离线应用场景。过去已有的一些非 LM 的流式零样本方法[4]本身资源场景要求和模型设计容量受限且缺乏训练数据,难以实现对未见说话人(unseen speaker)的高质量转换同时达到高自然度和相似度。 由于基于LM的模型在零样本 VC 中的成功,我们探索应用LM在流式VC上的可行性。直观的方法是遵循图1所示的广泛使用的识别-合成(Recognition-Synthesis)框架。基于 LM 的零样本 VC模型在流式场景中主要面临两个挑战: 可流式架构:流式中模型需要在接收输入后立即产生输出而不能依赖未来的输入信息。当前基于LM的VC模型仅能在接收完整输入之后才能进行转换。同时对于多层级的codec特征也使得流式的系统设计更加复杂。除此之外,流式系统的上下游依赖模型也影响VC模型的设计和性能。 性能差距:与非流模型相比,流式模型无法看到未来信息,面临缺失的上下文,存在潜在的性能下降。除此之外,依赖的语音提取器,即流式ASR,本身识别性能会比非流式版本低,同时它提取得到的BNF是低质量的语义信息,其中包含残存的说话人信息和噪声等。流式VC模型本身不可获取未来信息以及这种低质量的语义输入使得实现高质量的转换变得更加困难。 本文提出StreamVoice,一种基于流式 LM 的模型,用于高质量的零样本语音转换。具体来说,StreamVoice 具备可流式架构及进行全因果的语音生成。每个时间步上语义和声学特征的交替输入确保了流式的实现。此外,引入了两种方法来增强 LM 的上下文感知,以减轻上下文信息缺失造成的性能差距。1)结合教师指导的上下文预知(teacher-guided context foresight),其中非流式ASR作为教师来提供更加准确的当前和未来语义信息来引导VC模型用于增强声学预测。2)为了增强对于输入历史的上下文学习,语义掩蔽鼓励从历史损坏的语义输入进行声学预测,这也隐含地创建了一个信息瓶颈来减少源说话人的信息。实验验证了StreamVoice的良好的流式转换性能。同时StreamVoice本身不需要未来信息,在没有工程优化的情况下,A100上整个流式系统只需要124ms的首包延迟。 提出的方案如图2所示,StreamVoice依旧采用了识别-合成的框架。在这个框架中,语音首先被流式ASR和音频codec分别表征为语义特征 和声学特征 。StreamVoice本身由上下文感知语言模型和声学预测器组成。使用来自目标说话人语音的语义和声学特征 作为说话人提示,LM使用源语音的语义信息作为输入来自回归得到隐层输出 。声学预测器将隐层输出 还原为codec特征 .
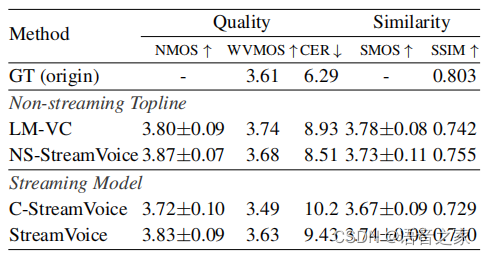
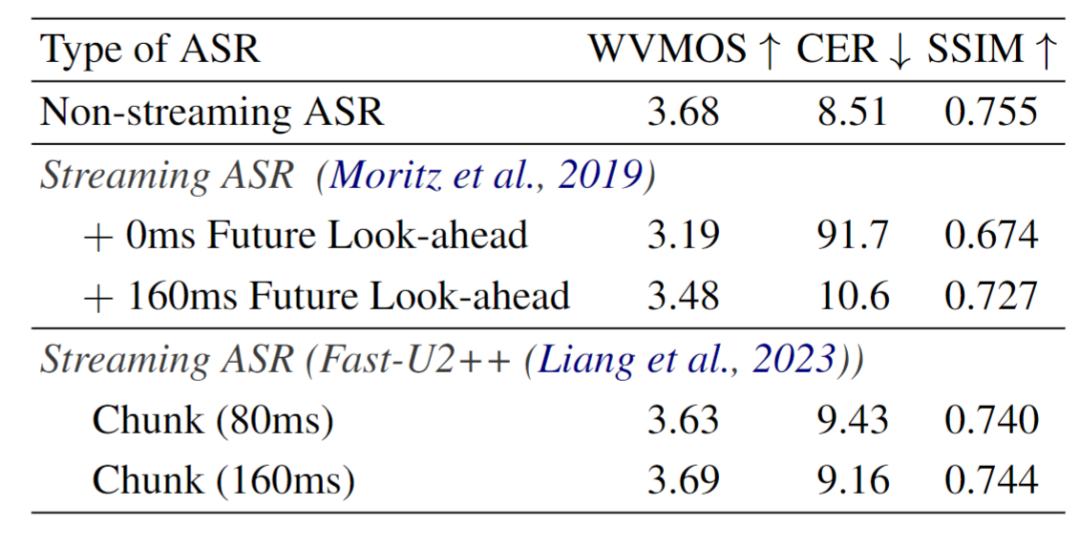
图2 StreamVoice框架 上下文感知增强 由于流式框架中因果关系的要求,VC模型面临着未来信息的缺失,同时流式ASR的低质量语义输入使得实现高质量的转换更具挑战性。我们引入了上下文感知增强方法来缓解语义输入和未来信息缺失产生的不完整上下文信息。具体来说,我们在 LM 中引入了上下文掩码自回归预测,以增强从给定的语义输入中捕获历史上下文。同时,提出了一种教师引导的上下文预知,以确保模型可以根据其历史上下文想象未来的上下文。 Context-masked Autoregressive Prediction:与过去很多工作类似,掩蔽的策略被直接用来处理输入序列以此鼓励模型从受损序列中更多的通过总结上下文来实现最终的自回归预测。 Teacher-guided Context Foresight:为了缓解缺乏未来上下文的问题,受到自监督APC[6]方法的启发,我们引入了由非流式ASR主导的教师引导上下文预知,来指导模型学习包含未来信息的上下文向量。如图5所示,具体来说, 隐层输出经过线性变换得到的上下文向量期望能够包含编码局部语音序列的通用结构,上下文向量通过预测包含当前时刻和未来k个时间步的语义信息,来共同保证对于未来信息预测和当前内容的准确传递。与原始的apc不同的是,我们采用非流式 ASR 模型作为教师来提供语义信息指导这个过程。这样做也是为了防止流式ASR 中低质量语义特征带来的问题。预测的上下文向量与隐层输出结合共同用于进一步的声学预测。 实验验证实验设置:实验中使用1500小时的中文数据进行训练。其中流式ASR使用的是Fast-U2++[7], 流式Codec采用的是Audiodec[8]。 实验结果:表1展示了StreamVoice在零样本语音转换中的结果。可以看出,相比于非流式VC系统,SteamVoice能够取得接近的结果,当然仍旧存在性能差异。而当将StreamVoice输入替换成非流式ASR特征之后,它的性能跟非流式topline具有可比的结果。这些结果表明了StreamVoice设计的有效性。 表1 零样本转换验证
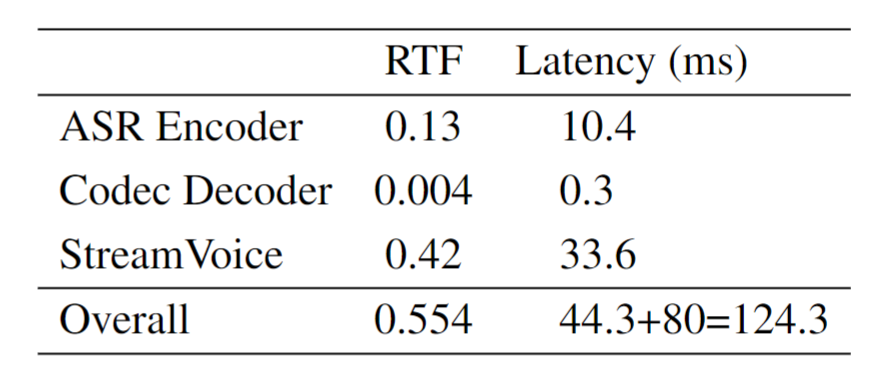
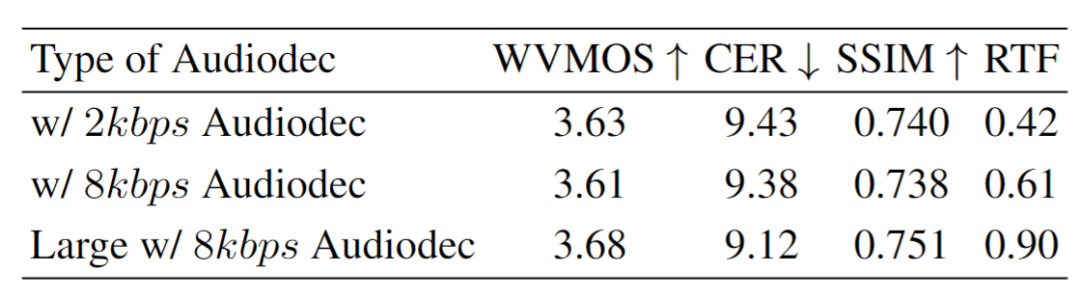
进一步我们测试了模型的延时,如表2所示,总体来说模型的RTF都小于1,满足实时的条件。对于模型的首包延迟,总体流式系统需要124.3ms。在V100上,StreamVoice相应的RTF为0.56,整体首包延迟变为137.2ms。集内说话人测试和消融实验详细可见论文。 表2 延迟测试结果(A100),其中ASR chunk size为80ms
流式系统依赖分析-ASR:如表3所示,我们探究了流式ASR系统选择对于下游流式VC性能影响。使用非流式ASR的StreamVoice性能好于使用流式ASR的系统。同时当streamvoice本身不包含未来视野时,使用CTC-based 流式asr的模型无法得到正常的结果。而当我们添加160ms的等待之后,即第160ms特征输入的时候模型才进行输出,模型能够得到相对合理的结果。这个问题可能来源于流式ASR[7]中报告的delayed CTC spike distributions和token emission latency,最终使得语义信息移位。当换成更低emission latency的fastu2++之后,streamvoice能够在模型中不添加未来感受野。当本身ASR的chunk越大,ASR性能越好,对应VC的结果也会提升,但是会存在性能和延时的取舍。 表3 对于ASR模型的依赖分析
流式系统依赖分析-Codec:如表4,我们探究了codec本身配置的影响。比特率越高,codec本身的音频还原质量会得到提升。在实验中我们发现在论文中提到的streamvoice配置下,codec比特率的变化却并没有带来明显的性能区别。当增加声学预测器网络参数量之后,这样的性能出现明显的提升。这个结果也表明了在流式系统的设计过程中,StreamVoice对于上下游的系统依赖,最终体现在性能和推理速度的相互影响。 表4 对于Codec模型配置依赖分析
以下为StreamVoice 流式零样本VC结果,在V100上的RTF为0.56,整体首包延迟为137.2ms。 第一组 输入语音
更多样例:https: //kerwinchao.github.io/StreamVoice/ 参考文献[1] Lifa Sun, K. Li, Hao Wang, Shiyin Kang, and H. Meng. 2016. Phonetic posteriorgrams for many-to-one voice conversion without parallel data training. International Conference on Multimedia and Expo (ICME), pages 1–6. [2] Kaizhi Qian, Yang Zhang, Shiyu Chang, Xuesong Yang, and Mark Hasegawa-Johnson. 2019. Autovc: Zeroshot voice style transfer with only autoencoder loss. In International Conference on Machine Learning (ICML), pages 5210–5219. [3] Zhichao Wang, Yuanzhe Chen, Lei Xie, Qiao Tian, and Yuping Wang. 2023c. LM-VC: Zero-shot voice conversion via speech generation based on language models. IEEE Signal Processing Letters, pages 1157– 1161. [4] Bohan Wang, Damien Ronssin, and Milos Cernak. 2023a. Alo-vc: Any-to-any low-latency one-shot voice conversion. In International Speech Communication Association (Interspeech), pages 2073–2077. [5] Li-Wei Chen, Shinji Watanabe, and Alexander Rudnicky. 2023a. A vector quantized approach for text to speech synthesis on real-world spontaneous speech. In Association for the Advancement of Artificial Intelligence (AAAI). [6] Yu-An Chung, Wei-Ning Hsu, Hao Tang, and James Glass. 2019. An Unsupervised Autoregressive Model for Speech Representation Learning. In International Speech Communication Association (Interspeech), pages 146–150. [7] Chengdong Liang, Xiao-Lei Zhang, BinBin Zhang, Di Wu, Shengqiang Li, Xingchen Song, Zhendong Peng, and Fuping Pan. 2023. Fast-u2++: Fast and accurate end-to-end speech recognition in joint ctc/attention frames. In International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. [8] Yi-Chiao Wu, Israel D Gebru, Dejan Markovi ́c, and Alexander Richard. 2023. Audiodec: An opensource streaming high-fidelity neural audio codec. In International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. |



【本文地址】
今日新闻 |
推荐新闻 |