编译原理实验2(自上而下语法分析) |
您所在的位置:网站首页 › 语法分析器输出的是单词 › 编译原理实验2(自上而下语法分析) |
编译原理实验2(自上而下语法分析)
|
一、实验目的 给出 PL/0 文法规范,要求编写 PL/0 语言的语法分析程序。通过设计、编制、调试一个典型的自上而下语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,进一步掌握常用的语法分析方法。选择有代表性的语法分析方法,如LL(1)文法分析;选择对各种常见程序语言都具备的语法结构,如赋值语句,特别是表达式,作为分析对象。提高自己的实践能力和解决问题的能力。二、实验原理 了解符已给 PL/0 语言文法,构造表达式部分的语法分析器。分析对象〈算术表达式〉的 BNF 定义如下: ::= [+|-]{ } ::= { } ::= || ‘(’‘)’ ::= +|- ::= *|/ ::= =|#|= 将实验一“词法分析”的输出结果,作为表达式语法分析器的输入,进行语法解析,对于语法正确的表达式,输出“语法正确”;对于语法错误的表达式,输出“语法错误”,指出错误原因。三、实验内容 1.了解符已给 PL/0 语言文法,构造表达式部分的语法分析器。 分析对象〈算术表达式〉的 BNF 定义如下: ::= [+|-]{ } ::= { } ::= || ‘(’‘)’ ::= +|- ::= *|/ ::= =|#|= 2.将实验一“词法分析”的输出结果,作为表达式语法分析器的输入,进行语法解析,对于语法正确的表达式,输出“语法正确”;对于语法错误的表达式,输出“语法错误”,指出错误原因。 3.输入:
4.输出:
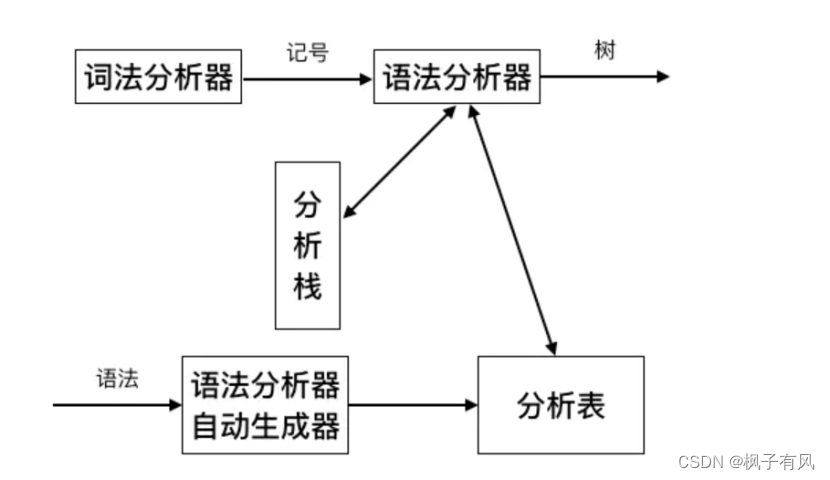
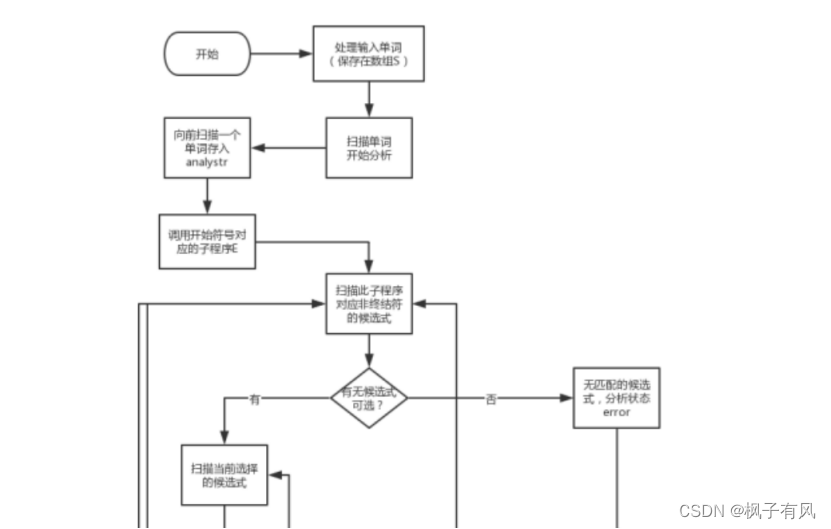
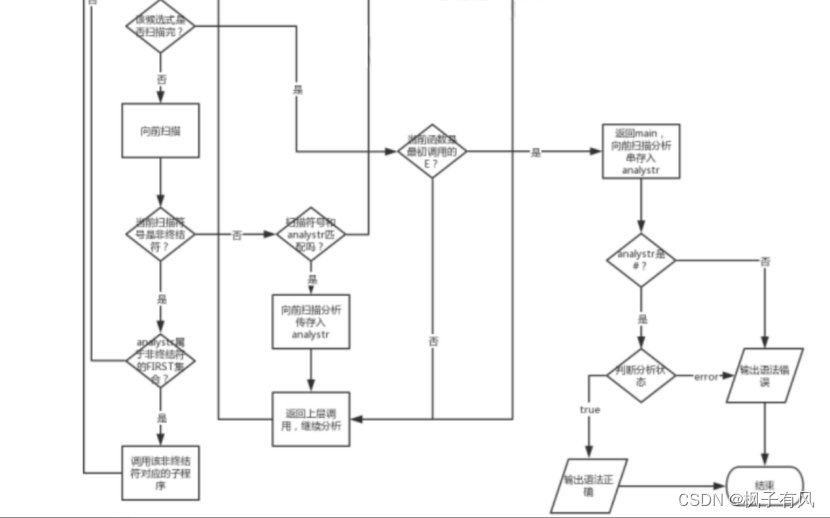
四、实验算法及流程图 算法思想LL(1)分析法属于确定的自顶向下分析方法。LL(1)的含义是:第一个L表明自顶向下分析是从左到右扫描输入串,第2个L表明分析过程中将使用最左推导,1表明只需向右看一个符号便可决定如何推导,即选择哪个产生式(规则)进行推导。 LL(1)文法的判别需要依次计算FIRST集、FOLLOW集和SELLECT集,然后判断是否为LL(1)文法,然后再进行句子分析。需要预测分析器对所给句型进行识别。即在LL(1)分析法中,每当在符号栈的栈顶出现非终极符时,要预测用哪个产生式的右部去替换该非终极符;当出现终结符时,判断其与剩余输入串的第一个字符是否匹配,如果匹配,则继续分析,否则报错。LL(1)分析方法要求文法满足如下条件:对于任一非终极符A的两个不同产生式A→a,A→β,都要满足下面条件:SELECT(A→a)n SELECT(A→p)=O 设计思想扩充的巴克斯范式 ::= [+|-]{ } ::= { } ::= || ‘(’‘)’ ::= +|- ::= *|/ 普通的巴克斯范式 为表示方便: 表达式E、项X、因子Y、标识符b,无符号整数z,加法运算符A,乘法运算符C E->AX|X|EAX X->Y|XCY Y->b|z|(E) A->+|- C->*|/ 消除左递归 E->XE’|AXE’ E’->AXE’|ε X->YX’ X’->CYX’|ε Y->b|z|(E) A->+|- C->*|/ 改进后的文法满足LL(1)文法条件,所以该文法是LL(1)的。 手动求了First集和Follow集,方便后面进行程序的验证。 FIRST和FOLLOW集合 FIRST(E)={b,z,(,+,-} FOLLOW(E)={#,)} FIRST(E’)={ε,+,-} FOLLOW(E’)={#,)} FIRST(X)={b,z,(} FOLLOW(X)={+,-,#,)} FIRST(X’)={ε,,/} FOLLOW(X’)={+,-,#,)} FIRST(Y)={b,z,(} FOLLOW(Y)={,/,+,-,#} FIRST(A)={+,-} FOLLOW(A)={b,z,(} FIRST©={,/} FOLLOW©={b,z,(} 关键步骤构建预测分析表。要构建预测分析表就要根据产生式来生成三个集合First set, Follow Set, Select Set First set的构建功能:对一个给定的非终结符,通过一系列语法推导后,能出现在推导表达式最左端的所有终结符的集合,统称为该非终结符的FIRST SET。 如果A是一个终结符,那么FIRST(A)={A}对于以下形式的语法推导:S -> a B S是非终结符,a是终结符,B是零个或多个终结符或非终结符的组合,那么 a属于 FIRST(S). 对于推导表达式:s -> b a s 和 b 是非终结符,而且b 不是nullable的,那么first(s) = first(b) 对于推导表达式:s -> a1 a2 … an b 如果a1, a2 … an 是nullable 的非终结符,b是非终结符但不是nullable的,或者b是终结符,那么 first(s) 是 first(a1)… first(an) 以及first(b)的集合。 Follow Set的构建对于某个非终结符通过一系列推导变换后,某个终结符出现在该非终结符的后面,那么我们称该终结符属于对应非终结符的FOLLOW SET。 先计算每一个非终结符的first set,并把每个非终结符的follow set设置为空.对于表达式 s -> …a b…, a 是一个非终结符,b 是终结符或非终结符, 那么FOLLOW(a) 就包含 FIRST(b).对于表达式 s->…a a1 a2 a3… an b…, 其中a是非终结符,a1, a2 a3… an 是nullable的非终结符,b是终结符或非nullable的非终结符,那么FOLLOW(a) 包含FIRST(a1)… FIRST(an) FIRST(b)的集合。对于表达式s -> … a 其中a是非终结符,而且a出现在右边推导的最后面,那么FOLLOW(a) 包含 FOLLOW(s)对于表达式 s -> a a1 a2…an ,其中a是非终结符而且不是nullable的,a1 a2…an 是nullable的非终结符,那么FOLLOW(a), FOLLOW(a1)…FOLLOW(an) 都包含FOLLOW(s) Select Set的构建对于标号为N的推导表达式s->a,以及当前输入T,那么Selest(N)要包括T的话,当栈顶元素是s,且输入为T时,要使用推导表达式N来进行下一步推导。 计算所以非终结符的first set 和follow set.对应非nullable的表达式 , s -> a b… 其中s是非终结符,a 是一个或多个nullable的非终结符,b是终结符或是非终结符但不是nallable的,b后面可以跟着一系列符号,假设其标号为N,那么该表达式的选择集就是FIRST(a) 和 FIRST(b)的并集。如果a不存在,也就是b的前面没有nullable的非终结符,那么SELECT(N) = FIRST(b).对应nullable的表达式: s -> a, s是非终结符,a是零个或多个nullable非终结符的集合,a也可以是ε,假设该表达式标号为N,那么SELECT(N)就是 FIRST(a) 和 FOLLOW(s)的并集。由于a可以是0个非终结符,也就是s -> ε,从而s可以推导为空,如果s推导为空时,那么我们就需要看看当前输入字符是不是FOLLOW(s),也就是跟在s推导后面的输入字符,如果是的话,我们才可以采用s->ε,去解析当前输入。 构建完整的预测分析表 将解析表所有元素初始化为-1for (每一个推导表达式 N) {lhs = 推导表达式箭头左边的非终结符 for (对应每一个在SELECT(N)中的token) { parse_table[lhs][token] = N } } 算法流程LL(1)大概的工作流程: 1)将开始符号压入栈中; 2)根据输入符号和分析表来选择产生式; 3)把产生式都压入栈中; 4)如果当前栈顶是终结符,就进行匹配; 5)匹配失败退出,成功则读入,再回到第二个步骤
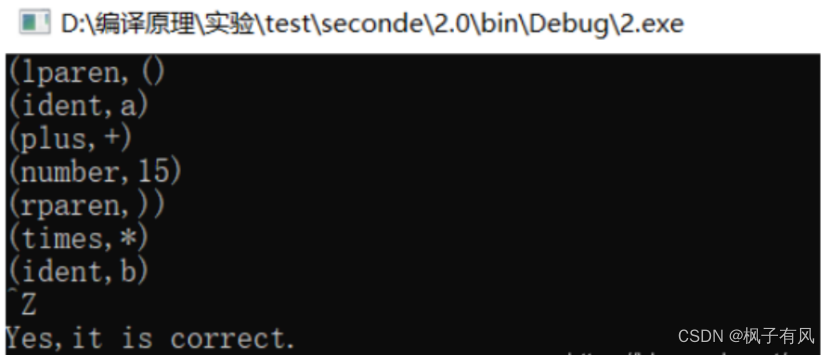
用例1
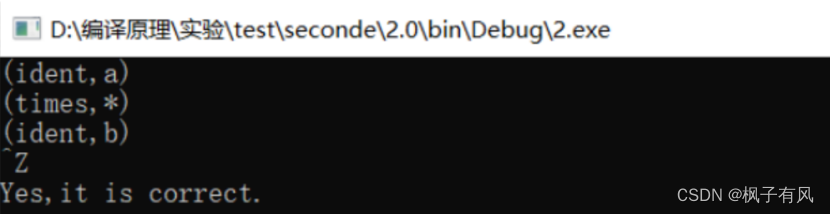
用例2
itc验证 递归下降分析也成功。
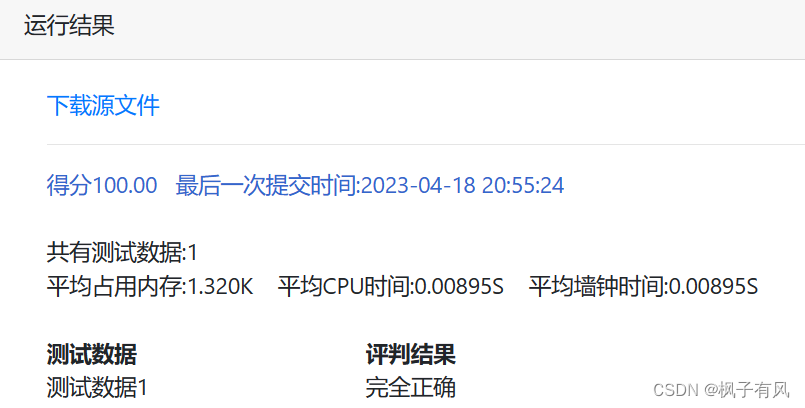
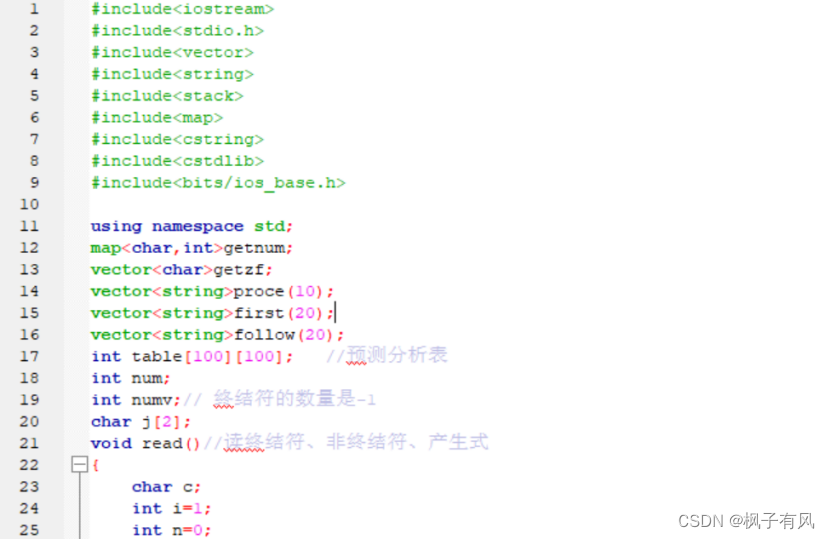
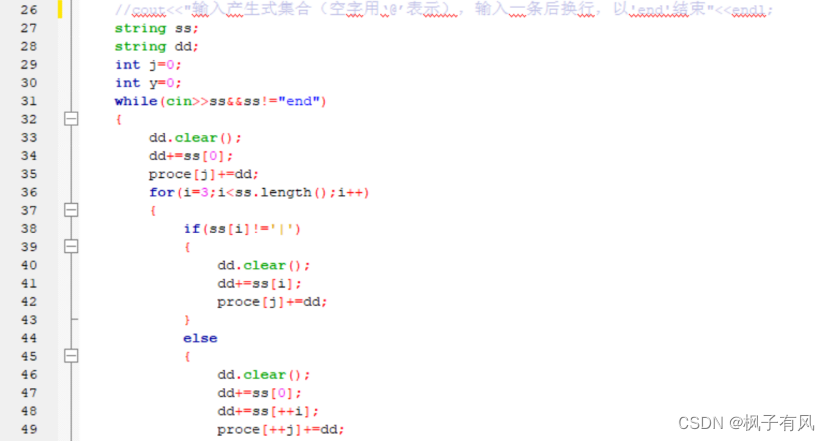
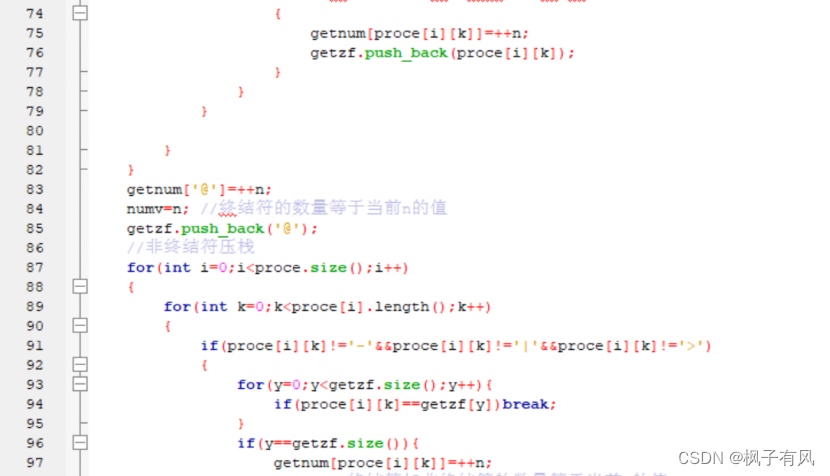
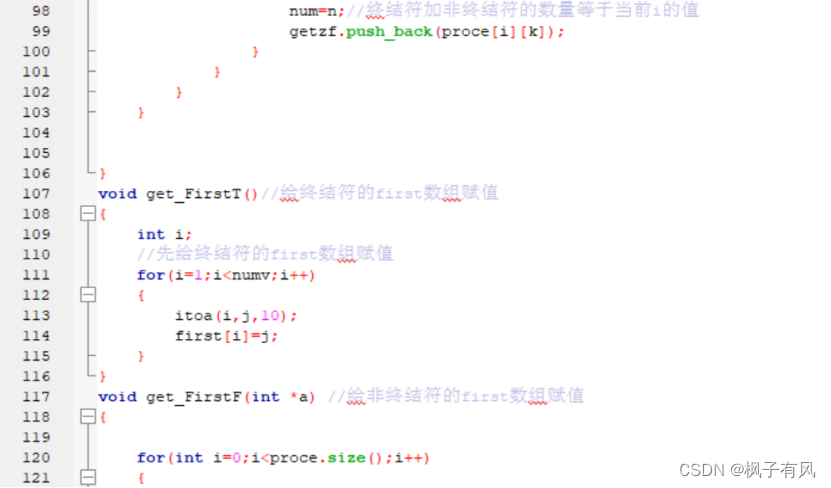
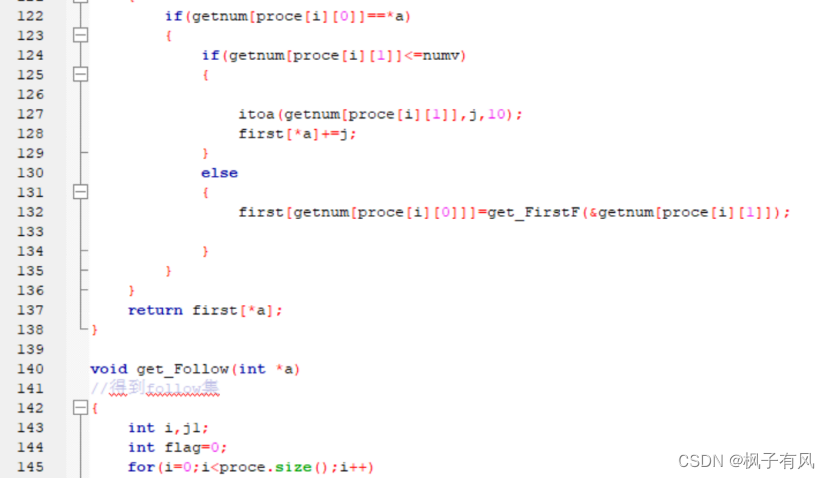
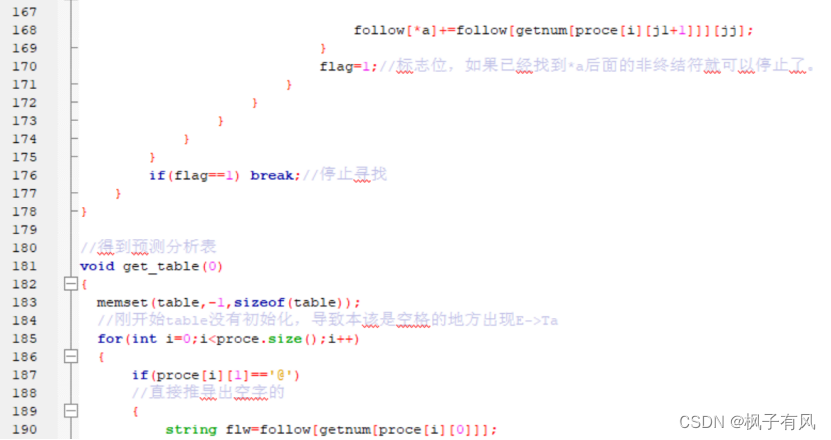
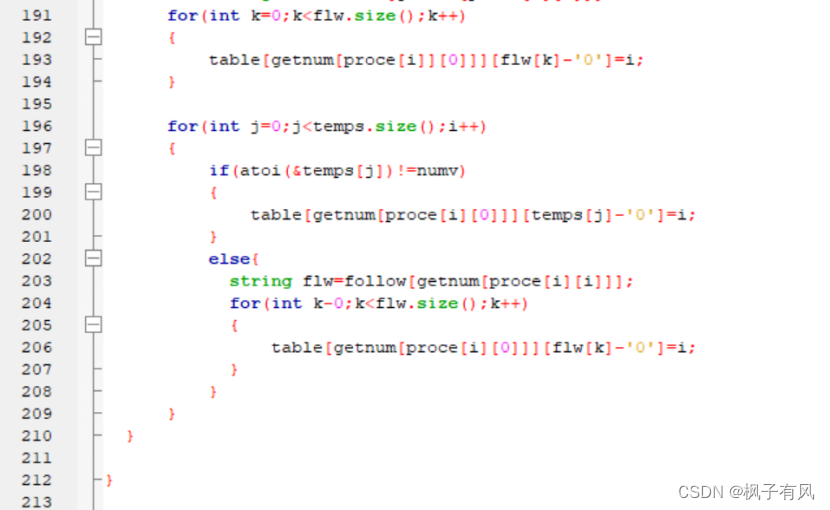
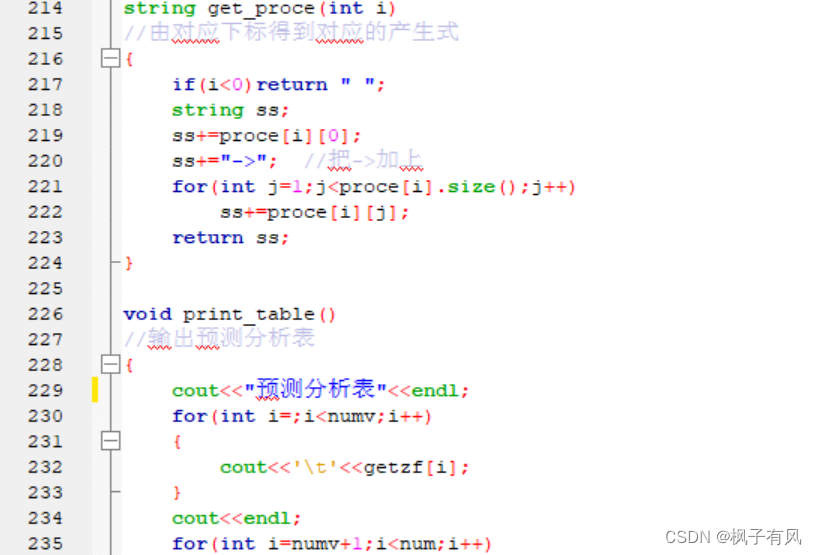
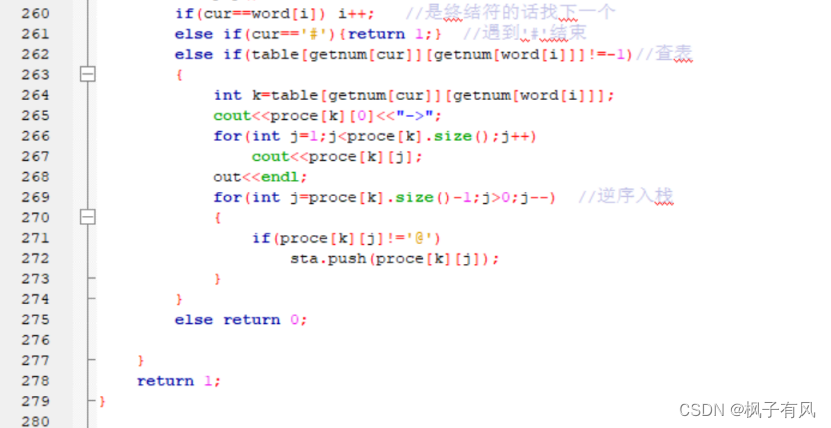
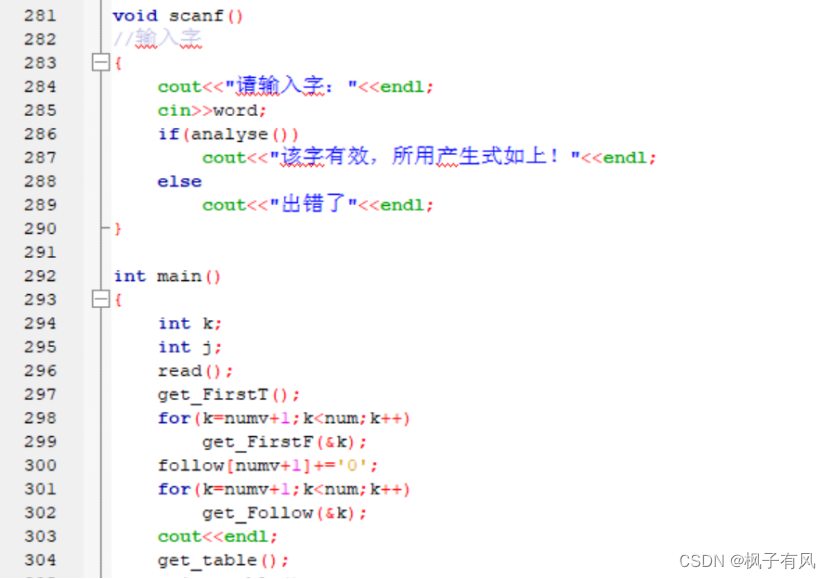
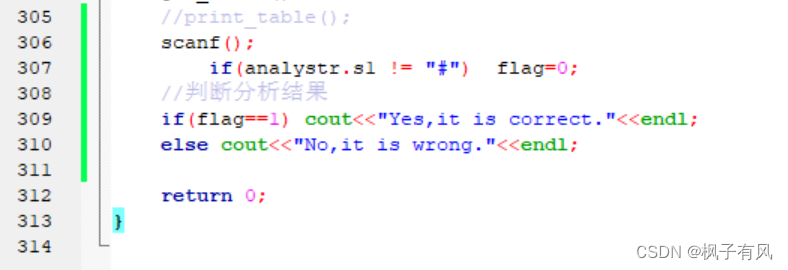
根据程序运行得到的结果可以看出:编写的代码正确。 实验体会第二次编译原理的实验课,最大的收获是复习了LL(1)文法的相关知识,从代码的层面深入的学习了符号表的建立与使用,同样提高了动手写代码的熟练程度。 这次实验难度不大,主要是理解和掌握建立FIRST集、FOLLOW集、SELECT集等操作,以及对预测分析表的理解对编写代码尤为重要。 这次编译原理实验课,总结上一次实验课的经验与教训:理解好项目给出的数据结构,以及演示模式程序执行的步骤和输出结果,熟练掌握数据结构的相关知识是完成代码的关键。 总的来说,通过这次实验课,既加深了我对编译原理课程重点内容的理解,又复习了数据结构、c/c++的相关知识,提高了编写代码的能力,收获良多。 最后,特别感谢刘老师一直以来的耐心指导和同学的热心帮助! 附录代码如下
|







【本文地址】
今日新闻 |
推荐新闻 |