TCP/IP协议专栏 |
您所在的位置:网站首页 › 该硬件没有有效的硬件标识号 › TCP/IP协议专栏 |
TCP/IP协议专栏
|
报文为什么要分片
一个链路层数据报能承载的最大数据量称为最大传送单元(MTU)。 因为IP数据报(IP头+DATA)被封装在链路层数据报中,故链路层的MTU严格地限制着IP数据报的长度, 而且在IP数据报的源与目的地路径上的各段链路可能使用不同的链路层协议,有不同的MTU. 例如,以太网的MTU为1500字节,而许多广域网的MTU不超过576字节。 当IP数据报的总长度大于链路MTU时, 就需要将IP数据报中的数据分装在两个或更多个较小的IP数据报中, 这些较小的数据报叫做片。 互联网协议使网络互相通信。设计要迎合不同物理性质的网络; 它是独立于链路层使用的基础传输技术。具有不同硬件的网络通常会发生变化,不仅在传输速度,而且在最大传输单元(MTU)。当一个网络要的数据报发送到具有较小MTU的一个网络,它可能片段的数据报。在IPv4中,这个功能被放置在因特网层,并且在IPv4路由器,这因此只需要这个层作为最高的一个在其设计中实现的处理。 与此相反,IPv6的,下一代互联网协议的,不允许的路由器来执行分片; 发送数据包之前,主机必须确定路径MTU。 ipv4 分片报文 IPv4分片的特点
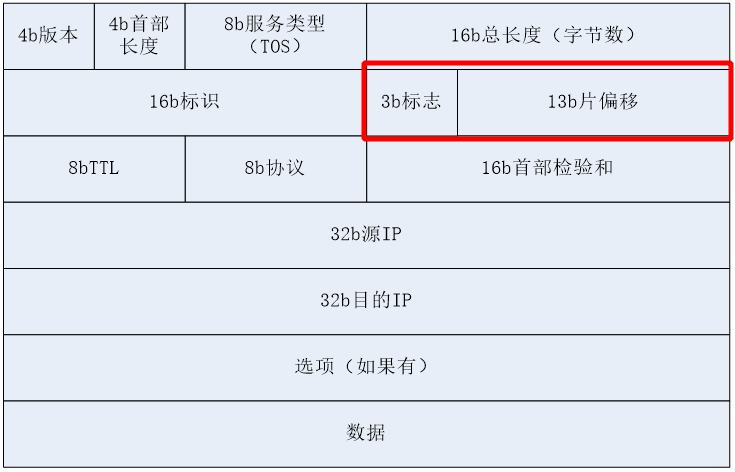
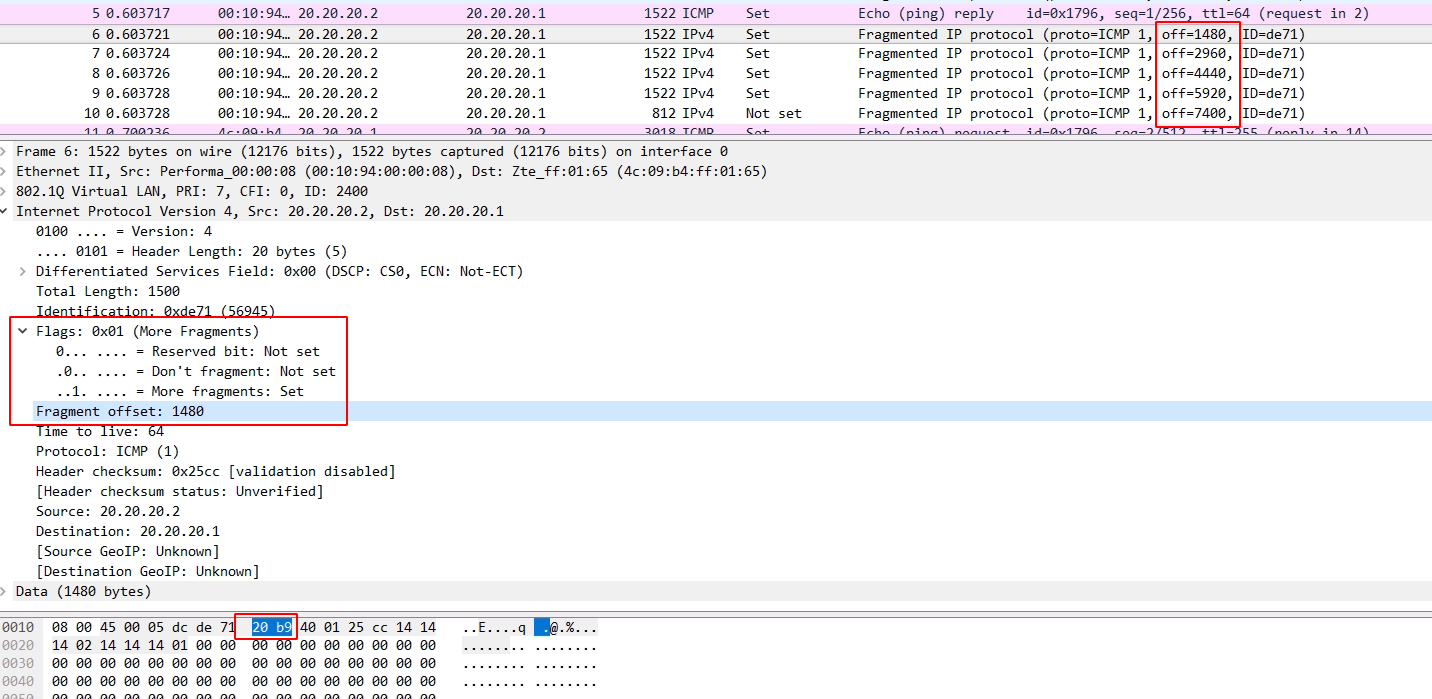
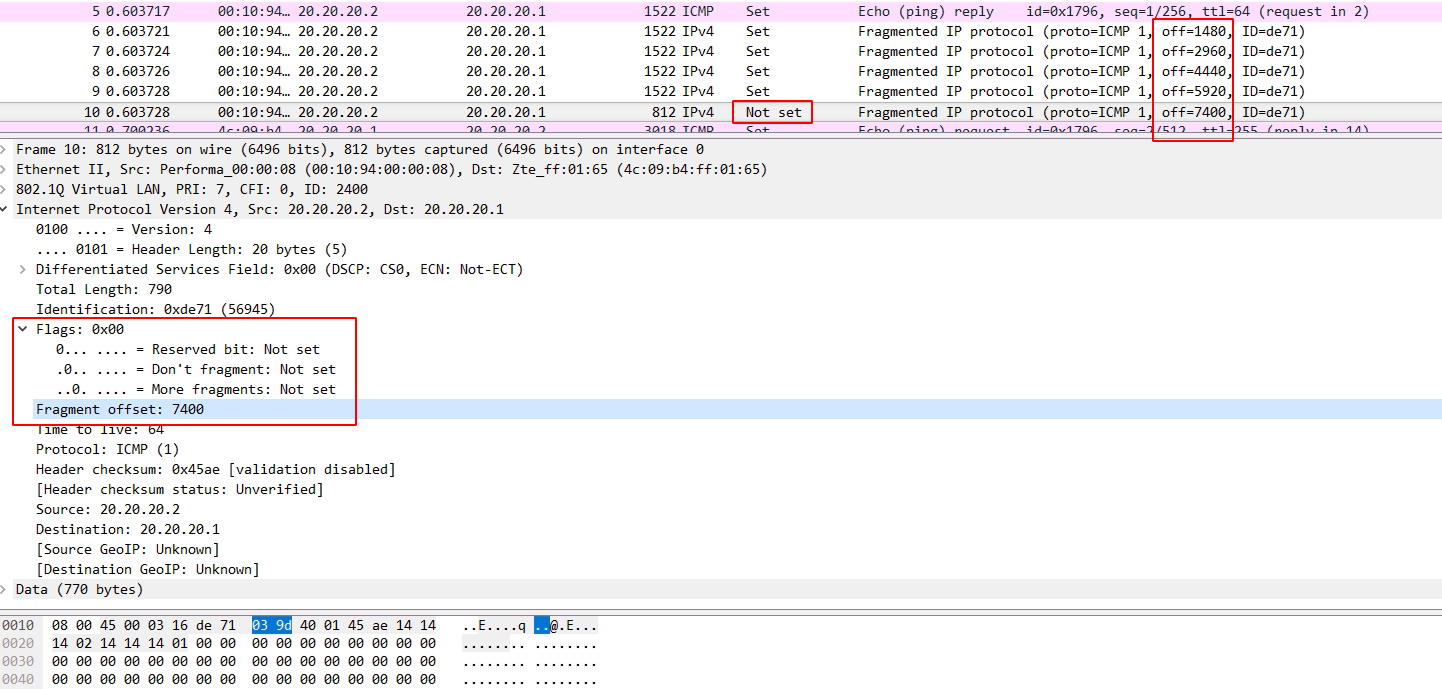
一个三比特字段遵循与用于控制或识别片段。他们是(按顺序,从高分以低位): 0:保留; 必须为零。 1位:不分段(DF) 2位:更多片段(MF) 如果DF标志被设置,并且分片需要来路由分组,则该分组被丢弃。这可以发送分组到不具有足够的资源来处理破碎的宿主时,可以使用。它也可用于路径MTU发现由主机IP软件,可以自动或使用诊断工具例如手动平或跟踪路由。对于未分段的数据包,对MF标志被清除。对于分片包,除了最后的所有片段具有MF标志设置。最后片段具有一个非零片偏移量字段,从一个未分段的分组区分它。 分片偏移 片段偏移字段以8字节块为单位进行测量。它是13位长,并指定特定相对于原始未分段的IP数据报的开始的片段的偏移量。零第一片段已偏移。这允许最多(2偏移13(次方)- 1)×8 =字节65,528,这将超过65,535字节的最大IP报文长度与包括报头长度(+ 65,528 20 = 65548字节)。 一般来说我们都知道MTU是1500字节,因此超过1500字节的数据就需要进行ip分片。 1、分片由IPv4头部中的标识(Identification)、分片偏移(Fragment offiet)和更多分片(More Fragments, MF)字段控制,分片的标识(Identification)都是同样的而且分片偏移(Fragment offiet)是以8字节为单位的偏移。 2、分片:源和目的端口号的UDP(协议)头部只出现在第一个分片里 3、重组:IP分片在目的地的网络层被重新组装。 目的主机使用IP首部中的标识、标志和片偏移字段来完成对片的重组。 同样的标识和不同的偏移让接收方可以对分片进行重组, 当MF = 0的分片被接收到时,重组程序才能确定原始数据报的长度, 它等于分片偏移字段的值(乘以8)加上当前分片IPv4总长度字段的值。。 标识(Identification):当创建一个 IP数据报时,源主机为该数据报加上一个标识号。 当一个路由器需要将一个数据报分片时,形成的每个数据报(即片)都具有相同的原始数据报的标识号。 当目的主机收到来自同一发送主机的一批数据报时,它可以通过检查数据报的标识号以确定哪些数据报是属于同一个原始数据报的片。 更多分片(More Fragments, MF)IP首部中的标志位有3个比特,但只有后2个比特有意义,分别是MF位和DF位(Don’t Fragment),标志指明该数据报后面是否还有更多的分组。 只有当DF=0时,该IP数据报才可以被分片。 MF则用来告知目的主机该IP数据报是否为原始数据报的最后一个片。 当MF=1时,表示相应的原始数据报还有后续的片; 当MF=0时,表示该数据报是相应原始数据报的最后-一个片。 目的主机在对片进行重组时,使用片偏移字段来确定片应放在原始IP数据报的哪个位置。 分片偏移(Fragment offiet)偏移量是用来记录每个分片所在的位置, 偏移量=相对分片报文长度/8; 假设一共传输3800字节,mtu为1400字节,由于固定ip首部为20字节, 因此实际传输长度为1420字节,所以只需要传输三次,1400+1400+1000, 那么第一片偏移为0,第二片偏移=1400/8=175,第三次偏移=2800/8=350. 分片偏移量计算。例: 考虑向一条具有1500字节的MTU的链路发送一个8000字节的数据报(首部20字节,数据部分7980字节), 假定初始化数据报具有序列号321,这将会生成多少个片?它们的特征是什么? 答: 因为IP数据报首部占20字节,因此在每个分片中片的大小是1500-20=1480个字节, 故原始数据报中7980字节数据必须被分配到7980/1480=6个片中。 所以7980字节数据必须被分配到6个独立的片中(每个片也是一一个IP数据报)。 由于偏移值的单位是8字节,所以除了最后一个片外,其他所有片中的有效数据载荷都是8的倍数。 每个片的标识号都为321.前5个片的MF=1(还有分片),最后一个片的MF=0(表示最后一个分片) 例:分片报文实例分析 1、首片
灰底的Fragment offset:1480 那行对应的十六进制码是蓝底的0X20b9, 刚开始很疑惑为何十进制的1480对应的是0x20b9,怎么算都不对啊,不知道读者您是不是遇到了这样的疑惑! 参考RFC791中相关字段的说明 才明白原来这个1480指的是偏移的实际字节而不是 fragment offset字段中比特位对应的十进制数值。 该字段的是以8个“八比特组”为单位的,所以1480在该字段的值是除以8之后的185,换算成二进制就是0 0000 1011 1001,因为前面还有个值为001的3比特的Flag字段,所以加上Flag字段后其二进制值是0010 0000 10111001,换算成二进制就是20b9。请自己算算吧。弄不明白的需要先掌握数据包结构及进制等基础了。 查阅RFC791,所述如下: The data of the long datagram is divided into two portions on a 8 octet (64 bit) boundary(the second portion might not be an integral multiple of 8 octets,but the first must be). 分片偏移是要按8 octet来对齐的,也就是按8字节对齐(分片偏移:即8字节为单位),所以这里的一个单位应该是8字节, 185单位 * 8字节 =1480字节,也就对的上了。 关于octet,大多数因特网标准使用八位组(octet)这个术语而不是使用byte来表示8位的量,早期的一些系统的byte表示的bit不一致,有的byte表示10bits,所以octet是准确定义的,1 octet = 8 bit; 另外,这里是标识 + 分片偏移,一起组合成的十六进制码 20b9,wireshark 中也清楚展示了,flags 是最高三位的 001,分片偏移是剩下的13位: 0 0000 1011 1001, 所以, 20b9 = 0010 0000 1011 1001. 3、最后一片
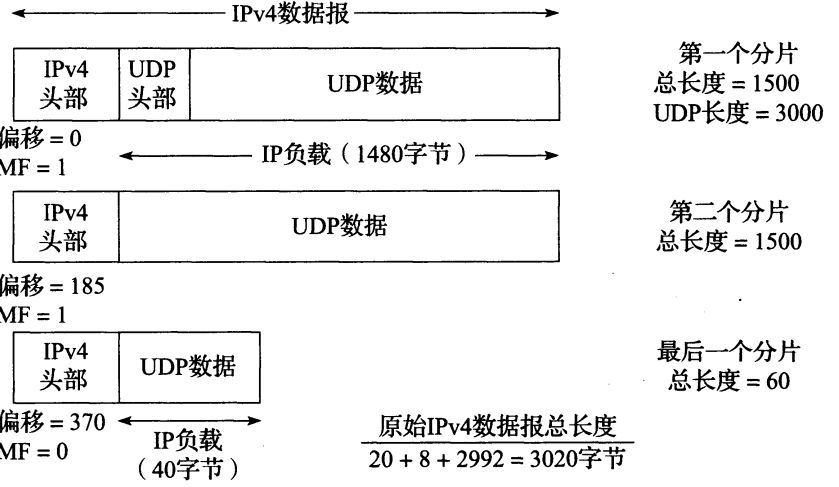
例:下图是一个长度为3000字节的udp包(包括了udp包头的8个字节)。 原始数据报要加上ipv4包头为3020字节,它超过了MTU的限制,因此发送的时候会进行分片。 第一个分片中实际传送了1472字节的udp数据和8字节udp包头。 此时偏移为0,因为接下来还有数据包要发因此MF置为1 第二个分片传送1480字节的udp数据,因为第一个分片已经传送了1480,因此这里的偏移为1480/8 = 185,因为接下来还有数据包要发因此MF置为1 最后一个分片传送剩下的40字节数据,并将MF置为0,此时接收方可以通过370*8+60来算出原始数据报的长度,因此也知道了udp包的大小为3000字节(减掉ip包头的20字节)。
我们发现它和我们上一节讲的不太一样,UDP包按理应该是第一个出现,之后跟着一串分片后的IPv4包。而打开上面截图里所有的IPv4包我们发现它们的MF标志全都是1,且最后的udp包的length明显大于了MTU。 这是因为wireshark的首选项中自动开启了重组分片数据的选项。这个默认开启的选项能直接帮我们重组原udp数据包并用它替换了MF=0的那个IPv4数据包,因此在开启该选项时我们是找不到MF=0的数据包的。
IPv6并没有完全放弃分片机制,只是说它用一种完全不同的机制来实现分片。 熟悉IPv4的肯定知道IP分片这个特性,它在某种意义上让应用程序忘记了数据包还有 大小这个属性,也就是说,应用程序可以发送小于IP头规定的最长65535字节的任意大 小的数据包。 IPv4严格采纳分层模型,让路径MTU这种事做到对应用程序完全透明而无感知。 如果路径MTU太小不足以让大数据报文通过,那么分片这种机制便开始起作用。 而IPv6网络的分片和实现,网络只管转发,分片这种端到端功能自然需要卸载到通信双方终 端主机!IPv6禁止中间节点设备对IP报文进行分片。分片只能在端到端进行! IPv6禁止了中间设备分片,卸载了一些信息处理流程。最终目的是让IPv6报头成为固定 的长度,且内部字段对齐,便于高效预取或者直接通过固定硬件处理,从而达到提高 处理性能的目的。 既然在路由器等转发设备上去掉分片机制这么好,那么为什么在端主机还允许分片, 直接全部禁止了不更好吗? 我们知道,应用层对于数据报文的解释,它代表了一个数据报呢,还是说代表一个流。 如果是代表一个流,那么一切OK,只要持续发送数据流字节即可, 网络情况好了就一次多发几个字节,网络情况不好了就少发几个甚至发1个字节,都无所谓。 但是对于用户数据报,比如UDP报文这种,就不行了。 UDP报文是严格按照报文长度发送和接收的,应用程序之间定义了一个2000字节的应用层协 议,那么一个报文就必须是2000字节长,不能说你IPv6为了转发效率而不让人家发长报文吧。 因此,IPv6不能完全放弃分片机制,只是说它用一种完全不同的机制来实现分片:1.分片和重组只能在端主机进行。 2.分片信息不在IPv6协议标准头里,而单独设计一个扩展头存放。 如此做,IPv6相当于: 报文始发站完全可以通过PMTU知晓链路最小MTU,这完全是端到端行为,卸载了跟网络没有毛线关系的额外动作。 IPv6等效于IPv4永久无条件设置Don’t Fragment标识(但并不绝对,对于1280以下MTU则例外!后面讲)。 卸载了IPv4头的分片相关字段后,这些分片字段便放在了扩展头里面 如果仅仅是以上的简单规定,那么在实现的时候将会遇到很多无法避开的问题: 在端主机只知道自己的链路MTU,如何知道中间路径的最小MTU,即如何确定要不要分片? 计算通过MTU发现找到了最小MTU,如何保证实际数据传输时就是按照MTU探测时的路径走的? … PMTU的实现过程,我这里依然不谈,我要说的是,IPv6为了让分片不那么频繁进行,依靠宣传力量 强制建议了一个规则 ,即 所有传输IPv6报文的链路都要提供1280字节以上的MTU容量! 呵呵,强制建议,意思是你必须实现它,如果你不实现,我也没有办法,毕竟为了保持网路的透明性,不能把事情做绝,但是求求你实现它好吗?我这可是IPv6的标准啊! 那么,为什么是1280字节?这是一个权衡的结果。 如果限制的最小MTU太小,那么将会有很多链路为了成本或者其它博弈结论考虑,提供小的MTU,如此一来,这种 不得不进行 的补救分片方案就会非常多,相当于抵消了IPv6禁止分片的收益。 小分片非常容易助力网路的拥塞,如果拥塞控制队列机制是基于包而不是基于自己的话,这会更加严重,并且小分片,特别是TCP段的小分片,一个丢失则整个重传,这会增加链路的重传率。 考虑到隧道封装协议的广泛存在以及以太网1500字节MTU的普遍性,1280空出220字节给隧道使用,足够了。 不管大了还是小了都不好,那么什么样的限制最好呢? 关于这点,我倒是有个形而上的想法,即整个互联网上所有链路MTU的方差,均差越小越好!即 大家的MTU都往使用最多的MTU的附近凑! 由于我们需要限制的是最小MTU,那么就是使用最多的1500,其下面不远的位置,照顾到隧道协议,空出足够的220字节,就选1280字节!完美。 那如果就有人有意或者无意,考虑到底层链路的硬件投资,考虑到兼容性,其MTU小于1280字节,怎么办? 没办法,还是要分片的,这就是 不得不进行的分片 1、第一片
|
 标志
标志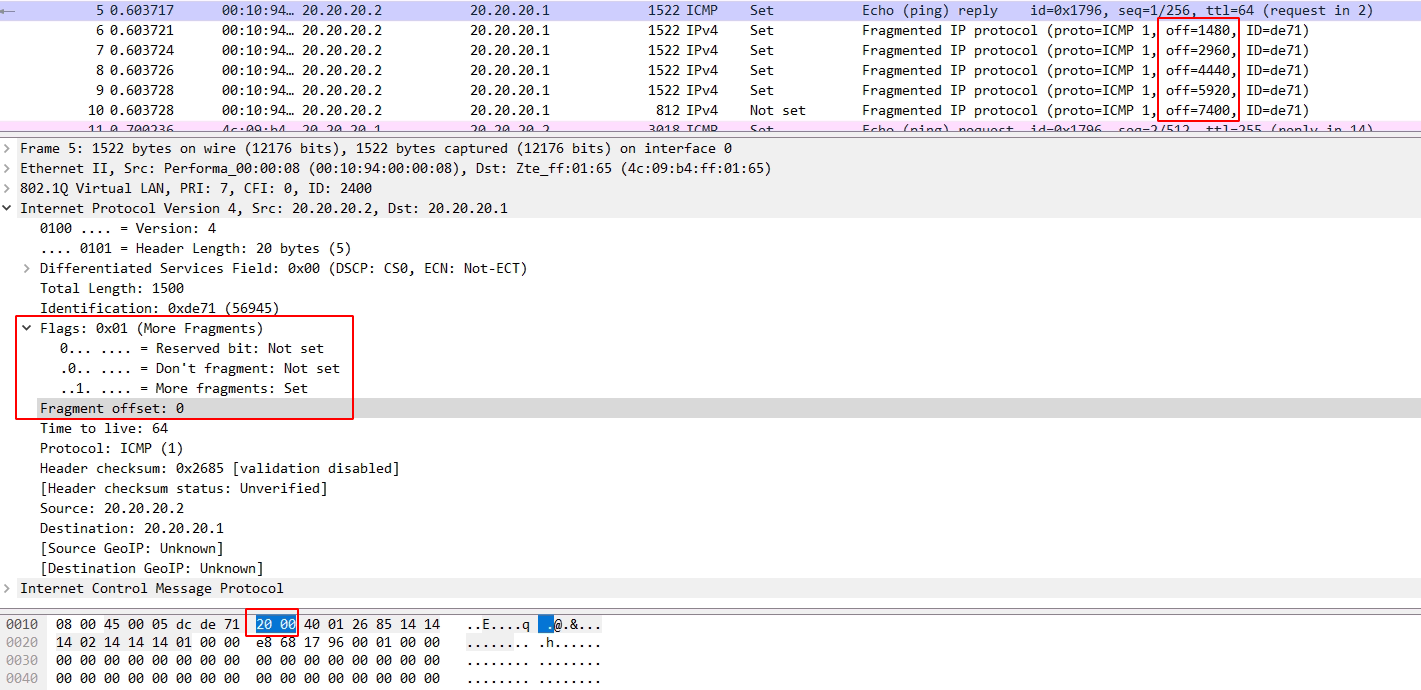
 wireshark中的抓到的报文(wireshark默认设置)
wireshark中的抓到的报文(wireshark默认设置)
 我们打开第一个UDP包,它的数据如下:
我们打开第一个UDP包,它的数据如下: 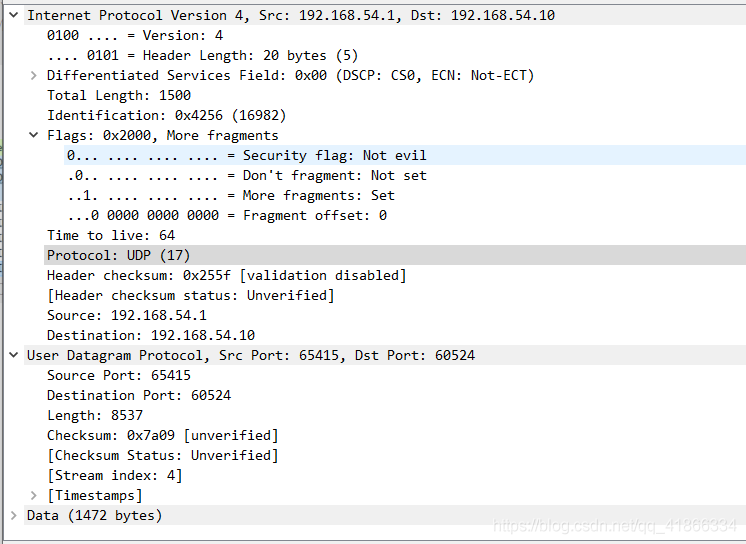 我们可以知道虽然它包头中的长度给出的Length为8537(包含8个字节包头,实际数据为8529字节),但是真实的Data里只有1472字节,1472+8(UDP包头)+20(IP包头) = MTU。我们再看这一组最后一个IPv4包:
我们可以知道虽然它包头中的长度给出的Length为8537(包含8个字节包头,实际数据为8529字节),但是真实的Data里只有1472字节,1472+8(UDP包头)+20(IP包头) = MTU。我们再看这一组最后一个IPv4包: 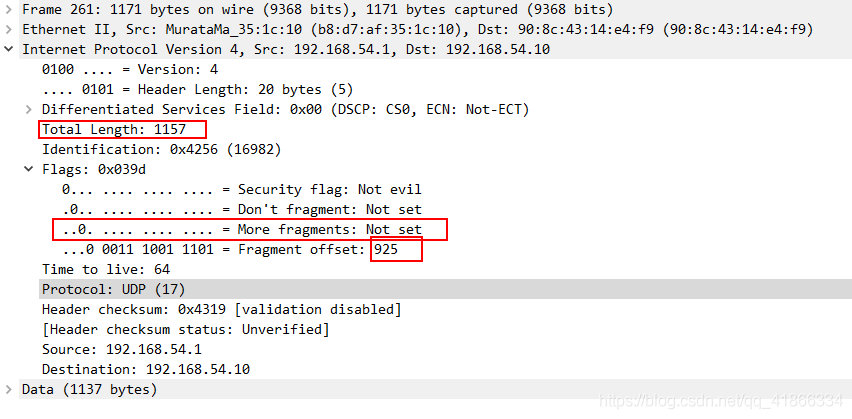 我们可以看到它的MF=0,因此计算925*8+1157 = 8557,这是原始的数据报文,减掉20字节的IP包头,恰好为8537字节。与UDP包中所给的Length值一样。
我们可以看到它的MF=0,因此计算925*8+1157 = 8557,这是原始的数据报文,减掉20字节的IP包头,恰好为8537字节。与UDP包中所给的Length值一样。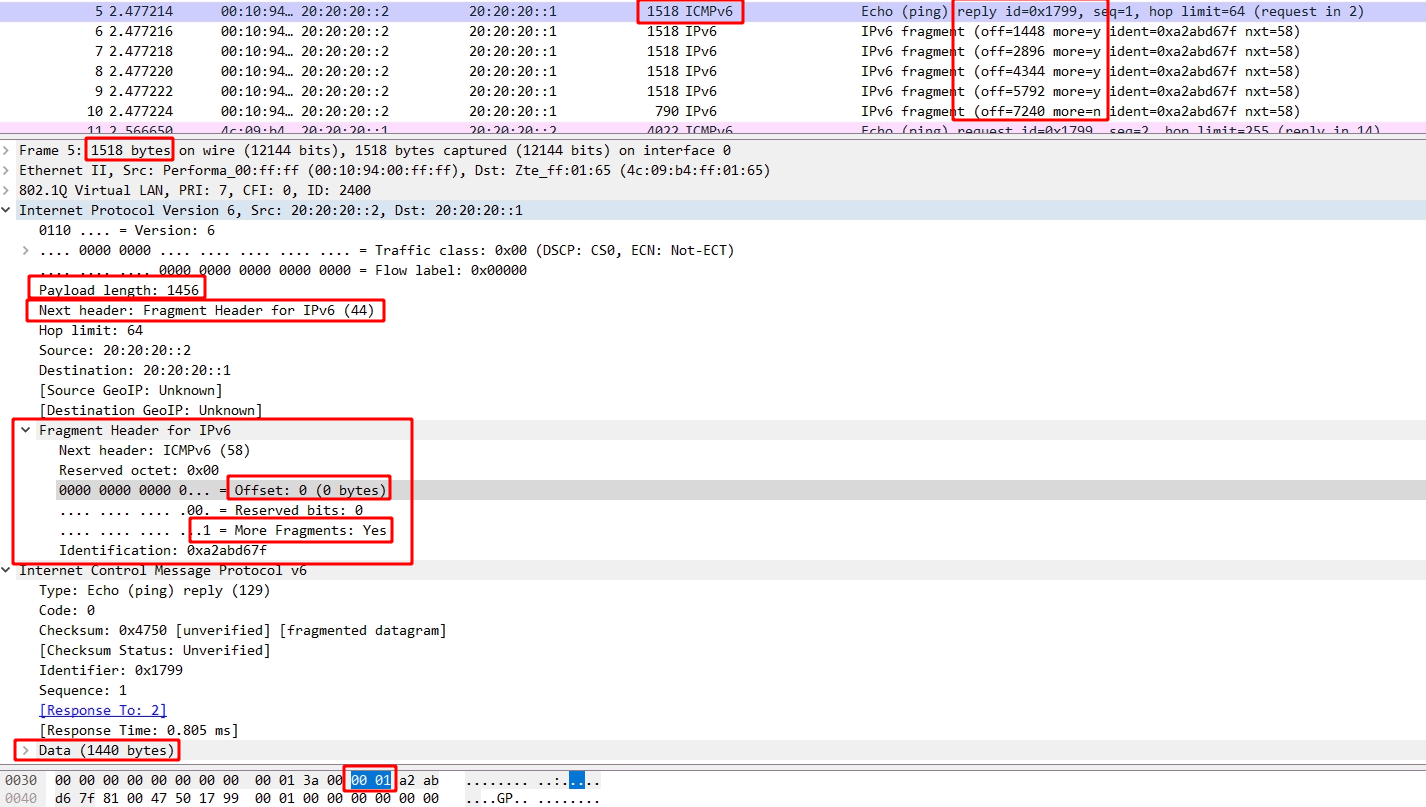
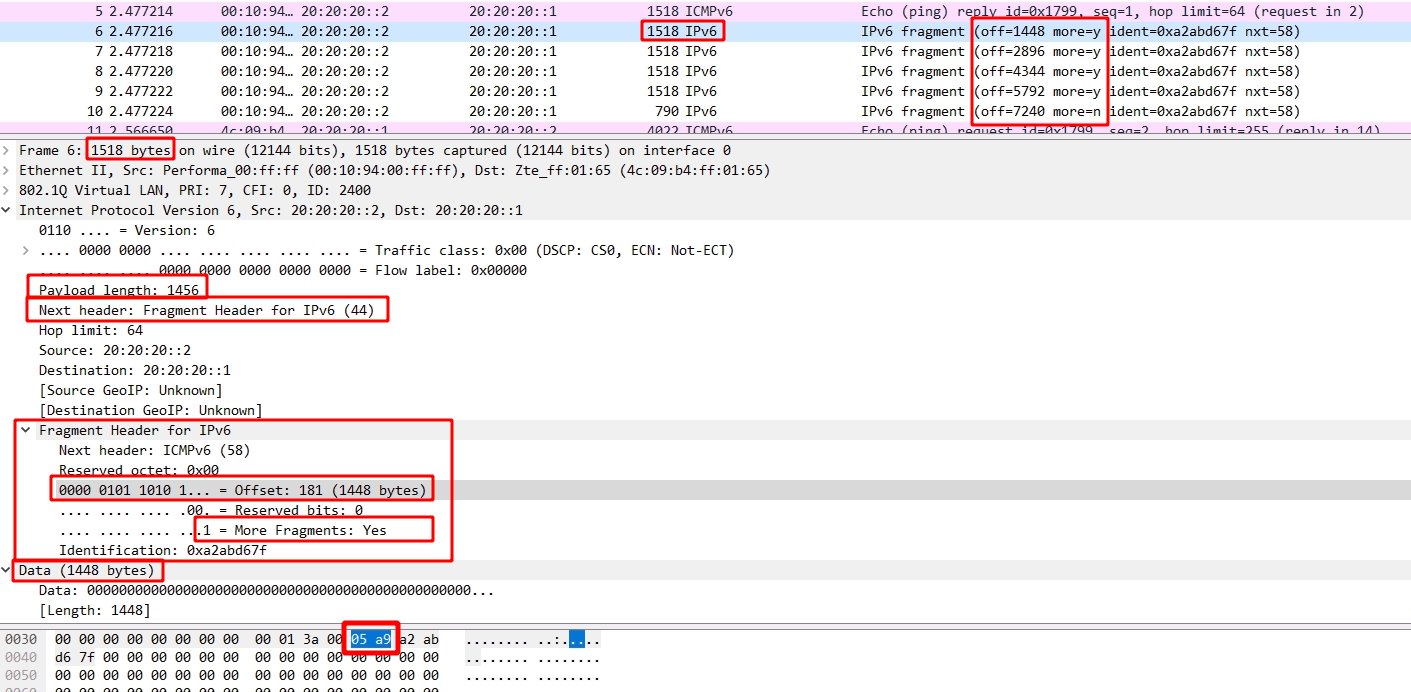
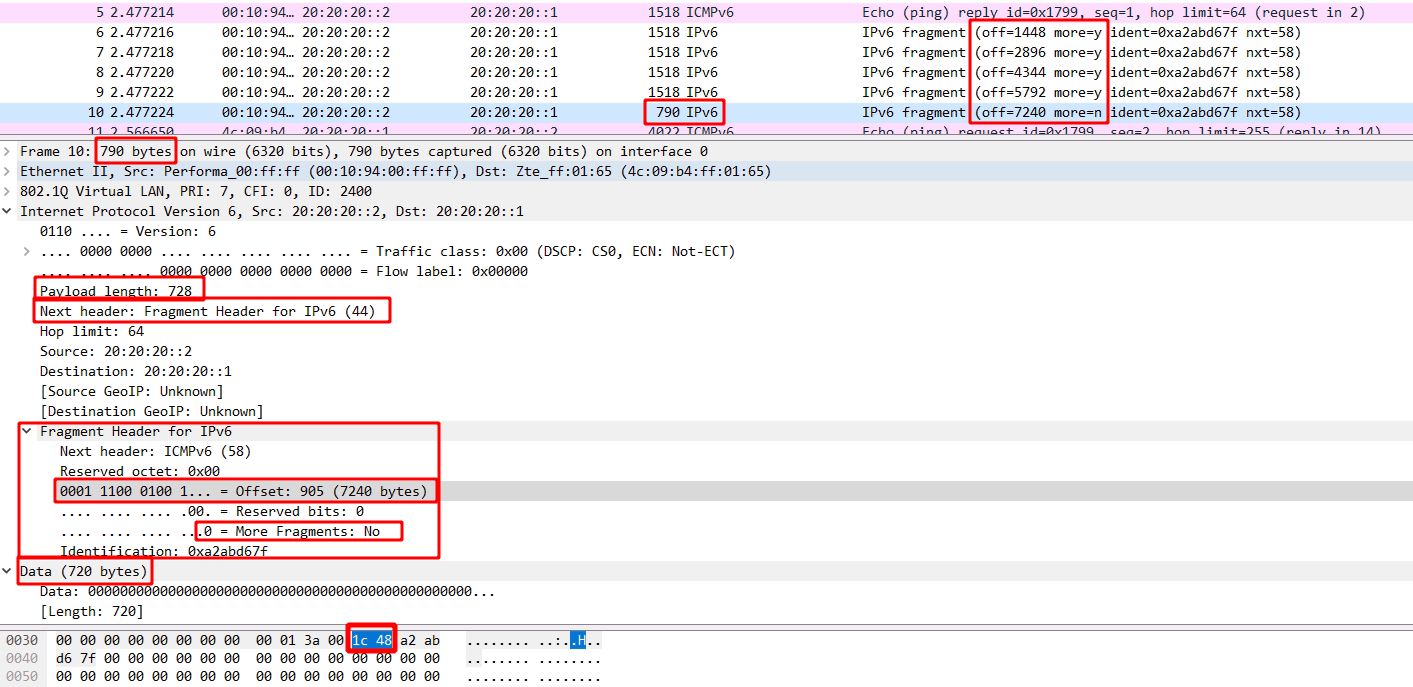
【本文地址】
今日新闻 |
推荐新闻 |