宋词自动生成系统和中文分词系统 |
您所在的位置:网站首页 › 诗词自动生成器程序 › 宋词自动生成系统和中文分词系统 |
宋词自动生成系统和中文分词系统
|
*****************2020年10月7日修改******************** 已经是3年前做的项目了,感觉搜索到这个文章的大部分应该都是学弟学妹(笑)。 如果没有记错,自然语言处理应该是工大计算机学院大二下的课程,也就是每年9月之后,这个文章的阅读量会有一波增长。 但是其实现在回想一下,项目里的很多细节我都记得不是很清晰了,但是依然记得谷雨老师的课上的很好,所以希望大家都可以在这门课里有所收获。特别是对nlp有兴趣的同学,可以修这门课其实还挺幸运的。 和这个课程项目配套的有一篇自然语言处理的课程笔记文章,我附在下面仅供参考: 然后就是最近更换了GitHub,所以我有重新上传了repo,链接如下: 因为我当时比较懒,没用写项目介绍之类的,所以文章下面的内容基本就是课设的内容,所以不建议大家抄,如果被发现可能成绩结果不太好(。・ω・。) 如果你觉得对你有所帮助的话,希望可以给repo一个star,以及给文章收藏和点赞。 ****************以下为原文部分***************** 简单介绍一下,这个只是笔者这学期学习自然语言课程的实验情况,主要做了宋词自动生成系统和中文分词系统。做法都很简单,但是过程还是蛮有趣的。 实验1 宋词词频统计研究背景: 对语料库的分析和词频统计是自然语言学科实验的基础,通过大规模语言数据进行知识获取从而完成后续实验内容。 实验要求: 编写程序,输入ci,自动分析统计ci.txt,统计宋词的单字词,双字词等。统计后,输出的是单字词和双字词的词典文件。文件中包括相应的词和频度(次数)。 实验步骤: 系统设计: 1.下载并分析词库 训练词库下载链接:https://pan.baidu.com/s/1c2basik 密码:jr5a 词库的每一行的内容分成: 一行词牌名 一行宋词 宋词段中会出现“,”、“。”、“、”等标点符号 一般的词牌名的长度不会超过8个字(经过反复测试得到的) 这里首先我们对词库进行一次冲洗,洗掉其中的词牌名和标点符号: 去掉词牌名: try{ FileReader fr = new FileReader( "/Volumes/Untitled/workplace/Ci.txt"); @SuppressWarnings("resource") BufferedReader br = new BufferedReader(fr); String line = ""; while(line!=null) { line = br.readLine(); if(line == null){ break; } else if(line.length()>8) {solution.solveLine(line);}去掉标点符号: static String[] lineParser(String line, int scale){ String[] lineDicts = null; if(line != null ) { String[] spliter = line.split("\\s+|,+|。+|、"); List container = new ArrayList(); for(int i=0; i2.使用Hashmap进行统计词频 考虑到文件的大小为3M左右,大约有150万字左右。如果用简单的方法统计词频会花费很长的时间,(粗略的估计1万字需要花费20~30分钟)所以这里采用了Hashmap。 系统演示与分析: 词频统计1: 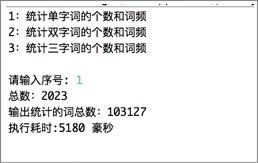 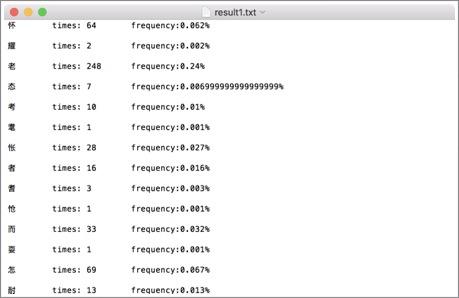 词频统计2:  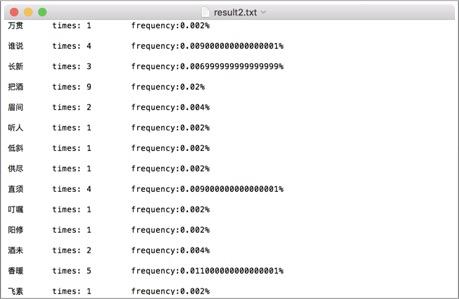 词频统计3:  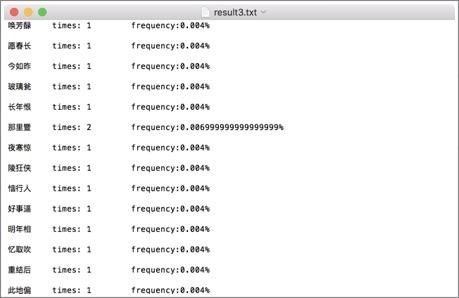 分析:先开始在windows下编程,并没有出现因为编码而出现问题。后来将代码拷到了MAC上后才发现原来的词库的编码是GBK,所以直接在eclipse中把默认的读取utf-8编码格式换成了GBK,但是这影响了后面的宋词自动生成系统的网页生成。 实验2 宋词自动生成研究背景: 通过实现宋词自动生成系统学习语言模型。 实验要求: 要求:输入词牌,基于宋词的词典和宋词的词牌,可以随机或者按照语言模型,自动生成宋词。设计相应的Ui或者Web界面。 模型方法与系统设计: 模型方法:随机生成宋词 系统设计: 1.研究词的格律: 选取两个词牌的样本: 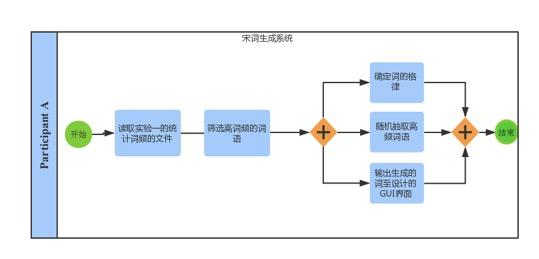 public static String 醉花阴(){
print("\n");
int temp = (int) ( Create(2).firstElement().size() * Math.random() + 0);
int temp1 = (int) ( Create(2).firstElement().size() * Math.random() + 0);
int temp2 = (int) ( Create(3).firstElement().size() * Math.random() + 0);
String con1="";
con1=Create(2).firstElement().get(temp)+Create(2).firstElement().get(temp1)+Create(3).firstElement().get(temp2);
System.out.println(con1);
int temp3 = (int) ( Create(2).firstElement().size() * Math.random() + 0);
int temp4 = (int) ( Create(1).firstElement().size() * Math.random() + 0);
int temp5 = (int) ( Create(2).firstElement().size() * Math.random() + 0);
String con2="";
con2=Create(2).firstElement().get(temp3)+Create(1).firstElement().get(temp4)+Create(2).firstElement().get(temp5);
int temp6 = (int) ( Create(2).firstElement().size() * Math.random() + 0);
int temp7 = (int) ( Create(1).firstElement().size() * Math.random() + 0);
int temp8 = (int) ( Create(2).firstElement().size() * Math.random() + 0);
String con3="";
con3=Create(2).firstElement().get(temp6)+Create(1).firstElement().get(temp7)+Create(2).firstElement().get(temp8);
System.out.println(con3);
int temp9 = (int) ( Create(2).firstElement().size() * Math.random() + 0);
int temp10 = (int) ( Create(2).firstElement().size() * Math.random() + 0);
String con4="";
con4=Create(2).firstElement().get(temp9)+Create(2).firstElement().get(temp10);
System.out.println(con4);
int temp11 = (int) ( Create(2).firstElement().size() * Math.random() + 0);
int temp12 = (int) ( Create(3).firstElement().size() * Math.random() + 0);
String con5="";
con5=Create(2).firstElement().get(temp11)+Create(3).firstElement().get(temp12);
System.out.println(con5);
String songpoem="";
songpoem=con1+"\n"+con2+"\n"+con3+"\n"+con4+"\n"+con5;
return songpoem;
} public static String 醉花阴(){
print("\n");
int temp = (int) ( Create(2).firstElement().size() * Math.random() + 0);
int temp1 = (int) ( Create(2).firstElement().size() * Math.random() + 0);
int temp2 = (int) ( Create(3).firstElement().size() * Math.random() + 0);
String con1="";
con1=Create(2).firstElement().get(temp)+Create(2).firstElement().get(temp1)+Create(3).firstElement().get(temp2);
System.out.println(con1);
int temp3 = (int) ( Create(2).firstElement().size() * Math.random() + 0);
int temp4 = (int) ( Create(1).firstElement().size() * Math.random() + 0);
int temp5 = (int) ( Create(2).firstElement().size() * Math.random() + 0);
String con2="";
con2=Create(2).firstElement().get(temp3)+Create(1).firstElement().get(temp4)+Create(2).firstElement().get(temp5);
int temp6 = (int) ( Create(2).firstElement().size() * Math.random() + 0);
int temp7 = (int) ( Create(1).firstElement().size() * Math.random() + 0);
int temp8 = (int) ( Create(2).firstElement().size() * Math.random() + 0);
String con3="";
con3=Create(2).firstElement().get(temp6)+Create(1).firstElement().get(temp7)+Create(2).firstElement().get(temp8);
System.out.println(con3);
int temp9 = (int) ( Create(2).firstElement().size() * Math.random() + 0);
int temp10 = (int) ( Create(2).firstElement().size() * Math.random() + 0);
String con4="";
con4=Create(2).firstElement().get(temp9)+Create(2).firstElement().get(temp10);
System.out.println(con4);
int temp11 = (int) ( Create(2).firstElement().size() * Math.random() + 0);
int temp12 = (int) ( Create(3).firstElement().size() * Math.random() + 0);
String con5="";
con5=Create(2).firstElement().get(temp11)+Create(3).firstElement().get(temp12);
System.out.println(con5);
String songpoem="";
songpoem=con1+"\n"+con2+"\n"+con3+"\n"+con4+"\n"+con5;
return songpoem;
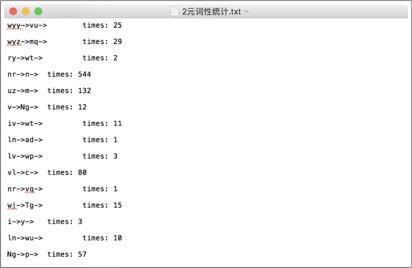
}构造输出的宋词模型:  系统演示与分析: 可以生成两种词牌的宋词。 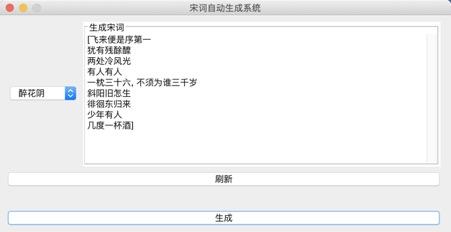 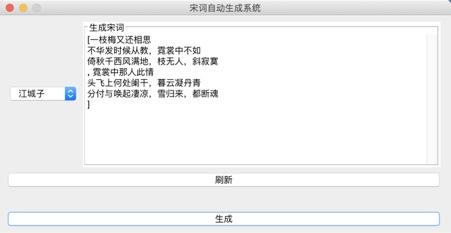 设计的web界面 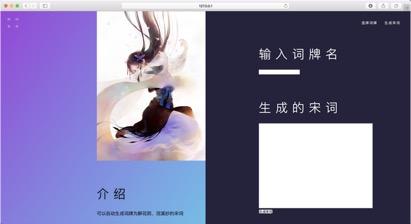  网页设计链接:https://pan.baidu.com/s/1i4KBfBB 密码:o77j 实验3 中文词频统计研究背景: 对语料库的分析和词频统计是自然语言学科实验的基础,通过大规模语言数据进行知识获取从而完成后续实验内容。 实验要求: 输入txt文件,统计1元模型和2元模型,输出单词和词频文件,双词和词频文件。设计相应的接口,能够快速载入文件,并检索单词和双词。 实验步骤: 1.下载并分析语库: 下载训练文库链接:https://pan.baidu.com/s/1nuTW1mT 密码:hwjh 分析文本: 例句: 19980101-01-001-001/m 迈向/vt 充满/vt 希望/n 的/ud 新/a 世纪/n ——/wp 一九九八年/t 新年/t 讲话/n (/wkz 附/vt 图片/n 1/m 张/qe )/wky 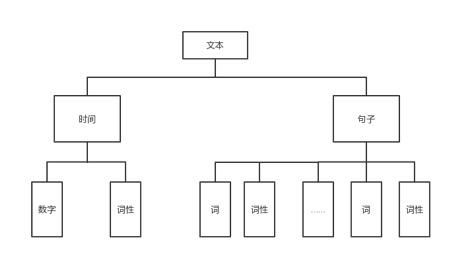 2.确定相应的冲洗文本的流程如下: 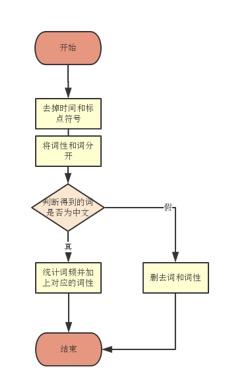 3.编写过滤代码: public void solveLine(String line){ for(int i=0;i2-gram的词语统计:  输入测试单词: “我” 输入测试双字词: “你好”  判断识别成功! 实验4 中文词法分析系统研究背景: 在课堂上学习了汉语分词的概要和隐式马尔可夫模型,了解了分词系统的算法,例如向前最长匹配和向后最长匹配算法。现在通过本次实验来自己实现中文词法分析系统,更加深刻认识分词的方法。 实验要求: 根据构建的单词词典和双词词典,用n-gram模型,或者前向最长匹配,或者后向最长匹配等算法,鼓励用更复杂一些的方法来进行,包括隐马尔科夫模型和条件随机场模型。 模型方法与系统设计: 模型方法: 1.隐式马尔可夫模型(HMM): 算法1:前向算法 (1) 初始化: a_1(i)=π_ib_i(O_1) , 1 ≤i ≤ N (2) 循环计算: α_{t+1}(j)=[∑^{i=N}_{i=1}α_t(i)a_{ij}]b_j(O_{t+1}), 1≤t ≤T −1 (3) 结束,输出: p(O|μ) =∑^{i=N}_{i=1}αT(i) 算法2:后向算法 (1)初始化: β_T(i) =1 , 1≤i ≤ N (2)循环计算: β_t(i) =∑^{j=N}_{j=1}a_{ij}b_j(O_{t+1})β_{t+1}(j), T −1≥t ≥1, 1≤i≤ N 算法3:Viterbi 算法 (1)初始化:δ1(i) =πibi(O1), 1≤i ≤ N 概率最大的路径变量:ψ1(i) = 0 (2)递推计算: 1≤i≤N ψ_t( j) =argmax_{1≤i≤iN}[δ_{t−1}(i)⋅a_{ij}]⋅b_j(O_t), 2≤t ≤T, 1≤i ≤ N (3)结束: Q_T=argmax_{1≤i≤N}[δ_T(i)], p(Q_T)maxT(i)1 经过统计发现,预料库中的词性状态一共有150多种,而且在2-gram的时候在已知当前输出状态的前提下获得下一个状态的概率太小。(虽然老师提出可以在数值很小的情况下可以取对数放大,但是最后还是放弃了。) 综合讨论语料库的问题,最后还是只采用了前向最大匹配的算法进行中文分词: FMM算法实现: public static String fmm(String s) { ArrayList list= new ArrayList(); int max=s.length(); String tryWord=null; tryWord= s; //取指定的最大长度的文本去词典里面匹配 while(s.length()>0) { if(Judge.judge(tryWord)){ list.add(tryWord+"/"); //从待分词文本中去除已经分词的文本 s=s.substring(tryWord.length()); tryWord=s; }else { //如果匹配不到,则长度减一继续匹配 if(tryWord.length()>1) { tryWord=tryWord.substring(0, tryWord.length()-1); }else { break;} } }最后系统设计如下图所示: 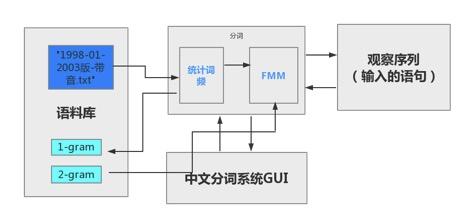 系统演示与分析: 测试语句: “也许我们都知道了” 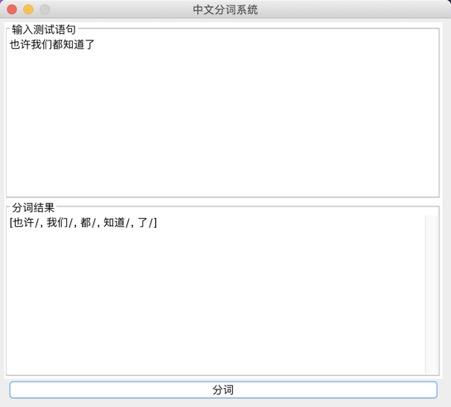 存在的问题: 问题1: 词库太小,有一些词找不到,会导致分词自动结束,如下: 测试选自《圣经》中的“我们经过的日子都在你的震怒之下,我们度尽的年岁好像一声叹息” 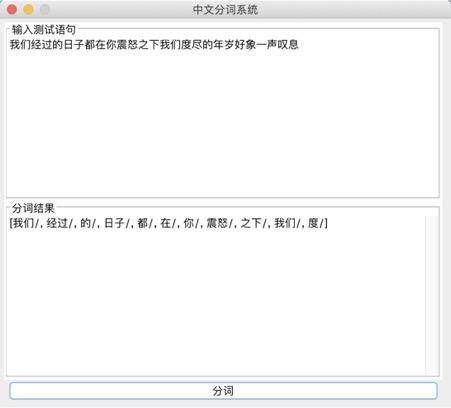 问题二: 没有办法解决有歧义的句子的分词 例如:“北京人多”可以解释为“北京”+“人多”也可以解释为“北京人”+“多”,演示之后发现为“北京/人/多” 记得在开视频的时候,底下的评论有一句“这样喝水水会流到喉咙里” 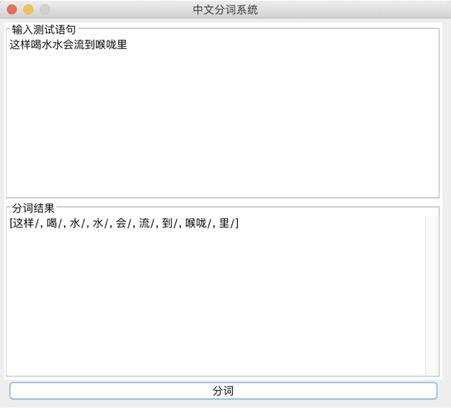 网友对这句话的理解也分成了两种: 1.这样喝水,水会流到喉咙里 2.这样喝水水,会流到喉咙里 我在这里也用自制的中文分词系统尝试了一下,发现,果然我的中文分词系统没有那么萌啊( ̄▽ ̄)。 实验结语完成所有实验之后觉得学习到了很多的东西,不仅仅是编写代码的能力提高了,老师给出的算法的思想更让我受益匪浅,在课程上和实验中同学们的相互讨论让人印象深刻。虽然实验过程中遇到了很多的问题,最后实现的功能也并不完全,但是还是很感谢老师的指导和同学的帮助。 |
【本文地址】