ABBYY的OCR识别语言设置教程 |
您所在的位置:网站首页 › 识别语言 › ABBYY的OCR识别语言设置教程 |
ABBYY的OCR识别语言设置教程
|
ABBYY FineReader PDF 15常常作为一款优秀的OCR文字识别软件被大家所熟知,其强大的OCR扫描功能能够精准识别文字并转化成可编辑可搜索文档,给我们的日常生活带来极大的便利。在使用ABBYY FineReader PDF 15的OCR扫描功能时,我们也必须要注意OCR识别语言的选择是否和图像扫描内容相匹配,如果语言设置不正确会导致OCR识别不出正确的文本内容。接下来,我就为大家讲解一下ABBYY的OCR识别语言设置教程。 第一、运行OCR编辑器 ABBYYFineReaderPDF15默认的OCR识别语言为简体中文和英语,如果我们要扫描的图像文本内容为日文,那么扫描出来的结果就会如图1所示为乱码。 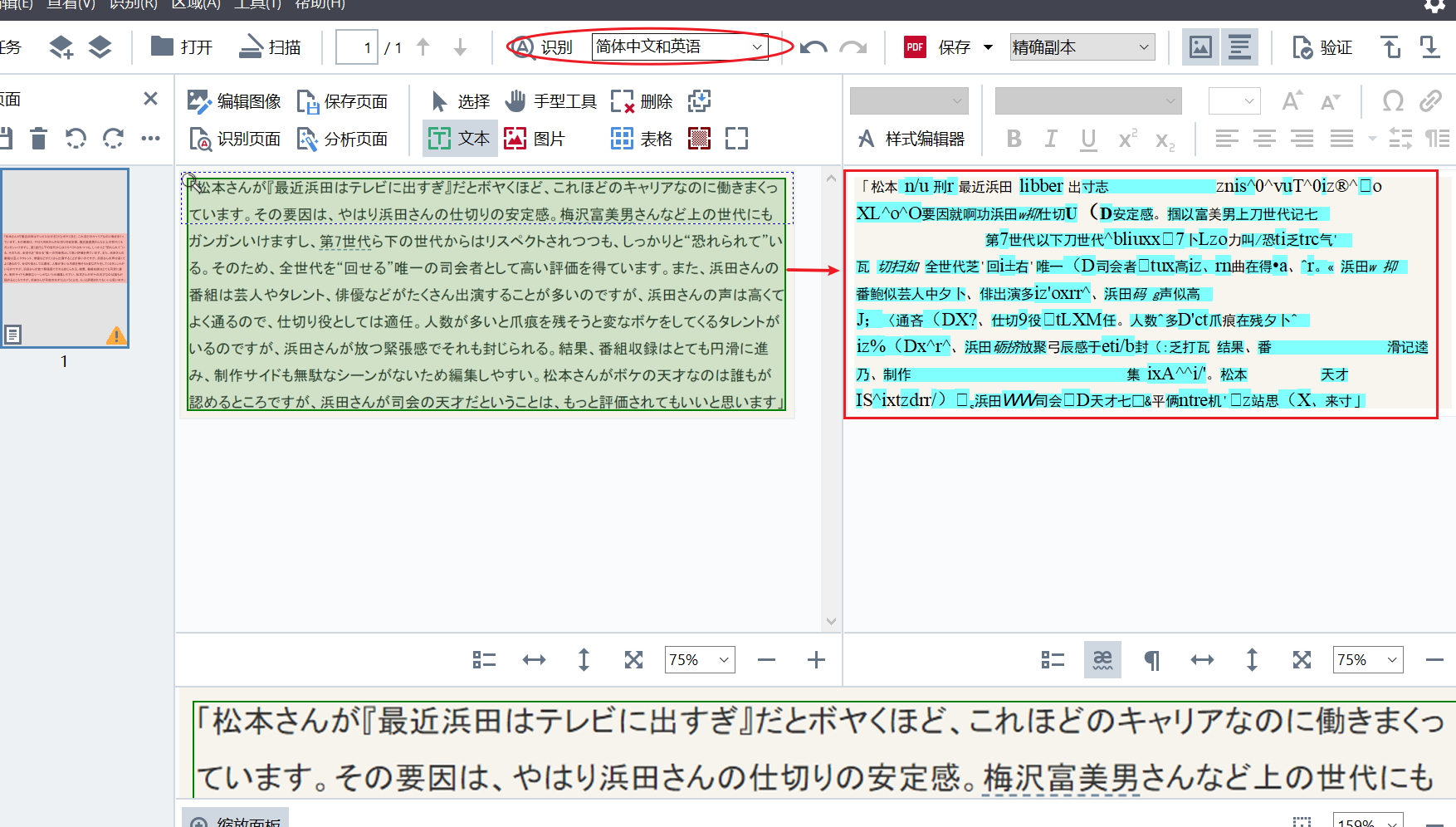 图1:ABBYYFineReaderPDF15OCR编辑器界面 图1:ABBYYFineReaderPDF15OCR编辑器界面
第二、设置OCR识别语言 打开OCR编辑器上方识别语言隐藏菜单,查看菜单栏内是否存在和扫描内容相匹配的语言。如果没有,点击底部“更多语言”选项,进一步查找匹配语言。 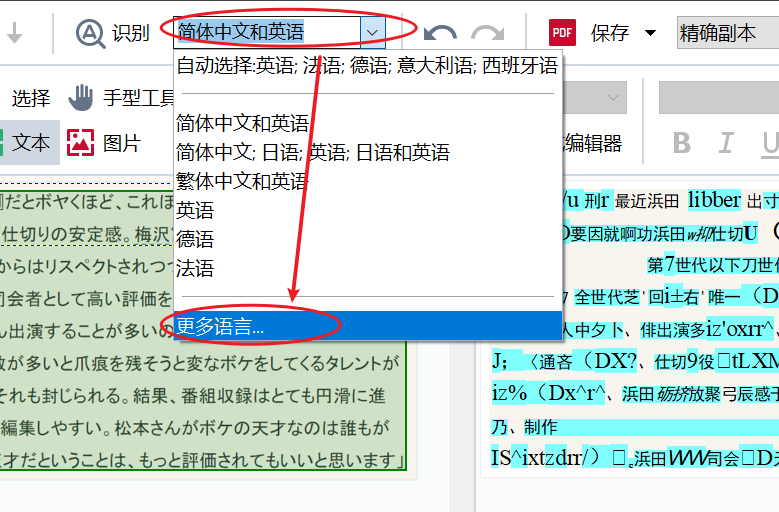 图2:设置OCR识别语言 图2:设置OCR识别语言
第三、手动指定OCR识别语言 进入OCR的语言编辑器界面后,在手动指定OCR语言栏内找到并勾选对应的语言,接着点击右下角的“确定”选项。 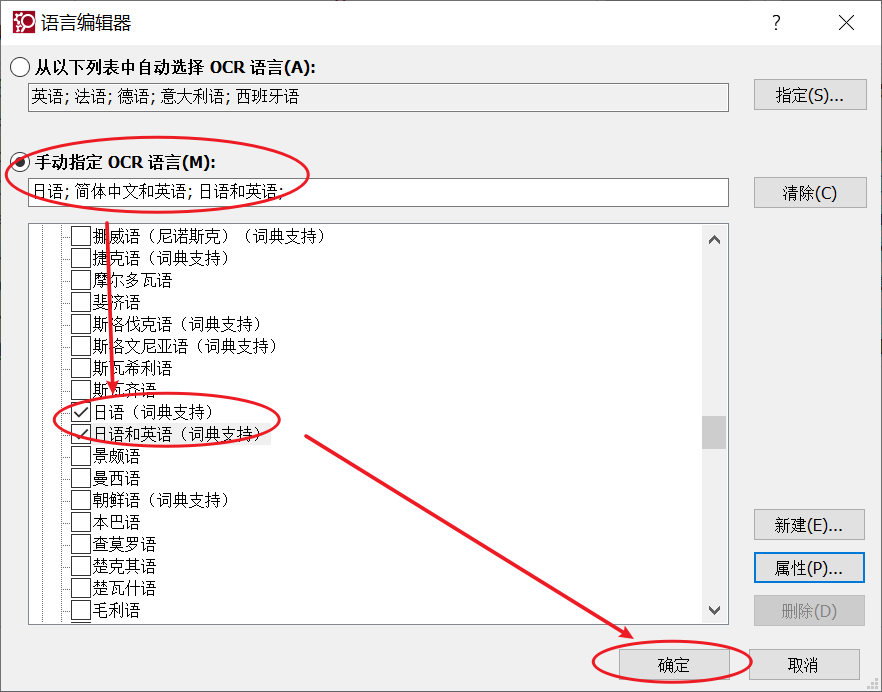 图3:手动指定OCR识别语言 图3:手动指定OCR识别语言
第四、重新扫描识别导入图像的文本内容 OCR语言重新设置之后,回到OCR编辑器主界面,点击“识别”选项对导入图像进行OCR扫描转化操作。如图4所示,此时转化后的文本与左侧图像对比精确度极高,如果检查后出现识别偏差,我们可以直接在右侧转化文本上进行修改。 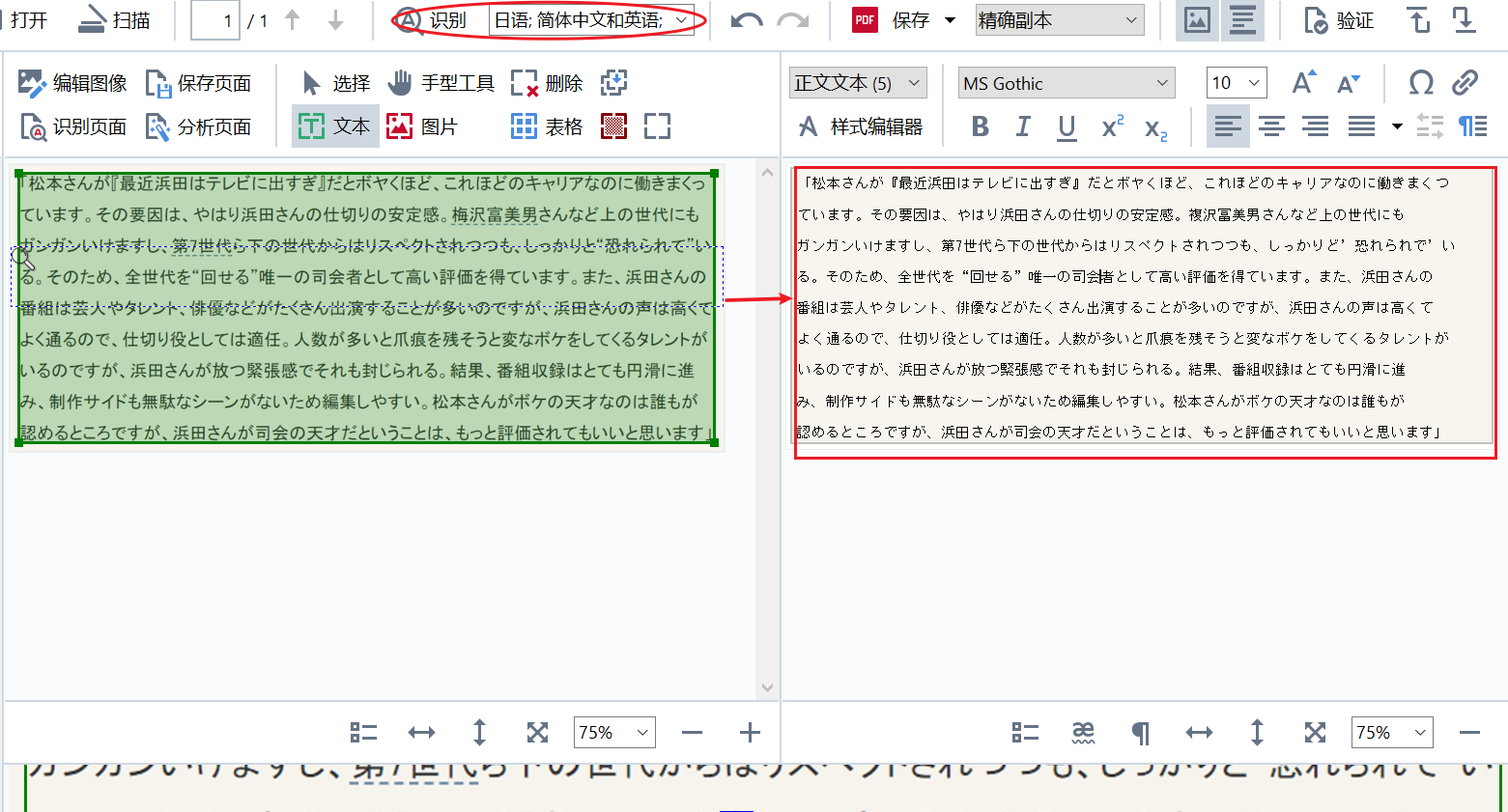 图4:重新扫描识别导入图像的文本内容 图4:重新扫描识别导入图像的文本内容
此外,我们还可以点击ABBYYFineReaderPDF15主界面左下角的“选项”设置,在弹出的设置界面中找到语言设置界面,在语言设置界面中重设OCR的识别语言。 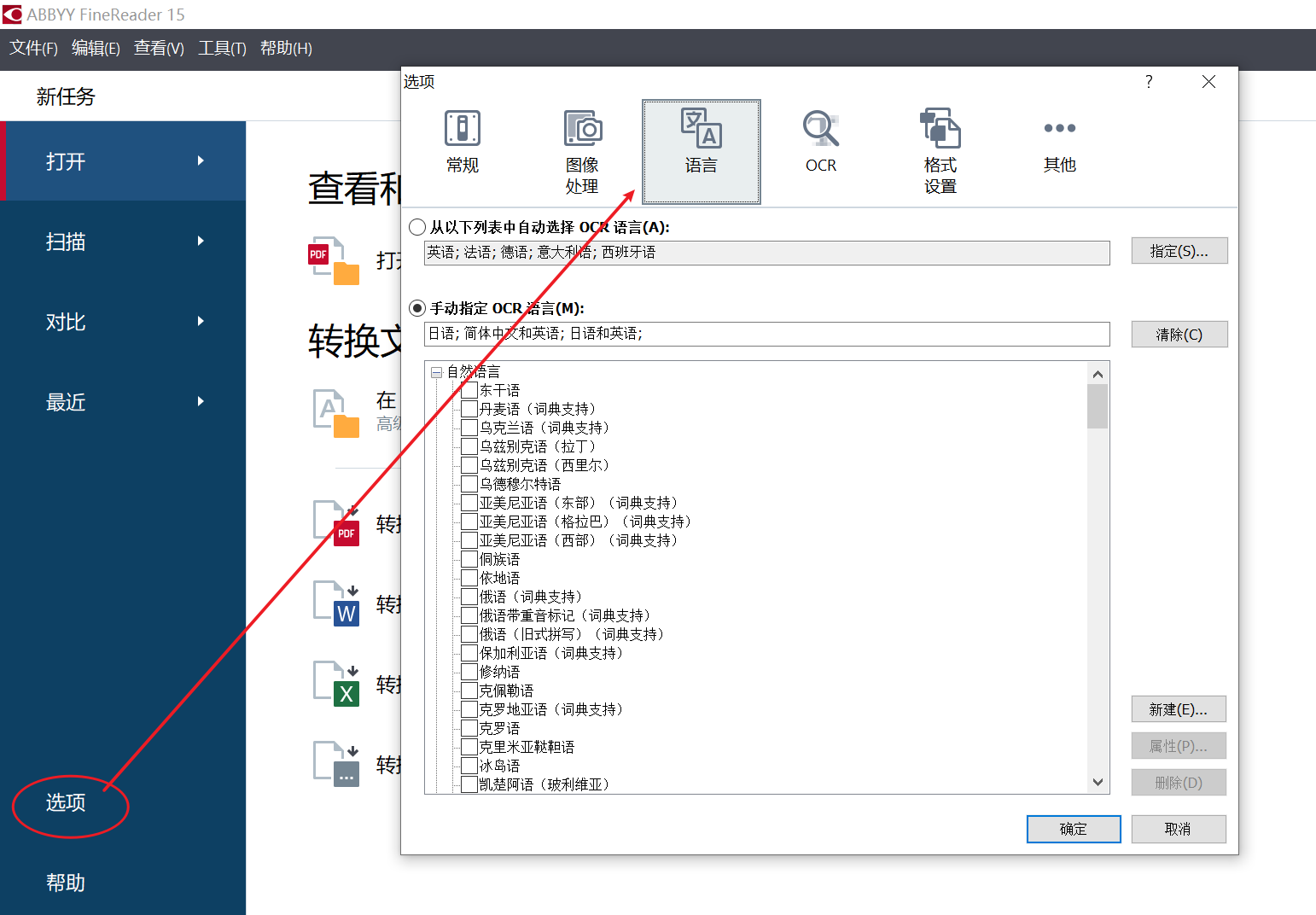 图5:ABBYYFineReaderPDF15主界面 图5:ABBYYFineReaderPDF15主界面
以上就是ABBYY的OCR识别语言设置教程的具体操作步骤,只有将OCR识别语言设置成合适的语言模式,我们才能得以顺利高效地完成OCR扫描转化操作。ABBYY FineReader PDF 15软件除了OCR扫描这一优势之外,还可以作为PDF编辑器对PDF文档进行编辑和处理,如果大家感兴趣的话请访问ABBYY FineReader PDF 15中文网站。
作者:Blur |
【本文地址】