【python】python旅游网数据抓取分析(源码+论文)【独一无二】 |
您所在的位置:网站首页 › 论文相关网站排名 › 【python】python旅游网数据抓取分析(源码+论文)【独一无二】 |
【python】python旅游网数据抓取分析(源码+论文)【独一无二】
|
👉博__主👈:米码收割机 👉技__能👈:C++/Python语言 👉公众号👈:测试开发自动化【获取源码+商业合作】 👉荣__誉👈:阿里云博客专家博主、51CTO技术博主 👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。 python旅游网数据抓取分析 目录 python旅游网数据抓取分析解析目标网址城市及其景点数量分析景点及其评分的数据酒店价格信息分析航班的价格数据分析旅游目的地的评论数量分析酒店评分数据分析航班起飞时间的数据分析热门城市旅游攻略分析 解析目标网址每个爬虫针对特定的目标网站(去哪儿网)进行数据抓取和解析。每个爬虫的功能和它们如何解析目标网站的数据。 WorldCountrySpider:爬虫用于抓取世界各国家的名称。它首先访问 https://travel.qunar.com/,然后利用XPath解析网页中的国家名称。假设国家名称被包裹在 标签且类名为country-name中,爬虫将提取所有这些标签的文本内容。 CityAttractionSpider:爬虫的目的是抓取特定城市的景点数量。它遍历了一系列城市的URL(如上海、北京等),然后通过XPath从页面中提取景点数量。假设景点数量信息位于ID为pager-container的 标签的data-total-count属性中。DestinationCommentSpider:爬虫用于统计特定目的地的评论数量。它访问了包含评论信息的API URL,并使用正则表达式从响应中提取评论数量。爬虫假定评论数量被包裹在标签中。 FlightPriceSpider:爬虫用于抓取特定航线的机票价格。它访问了一个包含航班价格信息的API,并使用Python的json模块来解析返回的JSON数据。爬虫提取了出发城市、到达城市以及机票价格。 FlightTimeSpider:爬虫旨在抓取航班的起飞时间。它同样访问了包含航班信息的API,并解析了JSON响应。然后,使用datetime模块将日期字符串转换为日期对象,以便后续处理。 HotelPriceSpider & HotelRatingSpider:爬虫分别用于抓取酒店的价格和评分信息。它们访问了包含酒店信息的API,并解析了返回的JSON数据。提取了酒店名称、城市、价格、房型、床型(对于价格爬虫)以及评分(对于评分爬虫)。 数据解析方法:XPath: 用于从HTML响应中提取数据。XPath是一种在XML文档中查找信息的语言,也适用于HTML。 正则表达式:用于从文本中提取符合特定模式的数据。 JSON解析:用于处理返回JSON格式的响应,如API请求的结果。 关注公众号,回复 “旅游网数据抓取分析” 获取源码
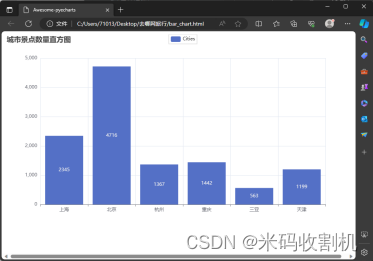
process_item 方法: 此方法是Pipeline的核心,它处理每个传递给Pipeline的项目(即在爬虫中提取的数据项)。对于QunarPipeline,它期望接收包含城市名称和景点数量的项目。方法中的逻辑是将城市名称作为键,景点数量作为值存储在self.data字典中。这种键值对存储方式简化了数据的聚合和后续处理。 close_spider 方法: 当爬虫结束时,此方法被调用。在这个阶段,所有的数据项都已经通过process_item方法处理并存储在self.data字典中。close_spider方法的作用是使用这些数据创建最终的可视化表示。使用pyecharts库中的Bar对象创建条形图,其中X轴表示城市名称,Y轴表示各个城市的景点数量。条形图的标题和其他全局选项也在此处设置。 数据可视化: 使用pyecharts创建的条形图可以直观地展示各个城市的景点数量对比。这种可视化对于理解和比较不同城市的旅游资源非常有用。最后,该条形图被渲染为一个HTML文件,可以在Web浏览器中查看。 关注公众号,回复 “旅游网数据抓取分析” 获取源码👇👇👇
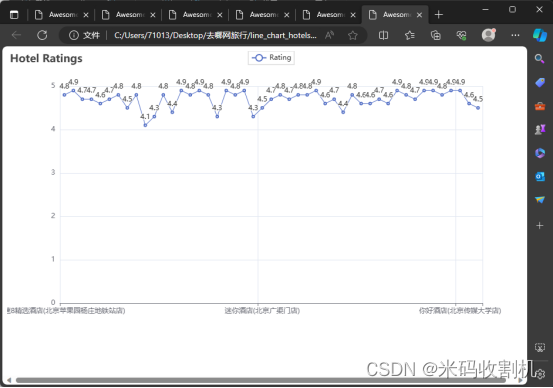
部分代码如下: class QunarPipeline: def open_spider(self, spider): self.data = {} def process_item(self, item, spider): self.data[item['city']] = item['attraction_count'] return item def close_spider(self, spider): bar = Bar() bar.add_xaxis(list(self.data.keys())) bar.add_yaxis("Cities", list(self.data.values())) bar.set_global_opts(title_opts=opts.TitleOpts(title="城市景点数量直方图")) bar.render("bar_chart.html") 景点及其评分的数据RatingPipeline 的主要功能是处理和可视化特定景点及其评分的数据。它专门针对爬取的景点评分数据进行处理和呈现。 open_spider 方法: 这个方法在爬虫启动时被调用。在这里,它初始化了一个空字典 self.data,用来存储景点名称及其对应的评分。此字典作为存储结构有助于后续的数据聚合和可视化。 部分代码如下: class RatingPipeline: def open_spider(self, spider): self.data = {} def process_item(self, item, spider): self.data[item['place']] = item['score'] return item def close_spider(self, spider): line = Line() line.add_xaxis(list(self.data.keys())) line.add_yaxis("评分", list(self.data.values())) line.set_global_opts(title_opts=opts.TitleOpts(title="地点评分折线图")) line.render("places_ratings_line_chart.html") 酒店价格信息分析open_spider 方法: 在爬虫启动时被调用。此方法初始化两个主要结构:self.city_aver_price 字典用于存储每个城市的酒店平均价格,而 self.city_message_price 列表用于收集酒店的详细信息,包括名称、城市、价格、房型和床型。 process_item 方法: 此方法是Pipeline的关键部分,它处理每个酒店数据项。首先,酒店的详细信息被添加到 self.city_message_price 列表中。随后,该方法检查 self.city_aver_price 字典中是否已存在该酒店所在城市的键值。如果不存在,会为该城市创建一个新条目,用于存储所有酒店的价格。这些价格随后被用于计算每个城市的酒店平均价格。 close_spider 方法: 在爬虫结束时调用。这个方法首先将所有酒店的详细信息存储到CSV文件中,为数据分析和记录提供了一个可靠的数据源。接下来,该方法计算每个城市的酒店平均价格,并使用 pyecharts 库创建一个条形图来可视化这些数据。
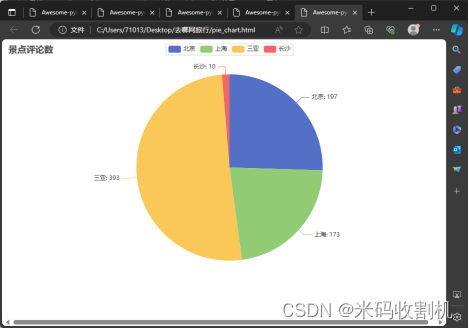
部分代码如下: class HotelPricePipeline: def open_spider(self, spider): self.city_aver_price = {} self.city_message_price = [["酒店名称", "城市", "价格", "房型", "床型"]] def process_item(self, item, spider): pass def close_spider(self, spider): # 保存数据到CSV文件 with open('city_message_price.csv', mode='w', newline='', encoding='utf-8-sig') as file: writer = csv.writer(file) writer.writerows(self.city_message_price) # 计算每个城市的平均价格 for city in self.city_aver_price: self.city_aver_price[city] = sum(self.city_aver_price[city]) / len(self.city_aver_price[city]) 航班的价格数据分析FlightPricePipeline 主要用于处理和分析航班的价格数据。它的核心功能是从爬虫返回的数据中提取航班价格信息,并基于这些数据创建可视化图表。 部分代码如下: class FlightPricesPipeline: def open_spider(self, spider): self.arr_money = {'SHA': [], 'BJS': [], 'HGH': [], 'CKG': []} def process_item(self, item, spider): self.arr_money[item['dep_city']].append(item['price']) return item def close_spider(self, spider): scatter = Scatter() scatter.add_xaxis([str(x) for x in range(17)]) # 横轴为数据点的序号 for city, values in self.arr_money.items(): scatter.add_yaxis(city, values, symbol_size=10) scatter.set_series_opts(label_opts=opts.LabelOpts(is_show=False)) scatter.set_global_opts( title_opts=opts.TitleOpts(title="城市数据散点图"), xaxis_opts=opts.AxisOpts(type_="category", name="城市"), yaxis_opts=opts.AxisOpts(type_="value", name="数据值"), ) 旅游目的地的评论数量分析DestinationCommentPipeline 专注于处理和可视化特定旅游目的地的评论数量数据。它的主要作用是从爬虫抓取的数据中提取评论计数,并将这些数据转换成可视化的形式,以提供关于各个旅游目的地受欢迎程度的直观理解。 HotelRatingPipeline 主要用于处理和可视化酒店评分数据。它的作用是收集各个酒店的评分信息,并将这些数据通过折线图的形式进行展示,以便用户能够直观地理解不同酒店的评分情况。
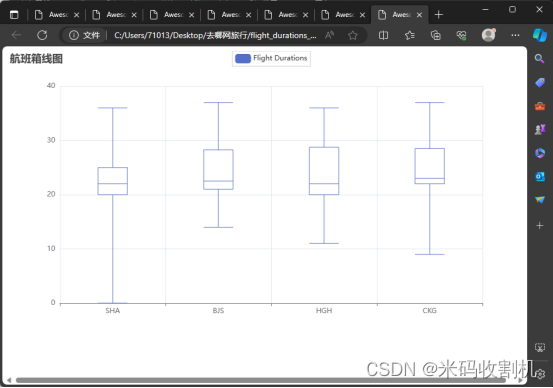
FlightTimePipeline 专注于处理航班起飞时间的数据。其主要目标是收集各个城市的航班起飞时间,并通过箱线图的形式对这些数据进行可视化展示。
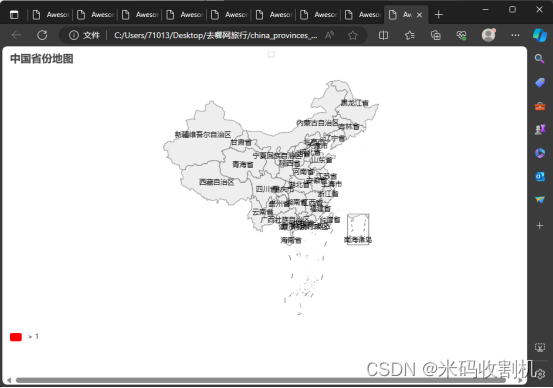
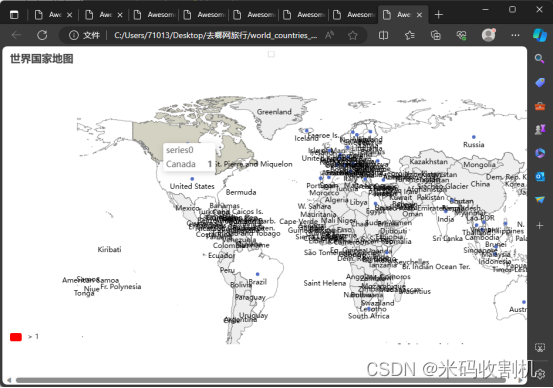
关注公众号,👇👇👇回复 “旅游网数据抓取分析” 获取源码👇👇👇 热门城市旅游攻略分析代码定义了一个名为 TravelMapPipeline 的类,其功能是在爬虫关闭时创建并保存中国省份和世界国家分布的地图。
关注公众号,👇👇👇回复 “旅游网数据抓取分析” 获取源码👇👇👇 |

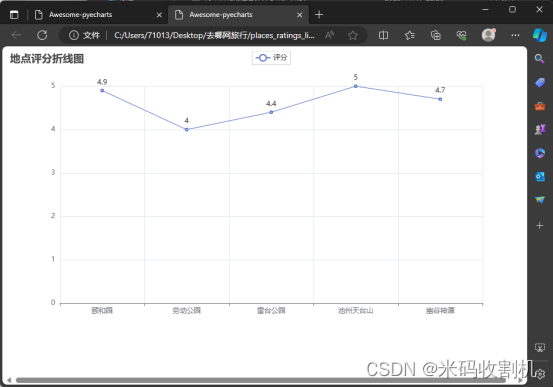 RatingPipeline 精确地处理了景点评分数据,并有效利用pyecharts库生成了一种直观的可视化方式。这不仅提高了代码的可读性和可维护性,也提供了一种灵活的方法来展示和比较不同景点的评价。通过这样的可视化,用户可以更容易地根据评分选择景点。
RatingPipeline 精确地处理了景点评分数据,并有效利用pyecharts库生成了一种直观的可视化方式。这不仅提高了代码的可读性和可维护性,也提供了一种灵活的方法来展示和比较不同景点的评价。通过这样的可视化,用户可以更容易地根据评分选择景点。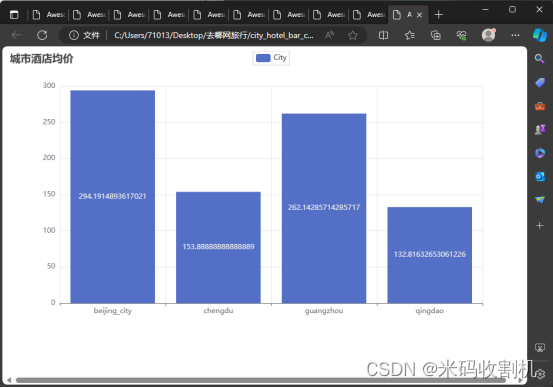 HotelPricePipeline 有效地整合了酒店数据的收集、存储和可视化。通过这种方式,它不仅提供了有用的市场洞察,还以易于理解的格式呈现了数据,使得决策者和消费者可以根据实际数据做出更明智的选择。
HotelPricePipeline 有效地整合了酒店数据的收集、存储和可视化。通过这种方式,它不仅提供了有用的市场洞察,还以易于理解的格式呈现了数据,使得决策者和消费者可以根据实际数据做出更明智的选择。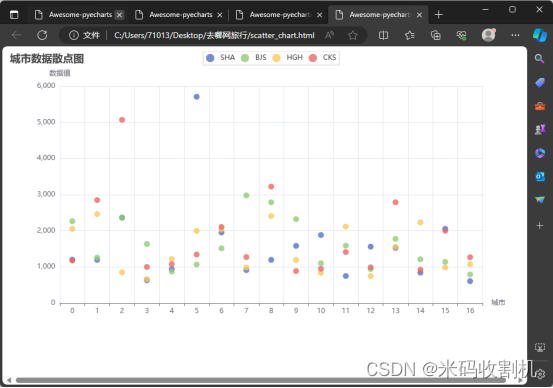
【本文地址】
今日新闻 |
推荐新闻 |