【NLP】3 种强大的长文本摘要方法和实例 |
您所在的位置:网站首页 › 论文总结的话 › 【NLP】3 种强大的长文本摘要方法和实例 |
【NLP】3 种强大的长文本摘要方法和实例
|
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎 📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃 🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝 📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。 如果你对这个系列感兴趣的话,可以关注订阅哟👋 文章目录 大文本摘要和小文本摘要之间的区别 6种长文本摘要的关键方法 使用 BERTSUM 进行长文本提取摘要 使用 BertSum 进行新闻文章摘要 使用 BertSum 的博客文章摘要 带有人类反馈的书籍摘要 书籍摘要方法的优缺点 汇总示例 Longformer 总结:Long-Document Transformer 使用 8k Token 的 Longformer 摘要 使用 GPT-3 的长文本摘要摘要 什么是抽象摘要? 什么是 GPT-3? 用于长文本摘要摘要的 GPT-3
文本摘要是一种 NLP 过程,它专注于减少给定输入的文本量,同时保留关键信息和上下文含义。考虑到手动摘要所需的时间和资源,使用 NLP 的自动摘要已经在许多不同的用例中针对许多不同的文档长度进行了增长也就不足为奇了。摘要空间发展迅速,新的重点是处理超大文本输入以总结成几行。对新闻文章和研究论文等较长文档的摘要需求的增加推动了该领域的增长。 导致长文本摘要新推动的关键变化是引入了 BERT 和 GPT-3 等转换器模型,它们可以在单次运行中处理更长的文本输入序列,以及对分块算法的新理解。过去的架构,如 LSTM 或 RNN,不如这些基于转换器的模型高效或准确,这使得长文档摘要变得更加困难。对如何构建和使用在运行时保持上下文信息结构并减少数据差异的分块算法的理解的增长也是关键。 大文本摘要和小文本摘要之间的区别将文档中的所有上下文信息打包成简短的摘要对于长文本来说要困难得多。如果我们的摘要必须最多说 5 句话,那么决定哪些信息有价值到足以添加 500 个单词与 50,000 个单词要困难得多。 通常需要分块算法,但它们确实增加了模型必须准确的数据方差覆盖范围。分块算法根据模型允许的最大标记和我们设置的参数来控制我们将多少较大的文档传递给摘要器。输入数据的新动态特性意味着我们的数据方差比用较小的文本看到的要大得多。 较长的文档通常具有更多的内部数据差异和信息波动。使用博客文章、访谈、成绩单等原因在对话中有多个摇摆,这使得理解哪些上下文信息对摘要有价值变得更加困难。随着文本的增长,模型必须学习特定关键字、主题和短语之间更深层次的关系。 有两种主要类型的摘要可用作任何增强版摘要的基线 -提取式和抽象式。他们专注于如何以自己的方式在生成的摘要中重建在输入文本中找到的关键信息。当使用较长的文本时,这两种方法都有自己独特的挑战。 6种长文本摘要的关键方法有许多不同的方法可以使用各种体系结构和框架来总结长文档文本。我们将看看当今使用的一些最流行的,以及我们看到它们表现出色的各种用例。 使用 BERTSUM 进行长文本提取摘要提取式摘要用于从给定文本中提取接近精确的短语或关键句子。处理管道类似于作用于每个句子的二元分类模型。 BertSum 是一个微调的 BERT 模型,专注于提取摘要。BERT 在这种新架构中用作编码器,在处理长输入和词到词关系方面具有最先进的能力。这种使用 BERT 作为基线并创建领域特定微调模型的管道非常受欢迎,因为利用基线训练可以在新领域提供很大的准确性提升,并且需要更少的数据点。
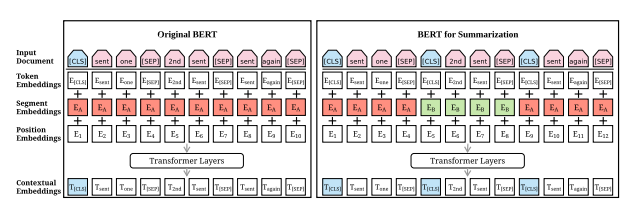
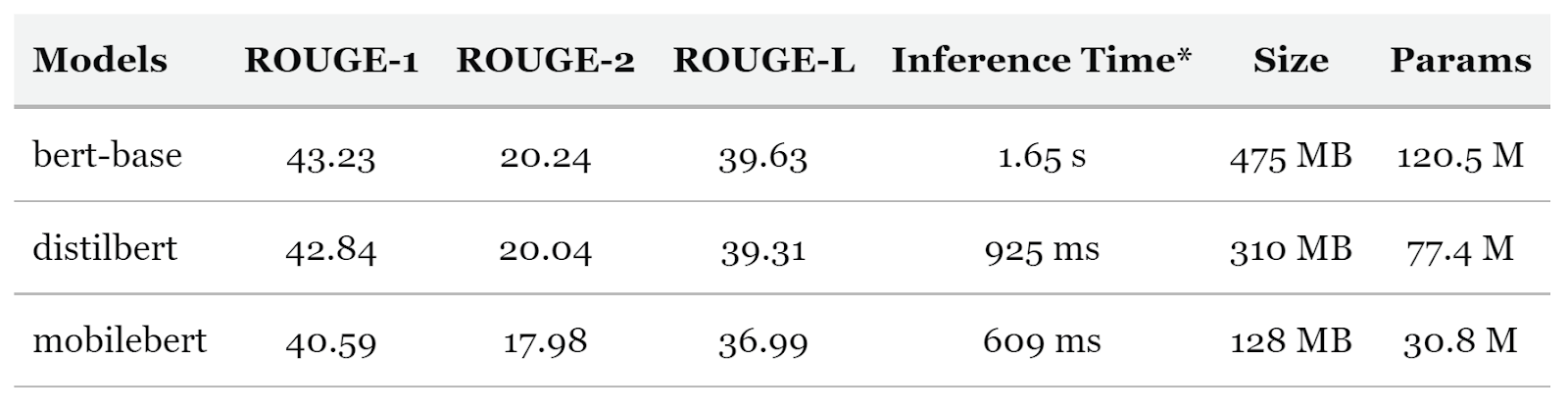
BertSum 研究论文 从基线到 BertSum 的关键变化是输入格式的变化。我们一次表示单个句子而不是整个文本,因此我们将 [CLS] 标记添加到每个句子的前面而不是整个文档。当我们运行编码器时,我们使用这些 [CLS] 标记来表示我们的句子。 BertSum 的优缺点 BertSum 架构的一个关键优势是 BERT 通常具有的灵活性。在查看如何处理长输入文本时,这些模型的大小和速度通常会成为等式的一部分。BertSum 有许多变体,它们使用不同的基线 BERT 模型,例如 DistilBERT 和 MobileBERT,它们要小得多,但可以获得几乎相同的结果。
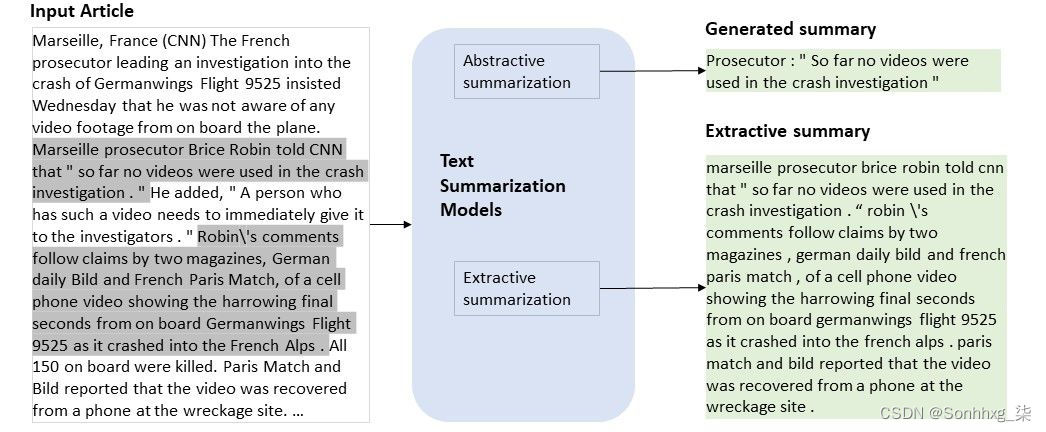
几乎相同的准确度数字但要小得多 提取摘要的另一个普遍优点是可以轻松评估准确性。鉴于摘要文本接近精确的句子性质,与抽象摘要相比,与地面实况数据集进行准确性比较要容易得多。 我们看到使用 BertSum 进行长文本摘要的主要缺点是 BERT 的底层令牌限制。BertSum 的输入令牌限制为 512,这比我们今天在 GPT-3 中看到的要小得多(在最新的指令版本中为 4000+)。这意味着对于长文本摘要,我们必须做一些特殊的事情: 1. 构建分块算法来拆分文本。 2. 考虑到每个文本块不包含上面的所有上下文信息,管理新级别的数据差异。3. 最后管理组合块输出。 我不会深入探讨这一点,但 BertSum 的更低令牌限制可能会导致问题。 使用 BertSum 进行新闻文章摘要我们使用 BertSum 创建新闻文章的段落长度摘要,其中包含从长文本中提取的确切重要句子。BertSum 允许我们调整我们想要使用的摘要的长度,这直接影响文章中的哪些信息被认为足够重要以包含在内。 我们可以在包含多个模块的管道中创建这篇文章的一段长的文章摘要:摘要如下所示,由要点组成。
我们已经使用了上面看到的完全相同的现有模型管道来将任何大小的任何博客帖子或访客帖子总结成一个简短而有趣的摘要。我们拿了一篇超过 6k 字的最长文章,并将其总结成一个段落。我们总是可以调整摘要的输出长度,以更好地适应信息量或博客文章的长度。
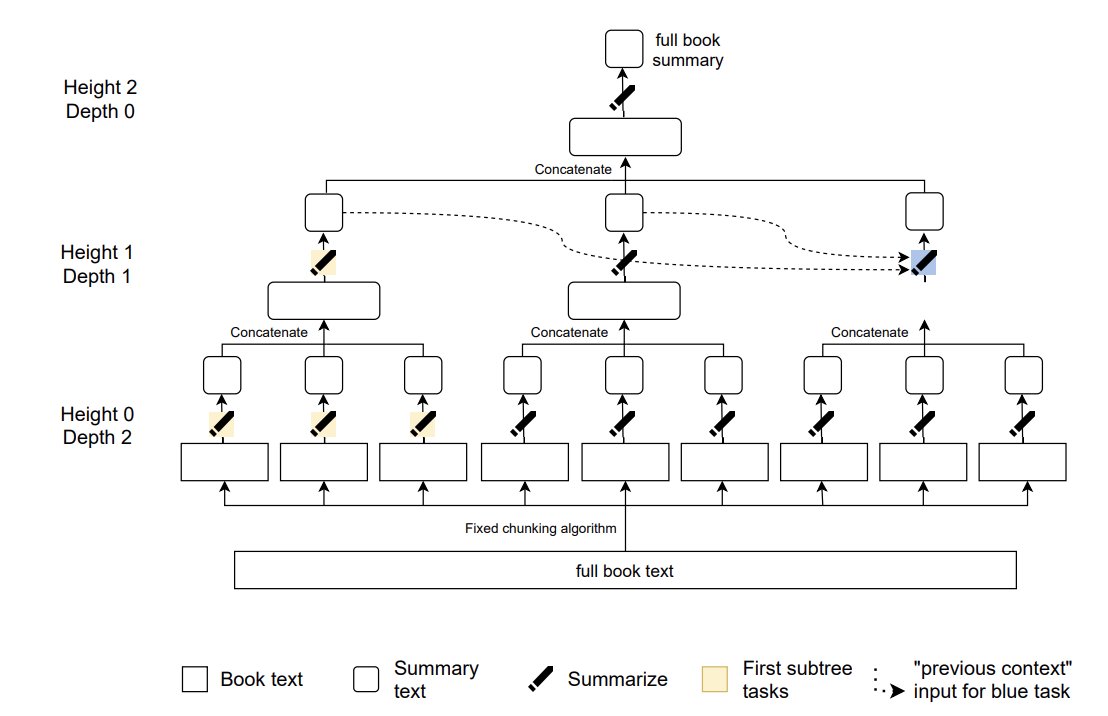
带有人类反馈的书籍摘要OpenAi 发布了一个新的摘要流水线,专注于使用强化学习和递归任务分解来对整本书进行抽象摘要。他们使用经过微调的 GPT-3 模型,该模型是根据人类创建的大量摘要创建的。该模型用于总结书籍的小部分,然后递归地将生成的摘要总结为最终的完整书籍摘要。他们最终使用了一些经过训练的模型来处理较大任务的较小部分,从而帮助人类对摘要提供高质量的反馈。 该模型最终对 5% 的书籍实现了接近人类水平的摘要准确性,并且在 15% 的时间里略低于人类水平。
OpenAi 采取的方法解决了超长输入文本的抽象摘要中经常出现的关键问题。人工反馈评估以及将机器摘要与人类摘要进行比较是评估摘要准确性的一些最流行的方法。这里的一个问题是,如果我们使用从整本书生成的模型,那么人类必须阅读整本书才能写出摘要。这使得评估生成的摘要的成本非常低效且资源密集。使用更小的块方法,人类评估者只需要理解和评估书中的较小部分。 递归任务分解路线包括许多评估系统的好处。与试图理解模型如何从全文到摘要的过程相比,使用块来分解和跟踪摘要过程要容易得多。在生成帮助我们映射关键信息的最终完整摘要之前,我们可以在中间步骤中看到更多细节。 考虑到分解方法,您可能会争辩说本书的长度没有限制。这是一个优势,与我们之前看到的单一模型 BertSum 方法形成对比。 汇总示例
Longformer 总结:Long-Document Transformer
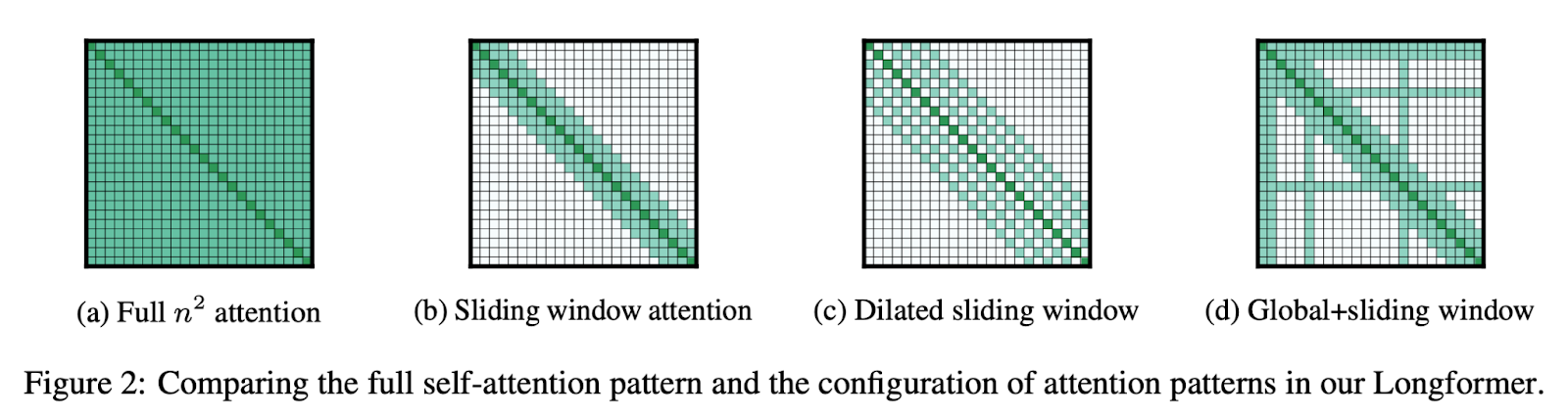
正如我们在 BertSum 的缺点中看到的那样,基于 transformer 的模型难以处理超长输入序列,因为它们的自注意力机制会随着序列长度的增长而迅速扩展。longformer 致力于解决此问题,因为它使用一种注意力机制,该机制与序列长度成线性比例,作为局部窗口注意力和任务动机注意力。这使得在单个实例中处理具有数千个标记的文档变得更加容易。我们使用这种称为 Longformer 编码器-解码器的变体来完成摘要任务。 longformer 架构的设置方式与我们在现代使用 BERT 的方式类似。longformer 通常用作基线语言理解模型,然后针对各种任务(如摘要、QA、序列分类 等)进行再训练或微调。该架构在长文档任务上始终优于基于 BERT 的模型(例如 RoBERTa),并且在几个领域中取得了最先进的结果。 考虑到我们在上一节中讨论的许多困难,这些困难伴随着使用任何模型总结长文本,很容易看出 longformer 编码器解码器如何使我们受益。通过扩展我们可以在单次运行中使用的标记数量,我们可以限制我们需要创建的文本块的数量。这极大地帮助我们保留了长文档中的重要上下文,而无需将其分成任何组块,从而在最后形成更强大的摘要。longformer 还使将所有较小的块摘要组合成一个最终摘要变得容易得多,因为我们要组合的东西更少。 使用 8k Token 的 Longformer 摘要
代码示例 最近,长期使用的编码器-解码器架构针对非常流行的 Pubmed 摘要数据集的摘要进行了微调。Pubmed 是一个大型文档数据集,用于汇总医学发表的论文。数据集中的中位标记长度为 2715,其中 10% 的文档具有 6101 个标记。使用较早的编码器-解码器架构,我们将最大长度设置为 8192 个标记,并且可以单个GPU上完成。在最流行的示例中,我们将最大摘要长度设置为 512 个标记。 使用 GPT-3 的长文本摘要摘要
什么是抽象摘要?抽象摘要侧重于以释义格式生成输入文本的摘要,将所有信息都考虑在内。这与我们在提取式摘要中看到的非常不同,因为抽象式摘要不会生成由每个“精确的最佳句子”组成的段落,而是生成所有内容的简明摘要。 什么是 GPT-3?GPT-3 是 OpenAi 于 2020 年 6 月发布的基于 transformer 的模型。它是迄今为止最大的 transformer 模型之一,拥有 1750 亿个参数。大型语言模型架构是在非常大量的数据上训练的,包括所有常见的爬网、所有维基百科和许多其他大型文本源。该模型是自回归的,并使用基于提示的学习格式,允许在运行时针对 NLP 中的各种用例对其进行调整。 用于长文本摘要摘要的 GPT-3GPT-3 有几个关键优势,使其成为长文本摘要的绝佳选择: 1.它可以处理很长的输入序列 2. 模型自然地处理了大量的数据方差 3. 您可以为您的用例混合提取式和抽象式摘要。 最后一点是迄今为止使用 GPT-3 的最大好处。通常,摘要任务在完全正确的输出看起来的本质上并不是严格的提取或抽象的。一些用例,例如这个关键主题提取管道,摘要以项目符号的形式呈现,其中某些部分来自文本的确切短语,但更多地反映了 75/25 的抽象拆分。这种融合两种僵化的总结思想的能力是 GPT-3 基于提示的编程所提供的极大灵活性的结果。基于提示的逻辑使我们能够开始生成这些自定义摘要,而无需完全按照我们的需要找到预训练模型或创建庞大的数据集。
|






【本文地址】
今日新闻 |
推荐新闻 |