计算机视觉(十六):目标检测概述 |
您所在的位置:网站首页 › 计算机视觉的主要应用领域有哪些内容 › 计算机视觉(十六):目标检测概述 |
计算机视觉(十六):目标检测概述
|
1 什么是目标检测
目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置。 例子:确定某张给定图像中是否存在给定类别(比如人、车、自行车、狗和猫)的目标实例;如果存在,就返回每个目标实例的空间位置和覆盖范围。作为图像理解和计算机视觉的基石,目标检测是解决分割、场景理解、目标追踪、图像描述、事件检测和活动识别等更复杂更高层次的视觉任务的基础。 目标检测的应用场景: 目标检测具有巨大的实用价值和应用前景。 应用领域包括人脸检测、行人检测、车辆检测、卫星图像中道路的检测、车载摄像机图像中的障碍物检测、医学影像在的病灶检测等。应用场景包括长/视频领域、医学场景、安防领域、自动驾驶等等众多领域行人车辆检测: 这里我们举一些使用的场景 在视频中去进行检测明星人物,检测出某明星的视频只看他的视频。类似在爱奇艺中的只看他功能快速筛选仅有明星出现的片段。 2 目标检测算法介绍下面这张图代表了目标检测算法的发展历史(基于深度学习),其中红色部分是影响较大的算法论文。是需要着重了解的。 两步走的目标检测: 先进行区域推荐,而后进行目标分类 包含一个用于区域提议的预处理步骤,使得整体流程是两级式的。代表:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN和R-FCN等 端到端的目标检测: 直接在网络中提取特征来预测物体分类和位置 即无区域提议的框架,这是一种单独提出的方法,不会将检测提议分开,使得整个流程是单级式的。代表:OverFeat、YOLOv1、YOLOv2、YOLOv3、SSD和RetinaNet等
因为对比角度有很多,性能和准确度,性能方面不好比较,涉及到使用的CPU和GPU的区别。不同算法当时实验环境不一样。这里进行了准确度的比较 论文在常见数据集中的测试效果: DetectorVOC07 (mAP@IoU=0.5)VOC12 (mAP@IoU=0.5)COCO (mAP@IoU=0.5:0.95)Published InR-CNN58.5--CVPR’14SPP-Net59.2--ECCV’14MR-CNN78.2 (07+12)73.9 (07+12)-ICCV’15Fast R-CNN70.0 (07+12)68.4 (07++12)19.7ICCV’15Faster R-CNN73.2 (07+12)70.4 (07++12)21.9NIPS’15YOLO v166.4 (07+12)57.9 (07++12)-CVPR’16G-CNN66.866.4 (07+12)-CVPR’16AZNet70.4-22.3CVPR’16ION80.177.933.1CVPR’16HyperNet76.3 (07+12)71.4 (07++12)-CVPR’16OHEM78.9 (07+12)76.3 (07++12)22.4CVPR’16MPN--33.2BMVC’16SSD 76.8(07+12)74.9 (07++12)31.2ECCV’16GBDNet77.2 (07+12)-27.0ECCV’16CPF76.4 (07+12)72.6 (07++12)-ECCV’16R-FCN79.5 (07+12)77.6 (07++12)29.9NIPS’16DeepID-Net69.0--PAMI’16NoC71.6 (07+12)68.8 (07+12)27.2TPAMI’16DSSD81.5 (07+12)80.0 (07++12)33.2arXiv’17TDM--37.3CVPR’17FPN--36.2CVPR’17YOLO v278.6 (07+12)73.4 (07++12)-CVPR’17RON77.6 (07+12)75.4 (07++12)27.4CVPR’17DeNet77.1 (07+12)73.9 (07++12)33.8ICCV’17CoupleNet82.7 (07+12)80.4 (07++12)34.4ICCV’17RetinaNet--39.1ICCV’17DSOD77.7 (07+12)76.3 (07++12)-ICCV’17SMN70.0--ICCV’17Light-Head R-CNN--41.5arXiv’17YOLO v3--33.0arXiv’18SIN76.0 (07+12)73.1 (07++12)23.2CVPR’18STDN80.9 (07+12)--CVPR’18RefineDet83.8 (07+12)83.5 (07++12)41.8CVPR’18SNIP--45.7CVPR’18Relation-Network--32.5CVPR’18Cascade R-CNN--42.8CVPR’18MLKP80.6 (07+12)77.2 (07++12)28.6CVPR’18Fitness-NMS--41.8CVPR’18RFBNet82.2 (07+12)--ECCV’18CornerNet--42.1ECCV’18PFPNet84.1 (07+12)83.7 (07++12)39.4ECCV’18Pelee70.9 (07+12)--NIPS’18HKRM78.8 (07+12)-37.8NIPS’18M2Det--44.2AAAI’19R-DAD81.2 (07++12)82.0 (07++12)43.1AAAI’19 3 目标检测的任务分类的任务回顾 分类的损失与优化 在训练的时候需要计算每个样本的损失,那么CNN做分类的时候使用softmax函数计算结果,损失为交叉熵损失
 目标检测 目标检测  输出结果对比 输出结果对比
物体位置: x, y, w,h:物体的中心点位置,以及中心点距离物体两边的长宽xmin, ymin, xmax, ymax:物体位置的左上角、右下角坐标 4 目标定位的简单实现思路在分类的时候我们直接输出各个类别的概率,如果再加上定位的话,我们可以考虑在网络的最后输出加上位置信息。下面我们考虑图中只有一个物体的检测时候,我们可以有以下方法去进行训练我们的模型 4.1 回归位置增加一个全连接层,即为FC1、FC2 FC1:作为类别的输出FC2:作为这个物体位置数值的输出
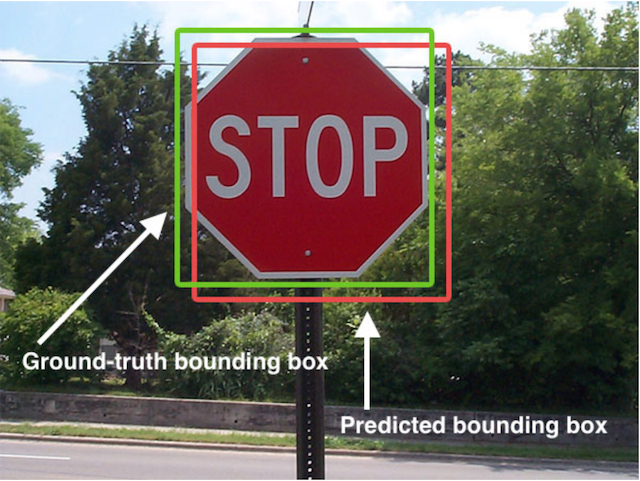
如下图所示 在目标检测当中,对bbox主要由两种类别。 Ground-truth bounding box:图片当中真实标记的框Predicted bounding box:预测的时候标记的框
目标检测在很多领域都有应用需求,包括人脸检测,行人检测,车辆检测以及遥感影像中的重要地物检测等。 人脸检测: 人脸检测是人脸识别应用中重要的一个环节,主要用于确定人脸在图像中的大小和位置,即解决“人脸在哪里”的问题,把真正的人脸区域从图像中裁剪出来,便于后续的人脸特征分析和识 别。 |
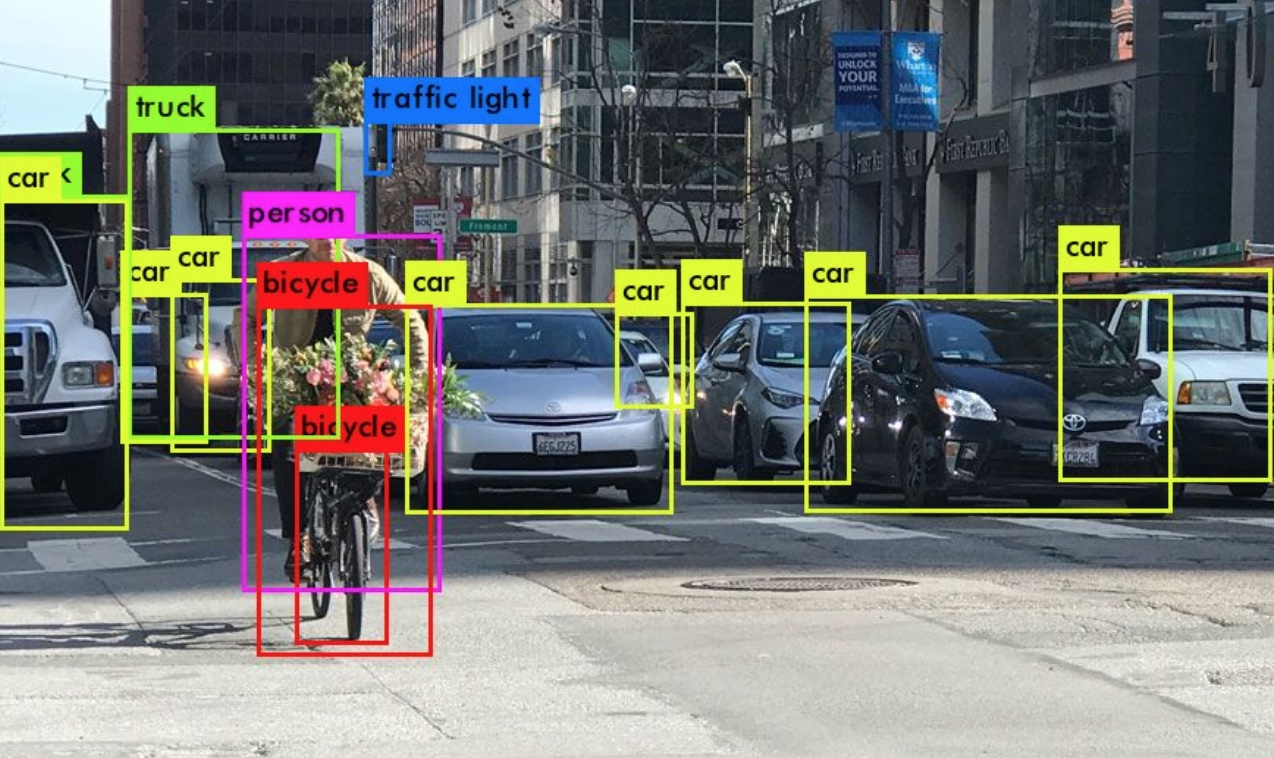 多人脸的检测:
多人脸的检测:  目标检测的实用价值
目标检测的实用价值 算法分类
算法分类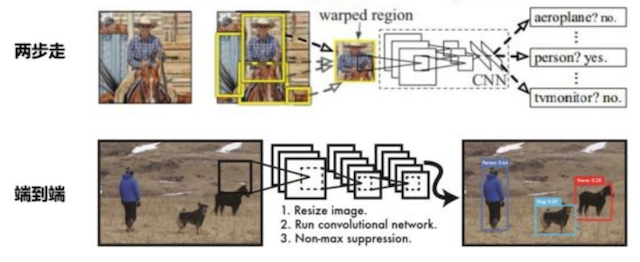 几种类别结构的形式如下:
几种类别结构的形式如下: 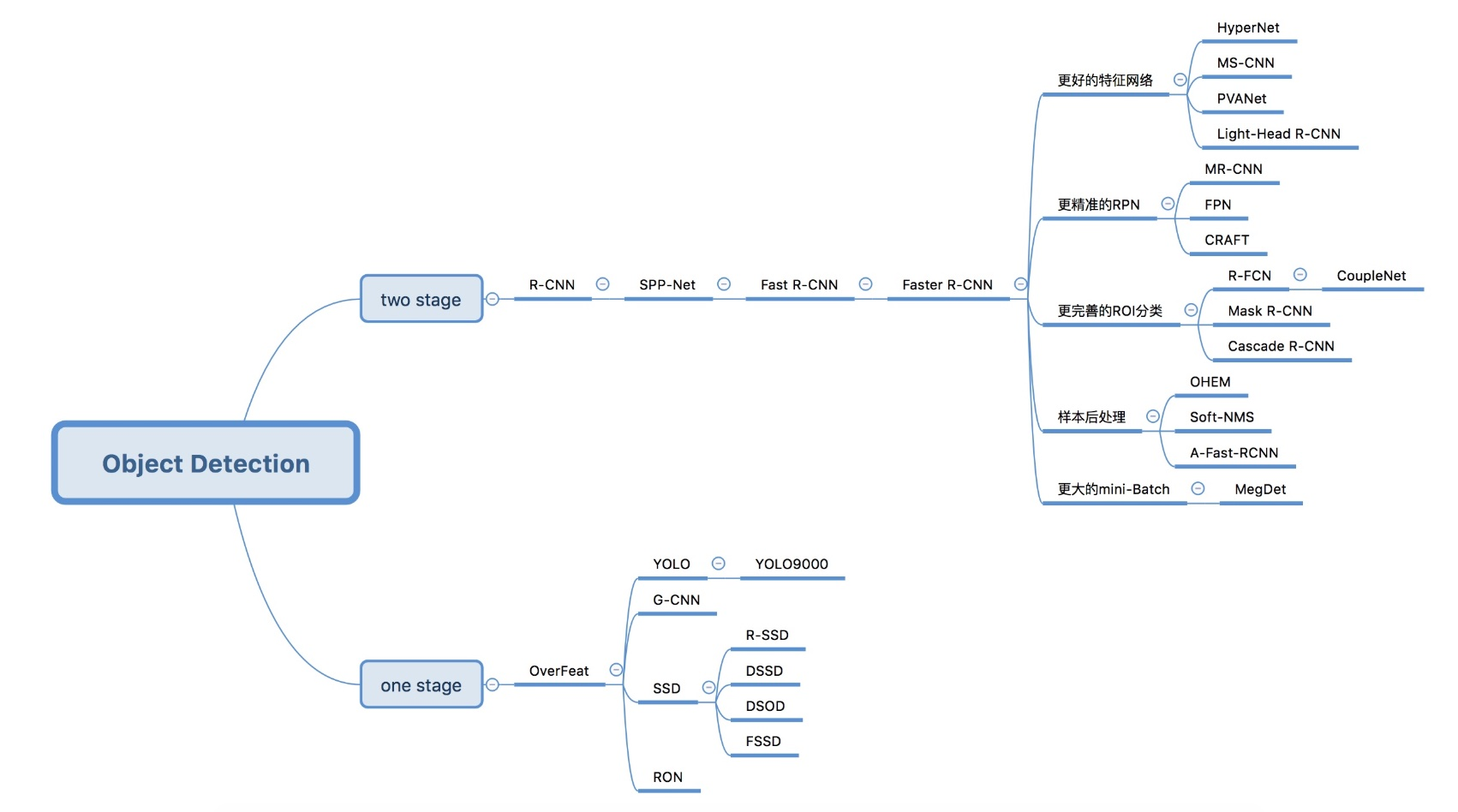 算法效果对比
算法效果对比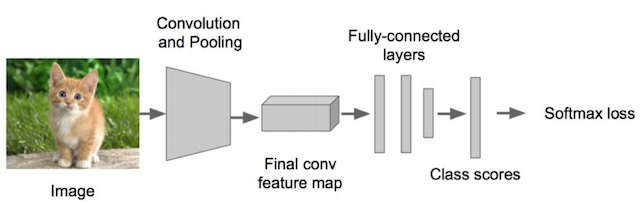 常见CNN模型
常见CNN模型 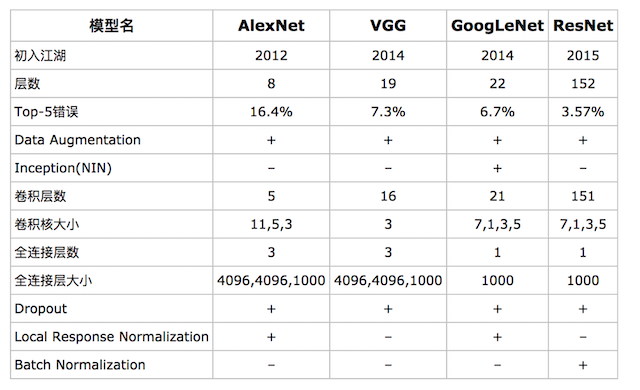 对于目标检测来说不仅仅是分类这样简单的一个图片输出一个结果,而且还需要输出图片中目标的位置信息,所以从分类到检测,如下图标记了过程:
对于目标检测来说不仅仅是分类这样简单的一个图片输出一个结果,而且还需要输出图片中目标的位置信息,所以从分类到检测,如下图标记了过程: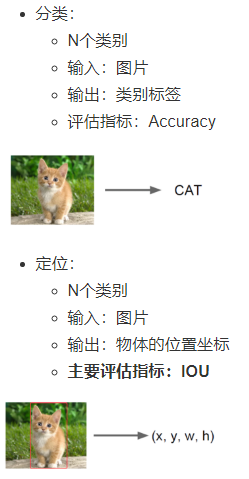 其中我们得出来的(x,y,w,h)有一个专业的名词,叫做bounding box(bbox)
其中我们得出来的(x,y,w,h)有一个专业的名词,叫做bounding box(bbox)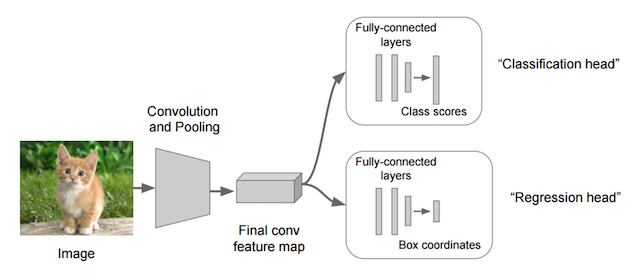 假设有10个类别,输出[p1,p2,p3,…,p10],然后输出这一个对象的四个位置信息[x,y,w,h]。同理知道要网络输出什么,如果衡量整个网络的损失
假设有10个类别,输出[p1,p2,p3,…,p10],然后输出这一个对象的四个位置信息[x,y,w,h]。同理知道要网络输出什么,如果衡量整个网络的损失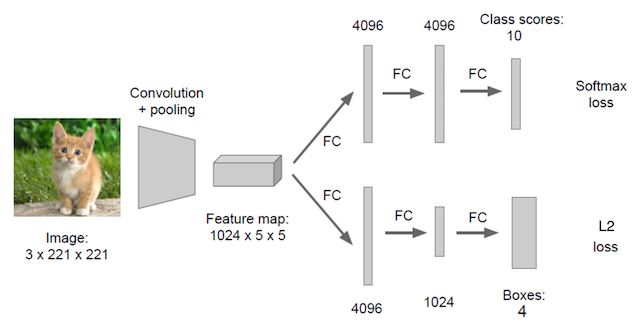
 一般在目标检测当中,我们预测的框有可能很多个,真实框GT也有很多个。
一般在目标检测当中,我们预测的框有可能很多个,真实框GT也有很多个。 行人检测: 行人检测具有极其广泛的应用:智能辅助驾驶,智能监控,行人分析以及智能机器人等领域。此外,其在视频监控,人流量统计,自动驾驶中都有重要的地位。特征提取、形变处理、遮挡处理、分类是四个行人检测中的重要部分。
行人检测: 行人检测具有极其广泛的应用:智能辅助驾驶,智能监控,行人分析以及智能机器人等领域。此外,其在视频监控,人流量统计,自动驾驶中都有重要的地位。特征提取、形变处理、遮挡处理、分类是四个行人检测中的重要部分。  车辆检测: 车辆检测在智能交通,视频监控,自动驾驶中有重要的地位。车流量统计,车辆违章的自动分析等都离不开它,在自动驾驶中,首先要解决的问题就是确定道路在哪里,周围有哪些车、人或障碍物。
车辆检测: 车辆检测在智能交通,视频监控,自动驾驶中有重要的地位。车流量统计,车辆违章的自动分析等都离不开它,在自动驾驶中,首先要解决的问题就是确定道路在哪里,周围有哪些车、人或障碍物。 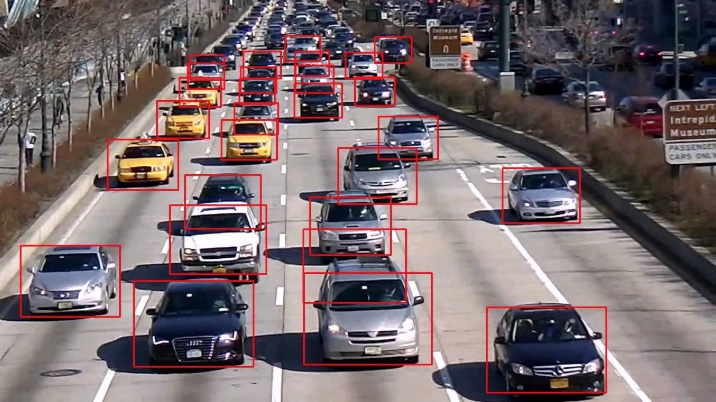 此外,交通标志如交通灯、行驶规则标志的识别对于自动驾驶也非常重要,我们需要根据红绿灯状态,是否允许左右转、掉头等标志确定车辆的行为。同时,医学影像图像如MRI的肿瘤等病变部位检测和识别对于诊断的自动化,提供优质的治疗具有重要的意义。还有工业中材质表面的缺陷检测,硬刷电路板表面的缺陷检测等。
此外,交通标志如交通灯、行驶规则标志的识别对于自动驾驶也非常重要,我们需要根据红绿灯状态,是否允许左右转、掉头等标志确定车辆的行为。同时,医学影像图像如MRI的肿瘤等病变部位检测和识别对于诊断的自动化,提供优质的治疗具有重要的意义。还有工业中材质表面的缺陷检测,硬刷电路板表面的缺陷检测等。【本文地址】
今日新闻 |
推荐新闻 |