PostgreSQL的几种常见问题和解决方法 |
您所在的位置:网站首页 › 计算机PG信号 › PostgreSQL的几种常见问题和解决方法 |
PostgreSQL的几种常见问题和解决方法
|
1. 前言
1.1 概述
本文介绍了postgresql的几种常见问题,并从现象出发,逐步排查问题,分析导致问题的原因并给出解决方案。 本文介绍的问题分为两大类:一类是关于PostgreSQL无法启动的问题,另一类是PostgreSQL启动后,部分数据库对象无法访问的问题。 1.2 软件环境本文使用的 PostgreSQL 版本是 9.6。 1.3 一些约定术语PostgreSQL安装路径:默认是 “D:\Program Files\PostgreSQL\9.6” bin 文件夹:PostgreSQL安装路径下的bin文件夹。 data 文件夹:PostgreSQL安装路径下的data文件夹。 2. 问题和解决方法 2.1 PostgreSQL无法启动PostgreSQL 没有正常启动时,在 “服务”中再次启动失败。 2.1.1 端口占用我们首先需要判断是不是该服务的端口被占用。PostgreSQL服务的默认端口是5432,那么我们在命令行中执行如下命令 netstat -ano | find /i "5432" 如果发现了某个进程使用了5432这个端口,这说明是端口占用导致服务无法启动:
这个进程的pid是2364,你想查看它是什么进程,可以执行: tasklist | findstr "2364" 执行结果如下:
你可以在任务管理器-进程页面中,或者通过下面的命令结束这个进程: taskkill /f /pid 2364 小知识: PostgreSQL 是多进程模型的数据库。它在运行时,会启动一个名为“pg_ctl”进程和若干个名为“postgres” 的进程。其中,进程pg_ctl是“祖先”进程,它表示数据库处于运行状态,占用的内存很少;其他所有工作进程的名称都是postgres。 在 Windows 操作系统上,如果 pg_ctl.exe 被异常关闭了,进程 postgres.exe 还会存在。数据库运行端口仍然被占用。会导致数据库无法启动。 2.1.2 文件 postmaster.pid 残留进入 PostgreSQL的data 文件夹,查看是否有残留的文件 postmaster.pid。正常情况下,PostgreSQL 在启动时会创建这个文件,其内容是 PostgreSQL 的主进程的 pid。如果它存在,则数据库会认为自己已经启动了,所以启动失败。 因此需要删除这个文件,再尝试启动数据库。
如果端口没有被占用,那么你可以用PostgreSQL原生的命令启动它。 进入postgresql安装路径下的 bin 文件夹,在这里打开命令行,执行下面的命令: .\pg_ctl start -D ..\data 如果程序报出如下错误: ERROR: could not open control file “global/pg_control”: Permission denied
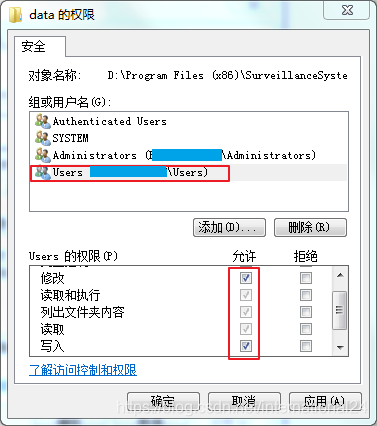
则说明当前操作系统用户丢失了data文件夹及其内容的权限。 下面是解决方法: 1. 首先,进入postgresql 的安装路径,右键data文件夹,依次点击属性——安全——编辑,你能看到所有用户或用户组的权限。
2. 确保System 和 Administrator 拥有“完全控制”权限。Users 用户组默认只拥有“读取和执行”,“列出文件夹内容”和“读取”3种权限。当启动数据库提示“权限不足”时,应再添加“修改”和 “写入”。
3. 保存并尝试再次在bin 文件夹下执行: .\pg_ctl start -D ..\data 观察PostgreSQL数据库能否启动。 2.1.4 could not create control file “global/pg_control”:file exists该问题的解决方法与 “2.1.3 could not open control file “global/pg_control”:Permission denied” 的问题完全相同。 2.1.5 could not locate a valid checkpoint record如果启动数据库时,提示“正在启动服务器进程”,且长时间无法启动成功,如下图所示,需要查看数据库运行日志,它们位于data文件夹下的pg_log中的。
打开问题发生时的数据库运行日志,查看信息。 如果日志中出现类似下面黑体字的信息,说明是PostgreSQL数据库中的预写式日志(write ahead log,简称WAL,又称事务日志,简称xlog)损坏了: LOG: could not open file "pg_xlog/0000000100000000000000E7" (log file 0, segment 231): No such file or directory LOG: invalid primary checkpoint record LOG: could not open file "pg_xlog/0000000100000000000000E7" (log file 0, segment 231): No such file or directory LOG: invalid secondary checkpoint record PANIC: could not locate a valid checkpoint record 解决方法如下: 进入bin 文件夹,在这里打开命令行,执行下面的命令来重置事务日志: .\pg_resetxlog.exe -f ..\data 如果程序提示“事务日志重置”,则代表事务日志重置成功。这时,我们可以尝试启动数据库。
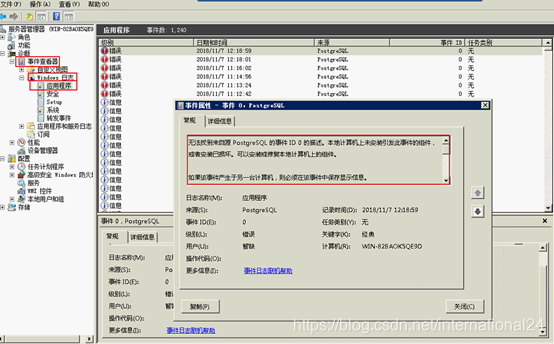
有时程序提示: pg_resetxlog : Could not create pg_control: File exists 不必担心。我们只需要执行“2.1.3 could not open control file “global/pg_control”:Permission denied”这一节的操作,为用户加上权限,然后重新重置事务日志即可 2.1.6 failed to re-find parent key in index "227236" for split pages 370/371有时,数据库无法启动时,我们查看位于data文件夹下的pg_log中的数据库运行日志,会发现类似下面的信息: LOG: redo starts at 270/55E04AE8 LOG: could not open file pg_xlog/0000000100000270000000CC" (log file 624, segment 204): No such file or directory LOG: redo done at 270/CBFFE940 LOG: last completed transaction was at log time 2018-11-26 01:55:01.259996-02 FATAL: failed to re-find parent key in index "227236" for split pages 370/371 LOG: startup process (PID 5011) exited with exit code 1 LOG: aborting startup due to startup process failure 上面黑体字的信息,同样说明是PostgreSQL数据库中的预写式日志文件损坏了。 该问题的解决方法和“2.1.5 could not locate a valid checkpoint record”的问题的解决方法相同。 2.1.7 无法找到来自源 PostgreSQL 的事件 ID 0 的描述。如果上面的方法没有解决问题,那么我们需要进入事件管理器中查看是否有错误日志: 在事件查看器-Windows日志-应用程序中,查看是否有如下错误日志: 无法找到来自源 PostgreSQL 的事件 ID 0 的描述。本地计算机上未安装引发此事件的组件,或者安装已损坏。可以安装或修复本地计算机上的组件。
如果出现了这样的信息,则说明PostgreSQL软件已经损坏,需要重新安装。不过,数据文件不一定损坏了,因此如果上次备份至今,数据库中产生过非常重要的数据(比如账单信息),你应该将data文件夹复制到另一个目录,然后重新安装平台,并恢复data文件夹。 2.1.8 Could not read from file "pg_clog/000E" at offset 172032还有一种不常见的情况。如果日志中出现类似下面的信息: ERROR: could not access status of transaction 710708 DETAIL: Could not read from file "pg_clog/000E" at offset 172032: No error. 则表示位于data文件夹下pg_clog中的名为 000E 的提交日志文件丢失了。 解决方法如下: 在linux 操作系统中,执行下列命令: dd if=/dev/zero of=/root/000E bs=256k count=1 或者在windows中安装 dd,随后执行: dd if=/dev/zero of=D:\000E bs=256k count=1 然后将创建好的000E 文件拷贝至data文件夹下的pg_clog 中。 2.1.8 FATAL: could not write lock file "postmaster.pid": No space left on device如果日志提示 FATAL: could not write lock file "postmaster.pid": No space left on device 表示磁盘空间不足。可清理无用文件或者扩容磁盘。 2.1.9 FATAL:could not create semaphores: No space left on device如果日志提示 FATAL:could not create semaphores: No space left on device 说明在linux 服务器上,信号量不足。 你可以通过下面的命令查看 [root@node1 ~]# sysctl -n kernel.sem 250 32000 32 128 第一列,表示每个信号集中的最大信号量数目。 第二列,表示系统范围内的最大信号量总数目。 第三列,表示每个信号发生时的最大系统操作数目。 第四列,表示系统范围内的最大信号集总数目。 可以增大这个参数: echo "500 5120000 2500 9000" > /proc/sys/kernel/sem 2.2 数据库启动后,部分数据库或表无法访问这种情况下,你需要进入 data文件夹下的pg_log文件夹,查看问题发生时刻产生的运行日志。 2.2.1 permission denied for relation tb_door如果运行日志出现类似下面的信息,这说明是当前访问用户没有表tb_door的某些权限: ERROR: permission denied for relation tb_door 如果你希望当前用户(以myuser为例)拥有特定访问权限(以SELECT,INSERT,UPDATE ,DELETE为例),可以这样解决: 首先,通过postgres用户或拥有tb_door 相应访问权限即授予权限的用户登录数据库;执行如下命令,为用户授予权限:grant SELECT,INSERT,UPDATE,DELETE on tb_door to myuser 2.2.2 must be owner of relation tb_door如果运行日志出现类似下面的信息,这说明是当前用户没有表 tb_door的所有权: ERROR: must be owner of relation tb_door 你可以使用管理员postgres登录相应数据库,手动执行下面命令将tb_door的属主你希望的用户,以myuser为例: Alter table tb_door owner to myuser; 2.2.3 invalid page header in block 120 of relation base/272816/309624如果日志中出现类似下面的信息: ERROR: invalid page header in block 120 of relation base/272816/309624 则表示数据表文件损坏。这通常是由于异常断电或误操作导致的。这里“272816”是发生问题的数据库的对象id(oid), “309624”表示发生问题的表的文件结点(filenode) 如果发生损坏的表以及损坏的页面数量较少,我们可以以牺牲部分数据的代价恢复整体;如果损坏的表数量过多,或者损失的数据非常重要,就需要从备份中恢复数据了。 当发生损坏的表以及损坏的页面数量较少时,解决方法如下: 确定发生问题的数据库。连接任意数据库,执行下面的sql语句:select datname from pg_database where oid = 272816; 查询结果如下: testdb 这表示发生问题的数据库名是testdb 2. 查找损坏的数据库对象。连接发生问题的数据库,执行下面的sql语句: select relname,relkind from pg_class where relfilenode = 309624 如果查询结果中 relkind = r,表示损坏的是表。 例如: tb_door, r relname = tb_door这表示损坏的表是tb_door。 如果查询结果中relkind = i,表示损坏的是一个索引。 例如: dept_number_index, i 或者: tb_dept_pkey, i 需要注意,损坏的可能是普通索引,也可能是主键或唯一键。如果索引的名称中有“_pkey”等很可能属于主键,而名称中含有 “_key”则很可能属于唯一键。 还需要格外注意一点,表/索引可修复的前提条件是损坏的表是应用程序创建的表/索引,而不是PostgreSQL的系统表和建立在其上的索引。如果系统表/建立在其上的索引发生损坏,则需要从备份中恢复数据库。判断一个表是否是系统表,最简单的方法是:如果表名是“pg_”开头的,则说明它是系统表。 小知识 pgclass.relkind 的值有下面几种: r: 表示ordinary table(普通表); i: 表示index(索引); S: 表示sequence(序列); V: 表示view(视图); m: 表示materialized view(物化视图); c: 表示composite type(复合类型); t: 表示TOAST table(TOAST 表); f: 表示foreign table(外部表) 3. 修复损坏的数据库对象。连接发生损坏的数据库,执行修复命令。 如果损坏的是表,以tb_door为例,则依次执行下列命令即可完成修复: set zero_damaged_pages = on; vacuum tb_door; reindex table tb_door;
如果损坏的是普通索引,以dept_number_index为例, 则依次执行: set zero_damaged_pages = on; reindex index dept_number_index;
如果损坏的是主键或唯一键,则首先需要找到它所在的表,以tb_dept_pkey为例: Select tablename,indexname from pg_indexes where indexname = ‘tb_dept_pkey’; 查询结果: tb_dept, tb_dept_pkey 然后获取索引的定义: select pg_get_constraintdef((select oid from pg_constraint where conname = ' tb_dept_pkey ')); 查询结果: PRIMARY KEY (dept_id)
然后重新创建这个约束: Alter table drop constriant tb_dept_pkey; Alter table add constraint tb_dept_pkey PRIMARY KEY (dept_id); 2.2.4 could not read block 190 in file "base/272816/309624"该问题也是数据表文件损坏。它的解决方法与“2.2.3 invalid page header in block 120 of relation base/272816/309624”的问题完全相同。 2.2.5 could not open file "base/272816/379923": No such file or directory如果日志中出现类似下面的信息: 2019-01-21 14:28:03 HKT ERROR: could not open file "base/272816/379923": No such file or directory 则说明,oid为272816的数据库中,oid为379923的表对应的文件被删除了。 解决方法如下: 1. 首先判断是哪一个数据库中发生了此问题。连接任意数据库,执行如下sql: select datname from pg_database where oid = 272816 查询结果如下: testdb 2. 从备份中恢复该数据库。 2.2.6 ERROR: relation "s_log_config_info" does not exist at character 103如果日志中出现了下面的信息: ERROR: relation "s_log_config_info" does not exist at character 103 STATEMENT: select id, log_type_code, sub_sys_code, module_code, module_name, ctrl_type_code, ctrl_type_name from s_log_config_info where 1=1 and (log_type_code in ($1 , $2 , $3)); 那么可能的原因有两种: 1. s_log_config_info 这个表被误删或者损坏了; 2. 用户丢失了 s_log_config_info 所在的模式(一般是public 模式)的权限。 解决问题的方法如下: 1. 首先,连接到出问题的数据库中,查看 s_log_config_info 表是否存在于正确的模式中。如果发现 s_log_config_info 不存在,则需要使用备份文件恢复这张表或者整个数据库,视情况而定。 2. 如果表s_log_config_info存在,那很可能是用户丢失了这张表所在的模式的权限。 解决方法是为用户添加模式的权限,可根据实际确定授予什么样的权限。 例如,把public 模式的所有权给用户my_user: Alter schema public owner to my_user; 把public 用户的所有访问权限授予my_user: Grant all on schema public to my_user; 2.3 数据库启动后,部分数据库或表无法访问 2.3.1 No buffer space available有时,在服务管理器中,PostgreSQL 显示为 正在运行状态,但是使用客户端连接使,提示“could not connect to server: No buffer space available”,在postgresql运行日志中,也能看到类似日志。 解决方法如下: 首先,在服务管理器中关闭 PostgreSQL 服务。尝试用 PostgreSQL 自身的命令启动它。进入postgresql安装路径下的 bin 文件夹,在这里打开命令行,执行下面的命令:.\pg_ctl start -D ..\data 3. 观察提示信息。如果提示PostgreSQL启动成功,则用客户端连接数据库;如果启动不成功,则参考 2.1 章的内容。 4. 如果仍然有这样的错误提示,那说明很可能是内存不足。你需要在操作系统中查看内存,如果发现可用内存较少,那你需要观察是否有服务内存异常过高,并处理它。在 Windows 上 有一种特殊的情况,各种服务起来正常,但内存很少,这是因为 windows Socket 连接关闭后,内存不释放。对于windows 2008,解决方法是打 windows补丁 KB2577795。 2.3.2 no pg_hba.conf entry for host如果日志中出现类似下面的信息: FATAL: no pg_hba.conf entry for host "192.168.0.123", user "testuser", database "testdb" 则表示数据库服务器没有允许来自地址192.168.0.123的 testuser 用户访问数据库testdb。 解决的方法如下: 检查 data 目录中的配置文件 postgresql.conf 中的参数 listen_addresses,把它的值改为 ’*’, 或者包含客户端的IP。修改data 目录中的访问权限配置文件 pg_hba.conf。如果你希望所有地址的所有用户可以访问此服务器中的全部数据库,可以添加下面这一行:host all all 0.0.0.0/0 md5 如果你只希望192.168.0.123 上的用户可以访问此数据库,则添加: host all all 192.168.0.123/32 md5 或者你仅仅希望192.168.0.123 上的 testuser 用户可以访问此数据库,则添加: host testuser all 192.168.0.123/32 md5 3. 重启数据库即可。 小知识: pg_hba.conf 是 postgresql 服务端的访问权限控制文件,控制来自哪里的什么用户,以什么建立方式连接,以什么方法认证,访问哪一个数据库。每行是一个访问控制条目,内容的示例如下: host all all 127.0.0.1/32 md5 每列的含义如下: 第一列表示访问域的类型,其值有local,host,hostssl,hostnossl。一般选择 host,表示使用 TCP/IP 建立的连接。 第二列表示允许访问的数据库用户,“all” 表示所有用户可以访问。 第三列表示允许被访问的数据库名,“all” 表示所有数据库都允许被访问。 第四列表示允许访问的ip地址,127.0.0.1/32表示本地IP地址,192.168.0.123/32 表示地址192.168.0.123,192.168.0.0/24表示子网192.168.0.0 ~ 192.168.0.255,0.0.0.0/0表示任何IP地址。 第五列是认证的方式。“md5” 表示MD5密码认证,trust表示无密码认证。 2.3.3 No connection could be made because the target machine actively refused it.如果日志中出现类似下面的信息: LOG: could not receive data from client: No connection could be made because the target machine actively refused it. 则表示有一些因素使数据库服务器拒绝了客户端的连接。 解决的思路如下: 首先检查平台有没有单点登录。如果有,关闭。检查有没有安装防火墙,如果有,允许5432端口连接。检查 data 目录中的配置文件 postgresql.conf 中的参数 listen_addresses,把它的值改为 ’*’, 或者包含客户端的IP。修改data 目录中的访问权限配置文件 pg_hba.conf。如果你希望所有地址的所有用户可以访问此服务器中的全部数据库,可以添加下面这一行:host all all 0.0.0.0/0 md5 如果你只希望192.168.0.123 上的用户可以访问此数据库,则添加: host all all 192.168.0.123/32 md5 5. 重启数据库,观察能否访问。 |






【本文地址】
今日新闻 |
推荐新闻 |