计算机求导方法:自动微分(Automatic Differentiation) |
您所在的位置:网站首页 › 计算器怎么求导函数图像的 › 计算机求导方法:自动微分(Automatic Differentiation) |
计算机求导方法:自动微分(Automatic Differentiation)
|
目录
1 Manual Differentiation (手动微分)1.1 计算方法1.2 缺陷
2 Symbolic Differentiation (符号微分)2.1 计算方法2.2 缺陷
3 Numerical Differentiation (数值微分)3.1 计算方法3.2 缺陷
4 Automatic Differentiation (自动微分)4.1 Forward-Mode (前向模式)4.2 Reverse-Mode (反向模式)4.3 小结
5 参考
1 Manual Differentiation (手动微分)
1.1 计算方法
手动求导,顾名思义,通过求导的一些公式,我们提前算好导数表达式,再带入公式求解。 假设我们以一个输入为3个变量的函数 f f f为例: f ( x 1 , x 2 , x 3 ) = 3 ∗ ( x 1 2 + x 2 ∗ x 3 ) f(x_1, x_2, x_3) = 3*(x_1^2+x_2*x_3) f(x1,x2,x3)=3∗(x12+x2∗x3) 我们定义输入的三个值为 ( x 1 = 2 , x 2 = 3 , x 3 = 4 ) (x_1=2, x_2=3, x_3=4) (x1=2,x2=3,x3=4),那手动微分是怎么计算?首先,分别对 x 1 , x 2 , x 3 x_1, x_2, x_3 x1,x2,x3求导,再带入输入值,得到如下结果: ∂ f ( x 1 , x 2 , x 3 ) ∂ x 1 = 3 ∗ 2 ∗ x 1 = 12 \frac{\partial f(x_1, x_2, x_3)}{\partial x_1} = 3*2*x_1 = 12 ∂x1∂f(x1,x2,x3)=3∗2∗x1=12 ∂ f ( x 1 , x 2 , x 3 ) ∂ x 2 = 3 ∗ x 3 = 12 \frac{\partial f(x_1, x_2, x_3)}{\partial x_2} = 3*x_3 = 12 ∂x2∂f(x1,x2,x3)=3∗x3=12 ∂ f ( x 1 , x 2 , x 3 ) ∂ x 3 = 3 ∗ x 2 = 9 \frac{\partial f(x_1, x_2, x_3)}{\partial x_3} = 3*x_2 = 9 ∂x3∂f(x1,x2,x3)=3∗x2=9 1.2 缺陷 当计算较复杂的函数时,求导结果表达式将会十分繁琐每次给定不同的目标函数,都需要重新计算求导表达式,定义函数公式,效率低,无法大规模复用 2 Symbolic Differentiation (符号微分) 2.1 计算方法符号微分通过求导规则来计算导数值,给定一个函数,通过规则一步一步求解,常见的求导规则有如下: 加法求导规则:d ( f + g ) d x = d f d x + d g d x \frac{d(f+g)}{dx} = \frac{df}{dx} + \frac{dg}{dx} dxd(f+g)=dxdf+dxdg 乘法求导规则: d ( f g ) d x = d f d x g + f d g d x \frac{d(fg)}{dx} = \frac{df}{dx}g + f \frac{dg}{dx} dxd(fg)=dxdfg+fdxdg链式法则: d ( f ( g ( x ) ) ) d x = d f ( g ( x ) ) d g ( x ) d g ( x ) d x \frac{d(f(g(x)))}{dx} = \frac{df(g(x))}{dg(x)}\frac{dg(x)}{dx} dxd(f(g(x)))=dg(x)df(g(x))dxdg(x) 2.2 缺陷符号微分的主要缺陷就是: 对于复杂的函数,求导结果表达式十分繁琐,如下图所示: 为了计算最终的数值梯度,中间符号表达式都需要存储,很浪费资源计算过程中容易出错
3 Numerical Differentiation (数值微分)
3.1 计算方法 为了计算最终的数值梯度,中间符号表达式都需要存储,很浪费资源计算过程中容易出错
3 Numerical Differentiation (数值微分)
3.1 计算方法
数值微分主要基于导数的极限定义,例如给定一个多元函数 f : R n → R f: R^n \to R f:Rn→R,我们可以估计函数梯度 ∇ f = ( ∂ f ∂ x 1 , . . . , ∂ f ∂ x n ) \nabla f = (\frac{\partial f}{\partial x_1}, ..., \frac{\partial f}{\partial x_n}) ∇f=(∂x1∂f,...,∂xn∂f)公式如下: ∂ f ( x ) ∂ x i ≈ lim h → 0 f ( x + h e i ) − f ( x ) h \frac{\partial f(x)}{\partial x_i} \approx \lim_{h \to 0} \frac{f(x+he_i)-f(x)}{h} ∂xi∂f(x)≈h→0limhf(x+hei)−f(x) 为了避免截断误差,一般使用中心差分,如下公式: ∂ f ( x ) ∂ x i ≈ lim h → 0 f ( x + h e i ) − f ( x − h e i ) 2 h \frac{\partial f(x)}{\partial x_i} \approx \lim_{h \to 0}\frac{f(x+he_i)-f(x-he_i)}{2h} ∂xi∂f(x)≈h→0lim2hf(x+hei)−f(x−hei) h h h是一个很小的数,一般设置为 h = 1 e − 6 h=1e-6 h=1e−6 3.2 缺陷 计算 n n n维度的梯度,需要计算函数 O ( n ) O(n) O(n)次对 f f f函数的计算,效率较慢每一步需要很小心的选择 h h h,梯度计算存在舍入误差 4 Automatic Differentiation (自动微分)自动微分是一个有效的计算偏导方法,对任意函数的一点,自动微分可以自动计算偏导数。自动微分有两种计算方式:前向模式和反向模式,接下来我们用函数 f ( x 1 , x 2 ) = l n ( x 1 ) + x 1 x 2 − s i n ( x 2 ) f(x_1, x_2) = ln(x_1) + x_1x_2 - sin(x_2) f(x1,x2)=ln(x1)+x1x2−sin(x2)为例,分别对自动微分的前向模式和方向模式做一个对比。 4.1 Forward-Mode (前向模式)对函数
f
(
x
1
,
x
2
)
=
l
n
(
x
1
)
+
x
1
x
2
−
s
i
n
(
x
2
)
f(x_1, x_2) = ln(x_1) + x_1x_2 - sin(x_2)
f(x1,x2)=ln(x1)+x1x2−sin(x2)构造图如下:  通过函数
f
f
f定义形式,将输入的值带入求解,计算各中间的变量值
v
i
v_i
vistep 2 : 从前往后计算偏导数 因为定义
v
˙
=
∂
v
i
∂
x
1
v˙= \frac{\partial v_i}{\partial x_1}
v˙=∂x1∂vi,所以
x
˙
1
=
∂
x
1
∂
x
1
=
1
x˙_1 = \frac{\partial x_1}{\partial x_1}=1
x˙1=∂x1∂x1=1,则计算结果如下: 通过函数
f
f
f定义形式,将输入的值带入求解,计算各中间的变量值
v
i
v_i
vistep 2 : 从前往后计算偏导数 因为定义
v
˙
=
∂
v
i
∂
x
1
v˙= \frac{\partial v_i}{\partial x_1}
v˙=∂x1∂vi,所以
x
˙
1
=
∂
x
1
∂
x
1
=
1
x˙_1 = \frac{\partial x_1}{\partial x_1}=1
x˙1=∂x1∂x1=1,则计算结果如下:  根据前向计算的结果和求导的链式法则,很容易得出上述结果,得到最终的结果:
y
˙
=
˙
v
5
=
5.5
y˙= ˙v_5 = 5.5
y˙=˙v5=5.5 若给定一个函数方程:
f
:
R
n
→
R
m
f:R^n \to R^m
f:Rn→Rm,输入是
n
n
n个独立的变量
x
i
x_i
xi和
m
m
m个非独立的输出变量
y
j
y_j
yj,在
x
=
a
x=a
x=a取值点,则计算的雅可比导数矩阵形式如下:
J
f
=
[
∂
y
1
∂
x
1
.
.
.
∂
y
1
∂
x
n
.
.
.
.
.
.
.
.
.
∂
y
m
∂
x
1
.
.
.
∂
y
m
∂
x
n
]
x
=
a
J_f = \begin{bmatrix} \frac{\partial y_1}{\partial x_1} & ... & \frac{\partial y_1}{\partial x_n} \\.&.&.\\.&.&.\\.&.&. \\ \frac{\partial y_m}{\partial x_1} & ... & \frac{\partial y_m}{\partial x_n} \end{bmatrix}_{x=a}
Jf=⎣⎢⎢⎢⎢⎡∂x1∂y1...∂x1∂ym.........∂xn∂y1...∂xn∂ym⎦⎥⎥⎥⎥⎤x=a 自动微分的前向模式十分有效,对于函数方程
f
:
R
→
R
m
f : R \to R^m
f:R→Rm,对于所有的偏导数计算
d
y
i
d
x
\frac{dy_i}{dx}
dxdyi只需要一次前向计算,但如果函数方程是
f
:
R
n
→
R
f: R^n \to R
f:Rn→R,则前向模式需要计算
n
n
n个等式计算梯度:
∇
f
=
(
∂
y
∂
x
1
,
.
.
.
,
∂
y
∂
x
n
)
\nabla f = (\frac{\partial y}{\partial x_1},...,\frac{\partial y}{\partial x_n})
∇f=(∂x1∂y,...,∂xn∂y) 而当函数
f
:
R
n
→
R
m
f: R^n \to R^m
f:Rn→Rm其中
n
≫
m
n ≫ m
n≫m,则前向模式效率将会十分低,特别是目前DL模型有上亿级别的参数,所以需要更快的方式计算,这就是接下来要讲的反向模式。
4.2 Reverse-Mode (反向模式) 根据前向计算的结果和求导的链式法则,很容易得出上述结果,得到最终的结果:
y
˙
=
˙
v
5
=
5.5
y˙= ˙v_5 = 5.5
y˙=˙v5=5.5 若给定一个函数方程:
f
:
R
n
→
R
m
f:R^n \to R^m
f:Rn→Rm,输入是
n
n
n个独立的变量
x
i
x_i
xi和
m
m
m个非独立的输出变量
y
j
y_j
yj,在
x
=
a
x=a
x=a取值点,则计算的雅可比导数矩阵形式如下:
J
f
=
[
∂
y
1
∂
x
1
.
.
.
∂
y
1
∂
x
n
.
.
.
.
.
.
.
.
.
∂
y
m
∂
x
1
.
.
.
∂
y
m
∂
x
n
]
x
=
a
J_f = \begin{bmatrix} \frac{\partial y_1}{\partial x_1} & ... & \frac{\partial y_1}{\partial x_n} \\.&.&.\\.&.&.\\.&.&. \\ \frac{\partial y_m}{\partial x_1} & ... & \frac{\partial y_m}{\partial x_n} \end{bmatrix}_{x=a}
Jf=⎣⎢⎢⎢⎢⎡∂x1∂y1...∂x1∂ym.........∂xn∂y1...∂xn∂ym⎦⎥⎥⎥⎥⎤x=a 自动微分的前向模式十分有效,对于函数方程
f
:
R
→
R
m
f : R \to R^m
f:R→Rm,对于所有的偏导数计算
d
y
i
d
x
\frac{dy_i}{dx}
dxdyi只需要一次前向计算,但如果函数方程是
f
:
R
n
→
R
f: R^n \to R
f:Rn→R,则前向模式需要计算
n
n
n个等式计算梯度:
∇
f
=
(
∂
y
∂
x
1
,
.
.
.
,
∂
y
∂
x
n
)
\nabla f = (\frac{\partial y}{\partial x_1},...,\frac{\partial y}{\partial x_n})
∇f=(∂x1∂y,...,∂xn∂y) 而当函数
f
:
R
n
→
R
m
f: R^n \to R^m
f:Rn→Rm其中
n
≫
m
n ≫ m
n≫m,则前向模式效率将会十分低,特别是目前DL模型有上亿级别的参数,所以需要更快的方式计算,这就是接下来要讲的反向模式。
4.2 Reverse-Mode (反向模式)
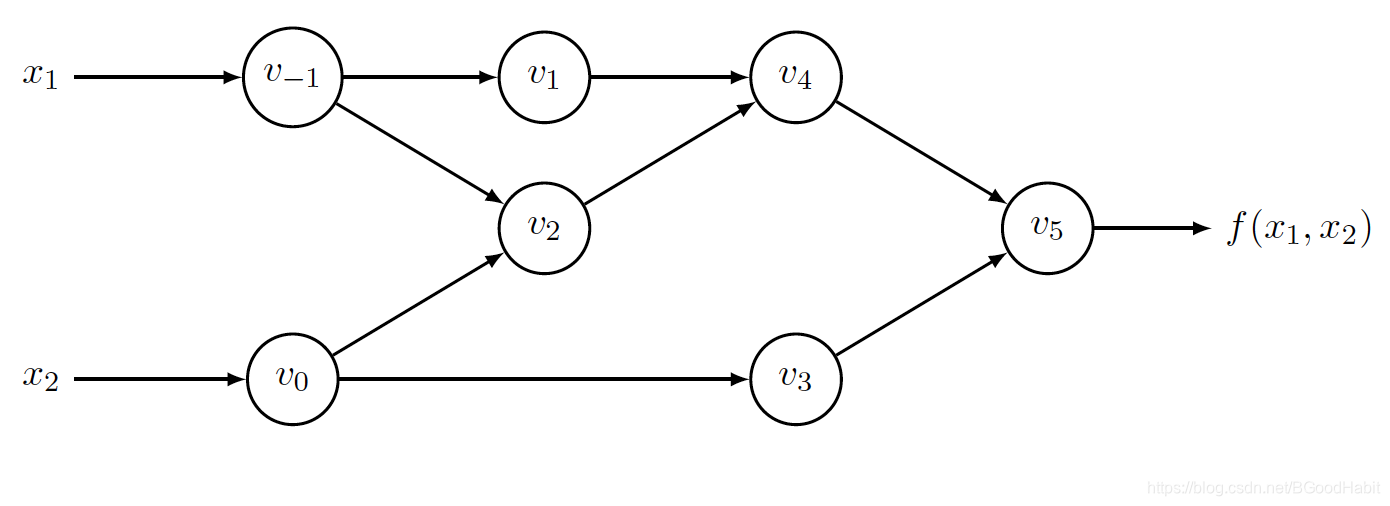
自动微分的反向模式通过从输出反向计算各变量的偏导数,我们定义变量 v ‾ i = ∂ y j ∂ v i \overline{v}_i = \frac{\partial y_j}{\partial v_i} vi=∂vi∂yj,还是回到例子 y = f ( x 1 , x 2 ) = l n ( x 1 ) + x 1 x 2 − s i n ( x 2 ) y=f(x_1,x_2)=ln(x_1) + x_1x_2 - sin(x_2) y=f(x1,x2)=ln(x1)+x1x2−sin(x2),从上述构造的图可以看出,变量 v 0 v_0 v0通过影响 v 2 和 v 3 v_2和v_3 v2和v3来影响 y y y,所以, v 0 v_0 v0对 y y y影响可以通过如下公式计算: ∂ y ∂ v 0 = ∂ y ∂ v 2 ∂ v 2 ∂ v 0 + ∂ y ∂ v 3 ∂ v 3 ∂ v 0 \frac{\partial y}{\partial v_0} = \frac{\partial y}{\partial v_2}\frac{\partial v_2}{\partial v_0}+\frac{\partial y}{\partial v_3}\frac{\partial v_3}{\partial v_0} ∂v0∂y=∂v2∂y∂v0∂v2+∂v3∂y∂v0∂v3 或者 v 0 ‾ = v 2 ‾ ∂ v 2 ∂ v 0 + v 3 ‾ ∂ v 3 ∂ v 0 \overline{v_0} = \overline{v_2}\frac{\partial v_2}{\partial v_0}+\overline{v_3}\frac{\partial v_3}{\partial v_0} v0=v2∂v0∂v2+v3∂v0∂v3 在反向模式里,我们首先以 v 5 ‾ = y ‾ = ∂ y ∂ y = 1 \overline{v_5}=\overline{y}=\frac{\partial y}{\partial y}=1 v5=y=∂y∂y=1开始,在最后我们得到 ∂ y ∂ x 1 = x 1 ‾ 和 ∂ y ∂ x 2 = x 2 ‾ \frac{\partial y}{\partial x_1}=\overline{x_1} 和 \frac{\partial y}{\partial x_2}=\overline{x_2} ∂x1∂y=x1和∂x2∂y=x2,只需要一次反向计算。 相对前向模式,反向模式最大的优势是需要更少的计算,对于函数 f : R n → R f: R^n \to R f:Rn→R这样有 n n n个输入,反向模式只需要一次计算就可以得到所有的梯度 ∇ f = ( ∂ y ∂ x 1 , . . . , ∂ y ∂ x n ) \nabla f = (\frac{\partial y}{\partial x_1},...,\frac{\partial y}{\partial x_n}) ∇f=(∂x1∂y,...,∂xn∂y),而前向计算需要算 n n n次前向计算。我们来看下在反向计算函数 f ( x 1 , x 2 ) f(x_1,x_2) f(x1,x2)过程 step 1: 前向计算各变量的值 和自动微分的前向模式一样,首先前向计算出每个变量的值 step 2: 反向计算各变量的梯度值 step 2: 反向计算各变量的梯度值 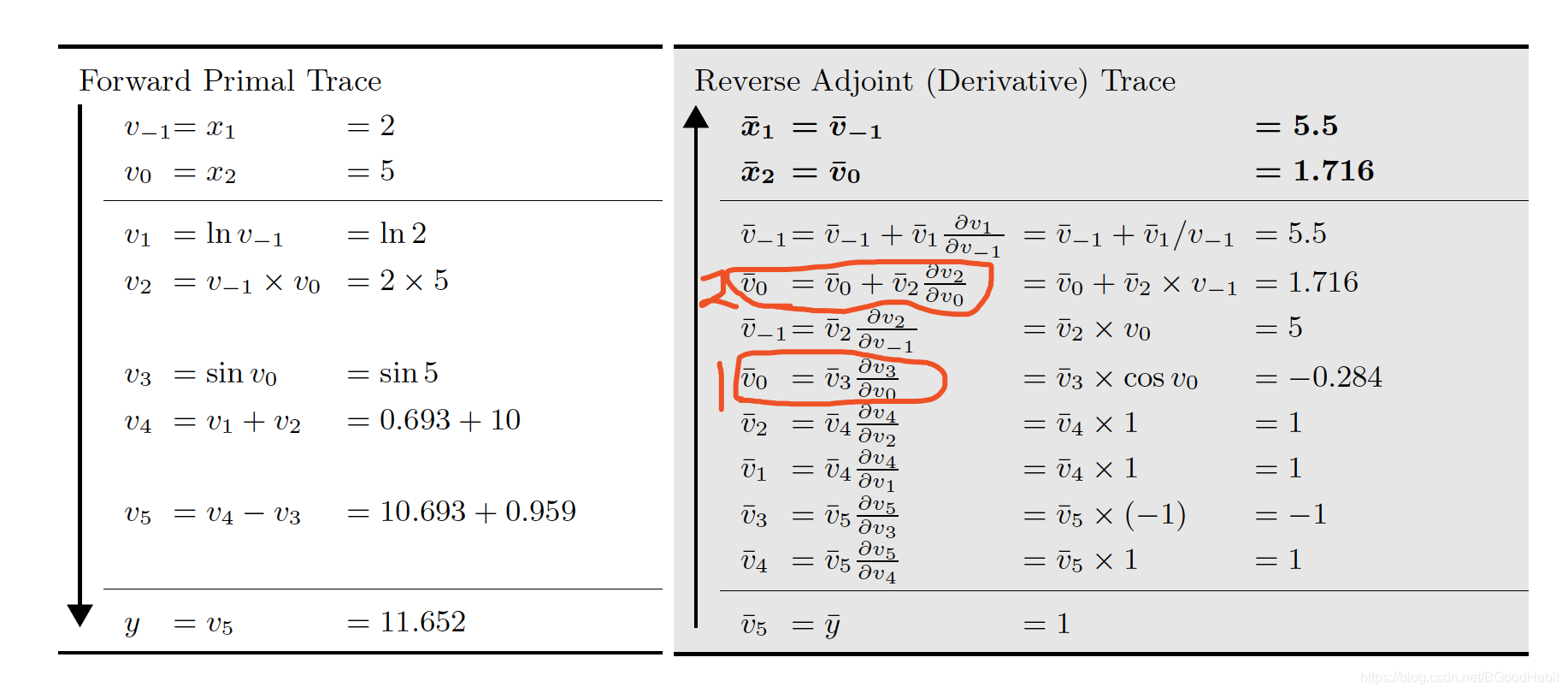
从下往上计算,其中 v 5 ‾ , v 4 ‾ , v 3 ‾ , v 1 ‾ , v 2 ‾ \overline{v_5}, \overline{v_4}, \overline{v_3}, \overline{v_1}, \overline{v_2} v5,v4,v3,v1,v2计算很容易求解得到,接下来我们来看 v 0 ‾ \overline{v_0} v0的计算,首先从构造的图来看, v 0 v_0 v0作用于 v 3 v_3 v3和 v 2 v_2 v2, 而 v 3 = sin v 0 v_3 = \sin{v_0} v3=sinv0,所以在反向模式里,如上图所示,标红的第一次计算 v 0 ‾ = ∂ y ∂ v 3 ∂ v 3 ∂ v 0 = v 3 ‾ ∂ v 3 ∂ v 0 \overline{v_0}=\frac{\partial y}{\partial v_3}\frac{\partial v_3}{\partial v_0}=\overline{v_3}\frac{\partial v_3}{\partial v_0} v0=∂v3∂y∂v0∂v3=v3∂v0∂v3,第二次计算 v 0 ‾ = ∂ y ∂ v 3 ∂ v 3 ∂ v 0 + ∂ y ∂ v 2 ∂ v 2 ∂ v 0 = v 0 ‾ + v 2 ‾ ∂ v 2 ∂ v 0 \overline{v_0}=\frac{\partial y}{\partial v_3}\frac{\partial v_3}{\partial v_0}+\frac{\partial y}{\partial v_2}\frac{\partial v_2}{\partial v_0}=\overline{v_0}+\overline{v_2}\frac{\partial v_2}{\partial v_0} v0=∂v3∂y∂v0∂v3+∂v2∂y∂v0∂v2=v0+v2∂v0∂v2,同理,可得到 v ‾ − 1 \overline{v}_{-1} v−1的结果 4.3 小结对于一个函数 f : R n → R m f : R^n \to R^m f:Rn→Rm,假设计算函数 f f f的所有operation操作总和记做 o p s ( f ) ops(f) ops(f),则计算一个 m × n m×n m×n的雅可比导数矩阵,自动微分的前向计算需要 n c nc nc次 o p s ( f ) ops(f) ops(f)操作,反向模式需要 m c mc mc次 o p s ( f ) ops(f) ops(f)操作,其中 c < 6 c < 6 c |
 每个中间变量
v
i
v_i
vi,计算对
x
1
x_1
x1的偏导数记做:
v
˙
=
∂
v
i
∂
x
1
v˙= \frac{\partial v_i}{\partial x_1}
v˙=∂x1∂vi 接下来,我们看自动微分的前向模式计算细节,我们按照输入
(
x
1
,
x
2
)
=
(
2
,
5
)
(x_1, x_2)=(2,5)
(x1,x2)=(2,5)为例:
每个中间变量
v
i
v_i
vi,计算对
x
1
x_1
x1的偏导数记做:
v
˙
=
∂
v
i
∂
x
1
v˙= \frac{\partial v_i}{\partial x_1}
v˙=∂x1∂vi 接下来,我们看自动微分的前向模式计算细节,我们按照输入
(
x
1
,
x
2
)
=
(
2
,
5
)
(x_1, x_2)=(2,5)
(x1,x2)=(2,5)为例:【本文地址】
今日新闻 |
推荐新闻 |