python |
您所在的位置:网站首页 › 视频里的字幕怎么转语音 › python |
python
|
文章目录
问题第一种离线语音模型方案先说后者,源码原理如下调用离线语音识别模型识别源码
第二种收费方案,问题解决思路导出音频分片,导出音频时间信息自动识别停顿,对声音切片编写函数,对语音分片实现语音识别,得到文字信息对csv文件处理,得到编写srt文件需要的信息处理时间格式的代码主文件调用,并主导srt文件生成
问题
两种方案生成srt文件,一个是调用其他平台的服务,一个是使用语音识别模型 前者收费,后者免费 第一种离线语音模型方案 先说后者,源码原理如下输入视频文件所在的文件夹,然后自动扫描得到所有以mp4结尾的文件 然后对这些文件进行声音分离得到wav声音文件 然后将这些wav文件分别送入语音识别模型 语音识别模型识别完成后生成srt文件放入同级目录下 语音模型的下载地址:都是免费的离线语音模型 有中,日,英离线语音识别模型 官网 模型文件下载地址https://alphacephei.com/vosk/models 调用离线语音识别模型识别源码 from moviepy.editor import * from moviepy.audio.fx.all import audio_left_right from moviepy.audio.AudioClip import AudioArrayClip import time def list_files(path): fileMP4List = [] fileSRTList = [] count=1 # 遍历目录下的所有文件和子目录,并输出 for root, dirs, files in os.walk(path): for file in files: if file.endswith("mp4"): fileMP4List.append([count,os.path.join(root, file)]) count=count+1 if file.endswith("srt"): fileSRTList.append(os.path.join(root, file)[:-4]) for i in range(len(fileMP4List)): if fileMP4List[i][1][:-4] in fileSRTList: fileMP4List[i][1]+=" 已有srt" return fileMP4List def getWav(videoPath): print("提取音频") clip = VideoFileClip(videoPath) audio = clip.audio # 将音频转换为单通道 audio_array = audio.to_soundarray() audio_left_right(audio_array) # 获取音频剪辑的持续时间 duration = audio.duration # 将单通道音频转换为音频剪辑对象 audio_mono = AudioArrayClip(audio_array, fps=audio.fps) newWavePath=videoPath[:-4]+'.wav' # 保存音频为WAV文件 audio_mono.write_audiofile(newWavePath) print("音频生成完成,准备输出srt") return newWavePath def getSrt(newWavePath): print("提取srt中...") print("开始加载识别模型") import subprocess import os import sys from vosk import Model, KaldiRecognizer, SetLogLevel SAMPLE_RATE = 16000 SetLogLevel(-1) # 解压的模型文件,英文,中文用对应model getCn=r"D:\Mycode\pythonCode\voice_txt\code\model\cn\vosk-model-cn-kaldi-multicn-0.15" getCn1=r"D:\Mycode\pythonCode\voice_txt\code\model\cn\vosk-model-cn-0.22" getJP=r"D:\Mycode\pythonCode\voice_txt\code\model\jp\vosk-model-ja-0.22" getEn=r"D:\Mycode\pythonCode\voice_txt\code\model\en\vosk-model-en-us-0.42-gigaspeech" model = Model(getCn) print("模型加载完毕,开始识别...") rec = KaldiRecognizer(model, SAMPLE_RATE) # 修改需要识别的语音文件路径 wavPath=newWavePath rec.SetWords(True) result = [] with subprocess.Popen(["ffmpeg", "-loglevel", "quiet", "-i", wavPath, "-ar", str(SAMPLE_RATE) , "-ac", "1", "-f", "s16le", "-"], stdout=subprocess.PIPE).stdout as stream: word=rec.SrtResult(stream) result.append(word) print(word) print(result) # 生成srt文件 output = open(wavPath[:-4]+'.srt','w') output.write("\n".join(result)) output.close() print("srt输出完成") os.remove(wavPath) while(1): # 列出当前目录下的所有文件和子目录 filePath = r"E:" allFile = list_files(filePath) for i in range(0, len(allFile)): if "已有srt" in allFile[i][1]: pass else: videoPath = allFile[i][1] print("开始识别的文件为:"+videoPath) try: getSrt(getWav(videoPath)) except: pass time.sleep(3) 第二种收费方案,问题各大平台都有长语音转写的服务,但是收费昂贵,而且有次数和时间限制。 因此我想到了一个白嫖的好办法。将长音频根据语句停顿切割得到短音频,使用他们提供的短音频识别服务来识别长音频不是更好吗?粗略计算了下,可以使用的时长为50000分钟,(提供的短音频识别服务次数以及时长远大于长音频)白嫖。 至于视频声音的停顿时间也是很容易得到的。 最后根据文字与文字出现的时间很容易就得到了视频的srt字幕 解决工程路径:https://download.csdn.net/download/lidashent/15453846 注意字幕导出的地址,自己修改一下,原理都讲清楚了,有需求根据自己的需求改就行了。 有疑问留言,我必解释好吧 思路 导出视频声音,根据声音停顿得到短句,同时导出短句的时间信息将长音频切割得到的多个短句文件分别进行语音识别,得到识别文字识别得到的文字与短句的时间信息处理得到视频srt字幕文件 导入srt字幕文件即可得到效果,如图 播放器推荐暴风影音或者迅雷,文字可以调节变色,大小,位置都比较方便。 原先视频是没有字幕的,经过上述处理得到srt文件就如同看字幕电影一样了。 得到的srt文件如图 原先视频是没有字幕的,经过上述处理得到srt文件就如同看字幕电影一样了。 得到的srt文件如图  接下来就一步一步开始吧,srt文件格式原理是什么,看我另一篇有关视频声音转为字幕的。那篇使用的长录音转文字接口,优惠力度不大,用几次就没了,所以特意写了这一篇可以白嫖而且时间非常长的,用个几个月都没有问题。 只需要关注srt格式就可以了 https://blog.csdn.net/lidashent/article/details/113987349
导出音频分片,导出音频时间信息 接下来就一步一步开始吧,srt文件格式原理是什么,看我另一篇有关视频声音转为字幕的。那篇使用的长录音转文字接口,优惠力度不大,用几次就没了,所以特意写了这一篇可以白嫖而且时间非常长的,用个几个月都没有问题。 只需要关注srt格式就可以了 https://blog.csdn.net/lidashent/article/details/113987349
导出音频分片,导出音频时间信息
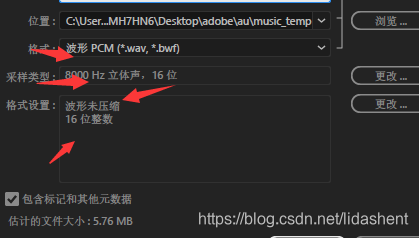
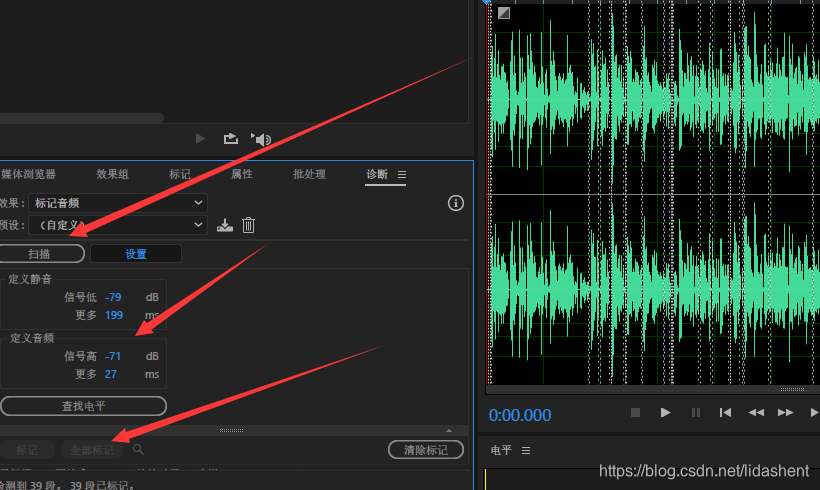
先将视频声音导出,设定标准为16bit,8000hz,这里使用的au,adobe audition (—解释—:)【这是短语音识别要求的】 (—解释—:)【这里需要注意的是,虽然切片对人声进行了保留,但是不乏切割到的音频有的是空白,因此需要一个大小判断,低于100kb可以默认为无声,当然条件自己设定吧】 效果-诊断-标记音频 设置静默阈值,时长越低分片越多,反向同理 声音阈值,时长越长,分片越少,反向同理 设置合适的阈值,注意自动分割的音频片,极限60s,最好不要超过45s 有音频片长度过长也不行,影响字幕观看,你不想看视频的时候视频上都是字幕吧?我一般看到分片间隔差不多10s就够了,这意味着10s左右会自动切换到下一个视频字幕信息 然后点击扫描, 再点击全部标记,就会显示灰色的标记信息
|
 点击到标记条,可以看到分片信息, ctrl a全选,然后右键选择导出音频,导出csv
点击到标记条,可以看到分片信息, ctrl a全选,然后右键选择导出音频,导出csv 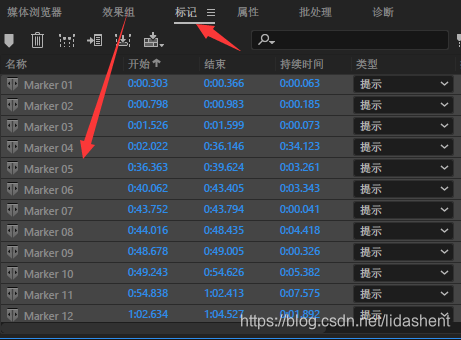 得到声音的发音时间,得到这段发音时间内的音频
得到声音的发音时间,得到这段发音时间内的音频 
 输出会附带进度信息。 得到srt文件导入对应视频就可以看到字幕效果了。
输出会附带进度信息。 得到srt文件导入对应视频就可以看到字幕效果了。【本文地址】
今日新闻 |
推荐新闻 |