faceswap换脸开源项目手把手教程 |
您所在的位置:网站首页 › 视频脸部合成素材下载 › faceswap换脸开源项目手把手教程 |
faceswap换脸开源项目手把手教程
|
写在前面: 作为一个初学者,这篇文章的完成主要是借助了这篇文章:faceswap Guide Extraction - A Workflow和D9区的 deepfakes/faceswap gui详细使用教程的一系列文章,感谢他们的付出,没有这些老师为我做指引就没有这篇文章,再此我只是做一个缝合。 faceswap介绍
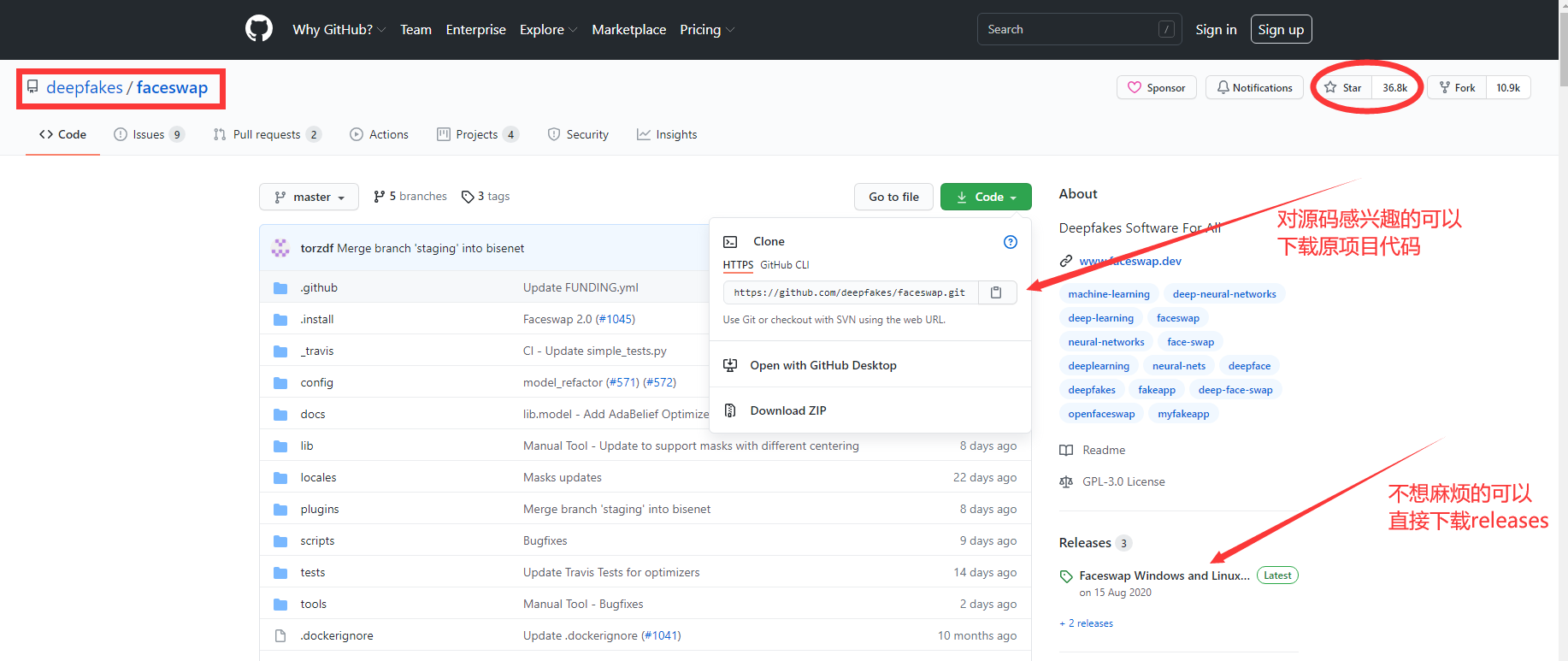
原项目链接:https://github.com/deepfakes/faceswap faceswap是当前最主流的开源换脸项目之一,目前在github上star数36.8k。 faceswap是领先的免费开源多平台Deepfakes软件。 由TensorFlow、Kera和Python提供支持;Faceswap将在Windows、MacOS和Linux上运行。 它支持使用CPU或GPU训练模型,对AMD和NVIDIA的支持不太一样,这里主要以NVIDIA的CUDA核心为例。 附项目网站:https://faceswap.dev/ 下载与安装
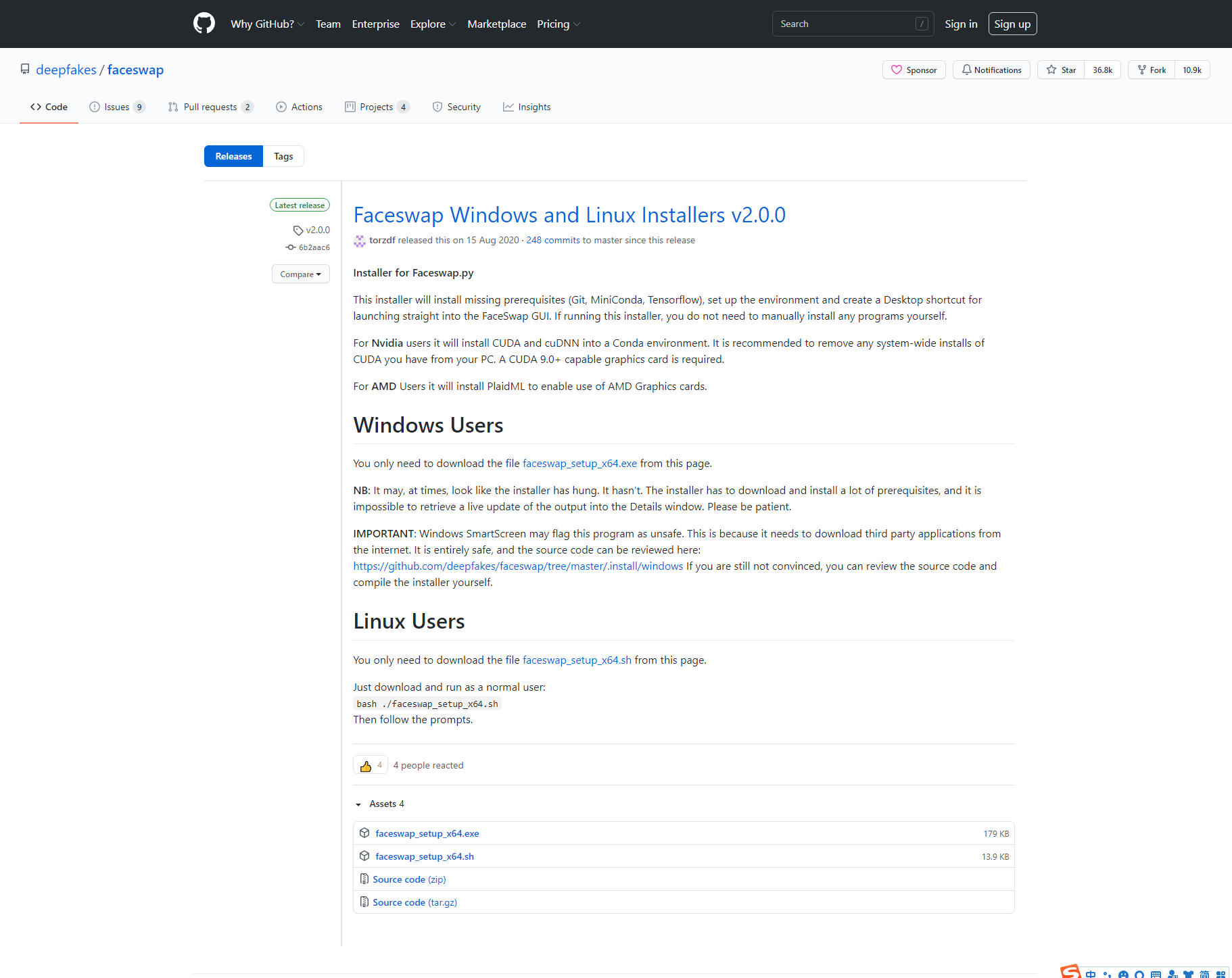
https://github.com/deepfakes/faceswap.git 可以通过git直接下载原项目,也可以只用已经打包好的releases版本(目前版本为2.0.0): https://github.com/deepfakes/faceswap/releases/tag/v2.0.0
对于源码方式,需要手动使用项目内的setup.py安装相关的组件包,对于使用exe方式的用户可以通过可视化的方式下一步安装。注意:这一步需要下载大量组件,且为了之后的训练模型,建议预留出至少4G的大小。 安装完成后桌面可见图标。 准备工作这里需要提前准备好被换脸的素材和换脸的素材,我这里分别拿两段视频为例,如果是图片亦可,需要注意的是视频也是会被处理成一帧一帧的图片的,对于新手而言,1000~3000张有效人脸图片较为合适,换算为视频大概为30秒到一分钟的视频比较合理。 初次进行换脸,准备的视频图片素材应尽量避免人脸模糊、人脸被遮挡、人脸在画面边缘导致不全等情况。 互换的两个素材尽量保持肤色接近,表情接近,以达到更好的效果。 展示项目结构(仅供参考,可不一致):F:\FaceswapRepos\20210608Tjf├─Media (存放初始视频素材,后期的对齐文件会自动生成在此)├─A_Image (存放被换脸视频处理后得到的大头图片)├─B_Image (存放换脸视频处理后得到的大头图片)├─Output (最终输出的图片素材)└─Training (存放训练模型文件) 第一步:Extractfaceswap的Extract模块主要包含3个功能: 人脸识别:在图片或视频的图像帧中找出人脸 人脸对齐:在识别到的人脸上找到“地标”(共68个特征点),从而确定人脸的方向 生成遮罩(可选项):遮罩可以突出人脸部分,遮罩外的像素将被认为是背景或障碍物
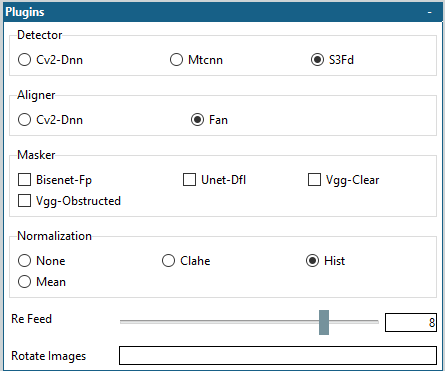
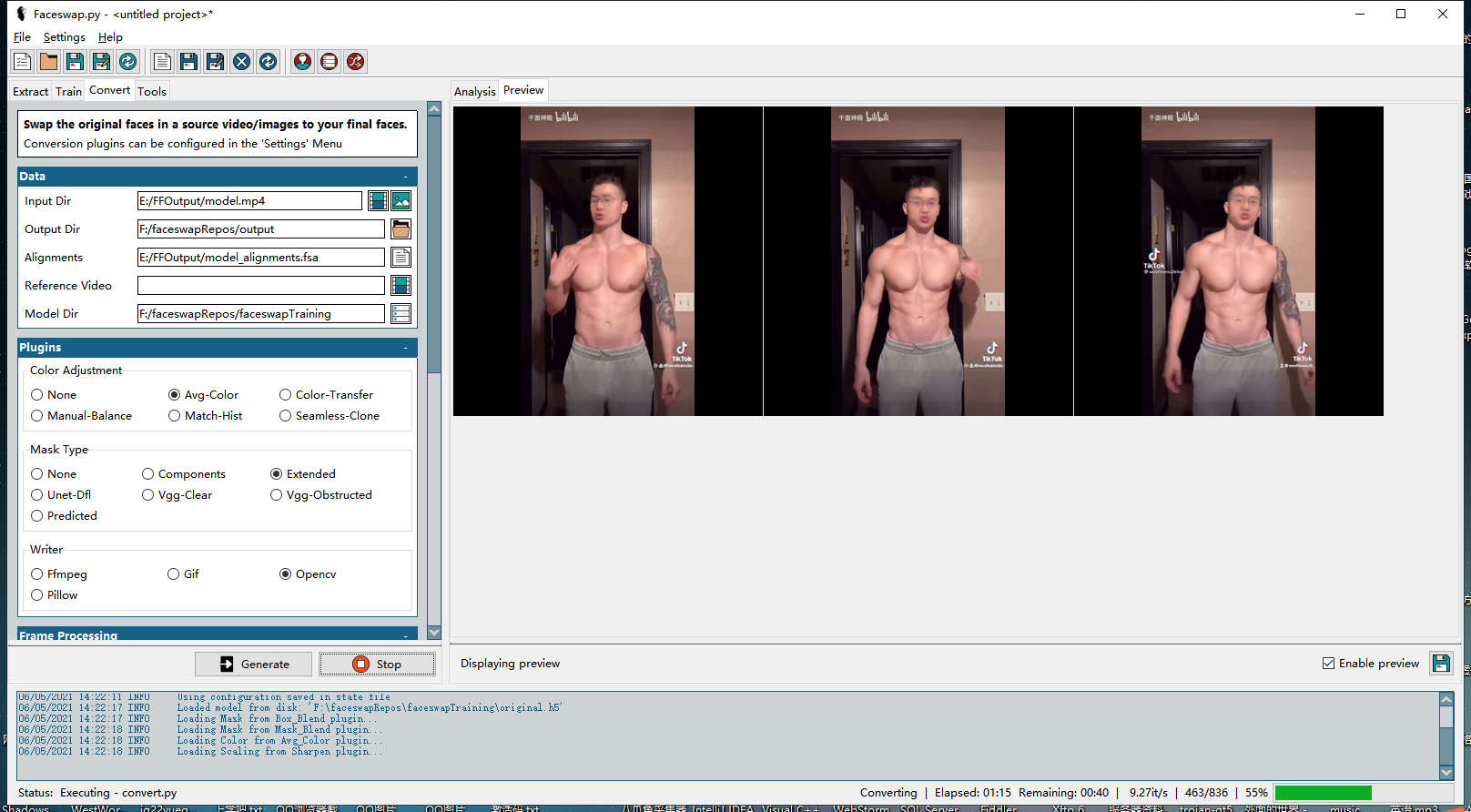
通过faceswap的extract模块我们可以得到以下2类文件: 从素材源中提取出的一系列人脸图片主要用于Train模块以进行后续的模型训练; 对齐文件可用于Train模块后续的模型训练(但非必须),它包含了可能会被用到的遮罩信息,此外,当Train模块中勾选“Warp to Landmarks”时,它可以提供人脸“地标”信息; 对于Convert模块来说,虽然对齐文件不是必不可少的,但它会极大的影响最终换脸的实际效果,除了包含可能会被用到的遮罩信息以外,它更重要的作用是告诉Convert模块原始图片或原始视频帧中需要被“换脸”的人脸位置。 打开软件创建一个新项目并保存: Input Dir: 这里我们可以选择一个视频文件,也可以选择一个包含一系列图片的文件夹,作为Extract的素材源 Output Dir: 这里我们可以选择一个文件夹,作为提取出的人脸图片的存放路径 Alignments: 计算得到的对齐文件目录,这里留空的话faceswap默认会把对齐文件输出到上面的“Input Dir”文件夹。 Plugins:
Detector, Aligner: 选择检测和对准算法,目前最优选择是:S3FD + FAN Masker: BiSeNet-FP - 在 CelebHQ-Masked 数据集上训练的相对轻量级的 NN 掩码。 从 https://github.com/zllrunning/face-parsing.PyTorch 移植。 此遮罩在其配置设置中具有附加选项,允许在遮罩区域内包含/排除头发、耳朵、眼睛和眼镜。 这是唯一与“全头”训练兼容的遮罩生成插件,因为头发需要包含在面罩区域内才能以这种方式进行训练。 BiSeNet-FP with Hair and ears excluded from the mask (默认设置):
BiSeNet-FP with Hair and ears included in the mask (全头部训练所需的头发):
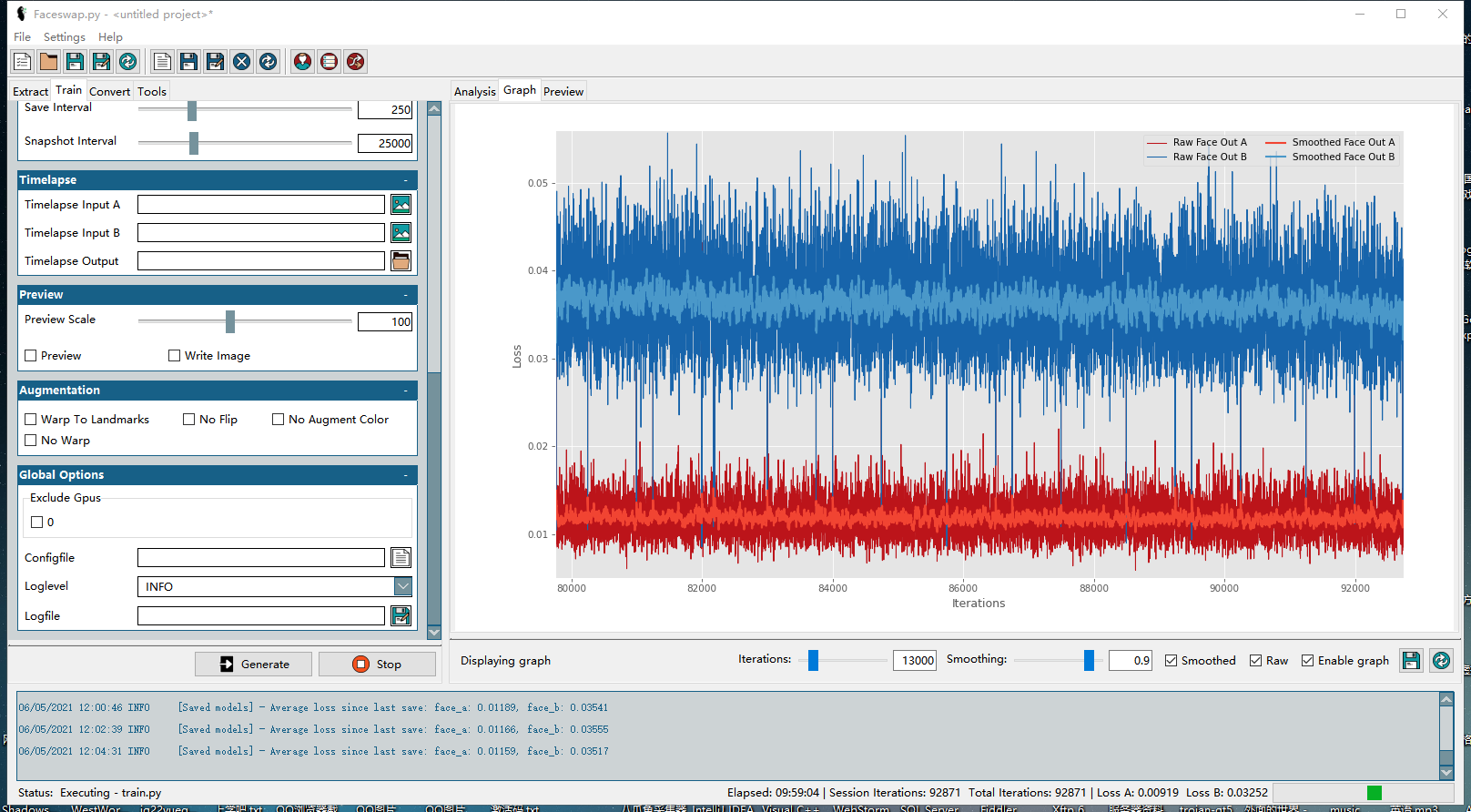
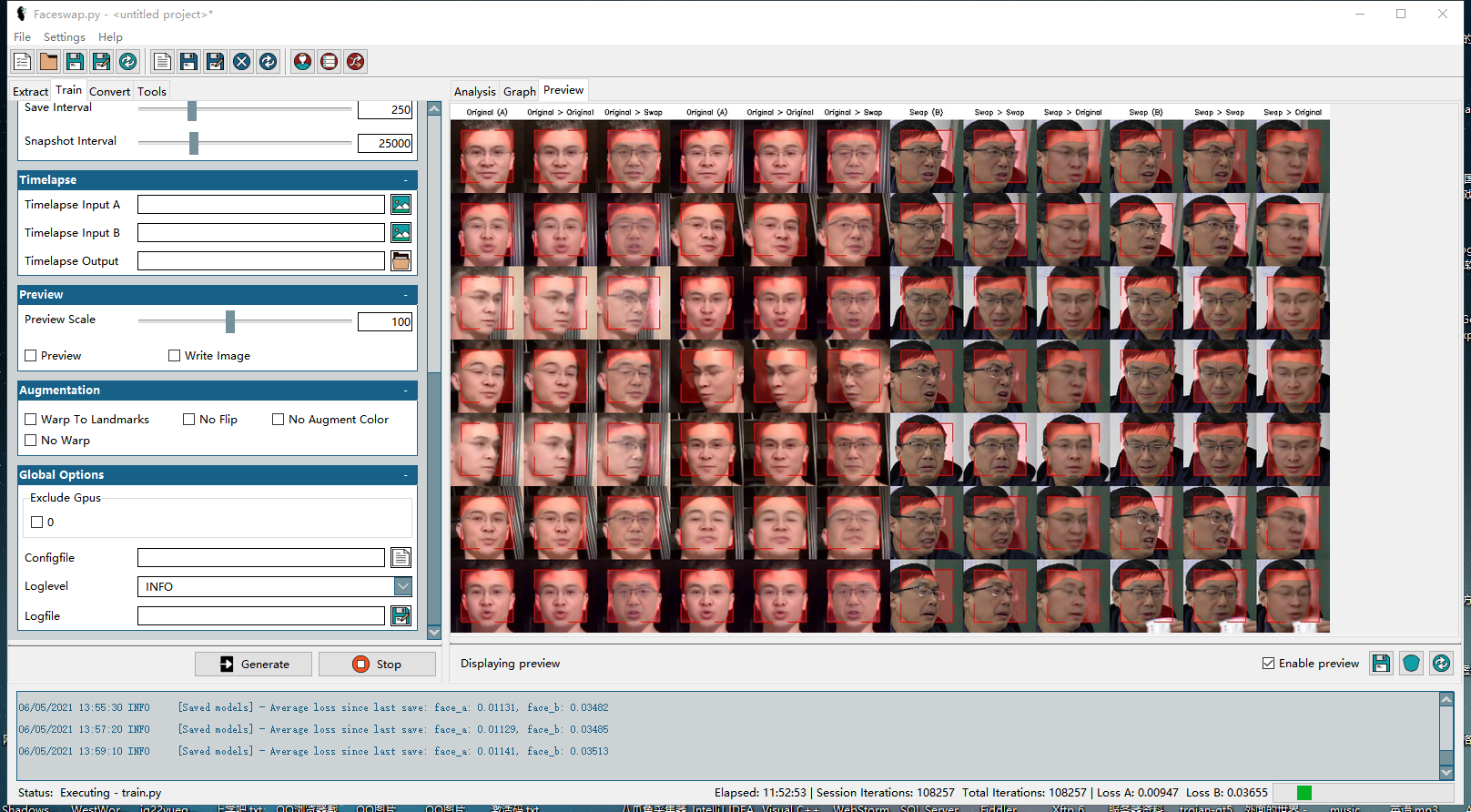
Unet-Dfl - 一个基于神经网络算法的遮罩生成插件,由开源社区成员训练维护 VGG-Clear - 另一个基于神经网络算法的遮罩生成插件,用于智能分割大部分正面的遮挡。 VGG-Obstructed - 设计用于对大部分正面脸进行智能分割。面具模型已经专门训练来识别一些面部障碍(手和眼镜)。 Normalization: 这一技术对输入提取器的图像进行处理,以便在光照困难的情况下更好地找到人脸。不同的标准化方法适用于不同的数据集,但我发现“hist”是最好的全能型。这将稍微慢提取,但它可以导致更好的对齐 Rotate Images: 不用管(除了CV2-DNN之外,对于所有的检测器来说,这是完全没有必要的。目前的探测器完全有能力在任何方向上发现面,所以这只会减慢你的进程,而收效甚微。) 训练结果可以看到训练到接近十万次左右的时候,大概花了10个小时左右。
|







【本文地址】
今日新闻 |
推荐新闻 |