利用Flink SQL实时统计单据状态(含历史数据) |
您所在的位置:网站首页 › 西安最近确诊病例人迹查询表 › 利用Flink SQL实时统计单据状态(含历史数据) |
利用Flink SQL实时统计单据状态(含历史数据)
|
背景
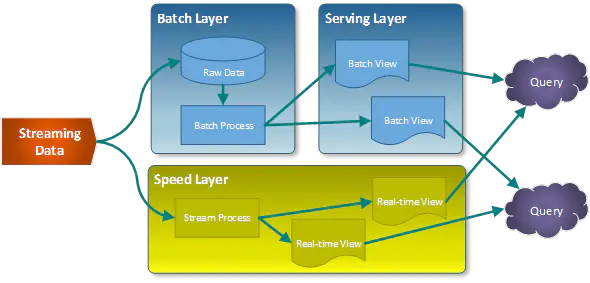
需求抽象下,有一种单据,整个生命周期中有很多种状态,现在要实时按照某个维度(例如用户id)统计其中某几个状态的数量,并按照该维度定时推送统计数据。 对于这个需求,解决办法有很多,那么什么情况下不需要Flink来实现? MySQL存储,单库单表,数据量比较小,直接sql查询MySQL存储,单库单表,统计维度和状态字段加了索引,且该维度数据比较分散,不会集中在某几个值(按照维度一次查询的数量比较少)业务接受统计数据延迟,例如一个小时更新一次,那么可以用小时离线表来统计有AnalyticDB(aliyun)、Elastic Search等分析型数据库可用(当然需要考虑成本问题)其实上面的场景已经覆盖大部分情况,从技术方案选型的角度来讲Flink一定是最后才考虑的方案,为什么这么说呢? 流式计算还是比较年轻的技术,开发体验还有待提高,尽管有FlinkSQL,但学习成本依然不低,需要转换思维调试成本比较高,无法像写代码那样调试计算逻辑,flink的调试通常只能看输入、输出需要有合适的数据输入,如果数据不合适的话,可能非常费事(下文会提到)那么什么情况下可以采用Flink的方案呢? 真的对实时性有严格要求,并且由于原始数据量级的问题,无法直接查询原始数据(对数据库压力太大,或耗时过久)出于学习的目的,且时间充裕其他因为直接查询路子走不通的情况(例如,分库分表了、数据量比较大太耗时)由于各种原因,申请不到分析型数据库,或者有现成的flink集群其他方案成本太高,包括 开发成本、机器资源成本、嘴皮子成本(开玩笑) 基本思路那么下面我们就来讨论实时要求下使用Flink的方案实现。 对于实时计算架构,业界有比较成熟两个方案,Lambda和Kappa Lambda架构比较成熟稳定,但是需要维护两套系统的代码,不易于维护
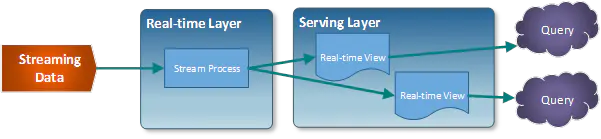
Kappa舍弃了离线数据,通过回溯流数据的方式来解决出问题后修复,但是如果时间跨度比较大的话,修复时间会很久,对于短期数据的统计,用这种方式肯定是更好的方案
对于我们这个需求: 首先时间跨度比较长,至少是几个月的然后要考虑应用代码的BUG等问题,如果纯用流式计算,如果不进行维护,后续的误差会越来越大,我们希望的是要有一定的自校准能力。另外结果的输出希望直接输出一张表,并且是全量数据,不必在应用层进行汇总,减少了一定的维护成本。结合我们的需求和这两个方案的优缺点,可以发现并不能照搬以上两种方案,需要做一些微创新
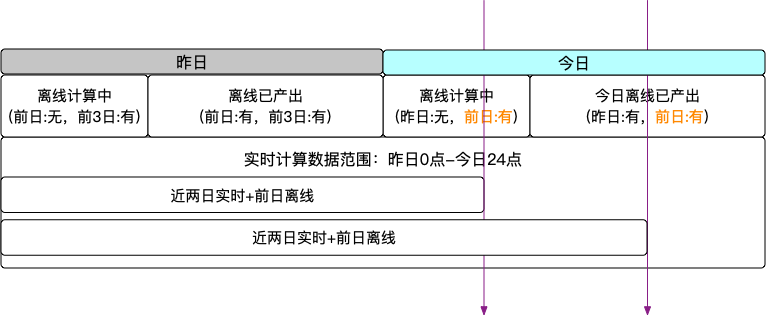
那么一个简单的雏形就出现了,但是会有一些问题 任务每次重启都要先做离线数据的初始化,如果没有初始化,今日无变化的数据就不会落到结果表中。这样除了实时任务外还需要一个初始化任务,每次重启任务就需要有两步,先初始化,然后将实时任务回溯到今日0点然后重跑我们知道离线数据通常需要花费比较久的时间,并且很多任务并不是0点就开始跑,有时候任务跑完就已经5、6点了,这期间离线数据用的是前天的,实时数据用的是今天的,这就会出现错误针对上面两个问题,可以考虑如下优化 主要是想省个事,这个好办,每天来定时刷一遍离线数据,如果有实时数据,那就以实时为准,没有则用离线。最重要的是可以通过这种方式用离线来对实时数据做一次校准,因为实时数据的效期是一天,如果第二天没有更新,这条数据就会被清理掉,那么就会替换为离线数据,起到了校准的目的。这个问题的本质是离线任务执行时间和实时计算的有效数据窗口之间有GAP,导致在离线任务产出之前,离线数据只有前日汇总可用,而实时计算的区间已经切换到今日,如下图所示
那么解决这个问题也比较简单,拉长实时计算的时间区间,给离线任务充足的时间,让离线数据和实时数据区间重叠即可,如下图所示,离线数据采用前日数据,不管昨日数据是否产生,实时数据从昨日0点开始统计,这样离线任务有整整一天的可执行时间,完全是充足的。
如果熟悉Flink撤回机制,很容易想到,这个不就是状态统计吗,两个group by不就搞定实时计数了吗? 如下面的代码所示,当同一个单据号的状态发生变化,就会撤回之前的那条数据,这个user_id下,前一个状态的计数就会减一。 select user_id,status,COUNT(orderNo) num from ( SELECT orderNo,LAST_VALUE(status) status ,LAST_VALUE(user_id) user_id from order_table group by orderNo ) group by user_id,status ;这样是很好,但是没有考虑单据生命周期跨越实时计算覆盖范围的情况,假如实时计算近两天的数据,我们要统计的状态是(10,15),这两个状态是连续的,考虑以下情况: 单据在两天前创建,状态没有到10,实时计算时有了状态为10的数据,此时 状态10计数+1。单据在近两天内创建,状态从10到15,由于单据状态为10或15都在实时计算范围内,根据撤回机制,状态10计数-1,状态15计数+1,很完美。单据在两天前创建且状态流转到10,在近两天出现了状态15,根据上面的sql,状态15计数+1,但并没有感知之前的状态10,所以加上离线数据的话,状态10的计数就多加了。简单说只利用实时计算的撤回机制,对于单据跨越实时计算覆盖范围的情况并不能很好处理。当然如果说我把实时计算区间设置大一些,几个月或者一年,超过单据最大生命周期的时间,这当然是可以的,但如果任务重启咋整,源数据并不会保存那么久,所以还是要考虑这个问题。 那状态变更的计数如何做呢? 根据上面描述,如果能拿到当前状态及前一个状态,那么可以对每个状态的计数进行加减。变更消息过来时,将更新后的状态计数加一,将更新前的状态计数减一,这样就能正确计数。但有时候现实会有很多限制条件,比如:状态变更消息没有更新前状态,或者干脆没有状态更新消息,那怎么办呢?改代码加上带更新前状态的消息,如果这种方式并不简单呢? 接入数据库变更日志(binlog)是一种很好的解耦方式,很多云服务提供的数据库都有对应的CDC(Change Data Capture)功能,像阿里云的Flink服务就提供了对应的connector(mysql-cdc);此外还有一些同步工具通过解析binlog将数据同步出来,通过开发对应的connector都可以对接上flink,例如Aliyun-DTS、canal等。 但是有些数据库同步工具没有变更前数据,对于数据同步的场景是无所谓的,但是我们这个场景是必须要的,对于这种情况,如果非要走下去,那就要加个中间层,缓存每个单据的前一次状态。有两种方案: 可以通过Flink的backend state 来存储,不过这个存储是有时效的,但单据的生命周期有可能大于存储时效,这时可以再引入离线数据。直接建一个单据前一次状态表,既作为维表又作为结果表,每次一条数过来先当做维表查询上一次状态,然后再把本次状态写入结果表。然而第2种方案有些重,引入了一张新的外部表,相当于同步了一份单据前一次状态的数据,并且还是要考虑离线数据的问题。而方案1,根据数据分布的特性,由于我们关心的状态在某一时刻,单据并不会很多,离线单据状态可以直接缓存到Flink,所以这里我决定还是用方案1来实现。 实现方案
整体的架构如上图所示,具体代码见文末附录。 方案说明: 单据上次状态:由于数据源没有更新前数据,因此我们只能利用Flink的存储,并加上离线的单据状态进行计算,得到前一次的状态值,这里自定义了聚合函数prevValue,缓存单据前一个状态,如果没有,那就从离线单据中取得,单据状态操作值转换:这里根据当前和上一次状态转换为+1或-1操作,如果两个状态一致,我们就要忽略掉,有可能是重复数据;利用UDTF,可能一条数据转为两条,上一次状态-1及当前状态+1;如果前一个状态为空,则忽略。注意点: 这里需要注意的是,从数据库同步到离线的单据,要选择通过更新时间来分区,这种方式会根据更新时间字段来判断某条数据该不该落到今天这个分区,这样会准确些。而普通的每天全量的方式就可能会把今天更新的数据也放到昨天的分区中,而我们实时计算的覆盖范围是识别更新时间的,这时有可能因为离线计算和实时计算有重叠而导致错误。 数据准确性调试数据的调试相对于业务逻辑的调试更加麻烦些,有如下原因: 测试数据不太好造,主要是因为场景多,输入输出输出比较复杂线上数据可能不如预期的规范,测试时不能覆盖到该场景我目前也没有什么比较好的办法,就是花时间造数据测试;在线上数据跑起来后要多验证,对于异常数据要把源数据拉下来找出原因。 可改进点 如果离线单据状态数据比较多,不能全部缓存,或者影响性能的话,可以引入其他存储,例如hbase。 参考资料 从Lambda架构到Kappa架构再到?浅谈未来数仓架构设计~flink官方文档 附录 Flink SQL代码 CREATE FUNCTION statusCount AS 'com.fliaping.flink.udf.StatusCountUdtf' ; CREATE FUNCTION prevValue AS 'com.fliaping.flink.udf.PrevValueUdaf' ; -- 采购单的tt数据源 create table xx_source ( id BIGINT ,gmt_modified VARCHAR ,user_id VARCHAR ,biz_status VARCHAR ,event_time AS PROCTIME() ,PRIMARY KEY (`id`) ) with ( type = 'your-db-type' ... ) ; -- 状态统计离线表 create table offline_order_status_num ( user_id VARCHAR COMMENT '供应商ID' ,biz_status VARCHAR COMMENT '业务状态' ,last_day_num BIGINT COMMENT '昨日待办数量' ,num BIGINT COMMENT '待办数量' ,ds VARCHAR COMMENT '分区字段' ,PRIMARY KEY (user_id, biz_status) ,PERIOD FOR SYSTEM_TIME --定义了维表的标识。 ) with ( type = 'your-offline-type' ... ) ; -- 单据状态离线表 create table order_status_history ( order_no VARCHAR COMMENT '供应商ID' ,biz_status VARCHAR COMMENT '业务状态' ,last_biz_status VARCHAR COMMENT '昨日状态' ,gmt_modified TIMESTAMP COMMENT '修改时间' ,last_gmt_modified TIMESTAMP COMMENT '昨日修改时间' ,ds VARCHAR COMMENT '分区字段' ,PRIMARY KEY (order_no) ,PERIOD FOR SYSTEM_TIME --定义了维表的标识。 ) with ( type = 'your-offline-type' ... ) ; -- 进行数据过滤 create VIEW filter_view AS select order_no ,user_id ,biz_status ,gmt_modified ,event_time FROM tt_source where order_no IS NOT NULL and user_id IS NOT NULL AND biz_status IS NOT NULL AND gmt_modified IS NOT NULL ; -- 获取Flink存储中的单据前一个状态,并缓存当前状态 CREATE VIEW get_before_biz_status AS SELECT order_no ,user_id ,biz_status ,TO_TIMESTAMP (gmt_modified) gmt_modified ,DATE_FORMAT (TO_TIMESTAMP (gmt_modified), 'yyyyMMdd') AS gmt_modified_day ,prevValue(biz_status) OVER (PARTITION BY order_no ORDER BY event_time) prev_biz_status FROM filter_view ; -- 对于Flink中没有存储上一次状态的单据,去离线数据中查出来 CREATE VIEW order_with_last_biz_status AS SELECT c.* -- 考虑每天的离线数据需要一定时间产出,故使用前日离线数据 ,IF ( d.ds = DATE_FORMAT ( date_sub (CURRENT_TIMESTAMP, 1), 'yyyy-MM-dd', 'yyyyMMdd' ) ,d.last_biz_status ,d.biz_status ) prev_biz_status_offline ,IF ( d.ds = DATE_FORMAT ( date_sub (CURRENT_TIMESTAMP, 1), 'yyyy-MM-dd', 'yyyyMMdd' ) ,d.last_gmt_modified ,d.gmt_modified ) gmt_modified_offline FROM get_before_biz_status c LEFT JOIN order_status_history FOR SYSTEM_TIME AS OF PROCTIME () d ON c.order_no = d.order_no AND c.prev_biz_status IS NULL ; -- 将状态迁移通过udtf映射为不同状态的操作数,例如,状态迁移为10-15-16,那么10来的时候,状态10的操作是+1,15来时,状态10 -1,15 +1,产生两条数据,16来时,15 -1, 这么做的原因是TT数据对于更新操作,没有更新前数据和更新后数据,对于状态计数只能通过加入业务状态机的方式识别状态变更到来时,哪个状态+1,哪个状态-1 CREATE VIEW status_shift_opt AS select S.order_no ,S.user_id ,S.biz_status ,S.gmt_modified_day ,S.gmt_modified ,T.effect_biz_status ,T.effect_biz_status_opt from ( -- 将离线和Flink中取到的前一个状态进行合并,确定该单据前一个状态 SELECT order_no ,user_id ,biz_status ,gmt_modified_day ,gmt_modified ,IF( prev_biz_status IS NULL AND prev_biz_status_offline IS NOT NULL ,prev_biz_status_offline ,prev_biz_status ) prev_biz_status FROM order_with_last_biz_status WHERE (gmt_modified_offline IS NOT NULL AND gmt_modified_offline < gmt_modified) or (gmt_modified_offline IS NULL) ) as S ,LATERAL TABLE (statusCount (biz_status,prev_biz_status)) as T (effect_biz_status, effect_biz_status_opt) ; -- 按照天数据进行分组,并过滤出近两天的数据 CREATE VIEW summary_with_day AS SELECT user_id ,effect_biz_status biz_status ,gmt_modified_day ,SUM(effect_biz_status_opt) num FROM status_shift_opt -- 实时数据,只统计昨日和今日的数据 WHERE effect_biz_status IN (10,15) GROUP BY user_id ,effect_biz_status,gmt_modified_day ; -- 按照供应商+状态维度进行分组,将近两日数据累加,得到(昨日+今日数量) CREATE VIEW summary_with_user_id_status AS SELECT user_id ,biz_status ,SUM(num) num FROM summary_with_day WHERE gmt_modified_day = DATE_FORMAT (CURRENT_TIMESTAMP, 'yyyyMMdd') or gmt_modified_day = DATE_FORMAT ( date_sub (CURRENT_TIMESTAMP, 1), 'yyyy-MM-dd', 'yyyyMMdd' ) GROUP BY user_id,biz_status ; -- 加上离线数量,维表离线数量(截止昨日0点) + 实时数量(昨日+今日)= 总数量 CREATE VIEW plus_offline_data AS SELECT user_id ,biz_status ,offline_num+num num ,CONCAT( 'offlineNum:' ,offline_num ,',realtimeNum:' ,num ,',sourceType:Flink_STREAM' ) attribute FROM ( SELECT a.user_id ,a.biz_status ,IF( b.ds = DATE_FORMAT ( date_sub (CURRENT_TIMESTAMP, 1), 'yyyy-MM-dd', 'yyyyMMdd' ) ,IF(b.last_day_num IS NULL,0,b.last_day_num) ,IF(b.num IS NULL,0,b.num) ) offline_num ,a.num FROM summary_with_user_id_status a LEFT JOIN offline_order_status_num FOR SYSTEM_TIME AS OF PROCTIME () b ON a.user_id = b.user_id and a.biz_status = b.biz_status ) ; create table mysql_output ( ,`user_id` varchar ,biz_status varchar ,num BIGINT ,attribute varchar ,primary key (biz_status, `user_id`) ) with ( type = 'mysql' ,url = 'jdbc:mysql://xxxxxx' ,tableName = 'order_status_count' ,userName = 'xxx' ,password = 'xxx' ) ; INSERT INTO mysql_output SELECT * FROM plus_offline_data ; UDFprevValue函数(UDAF:UDF - Aggregation Functions): package com.fliaping.flink.udf; import org.apache.flink.table.functions.AggregateFunction; public class PrevValueUdaf extends AggregateFunction { private static final long serialVersionUID = 3733259132660252997L; @Override public PrevValueAccum createAccumulator() { return new PrevValueAccum(); } @Override public String getValue(PrevValueAccum prevValueAccum) { return prevValueAccum.prevValue; } public void accumulate(PrevValueAccum accumulator, String iValue) { accumulator.prevValue = accumulator.currentValue; accumulator.currentValue =iValue; } public void retract(PrevValueAccum accumulator, String iValue) { accumulator.currentValue = accumulator.prevValue; accumulator.prevValue = iValue; } public void merge(PrevValueAccum accumulator, Iterable its) { for (PrevValueAccum it : its) { accumulator.currentValue = it.currentValue; accumulator.prevValue = it.prevValue; } } public static class PrevValueAccum { private String prevValue; private String currentValue; } }statusCount函数(UDTF:UDF - Table Functions): package com.fliaping.flink.udf; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.shaded.guava18.com.google.common.base.Objects; import org.apache.flink.table.functions.TableFunction; public class StatusCountUdtf extends TableFunction{ private static final long serialVersionUID = 5467096366714935845L; public void eval(String bizStatus, String prevBizStatus) { if(Objects.equal(bizStatus, prevBizStatus)) { return; } if (bizStatus != null) { collect(Tuple2.of(bizStatus, 1)); } if (prevBizStatus != null) { collect(Tuple2.of(prevBizStatus, -1)); } } }离线 SQL代码: -- 计算统计数量,包含day-1和day-2的数据 INSERT OVERWRITE TABLE order_status_num PARTITION(ds='${bizdate}') SELECT IF(a.user IS NULL,b.user_id,a.user_id) user_id ,IF(a.biz_status IS NULL,b.biz_status,a.biz_status) biz_status ,b.num last_day_num ,a.num FROM ( SELECT user_id ,biz_status ,COUNT(order_no) num FROM my_order WHERE ds = '${bizdate}' AND biz_status IN (10,15) GROUP BY user_id ,biz_status ) a FULL OUTER JOIN ( SELECT user_id ,biz_status ,COUNT(order_no) num FROM my_order WHERE ds = to_char(dateadd(to_date('${bizdate}', "yyyymmdd"), - 1, 'dd'), 'yyyymmdd') AND biz_status IN (10,15) GROUP BY user_id ,biz_status ) b ON a.user_id = b.user_id AND a.biz_status = b.biz_status ; -- 计算单据状态,包含day-1和day-2的数据 INSERT OVERWRITE TABLE order_status_history PARTITION(ds='${bizdate}') SELECT IF( a.order_no IS NULL ,b.order_no ,a.order_no ) order_no ,a.biz_status ,b.biz_status last_biz_status ,a.gmt_modified ,b.gmt_modified last_gmt_modified FROM ( SELECT order_no ,biz_status ,gmt_modified FROM my_order WHERE ds = '${bizdate}' AND biz_status IN (10,15) ) a FULL OUTER JOIN ( SELECT order_no ,biz_status ,gmt_modified FROM my_order WHERE ds = to_char(dateadd(to_date('${bizdate}', "yyyymmdd"), - 1, 'dd'), 'yyyymmdd') AND biz_status IN (10,15) ) b ON a.order_no = b.order_no ;文章来源:利用Flink SQL实时统计单据状态(含历史数据) - Fliaping's Blog |



【本文地址】
今日新闻 |
推荐新闻 |