【机器学习】准确率、精确度、召回率和 F1 定义 |
您所在的位置:网站首页 › 褶皱的布料是如何做成的 › 【机器学习】准确率、精确度、召回率和 F1 定义 |
【机器学习】准确率、精确度、召回率和 F1 定义
|
一、说明
数据科学家选择目标变量后 - 例如他们希望预测电子表格中的“列”,并完成了转换数据和构建模型的先决条件,最后步骤之一是评估模型的性能。 二、混淆矩阵的模型 2.1 混淆矩阵选择性能指标通常取决于要解决的业务问题。假设您的数据集中有 100 个示例,并且您已将每个示例输入模型并收到分类。预测与实际分类可以在称为混淆矩阵的表中绘制。0 Negative (predicted)Positive (predicted)Negative (actual)980Positive (actual)11上表描述了负输出与正输出。这两个结果是每个示例的“类”。由于只有两个类,因此用于生成混淆矩阵的模型可以描述为二元分类器。 (二元分类器的示例:垃圾邮件检测。所有电子邮件都是垃圾邮件或不是垃圾邮件,就像所有食物都是热狗或不是热狗一样。) 为了更好地解释该表,您还可以按照真阳性、真阴性、假阳性和假阴性来查看它。 Negative (predicted)Positive (predicted)Negative (actual)true negativefalse positivePositive (actual)false negativetrue positive 2.2 混淆矩阵的缺点包括只能评估模型的分类准确性,而不能评估模型的预测概率大小,无法解释模型的输出。 对于多分类问题,随着类别数的增加,混淆矩阵变得更加复杂,难以解释模型的表现。 混淆矩阵只能反映出数据集中已经存在的分类情况,无法衡量模型是否能够在未知数据上获得良好的表现。 对于不平衡数据集,混淆矩阵可能会误导分析者,因为它无法展现出各类别在数据集中的实际分布情况。 因此,混淆矩阵只是评估分类模型的一种方法,需要结合其他评价指标一起使用,才能更全面地评估模型的性能。 三、准确率 3.1 准确性总的来说,我们的模型正确的频率是多少?
作为一种启发式方法或经验法则,准确性可以立即告诉我们模型是否经过正确训练以及其总体表现如何。但是,它没有提供有关其应用于该问题的详细信息。 使用准确性作为主要性能指标的问题是,当类别严重不平衡时,它的效果并不好。 让我们使用上面混淆矩阵中的数据集。假设负面交易是正常交易,正面交易是欺诈交易。准确性会告诉您,您在所有课程中 99% 的时间都是正确的。 但我们可以看到,对于欺诈类别(正),您只有 50% 的时间是正确的,这意味着您将亏损。 天哪,如果你创建了一个硬性规则来预测所有交易都是正常的,那么你 98% 的时间都是对的。但这不是一个非常智能的模型,也不是一个非常智能的评估指标。这就是为什么当你的老板要求你告诉他们“这个模型有多准确?”时,你的答案可能是:“这很复杂。” 为了给出更好的答案,我们需要了解精确率、召回率和 f1 分数。 3.2 Accuracy的缺点如下不适合于不平衡的数据集:在不平衡的数据集中,即某些类别的数据数量明显较少时,使用Accuracy可能会导致误判严重。例如,在一个二分类问题中,若其中一类数据占总数据的90%,那么一个简单的模型总是预测这个类别,Accuracy值会很高,但是模型并没有学到有用的信息。 忽略了分类间的差异:在某些问题中,不同的分类可能具有不同的重要性,Accuracy无法表达出这些差异。例如,在癌症预测问题中,将正常人误判为患有癌症与将患有癌症的人误判为正常人所带来的影响是非常不同的。 受到异常值的影响:异常值(outliers)是指那些与其他数据明显不同的数据点,它们可能被视为一种错误或偏离了数据的正常分布。在某些情况下,单个的异常值可以对Accuracy带来很大的影响。 只是一个简单的指标:Accuracy是一个很简单的指标,它无法告诉我们模型的运行方式或任何有关错误分类的详细信息。其他的指标如precision、recall、F1-score等则可以更好地帮助我们了解不同类型的错误分类情况。 Accuracy Learn How to Apply AI to Simulations » 四2.3 精确 4.1 精确度模型当模型预测为正时,其正确率是多少?
当误报成本很高时,精确度会有所帮助。因此,我们假设问题涉及皮肤癌的检测。如果我们的模型精度非常低,那么许多患者将被告知他们患有黑色素瘤,这将包括一些误诊。许多额外的测试和压力都处于危险之中。当误报率过高时,那些监测结果的人会在遭受误报轰炸后学会忽略它们。 4.2 以下是Precision的一些缺点非常依赖于数据准确性:Precision需要高度准确的数据才能提供有用的结果。因此,如果数据质量较差,则可能会导致精度不准确。 忽略了其他指标:Precision只关注正确预测的正样本数量,而忽略了其他重要指标,如召回率、F1得分 五 召回率指标 5.1 召回率
当假阴性成本很高时,召回会有所帮助。如果我们需要探测来袭核导弹怎么办?假阴性会带来毁灭性的后果。如果搞错了,我们都会死。当漏报频繁发生时,您就会受到想要避免的事情的打击。假阴性是指当您决定忽略黑暗森林中树枝折断的声音时,您就会被熊吃掉。 (假阳性是在帐篷里彻夜不眠,冒着冷汗,听着森林里的每一个脚步声,结果第二天早上才意识到这些声音是花栗鼠发出的。这并不有趣。)如果你有一个模型,错误地让核导弹进入,你会想把它扔掉。如果你的模型因为花栗鼠而让你彻夜难眠,你也会想把它扔掉。如果像大多数人一样,您不想被熊吃掉,也不想整夜担心花栗鼠警报,那么您需要优化评估指标,该指标是精确度和召回率的综合衡量标准。输入 F1 分数... 5.2 召回率缺点有遗忘衰减现象:记忆在时间的推移中会遗忘和衰减,因此可能会出现遗忘部分信息或遗忘时间较久的信息的情况。 容易受到干扰:回忆时,可能会受到其他相关信息(干扰信息)的影响,导致原始信息被改变或者遗漏。 不准确性:记忆的准确性并不总是好的,有时候回忆出来的信息可能不够准确,或者与真实情况存在相差较大的误差。 依赖于情境:回忆的效率受到环境的影响,如果回忆时的情境与记忆时的情境不同,可能会影响到回忆效率。 受个人因素影响:个体回忆的能力不同,有些人可能回忆能力更好,有些人可能会遗忘更多的信息,这些个人因素也会影响到回忆的效果。 六 F1分数模型分析 6.1 F1分数
F1 是对模型准确性的总体衡量,结合了精确度和召回率,以一种奇怪的方式,加法和乘法只是将两种成分混合在一起形成一个单独的菜。也就是说,良好的 F1 分数意味着误报率和漏报率都较低,因此您可以正确识别真正的威胁,并且不会受到误报的干扰。当 F1 分数为 1 时,该模型被认为是完美的;而当 F1 分数为 0 时,则该模型完全失败。 请记住:所有模型都是错误的,但有些模型是有用的。也就是说,所有模型都会产生一些误报、一些误报,甚至可能两者都有。虽然您可以调整模型以最大限度地减少其中之一,但您通常会面临权衡,即假阴性的减少会导致假阳性的增加,反之亦然。您需要优化对您的特定问题最有用的性能指标。 6.2 F1分数的缺点包括:忽略了实际得分的大小:F1分数只关注模型预测的正例和真实正例之间的比例,而忽略了预测正确的样本个数和总预测样本个数的大小。这意味着在模型评估时,同样的F1分数可能对应着不同数量的正确预测。因此,F1分数不能完整地表示模型的性能。 不适用于不平衡类别:当不同类别的样本数量相差很大时,F1分数可能会受到影响。如果真实正例数很少,那么即使模型只能正确预测其中一些,F1分数也可能会很高。 只适合二分类问题:F1分数只能用于二分类问题。当涉及到多类别分类时,需要使用其他指标。 对于不同的阈值有不同的结果:F1分数的计算基于一个默认的阈值,该阈值不一定适用于所有问题。如果使用不同的阈值,F1分数的结果可能会有所不同,这使得比较不同模型的F1分数结果变得有挑战性。 因此,在使用F1分数进行模型评估时,需要注意以上的缺点,并结合其他指标来综合评估模型性能。 三、后记没有一个完美的模型,用户需要针对模型的优缺点,展开一种自主的分析,这才是最有益的尝试。
|
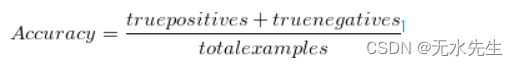

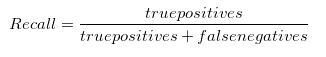
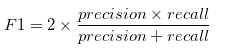
【本文地址】
今日新闻 |
推荐新闻 |