|
前言:本篇博客为《基于树莓派4B的YOLOv5-Lite目标检测的移植与部署》的后续博客,主旨为帮助大家实现 ONNX 模型到 NCNN 模型的转换,并且在树莓派4B进行成功部署!正常情况下,NCNN 模型是优于 ONNX 模型的,但是作者实际测试下来发现貌似 ONNX 模型的FPS和精度感觉都略优秀于 NCNN 模型,读者朋友可以根据自己时间情况去选择模型的使用!
实验效果图:

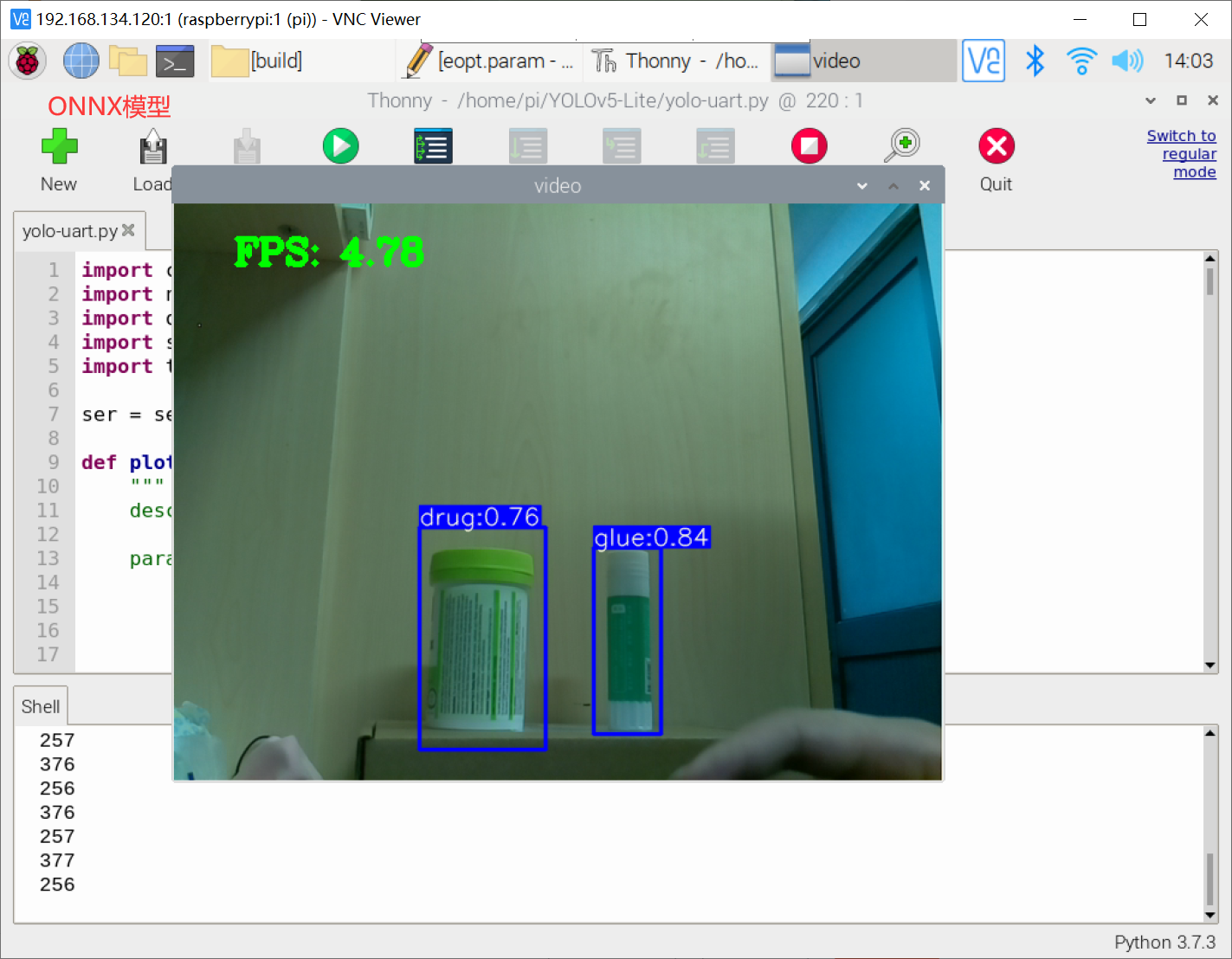
YOLOv5-Lite的ONNX模型FPS:4.78
YOLOv5-Lite的NCNN模型FPS:3.77
按道理来说,NCNN 模型的推理速度是快于 ONNX 模型的,作者这边也不知道什么情况。
一、工程前瞻
NCNN 的网络模型通常需要使用简化后的 ONNX 模型来转换,ONNX 模型依赖于原始的训练权重 Weight 的存在,故此我们需要使用自己的训练集于神经网络模型进行训练!
这部分的详解教程可以借鉴:http://t.csdn.cn/msjCZ
源码地址:ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite (github.com)
读者朋友可以使用 PyCharm 或者 VsCode 打开 Yolov5-Lite 的源码(作者使用PyCharm 2020.1 x64);
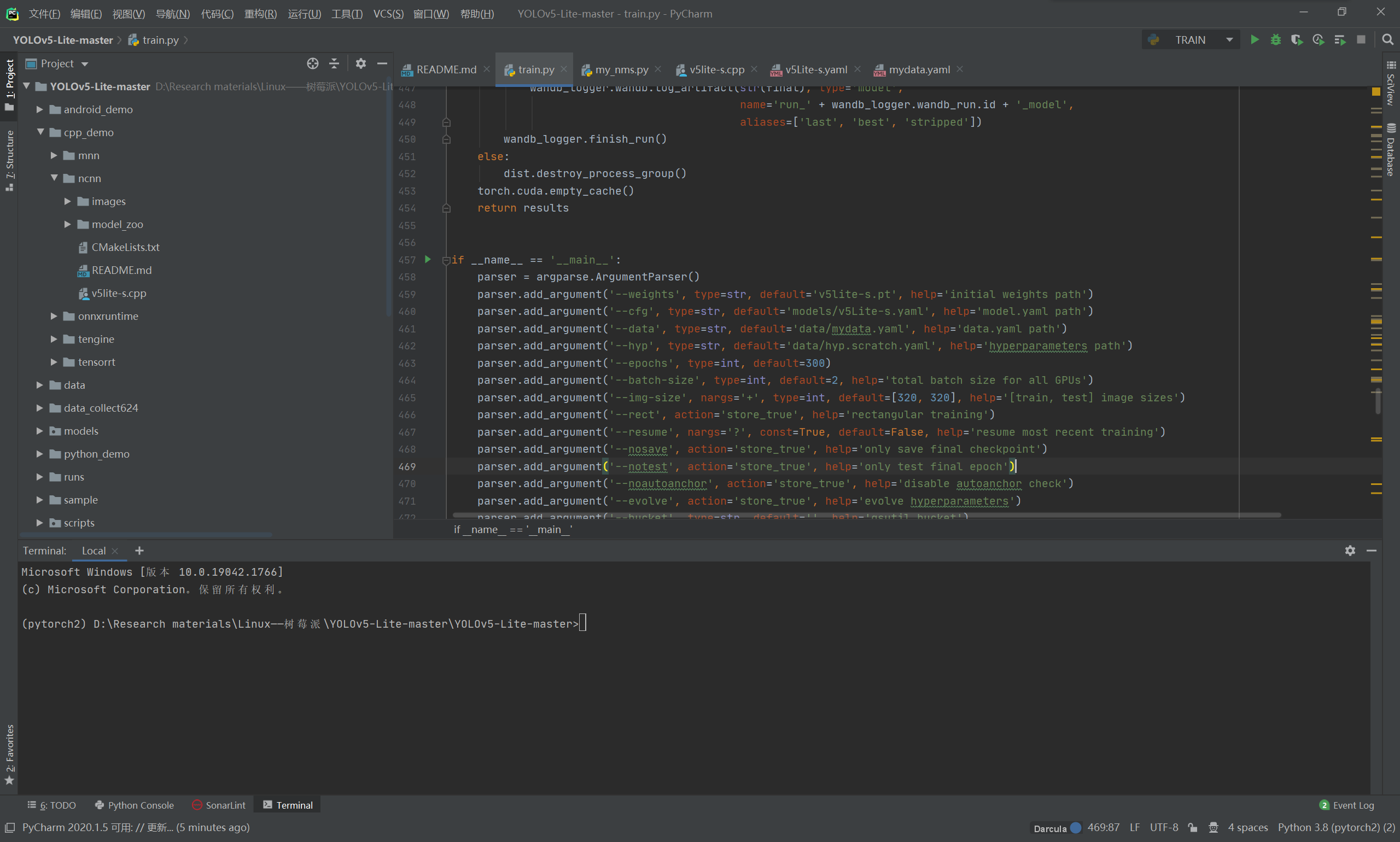
在 Yolov5-Lite 的目录下找到 train.py (训练文件)的 main 函数入口,进行如下配置:
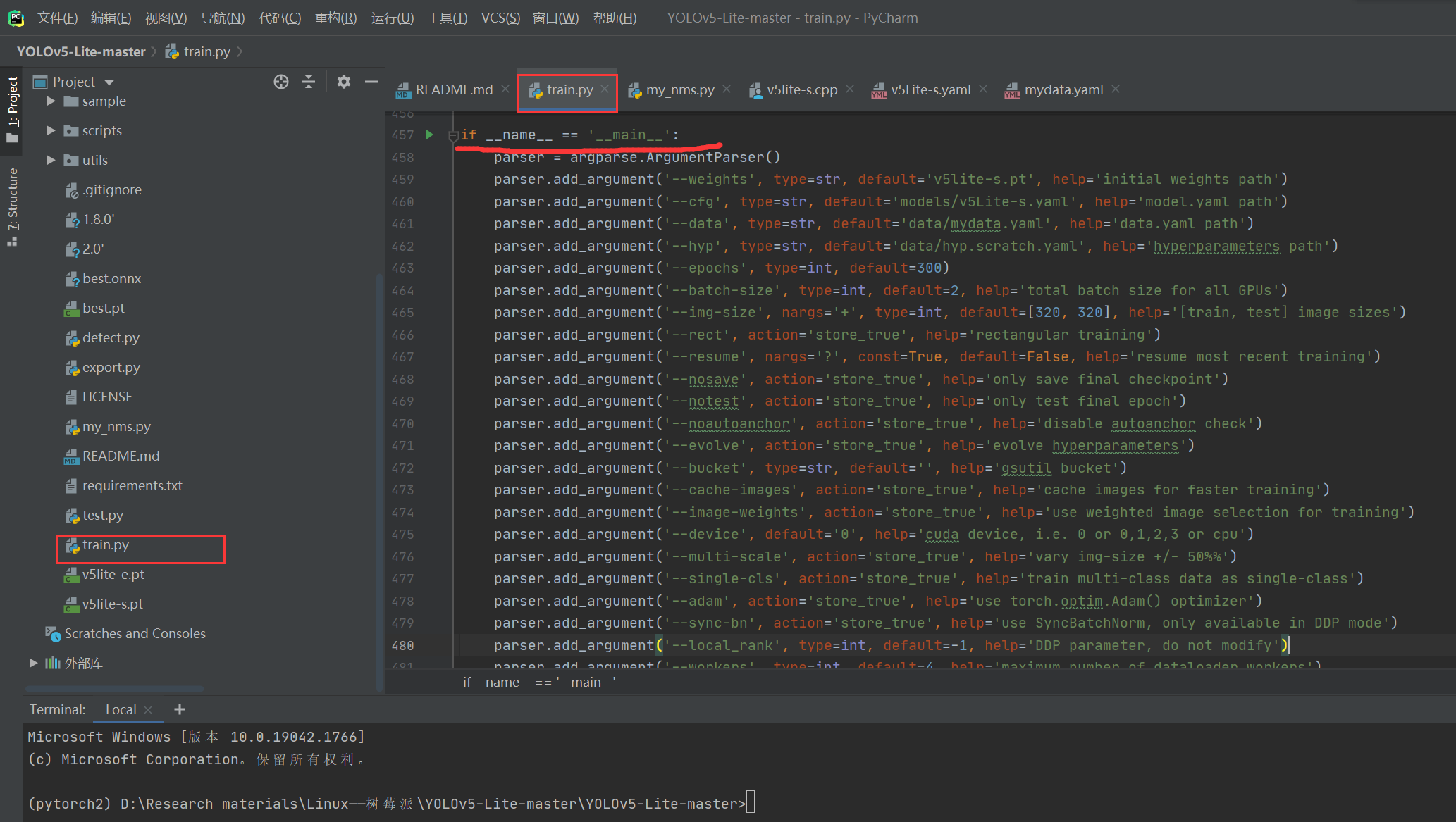
我们设置如下几个核心配置:
--weights v5lite-s.pt
--cfg models/v5Lite-s.yaml
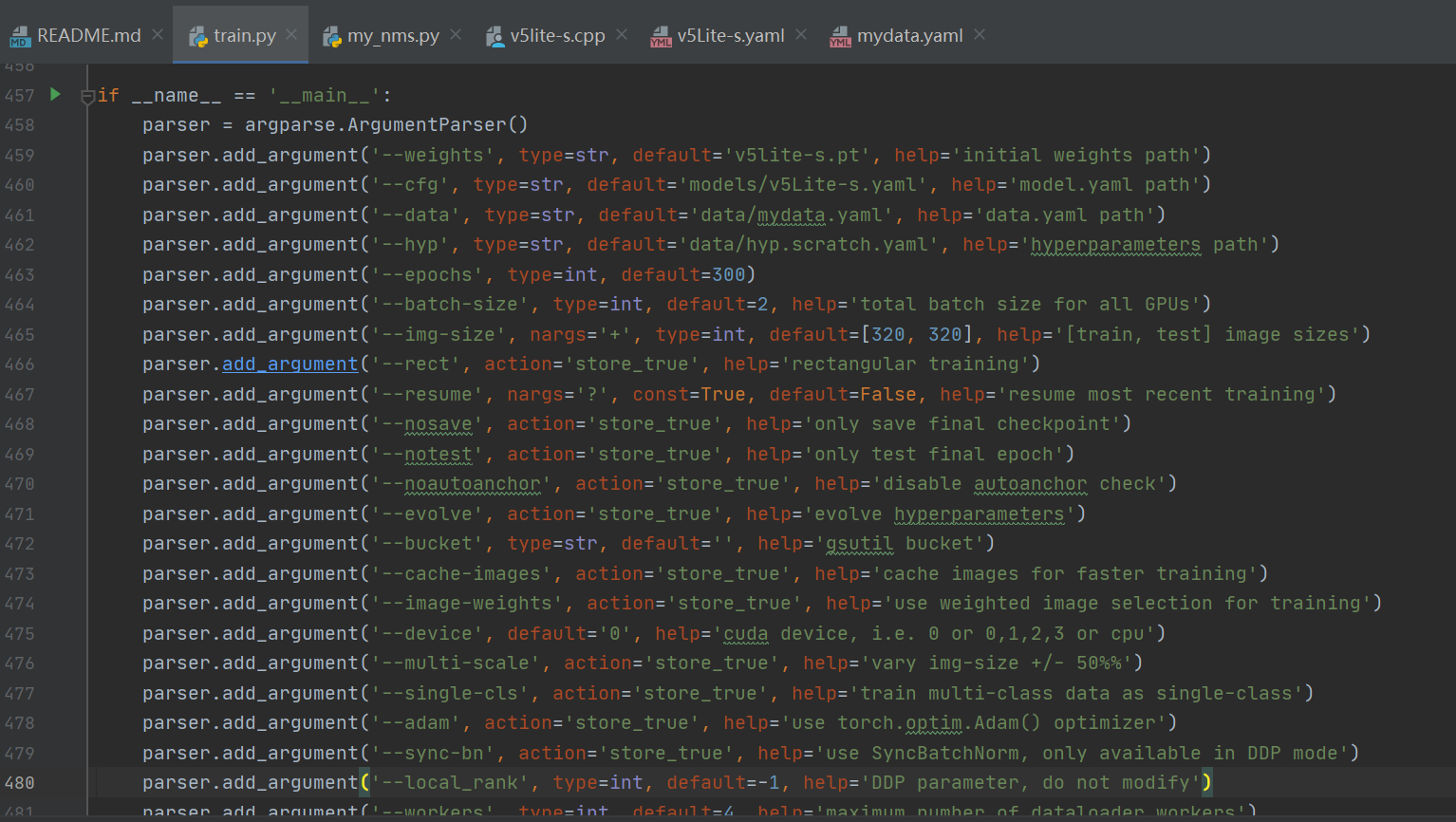
--data data/mydata.yaml
--img-size 320
--batch-size 16
--data data/mydata.yaml
device 0/cpu (可以不使用CUDA训练)
读者朋友一定要将数据集存放的地址位置搞正确!!!

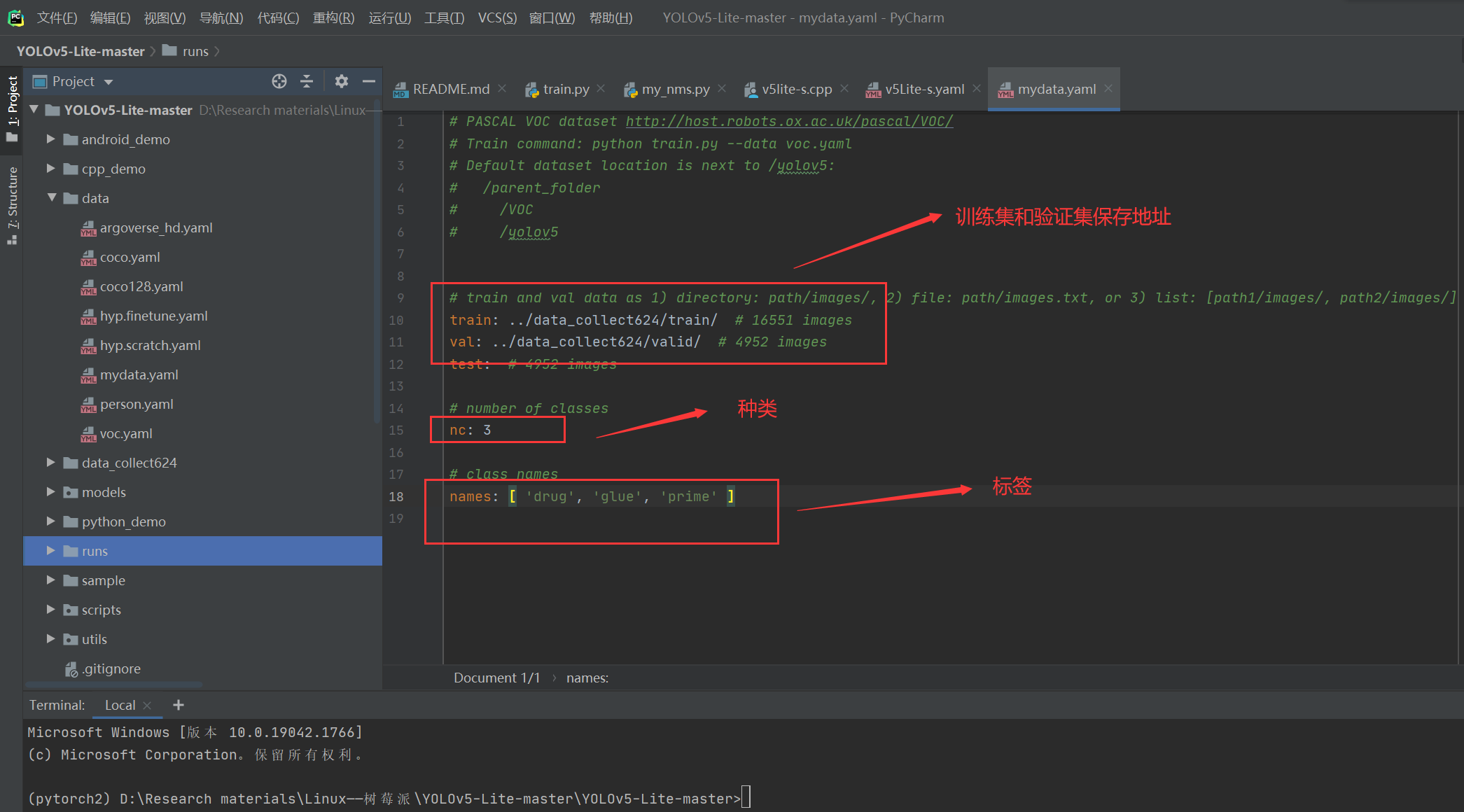
mydata.yaml:
Yolov5-Lite 网络模型的训练可以不一定必须使用 CUDA 进行加速,但是 pytorch 架构等依赖库一定需要满足,模型训练依赖要求如下:
# base ----------------------------------------
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
Pillow
PyYAML>=5.3.1
scipy>=1.4.1
torch>=1.8.0
torchvision>=0.9.0
tqdm>=4.41.0
# logging -------------------------------------
tensorboard>=2.4.1
# wandb
# plotting ------------------------------------
seaborn>=0.11.0
pandas
# export --------------------------------------
# coremltools>=4.1
# onnx>=1.9.1
# scikit-learn==0.19.2 # for coreml quantization
# extras --------------------------------------
thop # FLOPS computation
pycocotools>=2.0 # COCO mAP
将训练环境与数据集都搞定之后,就可以点击运行按钮进行 Yolov5-Lite 的模型训练了!
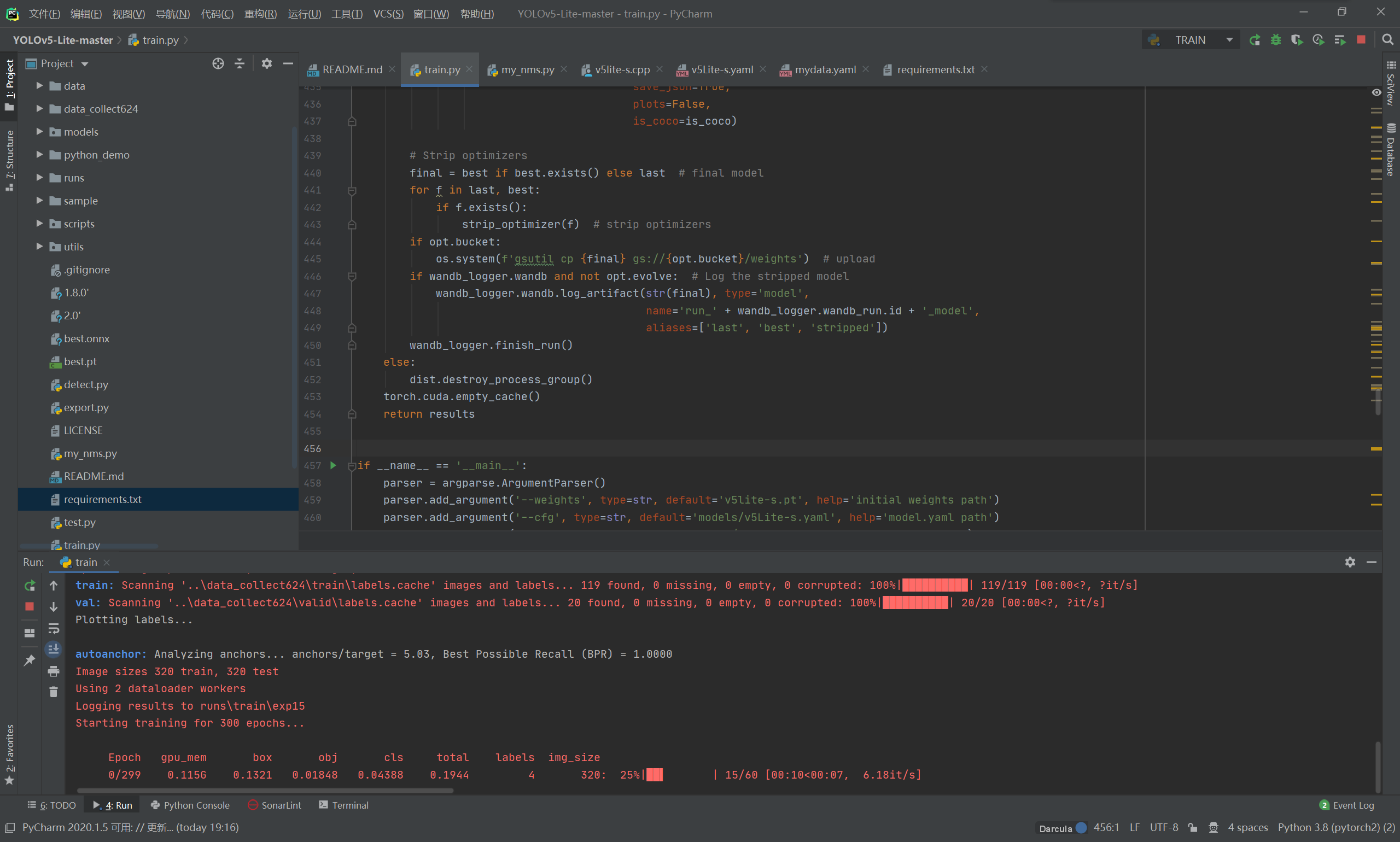
训练成功之后,将会在当前目录下的 run 文件下的 trian 文件下找到 expx (x代表数字),expx 则存放了第 x 次训练时候的各种数据内容,包括:历史最优权重best_weight,当前权重last_weight,训练结果result等等;

二、NCNN概述
NCNN 是一个针对移动平台优化的高性能神经网络推理框架,并在2017年7月正式开源。NCNN 是腾讯优图最“火”的开源项目之一,作为一个为手机端极致优化的高性能神经网络前向计算框架,在设计之初便将手机端的特殊场景融入核心理念,是业界首个为移动端优化的开源神经网络推断库。能实现无第三方依赖,跨平台操作,在手机端 cpu 运算速度在开源框架中处于领先水平。基于该平台,开发者能够轻松将深度学习算法移植到手机端,输出高效的执行,进而产出人工智能APP,将AI技术带到用户指尖。

支持大部分常用的 CNN 网络
Classical CNN: VGG AlexNet GoogleNet Inception ...Practical CNN: ResNet DenseNet SENet FPN ...Light-weight CNN: SqueezeNet MobileNetV1/V2/V3 ShuffleNetV1/V2 MNasNet ...Face Detection: MTCNN RetinaFace ...Detection: VGG-SSD MobileNet-SSD SqueezeNet-SSD MobileNetV2-SSDLite MobileNetV3-SSDLite ...Detection: Faster-RCNN R-FCN ...Detection: YOLOV2 YOLOV3 MobileNet-YOLOV3 YOLOV4 YOLOV5 ...Segmentation: FCN PSPNet UNet YOLACT ...Pose Estimation: SimplePose ...
官网地址:ncnn: ncnn ncnn 是腾讯优图实验室首个开源项目,是一个为手机端极致优化的高性能神经网络前向计算框架 (gitee.com)
三、树莓派4B的NCNN部署Lite模型
3.1 树莓派配置NCNN
1、安装依赖库;
sudo apt-get install git cmake
sudo apt-get install -y gfortran
sudo apt-get install -y libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler
sudo apt-get install --no-install-recommends libboost-all-dev
sudo apt-get install -y libgflags-dev libgoogle-glog-dev liblmdb-dev libatlas-base-dev
2、下载NCNN并编译;
$ git clone https://gitee.com/Tencent/ncnn.git
cd ncnn
mkdir build
cd build
cmake ..
make -j4
make install
完成后ncnn文件夹如下:

3.2 模型转换
如今的开源 YOLO 系列神经网络模型的目录下作者都会预留 export.py 文件将该神经网络模型进行转换到 ONNX 模型,方便大家实际情况下部署使用!

将我们训练好的最优训练权重 weights 存放到 YOLOv5-Lite 主目录下,之后运行如下代码:
python export.py --weights 'weights/last.pt' --batch-size 1 --img-size 320
使用 onnx-simplifier 对转换后的 onnx 进行简化:
pip install -U onnx-simplifier --user
python -m onnxsim best.onnx e.onnx

3.3 树莓派部署lite模型
1、将 ONNX 模型转换为 NCNN 模型
cd ncnn/build
./tools/onnx/onnx2ncnn e.onnx e.param e.bin
# 模型优化为fp16
./tools/onnxoptimize e.param e.bin eopt.param eopt.bin 65536

2、添加 YOLOv5-Lite.cpp代码
// Tencent is pleased to support the open source community by making ncnn available.
//
// Copyright (C) 2020 THL A29 Limited, a Tencent company. All rights reserved.
//
// Licensed under the BSD 3-Clause License (the "License"); you may not use this file except
// in compliance with the License. You may obtain a copy of the License at
//
// https://opensource.org/licenses/BSD-3-Clause
//
// Unless required by applicable law or agreed to in writing, software distributed
// under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
// CONDITIONS OF ANY KIND, either express or implied. See the License for the
// specific language governing permissions and limitations under the License.
#include "layer.h"
#include "net.h"
#if defined(USE_NCNN_SIMPLEOCV)
#include "simpleocv.h"
#else
#include
#include
#include
#endif
#include
#include
#include
#include
#include
#include
#include
using namespace std;
using namespace cv;
using namespace std::chrono;
// 0 : FP16
// 1 : INT8
#define USE_INT8 0
// 0 : Image
// 1 : Camera
#define USE_CAMERA 1
struct Object
{
cv::Rect_ rect;
int label;
float prob;
};
static inline float intersection_area(const Object& a, const Object& b)
{
cv::Rect_ inter = a.rect & b.rect;
return inter.area();
}
static void qsort_descent_inplace(std::vector& faceobjects, int left, int right)
{
int i = left;
int j = right;
float p = faceobjects[(left + right) / 2].prob;
while (i p)
i++;
while (faceobjects[j].prob < p)
j--;
if (i nms_threshold)
keep = 0;
}
if (keep)
picked.push_back(i);
}
}
static inline float sigmoid(float x)
{
return static_cast(1.f / (1.f + exp(-x)));
}
// unsigmoid
static inline float unsigmoid(float y) {
return static_cast(-1.0 * (log((1.0 / y) - 1.0)));
}
static void generate_proposals(const ncnn::Mat &anchors, int stride, const ncnn::Mat &in_pad,
const ncnn::Mat &feat_blob, float prob_threshold,
std::vector &objects) {
const int num_grid = feat_blob.h;
float unsig_pro = 0;
if (prob_threshold > 0.6)
unsig_pro = unsigmoid(prob_threshold);
int num_grid_x;
int num_grid_y;
if (in_pad.w > in_pad.h) {
num_grid_x = in_pad.w / stride;
num_grid_y = num_grid / num_grid_x;
} else {
num_grid_y = in_pad.h / stride;
num_grid_x = num_grid / num_grid_y;
}
const int num_class = feat_blob.w - 5;
const int num_anchors = anchors.w / 2;
for (int q = 0; q < num_anchors; q++) {
const float anchor_w = anchors[q * 2];
const float anchor_h = anchors[q * 2 + 1];
const ncnn::Mat feat = feat_blob.channel(q);
for (int i = 0; i < num_grid_y; i++) {
for (int j = 0; j < num_grid_x; j++) {
const float *featptr = feat.row(i * num_grid_x + j);
// find class index with max class score
int class_index = 0;
float class_score = -FLT_MAX;
float box_score = featptr[4];
if (prob_threshold > 0.6) {
// while prob_threshold > 0.6, unsigmoid better than sigmoid
if (box_score > unsig_pro) {
for (int k = 0; k < num_class; k++) {
float score = featptr[5 + k];
if (score > class_score) {
class_index = k;
class_score = score;
}
}
float confidence = sigmoid(box_score) * sigmoid(class_score);
if (confidence >= prob_threshold) {
float dx = sigmoid(featptr[0]);
float dy = sigmoid(featptr[1]);
float dw = sigmoid(featptr[2]);
float dh = sigmoid(featptr[3]);
float pb_cx = (dx * 2.f - 0.5f + j) * stride;
float pb_cy = (dy * 2.f - 0.5f + i) * stride;
float pb_w = pow(dw * 2.f, 2) * anchor_w;
float pb_h = pow(dh * 2.f, 2) * anchor_h;
float x0 = pb_cx - pb_w * 0.5f;
float y0 = pb_cy - pb_h * 0.5f;
float x1 = pb_cx + pb_w * 0.5f;
float y1 = pb_cy + pb_h * 0.5f;
Object obj;
obj.rect.x = x0;
obj.rect.y = y0;
obj.rect.width = x1 - x0;
obj.rect.height = y1 - y0;
obj.label = class_index;
obj.prob = confidence;
objects.push_back(obj);
}
} else {
for (int k = 0; k < num_class; k++) {
float score = featptr[5 + k];
if (score > class_score) {
class_index = k;
class_score = score;
}
}
float confidence = sigmoid(box_score) * sigmoid(class_score);
if (confidence >= prob_threshold) {
float dx = sigmoid(featptr[0]);
float dy = sigmoid(featptr[1]);
float dw = sigmoid(featptr[2]);
float dh = sigmoid(featptr[3]);
float pb_cx = (dx * 2.f - 0.5f + j) * stride;
float pb_cy = (dy * 2.f - 0.5f + i) * stride;
float pb_w = pow(dw * 2.f, 2) * anchor_w;
float pb_h = pow(dh * 2.f, 2) * anchor_h;
float x0 = pb_cx - pb_w * 0.5f;
float y0 = pb_cy - pb_h * 0.5f;
float x1 = pb_cx + pb_w * 0.5f;
float y1 = pb_cy + pb_h * 0.5f;
Object obj;
obj.rect.x = x0;
obj.rect.y = y0;
obj.rect.width = x1 - x0;
obj.rect.height = y1 - y0;
obj.label = class_index;
obj.prob = confidence;
objects.push_back(obj);
}
}
}
}
}
}
}
static int detect_yolov5(const cv::Mat& bgr, std::vector& objects)
{
ncnn::Net yolov5;
#if USE_INT8
yolov5.opt.use_int8_inference=true;
#else
yolov5.opt.use_vulkan_compute = true;
yolov5.opt.use_bf16_storage = true;
#endif
// original pretrained model from https://github.com/ultralytics/yolov5
// the ncnn model https://github.com/nihui/ncnn-assets/tree/master/models
#if USE_INT8
yolov5.load_param("/home/pi/ncnn/build/e.param");
yolov5.load_model("/home/pi/ncnn/build/e.bin");
#else
yolov5.load_param("/home/pi/ncnn/build/eopt.param");
yolov5.load_model("/home/pi/ncnn/build/eopt.bin");
#endif
const int target_size = 320;
const float prob_threshold = 0.60f;
const float nms_threshold = 0.60f;
int img_w = bgr.cols;
int img_h = bgr.rows;
// letterbox pad to multiple of 32
int w = img_w;
int h = img_h;
float scale = 1.f;
if (w > h)
{
scale = (float)target_size / w;
w = target_size;
h = h * scale;
}
else
{
scale = (float)target_size / h;
h = target_size;
w = w * scale;
}
ncnn::Mat in = ncnn::Mat::from_pixels_resize(bgr.data, ncnn::Mat::PIXEL_BGR2RGB, img_w, img_h, w, h);
// pad to target_size rectangle
// yolov5/utils/datasets.py letterbox
int wpad = (w + 31) / 32 * 32 - w;
int hpad = (h + 31) / 32 * 32 - h;
ncnn::Mat in_pad;
ncnn::copy_make_border(in, in_pad, hpad / 2, hpad - hpad / 2, wpad / 2, wpad - wpad / 2, ncnn::BORDER_CONSTANT, 114.f);
const float norm_vals[3] = {1 / 255.f, 1 / 255.f, 1 / 255.f};
in_pad.substract_mean_normalize(0, norm_vals);
ncnn::Extractor ex = yolov5.create_extractor();
ex.input("images", in_pad);
std::vector proposals;
// stride 8
{
ncnn::Mat out;
ex.extract("onnx::Sigmoid_647", out);
ncnn::Mat anchors(6);
anchors[0] = 10.f;
anchors[1] = 13.f;
anchors[2] = 16.f;
anchors[3] = 30.f;
anchors[4] = 33.f;
anchors[5] = 23.f;
std::vector objects8;
generate_proposals(anchors, 8, in_pad, out, prob_threshold, objects8);
proposals.insert(proposals.end(), objects8.begin(), objects8.end());
}
// stride 16
{
ncnn::Mat out;
ex.extract("onnx::Sigmoid_669", out);
ncnn::Mat anchors(6);
anchors[0] = 30.f;
anchors[1] = 61.f;
anchors[2] = 62.f;
anchors[3] = 45.f;
anchors[4] = 59.f;
anchors[5] = 119.f;
std::vector objects16;
generate_proposals(anchors, 16, in_pad, out, prob_threshold, objects16);
proposals.insert(proposals.end(), objects16.begin(), objects16.end());
}
// stride 32
{
ncnn::Mat out;
ex.extract("onnx::Sigmoid_691", out);
ncnn::Mat anchors(6);
anchors[0] = 116.f;
anchors[1] = 90.f;
anchors[2] = 156.f;
anchors[3] = 198.f;
anchors[4] = 373.f;
anchors[5] = 326.f;
std::vector objects32;
generate_proposals(anchors, 32, in_pad, out, prob_threshold, objects32);
proposals.insert(proposals.end(), objects32.begin(), objects32.end());
}
// sort all proposals by score from highest to lowest
qsort_descent_inplace(proposals);
// apply nms with nms_threshold
std::vector picked;
nms_sorted_bboxes(proposals, picked, nms_threshold);
int count = picked.size();
objects.resize(count);
for (int i = 0; i < count; i++)
{
objects[i] = proposals[picked[i]];
// adjust offset to original unpadded
float x0 = (objects[i].rect.x - (wpad / 2)) / scale;
float y0 = (objects[i].rect.y - (hpad / 2)) / scale;
float x1 = (objects[i].rect.x + objects[i].rect.width - (wpad / 2)) / scale;
float y1 = (objects[i].rect.y + objects[i].rect.height - (hpad / 2)) / scale;
// clip
x0 = std::max(std::min(x0, (float)(img_w - 1)), 0.f);
y0 = std::max(std::min(y0, (float)(img_h - 1)), 0.f);
x1 = std::max(std::min(x1, (float)(img_w - 1)), 0.f);
y1 = std::max(std::min(y1, (float)(img_h - 1)), 0.f);
objects[i].rect.x = x0;
objects[i].rect.y = y0;
objects[i].rect.width = x1 - x0;
objects[i].rect.height = y1 - y0;
}
return 0;
}
static void draw_objects(const cv::Mat& bgr, const std::vector& objects)
{
static const char* class_names[] = {
"drug","glue","prime"
};
cv::Mat image = bgr.clone();
for (size_t i = 0; i < objects.size(); i++)
{
const Object& obj = objects[i];
fprintf(stderr, "%d = %.5f at %.2f %.2f %.2f x %.2f\n", obj.label, obj.prob,
obj.rect.x, obj.rect.y, obj.rect.width, obj.rect.height);
cv::rectangle(image, obj.rect, cv::Scalar(0, 255, 0));
char text[256];
sprintf(text, "%s %.1f%%", class_names[obj.label], obj.prob * 100);
int baseLine = 0;
cv::Size label_size = cv::getTextSize(text, cv::FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
int x = obj.rect.x;
int y = obj.rect.y - label_size.height - baseLine;
if (y < 0)
y = 0;
if (x + label_size.width > image.cols)
x = image.cols - label_size.width;
cv::rectangle(image, cv::Rect(cv::Point(x, y), cv::Size(label_size.width, label_size.height + baseLine)),
cv::Scalar(255, 255, 255), -1);
cv::putText(image, text, cv::Point(x, y + label_size.height),
cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 0, 0));
// cv::putText(image, to_string(fps), cv::Point(100, 100), //FPS
//cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 0, 0));
}
#if USE_CAMERA
imshow("camera", image);
cv::waitKey(1);
#else
cv::imwrite("result.jpg", image);
#endif
}
#if USE_CAMERA
int main(int argc, char** argv)
{
cv::VideoCapture capture;
capture.open(0); //修改这个参数可以选择打开想要用的摄像头
cv::Mat frame;
//111
int FPS = 0;
int total_frames = 0;
high_resolution_clock::time_point t1, t2;
while (true)
{
capture >> frame;
cv::Mat m = frame;
cv::Mat f = frame;
std::vector objects;
auto start_time = std::chrono::high_resolution_clock::now(); // 记录开始时间
detect_yolov5(frame, objects);
auto end_time = std::chrono::high_resolution_clock::now(); // 记录结束时间
auto duration = std::chrono::duration_cast(end_time - start_time); // 计算执行时间
float fps = (float)(1000)/duration.count();
draw_objects(m, objects);
cout |