爬取医药卫生知识服务系统的药品数据 |
您所在的位置:网站首页 › 药品销售流程图片大全大图 › 爬取医药卫生知识服务系统的药品数据 |
爬取医药卫生知识服务系统的药品数据
|
爬取医药卫生知识服务系统的药品数据——超详细流程
文章目录
爬取医药卫生知识服务系统的药品数据——超详细流程前言一、寻找药品数据二、爬取药品ID1.资源获取2.数据提取3.资源保存4.主函数5.总体代码
三、爬取药品信息1.加载资源ID2.获取数据3.数据提取4.保存信息5.主函数6.总体代码
小结
前言
最近,实验室的项目需要用到医药卫生知识服务系统的药品数据,查看发现该网站上的数据不少,手动采集数据比较麻烦,考虑使用网络爬虫,交由我来进行分析和爬取。 在我爬取药品数据的时候,发现该系统的数据是通过 AJAX 动态加载的,直接无脑复制 URL 使用 request.get 爬取的简单方式是行不通的。于是我爬取完之后写下这篇博客作为一个记录,也方便后来者进行学习。 医药卫生知识服务系统的网址是 https://med.ckcest.cn/
请大家在这一步记住目录页和详情页是怎么找到的,之后的步骤中会直接提及这两个概念。 一、寻找药品数据每一个药品都用了单独的标签页进行展示,那么每一个药品都会对应一个链接来获取数据,因此我们找到这些 URL 的规律就可以爬取了。 我们点开第一个药品 氨己烯酸 和第二个药品 奥卡西平的详情页,在浏览器的地址栏中观察两个药品的URL: https://med.ckcest.cn/details.html?id=5005884384970756&classesEn=wiki&searchValue= https://med.ckcest.cn/details.html?id=5005884384954370&classesEn=wiki&searchValue=我们发现,URL仅在 id 部分发生了变化,其余完全相同。这意味着 id 即为每个药品数据的标识,我们只需要找到每个药品的 id ,对 URL 进行拼接就可以对应获取到单个药品数据了。 因此,我们只需要拿到所有药品的 id 信息,然后遍历每一条 id ,就能依次拿到所有药品的数据了。那么药品的 id 信息又从哪拿呢,我们可以通过药品目录页进行爬取。 接下来是具体的找 id 的步骤,这里我使用的是谷歌浏览器。注意,找数据是编写爬虫最关键的部分,这非常重要。 第一步,用谷歌浏览器进入药品目录页
通过 response 的对比发现,queryDetail.do 是单个药品的数据信息,而 searchList.do 是这一页十条药品的数据汇集信息。很明显,我们需要的是所有药品的 id,所以我们应当去分析 searchList.do 。 第五步,点击 searchList.do,在右侧中查看其 Header
这一步是为了熟悉对应数据的 JSON 结构,方便之后的编码工作进行数据的提取。如果使用熟练的话则可以跳过此步。
我们已经找到了药品 id 对应的链接,并且查看了对应数据的 JSON 格式,下面对药品 ID 进行爬取。 简单分为以下几个函数进行编写: 资源获取函数 getTotal()数据提取函数 findTotal()资源保存函数 saveTotal()主函数 main() 1.资源获取这里使用 request.get()方法进行资源获取,有两个注意事项: 准备多个用户代理 UA 来随机选取每爬取一次页面沉睡一些时间这两点的作用都是模拟用户的操作,更好地避免爬取过快导致爬虫被识别。同时,使用 try-except 结构也能更好地捕捉异常情况。 Tips:如果报异常的话,可以考虑 time.sleep() 多沉睡一点时间,例如 5 秒 getTotal()函数有一个参数,就是需要资源获取的 URL # 设置代理 UA = ["Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1" ] # 获取url资源 def getTotal(url): this_ua = random.choice(UA) # 随机选用使用代理 headers = { 'User-Agent': this_ua } params = { 'enc': 'utf-8', } try: r = requests.get(url=url, params=params, headers=headers) # 链接url time.sleep(1) # 沉睡1秒,避免爬取过快 r.raise_for_status() # 判断异常 r.encoding = r.apparent_encoding # 转码 # print(r.json()) return r.json() # 返回json文件 except HTTPError as e: # 异常提示 print('总页面链接异常!!!') print('总页面链接异常!!!') print('总页面链接异常!!!') print(e) return ''getTotal() 函数结束后会返回一个 json 文件,这个就是十条药品数据信息汇总的 json 文件。这里我给出第一条做个大概的示意 [ { showList: [ "wiki;title", "wiki;abstracts", "wiki;keywords", "wiki;drug_category" ], search: { data: [ { title: [ "氨己烯酸" ], abstracts: [ "常用于癫痫部分性发作,也可与其他抗癫痫药合用治疗难治性癫痫。还可用于儿童Lennox-Gastaut综合征和West综合征(婴儿痉挛症)。对癫痫小发作、肌阵挛发作效果欠佳。 " ], keywords: [ "婴儿痉挛", "发作", "肌阵挛", "癫痫" ], drug_category: [ "神经系统用药" ], classEn: [ "wiki" ], create_time: [ { date: 10, day: 5, hours: 16, minutes: 31, month: 6, seconds: 50, time: 1594369910000, timezoneOffset: -480, year: 120 } ], classZh: [ "百科" ], id: [ "5005884384970756" ] }, ] } } ] 2.数据提取数据提取时这里有一个需要注意的点,不是所有的数据都是药品数据。例如在药品目录页的第三页,第22条是鼻出血、第23条是病毒性肺炎,它们都不是我们所要的药品信息,对于这些非药品可以直接忽略。 于是,我去仔细对比了药品与非药品的 JSON 数据。通过对比发现,药品的数据中会有 drug_category 这个属性,而非药品是没有的。因此,我选择使用 drug_category 属性来鉴别药品。 我们使用 findTotal()函数来进行数据处理,该函数有两个参数,一个是待处理的 json 文件,一个是用于保存药品 id 信息的列表 # 获取总体页面下各个药的ID def findTotal(json, IdList): yaopinTotal = json[0]['search']['data'] # 定位药品总列表 for yaopin in yaopinTotal: # drug_category存在的才是药物,存入其ID if ('drug_category' in yaopin and len(yaopin['drug_category']) > 0): yaopinId = yaopin['id'][0] IdList.append(yaopinId) else: # 不存在的则不是药物,跳过即可 continue 3.资源保存所有的药品 id 信息提取完成之后,我们将其保存到文件中。为了方便查找,这里我将其保存在代码的同级目录下 saveTotal()函数进行文件的保存,该函数有一个参数,就是保存药品 id 信息的列表 # 保存资源 def saveTotal(IdList): path = './' file_name = "药品ID.csv" # 写入数据 with open(path + file_name, 'w+', newline='') as f: writer = csv.writer(f) writer.writerow(['ID']) # 写入文件的表头 for u in range(len(IdList)): writer.writerow([IdList[u]]) # 一次写入一行信息 4.主函数目录页有三种方式,分别展示十条、二十条、三十条。
总体代码如下: #coding=utf-8 import requests import csv import random import time from urllib.error import HTTPError # 设置代理 UA = ["Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1" ] # 获取url资源 def getTotal(url): this_ua = random.choice(UA) # 随机选用使用代理 headers = { 'User-Agent': this_ua } params = { 'enc': 'utf-8', } try: r = requests.get(url=url, params=params, headers=headers) # 链接url time.sleep(1) # 沉睡1秒,避免爬取过快 r.raise_for_status() # 判断异常 r.encoding = r.apparent_encoding # 转码 # print(r.json()) return r.json() # 返回json文件 except HTTPError as e: # 异常提示 print('总页面链接异常!!!') print('总页面链接异常!!!') print('总页面链接异常!!!') print(e) return '' # 获取总体页面下各个药的ID def findTotal(json, IdList): yaopinTotal = json[0]['search']['data'] # 定位药品总列表 for yaopin in yaopinTotal: # drug_category存在的才是药物,存入其ID if ('drug_category' in yaopin and len(yaopin['drug_category']) > 0): yaopinId = yaopin['id'][0] IdList.append(yaopinId) else: # 不存在的则不是药物,跳过即可 continue # 保存资源 def saveTotal(IdList): path = './' file_name = "药品ID.csv" # 写入数据 with open(path + file_name, 'w+', newline='') as f: writer = csv.writer(f) writer.writerow(['ID']) # 写入文件的表头 for u in range(len(IdList)): writer.writerow([IdList[u]]) # 一次写入一行信息 if __name__ == '__main__': print("--------------------爬取开始--------------------") page = 1 # 控制页数和每页个数 nums = 30 IdList = [] # 所有的ID结果存放 # # 每页展示10条,一共214页。若每页展示30条,一共72页 for i in range(1, 73): if(i%10 == 0): # 提示信息 print("正在爬取第%d页" % i) # 构造ID的URL urlId = 'https://med.ckcest.cn/searchList.do?' \ 'page=' + str(i) + '' \ '&classen=wiki&searchText=&searchText2=&sort=have_' \ 'abstracts+asc%3Bknowledge_map+desc%3Bwiki_first_letter+asc&' \ 'pageNumber=' + str(nums) + '' \ '&userId=' jsonTotal = getTotal(urlId) # 爬取页面 findTotal(jsonTotal, IdList) # 存入ID saveTotal(IdList) # 保存至文件 print("--------------------爬取结束--------------------")程序运行大概需要几分钟的时间,爬取完成的程序输出:
保存到的 药品ID.csv 文件如下图所示:
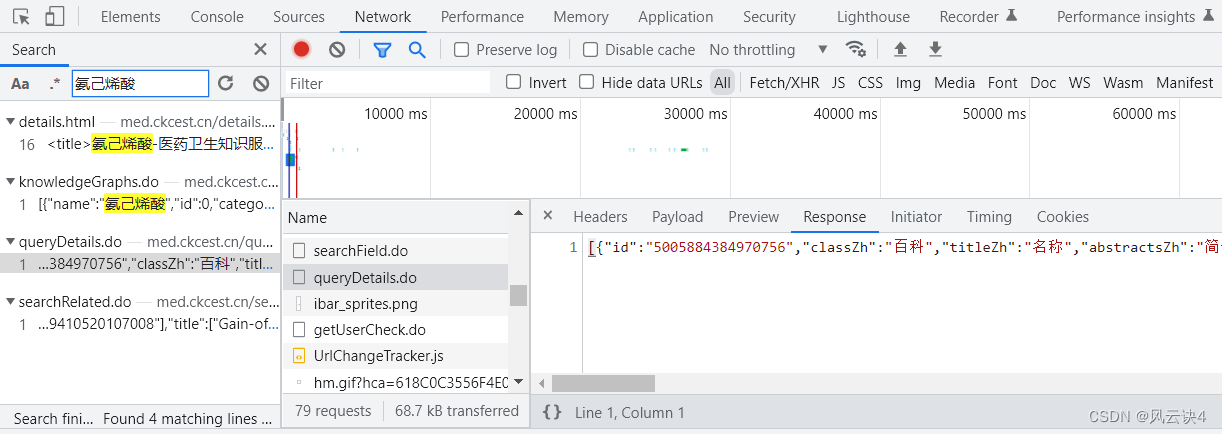
有了药品 id 之后,我们就可以爬取每个药品具体的数据了。 还是以第一个药品 氨己烯酸 为例,我们去寻找它的数据,操作方法与本博客的第一节 一、寻找药品数据 完全一模一样。 具体流程:在 氨己烯酸 的详情页,点击 F12,找到 Network,刷新加载数据后,搜索关键字 “氨己烯酸”。依次对比后发现 queryDetail.do 的 response 才与详情页的数据相匹配。
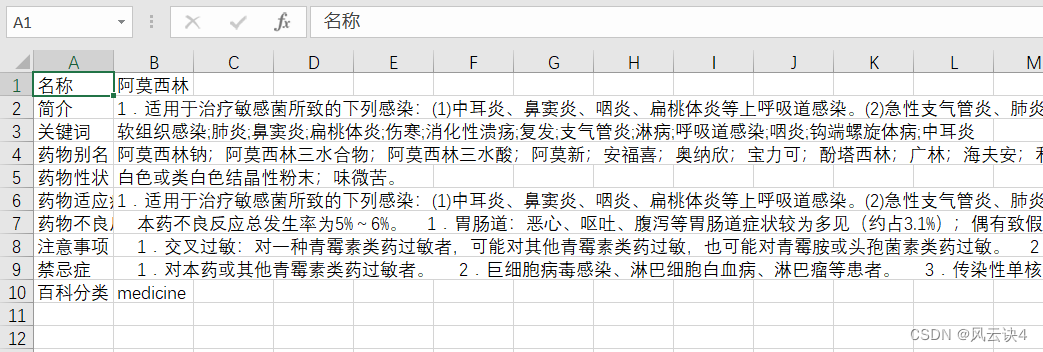
这里大概分为五个函数: 加载资源ID readerID()获取数据 getJson()数据提取 findJson()保存信息 saveMedicine()主函数 main() 1.加载资源ID药品ID.csv 是上一个爬虫程序爬取的关于所有药品 id 信息的文件,就放在同级目录下。 readerID()函数有一个参数,传入一个空列表,将 id 读取之后存入列表中 # 加载ID资源 def readerId(idList): path = './' file_name = "药品ID.csv" # 打开csv文件 with open(path + file_name, 'r', newline='') as f: reader = csv.reader(f) headers = next(reader) # 读取表头 for row in reader: # 循环获取表头之后的每一行 idList.append(row[0]) # 取第一列 2.获取数据写法与之前几乎没有区别,只是改成了 post 方法,需要定义 data 来传递参数。 getJson()函数有一个参数,接受传入的药品 id ,作为 post 的参数。 # 设置代理 UA = ["Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1" ] # 获取url请求 def getJson(medicineID): url = 'https://med.ckcest.cn/queryDetails.do' this_ua = random.choice(UA) # 随机选用使用代理 headers = { 'User-Agent': this_ua } # 关键参数 data = { 'id': medicineID, 'nameEn': 'wiki' } params = { 'enc': 'utf-8', } try: r = requests.post(url=url, data=data, params=params, headers=headers) # 链接url time.sleep(1) # 避免爬取过快 r.raise_for_status() # 判断异常 r.encoding = r.apparent_encoding # 转码 # print(r.json()) return r.json() # 返回json文件 except HTTPError as e: # 异常提示 print('链接异常!!!') print('链接异常!!!') print('链接异常!!!') print(e) return '' 3.数据提取数据提取这部分比较麻烦,因为它存在两个问题。 第一是每个药品数据属性不统一的问题。每条数据从 “keys” 属性大概分为头部和尾部两部分。在数据的头部,每一个药品从 titleZh 到 speciesZh 一共有固定的 14 个中文属性;但是在数据的尾部,有具体值的属性大概在5——10个不等。例如氨己烯酸一共有 8 个有具体值的属性,而 氨力农 却有 10 个属性有值。 以下是氨己烯酸的详细数据: [ { id: "5005884384970756", classZh: "百科", titleZh: "名称", abstractsZh: "简介", symptomsZh: "症状", diagnosisZh: "诊断", treatmentZh: "治疗", checksZh: "检查", keywordsZh: "关键词", drug_aliasesZh: "药物别名", drug_propertiesZh: "药物性状", drug_indicationsZh: "药物适应症", adverse_drug_reactionsZh: "药物不良反应", matters_needing_attentionZh: "注意事项", contraindicationZh: "禁忌症", speciesZh: "百科分类", keys: [ "title", "abstracts", "symptoms", "diagnosis", "treatment", "checks", "keywords", "drug_aliases", "drug_properties", "drug_indications", "adverse_drug_reactions", "matters_needing_attention", "contraindication", "species", "classZh" ], title: "氨己烯酸", abstracts: "常用于癫痫部分性发作,也可与其他抗癫痫药合用治疗难治性癫痫。还可用于儿童Lennox-Gastaut综合征和West综合征(婴儿痉挛症)。对癫痫小发作、肌阵挛发作效果欠佳。 ", keywords: "婴儿痉挛;发作;肌阵挛;癫痫", drug_aliases: "思波平;喜保宁;Gamma-vinyl;aminobutyric;acid;Sabril;Sabrilex;Vigabatrinum;Vinylaminobutyricacid; ", drug_indications: "常用于癫痫部分性发作,也可与其他抗癫痫药合用治疗难治性癫痫。还可用于儿童Lennox-Gastaut综合征和West综合征(婴儿痉挛症)。对癫痫小发作、肌阵挛发作效果欠佳。 ", adverse_drug_reactions: " 1.可见嗜睡、头晕、头痛、疲乏、体重增加、易激惹、神经质等。 2.当本药用于代替其他抗癫痫药时应逐渐增量。联合用药时亦应逐渐增加剂量,以达到所需的血药浓度。当与静脉注射用地西泮合用时,本药初次剂量可以较大,以迅速达到有效治疗浓度。 3.当成人剂量超过一日1.5g,6岁以下儿童剂量超过1g时,应密切注意毒性反应。 4.急性过量产生中枢抑制症状,包括呼吸抑制、昏迷。 5.用药过量的处理:包括催吐(除非患者很快得到缓解或处于昏睡、痉挛状态)、洗胃、活性炭吸附、导泻以及常规支持治疗。必要时可使用血液透析。", matters_needing_attention: " 1.慎用:肾功能不全者。 2.药物对老人的影响:老年患者慎用本药。 3.药物对妊娠的影响:大剂量时在动物实验中观察到胎仔畸形,孕妇不宜使用。 4.药物对哺乳的影响:哺乳妇女不宜使用本药。 5.用药前后及用药时:应当检查或监测长期服用本药的患者,应每6个月做1次眼科检查(尤其是视野检查)。", species: "medicine", fileServer: "https://med.ckcest.cn/attachments_la/" } ]针对这种情况,我的做法是,依次从数据头部取出 14 个属性的英文名,然后按英文名对比是否有值。因为 JSON 数据是键值对的形式,很好地支持了这种对比。 例如,titleZh 是“名称” 属性,我把最后两个字母 Zh 去掉,剩下 title,查找 title 键是否有值。如果该属性比对有值,则记录;如果结果是 None,则证明该属性没有具体值,直接跳过。 第二个问题是某些属性值存在 这样的 html 标签,以及 \r\n 换行符。 关于 标签,我考虑使用正则表达式进行去除,将该标签全部替换为空值。 # 这是一个示例 value = "1.可见嗜睡、头晕、头痛、疲乏、体重增加、易激惹、神经质等。 " regex = r'' # 正则检索 p 标签 value = re.sub(regex, "", value, re.I) # sub函数替换p标签为空,re.I不区分大小写至于\r\n 换行符,使用自带的 replace 函数将其替换为空值即可。不过这里有个小细节,\r\n这种连在一起的换行符,必须要连写在一起才能生效 # 有效写法 value= value.replace('\r', '').replace('\n', '') # 无效写法 value = value.replace('\r', '') value = value.replace('\n', '')最后我使用了两个列表,第一个列表存入中文属性名,第二个列表存入对应属性值,最后把两个列表都统一存入一个新列表中,进行数据传递。 findJson()函数有两个参数,第一个参数是待处理的 Json 文件,第二个参数是传递数据的统一列表。 # 处理json def findJson(pageJson, medicineInfo): data = pageJson[0] # 获取列表中的键值对对象 keysTmp = list(data.keys()) # 转化为列表方便操作 keysTmp = keysTmp[2:] # 去除最前面的两个键,id和class realKeys = [] # 保存键 realValues = [] # 保存值 for key in keysTmp: if (key.__eq__("keys")): # 只取keys之前的做匹配 break key2 = key[:-2] # 去除最后两个字母Zh 再进行匹配 valueRaw = data.get(key2) if (not valueRaw is None): # 如果找得到值,证明value存在,加入 # 此步进行数据清洗,去除p标签,\r\n regex = r'' # 正则检索 p 标签 value = re.sub(regex, "", valueRaw.replace('\r', '').replace('\n', ''), re.I) # sub函数替换p标签为空,re.I不区分大小写 # 数据加入key-value队列 realKeys.append(data.get(key)) realValues.append(value) # 保存药品的键值对列表信息 medicineInfo.append(realKeys) medicineInfo.append(realValues) 4.保存信息写法与之前基本一样,文件名由具体的药品名称来命名,保存在同级目录下 这里我选择的是第一列写入属性名,第二列写入属性值。(当然也可以按照自己的需求来进行更改) saveMedicine()函数有一个参数,即 findJson 函数处理好的数据列表 # 保存药品信息 def saveMedicine(medicineInfo): path = './' file_name = medicineInfo[1][0] + ".csv" # 写入数据 with open(path + file_name, 'w+', newline='') as f: # newline=''保证逐行写入 writer = csv.writer(f) for u in range(len(medicineInfo[0])): writer.writerow([medicineInfo[0][u], medicineInfo[1][u]]) # 一次写入一行信息效果大概是这个样子
主函数的写法与之前也基本一样。因为每个药品要生成一个文件,所以把保存数据写在了循环里面 if __name__ == '__main__': print("--------------------爬取开始--------------------") idList = [] readerId(idList) for i in range(len(idList)): # 每一个ID都是页面 if (i % 10 == 0): # 提示信息 print("正在爬取第%d页" % i) pageJson = getJson(idList[i]) # print(pageJson) medicineInfo = [] # 药品信息 findJson(pageJson, medicineInfo) # 提取药品信息 saveMedicine(medicineInfo) # 药品保存到文件 print("--------------------爬取结束--------------------") 6.总体代码总体代码如下: #coding=utf-8 import os import requests import csv import re import random import time from urllib.error import HTTPError # 设置代理 UA = ["Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1" ] # 获取url请求 def getJson(medicineID): url = 'https://med.ckcest.cn/queryDetails.do' this_ua = random.choice(UA) # 随机选用使用代理 headers = { 'User-Agent': this_ua } # 关键参数 data = { 'id': medicineID, 'nameEn': 'wiki' } params = { 'enc': 'utf-8', } try: r = requests.post(url=url, data=data, params=params, headers=headers) # 链接url time.sleep(1) # 避免爬取过快 r.raise_for_status() # 判断异常 r.encoding = r.apparent_encoding # 转码 # print(r.json()) return r.json() # 返回json文件 except HTTPError as e: # 异常提示 print('链接异常!!!') print('链接异常!!!') print('链接异常!!!') print(e) return '' # 处理json def findJson(pageJson, medicineInfo): data = pageJson[0] # 获取列表中的键值对对象 keysTmp = list(data.keys()) # 转化为列表方便操作 keysTmp = keysTmp[2:] # 去除最前面的两个键,id和class realKeys = [] # 保存键 realValues = [] # 保存值 for key in keysTmp: if (key.__eq__("keys")): # 只取keys之前的做匹配 break key2 = key[:-2] # 去除最后两个字母Zh 再进行匹配 valueRaw = data.get(key2) if (not valueRaw is None): # 如果找得到值,证明value存在,加入 # 此步进行数据清洗,去除p标签,\r\n regex = r'' # 正则检索 p 标签 value = re.sub(regex, "", valueRaw.replace('\r', '').replace('\n', ''), re.I) # sub函数替换p标签为空,re.I不区分大小写 # 数据加入key-value队列 realKeys.append(data.get(key)) realValues.append(value) # 保存药品的键值对列表信息 medicineInfo.append(realKeys) medicineInfo.append(realValues) # 加载ID资源 def readerId(idList): path = './' file_name = "药品ID.csv" # 打开csv文件 with open(path + file_name, 'r', newline='') as f: reader = csv.reader(f) headers = next(reader) # 读取表头 for row in reader: # 循环获取表头之后的每一行 idList.append(row[0]) # 取第一列 # 保存药品信息 def saveMedicine(medicineInfo): path = './' file_name = medicineInfo[1][0] + ".csv" # 写入数据 with open(path + file_name, 'w+', newline='') as f: # newline=''保证逐行写入 writer = csv.writer(f) for u in range(len(medicineInfo[0])): writer.writerow([medicineInfo[0][u], medicineInfo[1][u]]) # 一次写入一行信息 if __name__ == '__main__': print("--------------------爬取开始--------------------") idList = [] readerId(idList) for i in range(len(idList)): # 每一个ID都是页面 if (i % 10 == 0): # 提示信息 print("正在爬取第%d页" % i) pageJson = getJson(idList[i]) # print(pageJson) medicineInfo = [] # 药品信息 findJson(pageJson, medicineInfo) # 提取药品信息 saveMedicine(medicineInfo) # 药品保存到文件 print("--------------------爬取结束--------------------")因为每一页都要进行文件写入,所以程序运行时间会比较长,大概需要十分钟。爬取完成的程序输出:
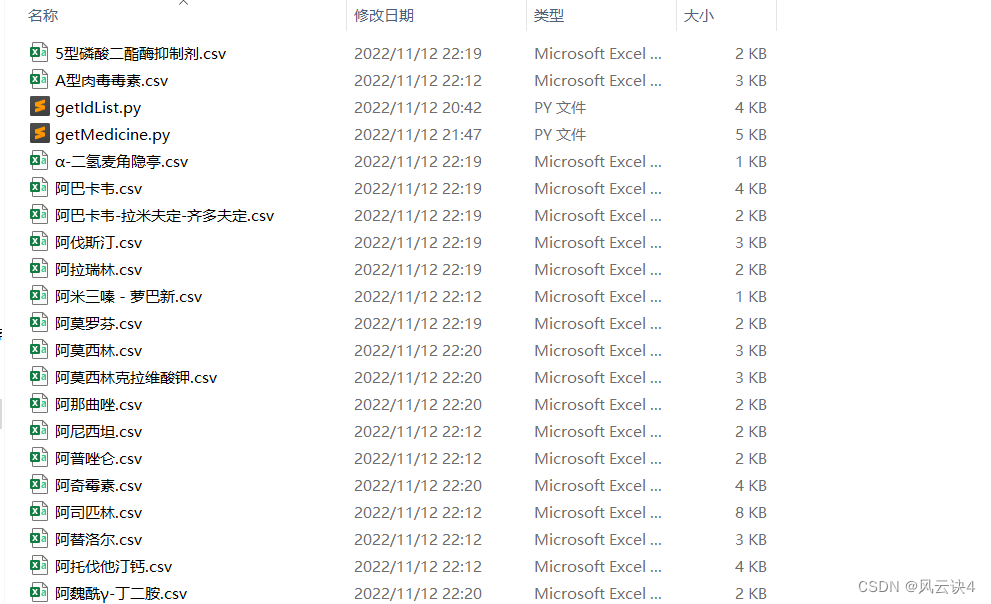
最终写入的文件如下:
要写好一个爬虫进行数据的爬取,还是挺劳心费神。 必须得对网页的数据加载方式有一个清晰的认知,对于JSON数据的传递链接有合理的分析。抓取到数据之后,要想方法筛选提炼数据,还要按自己所需要的格式进行清洗。 我在提取药品详细数据时,所使用的键值对的对比方法,也不见得是很好的,它只是我个人想到的一个可以完成当前任务的方法。大家也可以再想想别的办法来处理数据,很可能就比我这个更好。 拥有良好的编程基础,加上清晰的分析方法,才能有效地完成任务。 |
 我们点击右上方的 资源导航 -> 医药百科,进入药品目录页
我们点击右上方的 资源导航 -> 医药百科,进入药品目录页 可以看到这些药品数据都是我们需要的,网站进行了分页展示,每一页展示十条
可以看到这些药品数据都是我们需要的,网站进行了分页展示,每一页展示十条 点击第一条药品 氨己烯酸,就会在新的标签页中可以看到药品的详细数据,这是药品的详情页。
点击第一条药品 氨己烯酸,就会在新的标签页中可以看到药品的详细数据,这是药品的详情页。 总的任务就是把所有药品数据都爬取下来,每一个药品数据都用单独一个文件进行保存。
总的任务就是把所有药品数据都爬取下来,每一个药品数据都用单独一个文件进行保存。

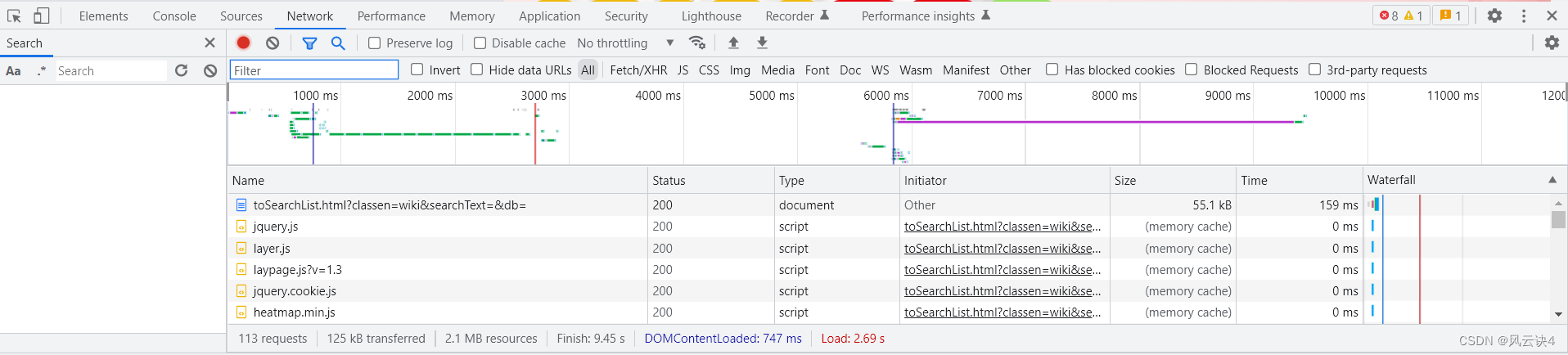
 可以看到,搜出了两个对应链接,我们分别点击链接,右侧的 response 会具体展示其数据。
可以看到,搜出了两个对应链接,我们分别点击链接,右侧的 response 会具体展示其数据。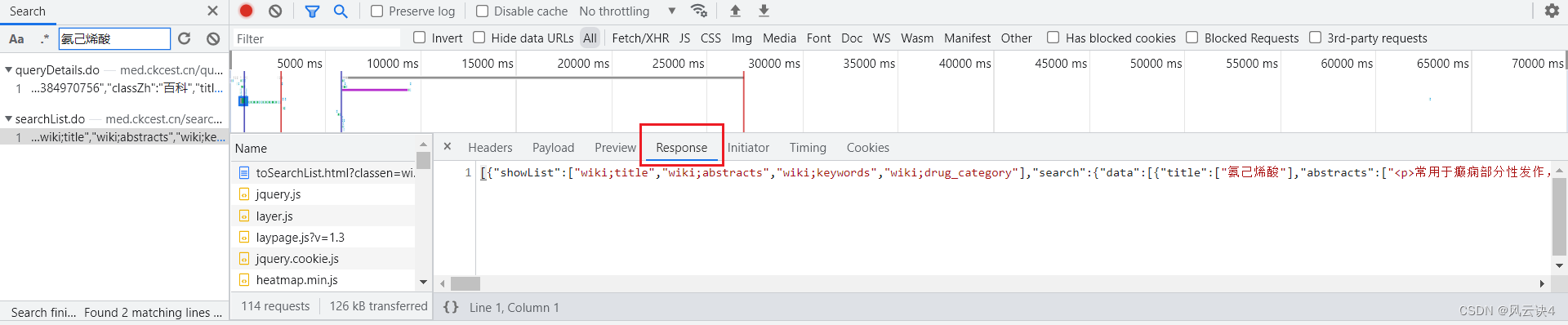
 可以看到,该链接使用的是 get 请求方法,URL中包含了两个重要参数:page=1 和 pageNum=10。参数的暗示就很明显了,这是第一页,这一页包含了十条数据。
可以看到,该链接使用的是 get 请求方法,URL中包含了两个重要参数:page=1 和 pageNum=10。参数的暗示就很明显了,这是第一页,这一页包含了十条数据。 当然,这样乱糟糟的页面是十分难看的,于是我装了一个浏览器插件:JSONVue,可以对 JSON 数据进行有效排列,展示会更加直观好看。(要装这个插件的自行百度就可以)。
当然,这样乱糟糟的页面是十分难看的,于是我装了一个浏览器插件:JSONVue,可以对 JSON 数据进行有效排列,展示会更加直观好看。(要装这个插件的自行百度就可以)。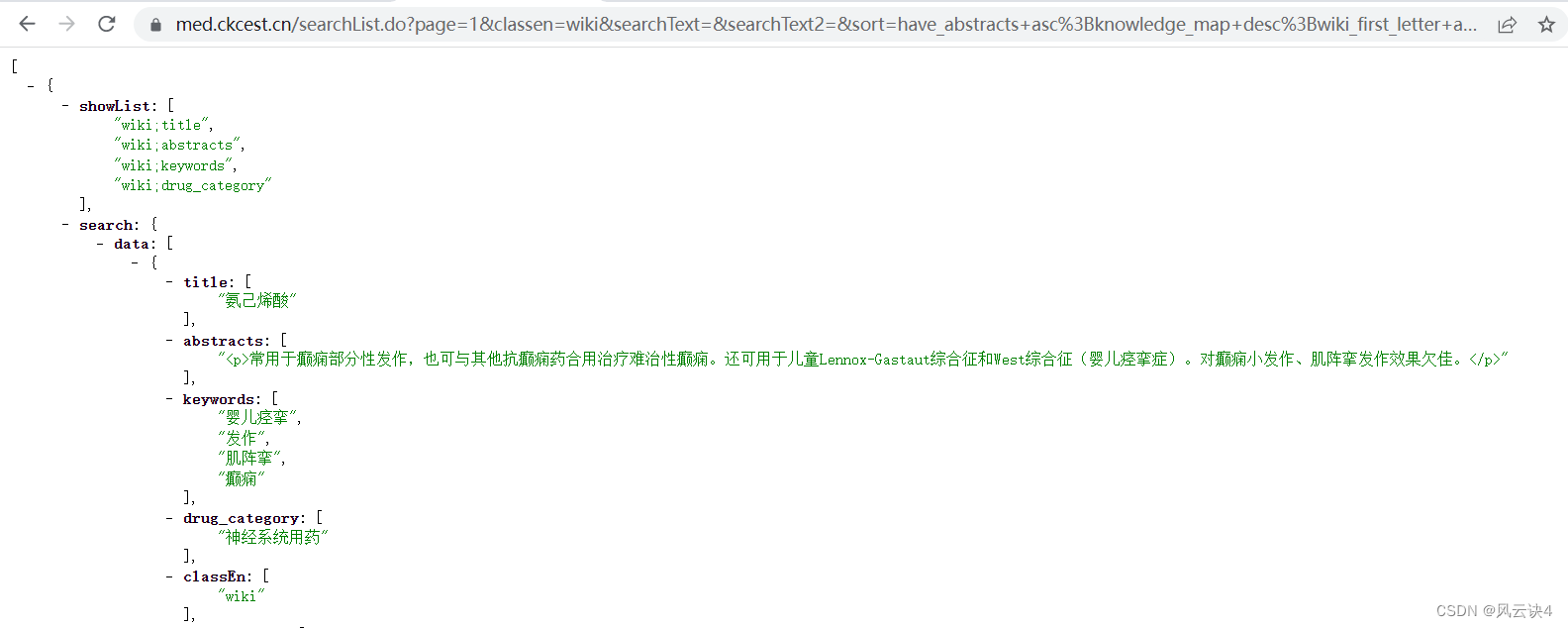
 主函数中通过循环控制 page 、pageNum 两个参数即可生成 URL。这里我选择每次取三十条
主函数中通过循环控制 page 、pageNum 两个参数即可生成 URL。这里我选择每次取三十条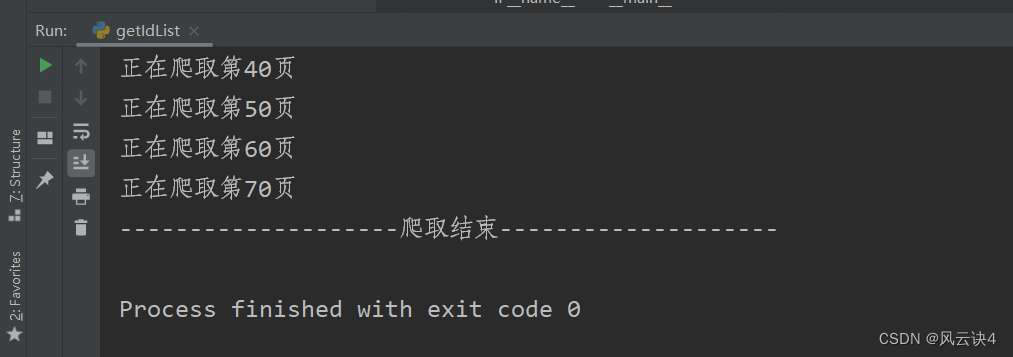
 查看 queryDetail.do 的 Header 部分,发现其使用 的是 POST 请求方法,URL 链接是 https://med.ckcest.cn/queryDetails.do
查看 queryDetail.do 的 Header 部分,发现其使用 的是 POST 请求方法,URL 链接是 https://med.ckcest.cn/queryDetails.do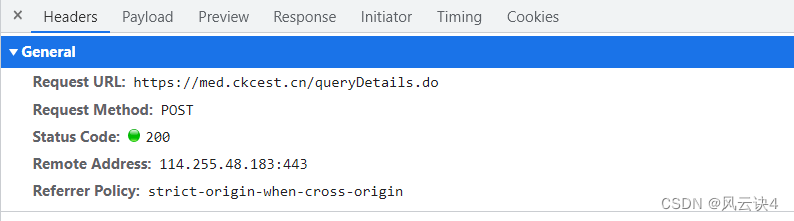 于是我们查看 Payload 部分,该部分写明了该链接要传递的参数是 id 和 nameEn
于是我们查看 Payload 部分,该部分写明了该链接要传递的参数是 id 和 nameEn 我们直接将参数拼接成一个新的 URL :https://med.ckcest.cn/queryDetails.do?id=5005884384970756&nameEn=wiki,在浏览器中开一个新窗口输入这个URL。可以看到,我们已经成功找到了该药品详情页的数据
我们直接将参数拼接成一个新的 URL :https://med.ckcest.cn/queryDetails.do?id=5005884384970756&nameEn=wiki,在浏览器中开一个新窗口输入这个URL。可以看到,我们已经成功找到了该药品详情页的数据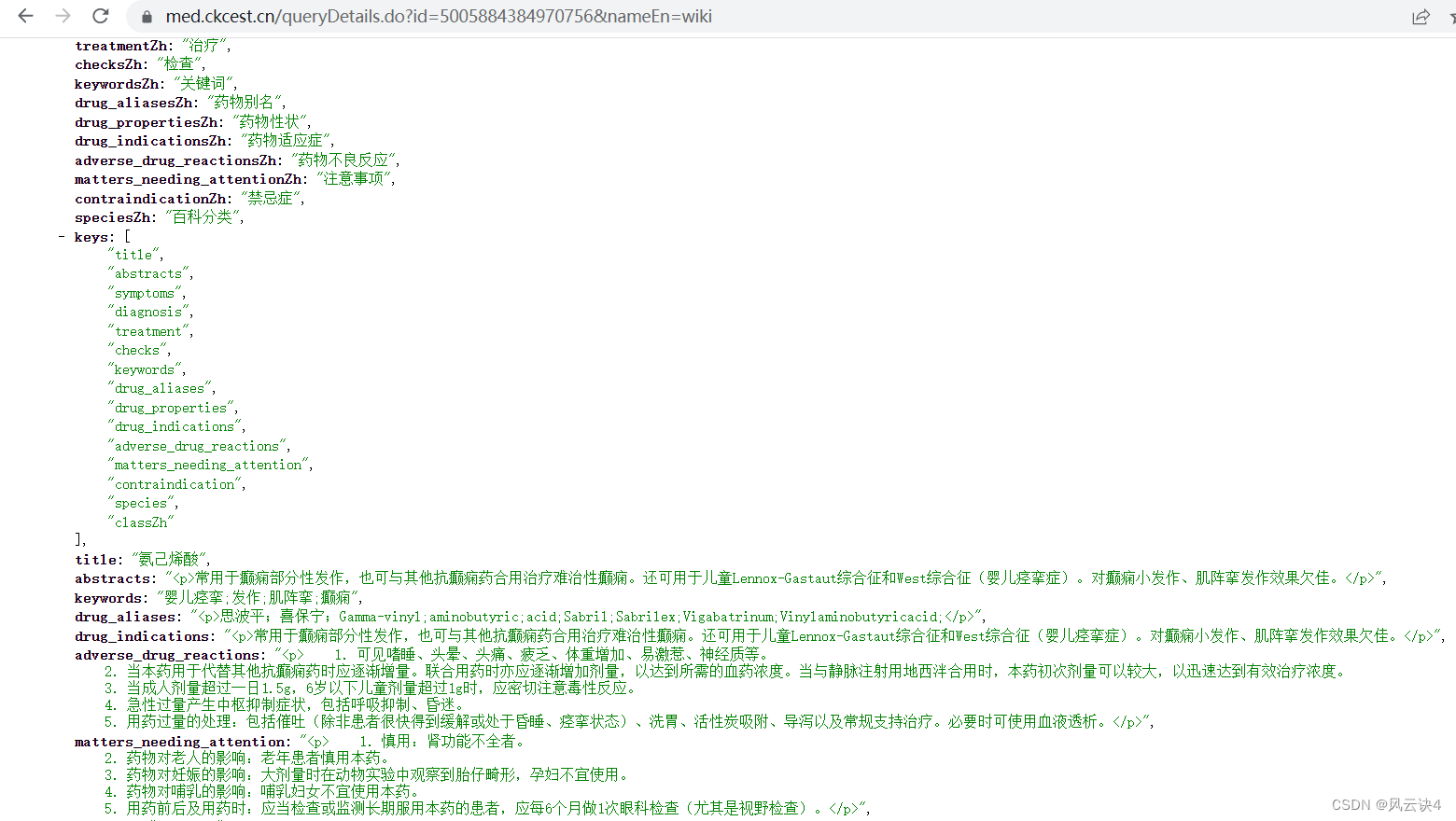 药品的 ID 我们刚才已经爬取过了,可以再次编写爬虫爬取每个药品的详情数据了。
药品的 ID 我们刚才已经爬取过了,可以再次编写爬虫爬取每个药品的详情数据了。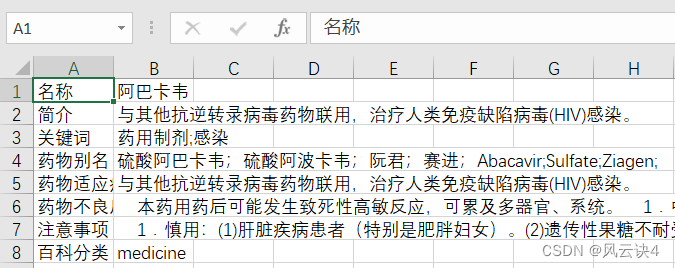
【本文地址】
今日新闻 |
推荐新闻 |