Hadoop集群安装和搭建(全面超详细的过程) |
您所在的位置:网站首页 › 英雄联盟穿甲英雄是谁 › Hadoop集群安装和搭建(全面超详细的过程) |
Hadoop集群安装和搭建(全面超详细的过程)
|
Hadoop集群安装和搭建(全面超详细的过程)
文章目录
Hadoop集群安装和搭建(全面超详细的过程)前言一、虚拟机的安装二、Linux系统安装1.环境准备2.虚拟机安装
三、Centos系统安装四、静态网络配置五、虚拟机克隆配置六、配置hosts文件和ssh免密登录七、Hadoop集群配置八、Hadoop集群测试
前言
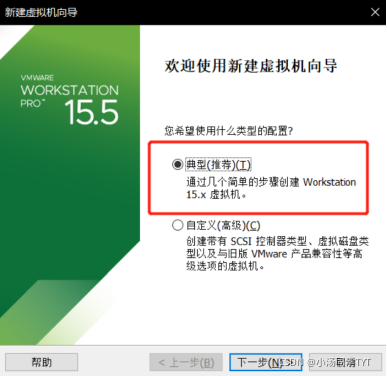
Hadoop是一个开源的、可运行与Linux集群上的分布式计算平台,用户可借助Hadoop存有基础环境的配置(虚拟机安装、Linux安装等),Hadoop集群搭建,配置和测试。 一、虚拟机的安装VMware (Virtual Machine ware)是一个“虚拟PC”软件公司,提供服务器、桌面虚拟化的解决方案。 使用的虚拟软件:VMware15 VMware15软件的安装包与安装教程:https://mp.weixin.qq.com/s/AqPE61EmGJ89lO6sJshOzA 二、Linux系统安装 1.环境准备 VMware15.5 proCentos7镜像文件(mini)Centos7下载链接:https://mirrors.tuna.tsinghua.edu.cn/centos/7.9.2009/isos/x86_64/ 2.虚拟机安装2.1 新建虚拟机,选择典型
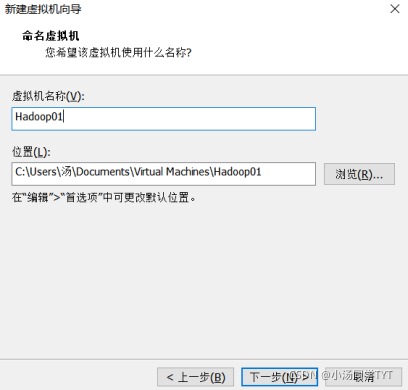
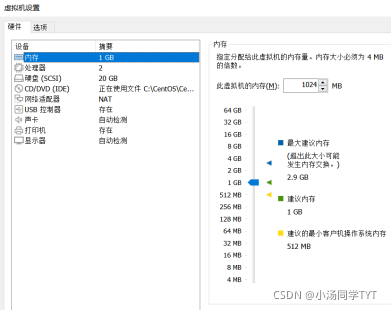
2.3 虚拟机名称和位置 2.4 指定磁盘容量 2.5 虚拟机配置如下 1.开启虚拟机 2.安装 CentOS7 3.选择语言(默认为English)
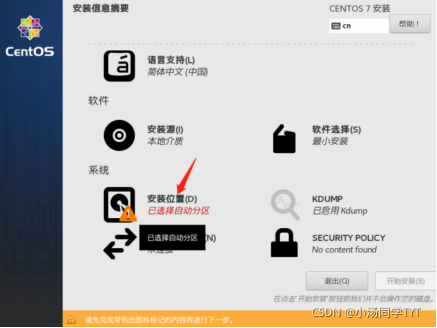
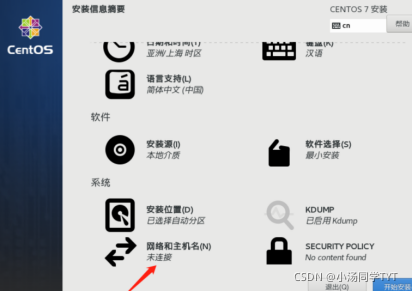
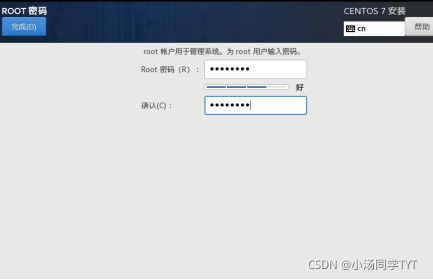
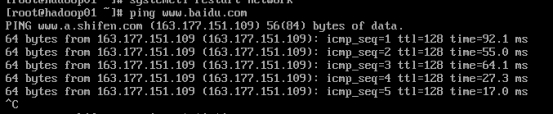
5.安装位置 6.系统网络和主机名 7.开始安装 8.设置ROOT密码 9.安装完成后重启即可 10.使用root权限登录 1.查看网络是否连通 ping www.baidu.com
2.安装net-tools yum upgrade yum install net-tools3.查看Mac地址(enter后面)
4.查看ip地址的起始和结束地址
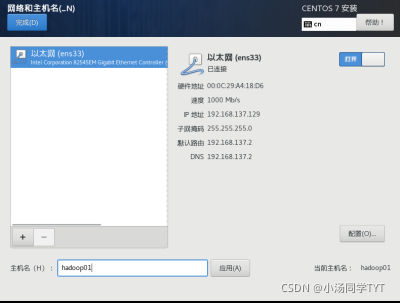
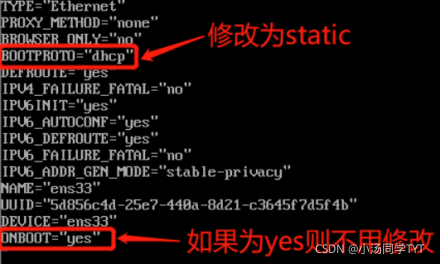
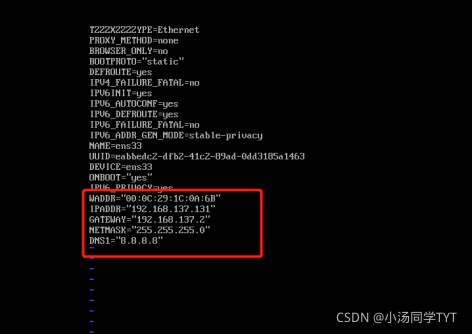
5.修改网络配置文件 vi /etc/sysconfig/network-scripts/ifcfg-ens33mac地址为2步骤的enter值 ip地址参照4步骤自行选择(必须在起始和结束的范围内) 子网掩码默认设置为255.255.255.0 网关的值为将ip地址中最后一段的值改为2 DNS使用谷歌提供的免费dns1:8.8.8.8
6.重启网络服务,查看是否配置成功 systemctl restart network ping www.baidu.com7.重启虚拟机后,查看是否连通网络(ip地址并未改变,且能连通网络) reboot ifconfig ping www.baidu.com
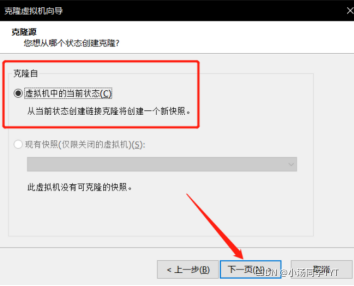
1.克隆虚拟机(右键相应虚拟机->管理->克隆)
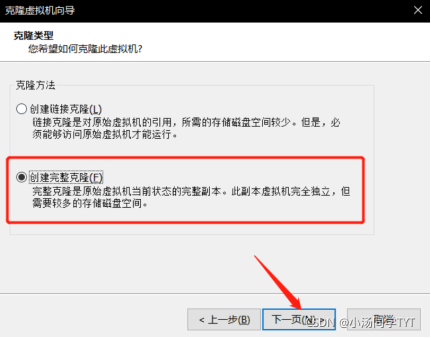
2.创建完整克隆
3.克隆虚拟机名称和位置(等待克隆完成)
4.开启Hadoop02,修改主机名 hostnamectl set-hostname hadoop02 reboot //修改主机名后需重启虚拟机
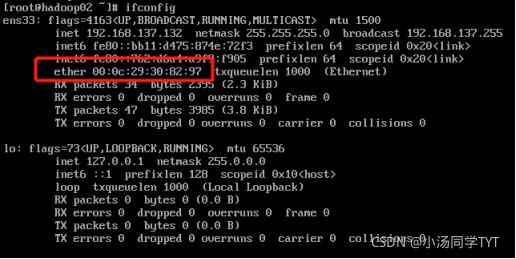
5.查看mac地址 ifconfig
6.网络配置文件修改(标红需要修改,IP自己设置,mac用步骤5查到地址,网关为ip地址最后改为2) vi /etc/sysconfig/network-scripts/ifcfg-ens33
7.重新启动网络配置(查看网络是否可用) systemctl restart network ping www.baidu.com8.按照以上步骤,再克隆另外一台虚拟机Hadoop03 六、配置hosts文件和ssh免密登录1.修改hosts配置文件(所有虚拟机都需要配置此文件) vi /etc/hosts
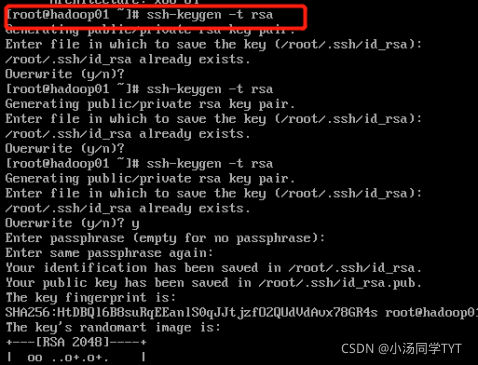
2.生成密钥文件(四次回车) ssh-keygen -t rsa
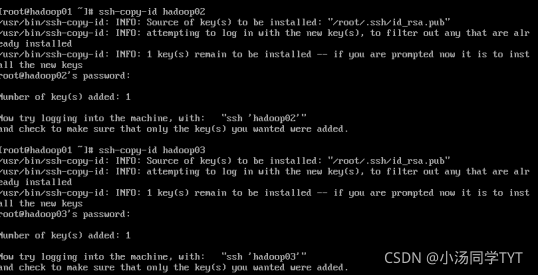
2.将本机公钥文件复制到其它虚拟机上(接收方需先开机) 在hadoop01上执行,先输入yes,后输入对应主机的密码,多台虚拟机配置操作相同 ssh-copy-id hadoop01 ssh-copy-id hadoop02 ssh-copy-id hadoop03
3.在虚拟机hadoop02,hadoop03都需要执行,保证三台主机都能够免密登录 ssh-copy-id hadoop01 ssh-copy-id hadoop02 ssh-copy-id hadoop023.查看是否成功免密登录
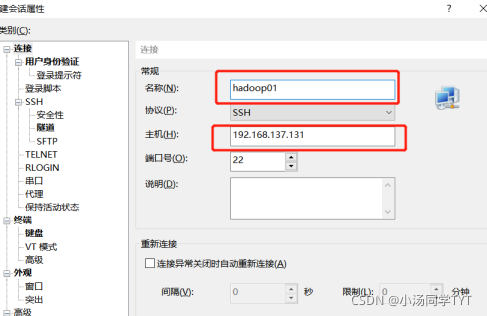
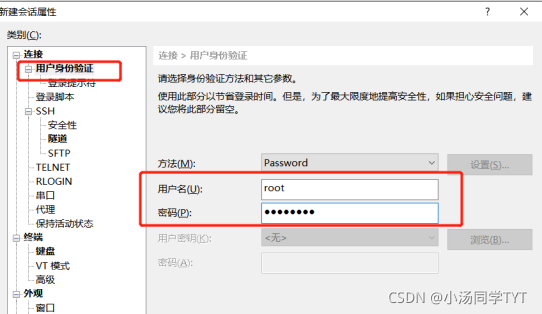
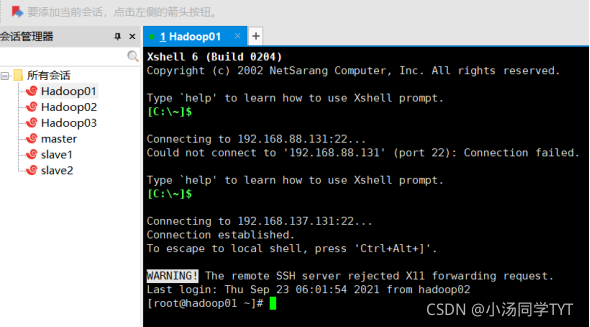
1.在所有虚拟机根目录下新建文件夹export,export文件夹中新建data、servers和software文件 mkdir -p /export/data mkdir -p /export/servers mkdir -p /export/software2.准备安装包 hadoop-2.7.4.tar.gz jdk-8u161-linux-x64.tar.gz 3.下载安装软件Xshell 打开Xshell后点击文件并选择新建,名称填hadoop01,主机填写hadoop01的IP地址,再点击用户身份验证,把hadoop01的账号,密码输入,就可以通过Xshell控制虚拟机,方便后续软件的传输。(重复步骤新建会话控制hadoop02,hadoop03)
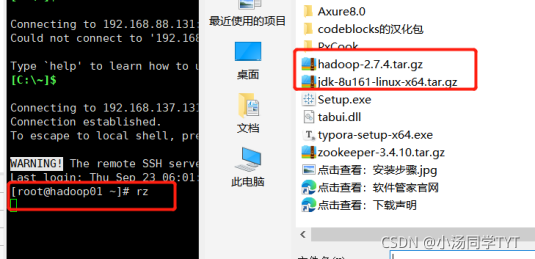
4.在Xshell先进入software文件内,然后下载rz命令,并使用rz命令进行文件上传,此时会弹出上传的窗口,选择要上传的文件,点击确定即可将本地文件上传到Linux上。 cd /export/software yum -y install lrzsz rz
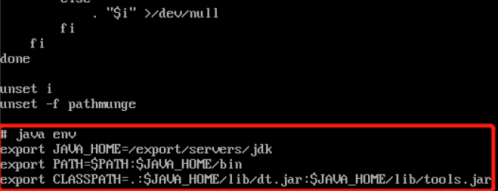
5.安装JDK(所有虚拟机都要操作) 5.1 解压jdk cd /export/software tar -zxvf jdk-8u161-linux-x64.tar.gz -C /export/servers/5.2 重命名jdk目录 cd /export/servers mv jdk1.8.0_161 jdk5.3 配置环境变量 vi /etc/profile #tip:在配置文件末尾追加 export JAVA_HOME=/export/servers/jdk export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
5.4 使配置文件生效 source /etc/profile5.5 查看是否配置成功 java -version
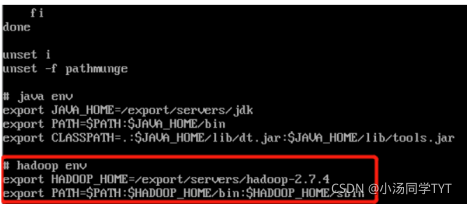
6.Hadoop安装(所有虚拟机都要操作) 6.1 解压hadoop cd /export/software tar -zxvf hadoop-2.7.4.tar.gz -C /export/servers/6.2 打开配置文件 vi /etc/profile6.3 配置hadoop环境变量 #tip:在文件末尾追加 export HADOOP_HOME=/export/servers/hadoop-2.7.4 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
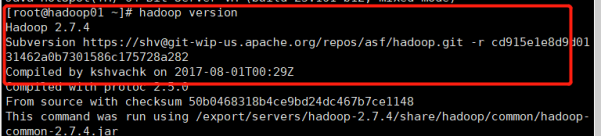
6.4 使配置文件生效 source /etc/profile6.5 查看是否配置成功 hadoop version
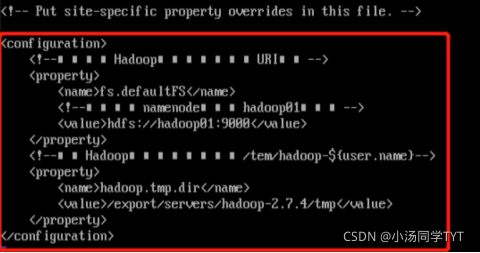
7.Hadoop集群配置 7.1 进入主节点配置目录 cd /export/servers/hadoop-2.7.4/etc/hadoop/7.2 修改hadoop-env.sh文件 vi hadoop-env.sh #tip:找到相应位置,添加这段话 export JAVA_HOME=/export/servers/jdk7.3 修改core-site.xml文件 vi core-site.xml #tip:下图中乱码部分为注释代码,可以删掉,不影响 fs.defaultFS hdfs://hadoop01:9000 hadoop.tmp.dir /export/servers/hadoop-2.7.4/tmp
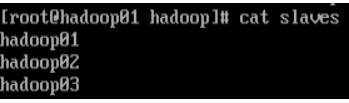
7.4 修改hdfs-site.xml文件 vi hdfs-site.xml dfs.replication 3 dfs.namenode.secondary.http-address hadoop02:500907.5 修改mapred-site.xml文件 cp mapred-site.xml.template mapred-site.xml** vi mapred-site.xml mapreduce.framework.name yarn7.6 修改yarn-site.xml文件 vi yarn-site.xml yarn.resourcemanager.hostname hadoop01 yarn.nodemanager.aux-services mapreduce_shuffle7.7 修改slaves文件 #tip:将文件中的localhost删除,添加主节点和子节点的主机名称 #tip:如主节点hadoop01,子节点hadoop02和hadoop03 vi slaves
7.8将主节点中配置好的文件和hadoop目录copy给子节点 #tip:这里主节点为hadoop01,子节点为hadoop02和hadoop03 scp /etc/profile hadoop02:/etc/profile scp /etc/profile hadoop03:/etc/profile scp -r /export/ hadoop02:/ scp -r /export/ hadoop03:/7.9 使子节点中的配置文件生效 #tip:返回hadoop02和hadoop03节点执行下面命令 source /etc/profile7.10 在主节点格式化文件系统(successfully formatted 格式化成功) hdfs namenode -format
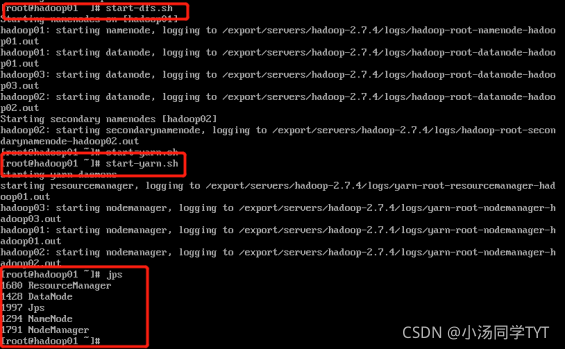
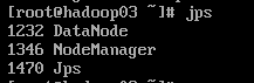
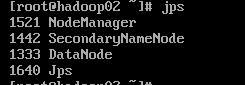
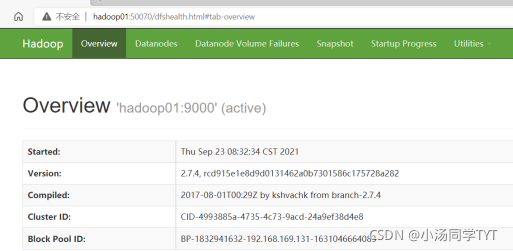
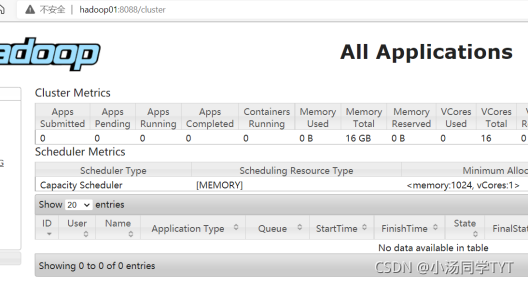
1.启动集群 1.1在主节点启动所有HDFS服务进程 start-dfs.sh1.2 在主节点启动所有HDFS服务进程 start-yarn.sh1.3 使用jps命令查看进程 2.关闭防火墙(所有虚拟机都要操作) systemctl stop firewalld #关闭防火墙 systemctl disable firlewalld #关闭防火墙开机启动3.打开window下的C:\Windows\System32\drivers\etc打开hosts文件,在文件末添加三行代码: 192.168.121.134 hadoop01 192.68.121.135 hadoop02 192.168.121.136 hadoop03 4.通过UI界面查看Hadoop运行状态,在Windows系统下,访问http://hadoop01:50070,查看HDFS集群状态 5.在Windows系统下,访问http://hadoop01:8088,查看Yarn集群状态
|
 ;2.2 选择安装程序光盘映像文件(iso)
;2.2 选择安装程序光盘映像文件(iso) 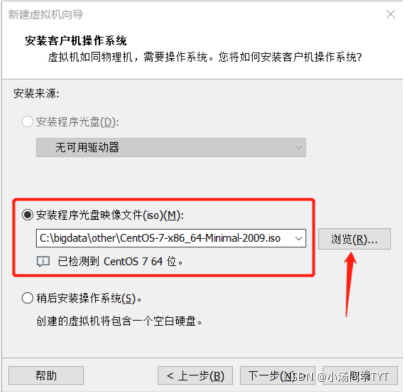



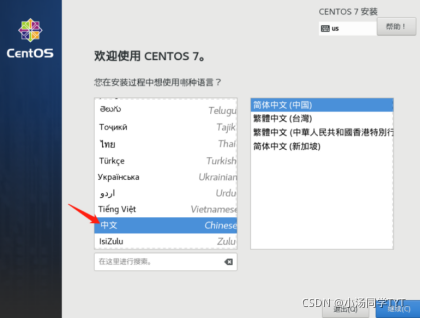 4.日期和时间亚洲/上海(这里默认为最小)
4.日期和时间亚洲/上海(这里默认为最小) 












【本文地址】
今日新闻 |
推荐新闻 |