一种基于多模态大数据的短视频舆情分类方法 |
您所在的位置:网站首页 › 舆情分类的九大分类 › 一种基于多模态大数据的短视频舆情分类方法 |
一种基于多模态大数据的短视频舆情分类方法
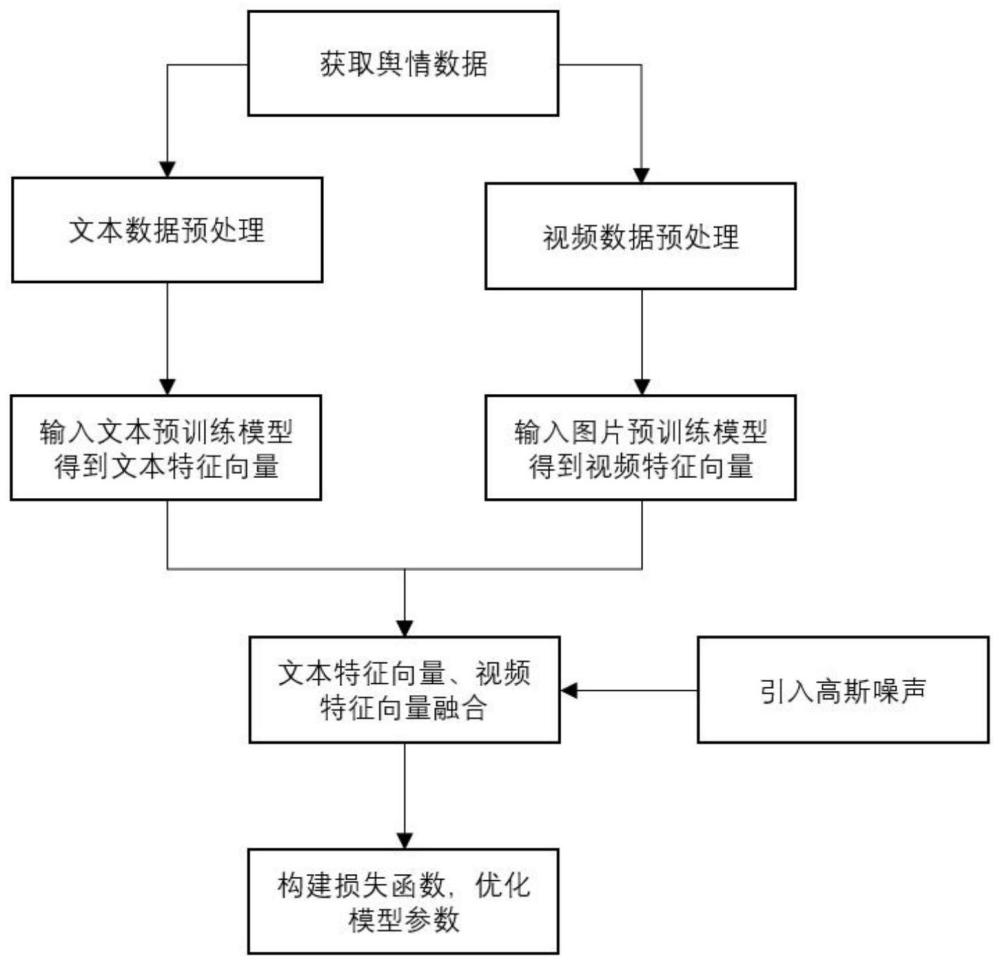 本发明涉及自然语言处理及计算机视觉交叉领域,具体涉及一种基于多模态大数据的短视频舆情分类方法。 背景技术: 1、近年来随着互联网与短视频平台的不断发展,舆情事件的传播速度越来越快,短视频具有内容短小精悍,视频节奏快,覆盖范围广的特点,当舆情事件发酵,短视频作为重要的传播途径需要对相关短视频数据进行分类监控,舆情数据分类则是不可获取的一环。对舆情事件进行分类监控有多方面的意义和价值,能及时处理危机事件,防止带来负面影响,同时能够辅助舆情的主角掌握主动权。但当前舆情分类相关方法多针对文本数据,但对包含视频数据和文本数据的短视频数据分类无能为力,同时在训练中由于训练轮次等关系可能导致模型过拟合,导致分类准确性较低。 技术实现思路 1、为解决以上现有技术存在的问题,本发明提出了一种基于多模态大数据的短视频舆情分类方法,该方法包括:获取待处理的短视频数据和对应的标题数据;对标题数据进行预处理,将预处理后的标题数据和短视频数据输入到训练后的短视频舆情分类模型中,得到短视频舆情分类结果; 2、对短视频舆情分类模型进行训练包括: 3、s1、获取原始数据集,其中原始数据集中的数据包括短视频数据和对应的标题数据; 4、s2、对标题数据进行预处理,将预处理后的标题数据输入到文本编码模块中,得到标题向量特征; 5、s3、从短视频数据中抽取k帧图片,将k帧图片输入到视频编码模块中,得到视频向量特征; 6、s4、根据标题向量特征和视频向量特征计算数据特征向量; 7、s5、对数据特征向量添加高斯噪声,并输入到分类器,得到分类结果; 8、s6、根据分类结果构建模型损失函数,不断优化调整模型参数,当损失函数收敛时完成模型的训练。 9、优选的,对标题数据进行预处理包括:将标题数据中的字母统一转化为小写字母,并去除停用词和非法词;将标题中表情符号转换成对应的汉字,并截取文本长度为k,不足k的在后面补0。 10、进一步的,文本长度为k的计算公式为: 11、 12、其中,floor(.)表示向下取整,mall表示训练时机器显存大小,mt表示单条文本占用显存大小,mv表示单个图片占用显存大小,me表示引入高斯噪声向量占用显存大小,batch为批次大小,mmodel表示模型占用显存大小。 13、优选的,采用视频编码模块对k帧图片进行处理包括:将k帧图片裁剪为224*224的尺寸;对裁剪后的每张图片进行切分,得到patch个16*16像素大小的图片;将切分后的patch个图片输入到预训练模型,得到每帧图片的向量特征。 14、优选的,计算数据特征向量包括:将标题向量特征t和视频向量特征v进行融合,计算包括: 15、t’=tanh(g1(t)) 16、v’=r(g2(v)) 17、qt=r(g3(t’)) 18、kt=r(g4(t’) 19、 20、其中,g1、g2、g3、g4均表示线性层,r()表示relu激活函数,tanh()表示tanh激活函数,⊙表示对应位置元素相乘,dk表示向量长度,softmax()表示softmax激活函数,qt表示标题向量计算得到向量,表示标题向量计算得到的向量的转置,(v’+v’⊙t’)表示引入残差链接的注意力计算方法。 21、优选的,高斯噪声向量生成包括:将噪声向量长度与数据特征向量长度一致,计算公式为: 22、 23、其中,avg(e)表示对一个批次内的所有维度的值求平均,batch表示批次大小。 24、优选的,对数据特征向量添加高斯噪声包括:采用门控机制将高斯噪声加入到数据特性向量中,具体公式包括: 25、e’=t(g1’(e)) 26、m’=σ(m+g2’(r(g(m)))) 27、e”=(1-a)e’+a·e’⊙m’ 28、其中,t表示tanh激活函数,g1’、g2’均为线性层,σ表示sigmoid激活函数,a表示超参数,e”为数据向量混合高斯噪声向量的特征向量,⊙表示对应位置元素相乘。 29、优选的,模型损失函数表达式为: 30、 31、其中,a、b均为超参数,pi为第i类预测的概率,yi为标签,mi为一个批次内第i类的数量。 32、本发明的有益效果: 33、本发明能够充分融合短视频舆情数据中的视频向量特征和文本向量特征得到数据向量特征,同时向数据向量特征中引入高斯噪声以增强模型的泛化性能,同时提出一种损失函数的计算方法,提升模型分类的准确性。 技术特征: 1.一种基于多模态大数据的短视频舆情分类方法,其特征在于,包括:获取待处理的短视频数据和对应的标题数据;对标题数据进行预处理,将预处理后的标题数据和短视频数据输入到训练后的短视频舆情分类模型中,得到短视频舆情分类结果; 2.根据权利要求1所述的一种基于多模态大数据的短视频舆情分类方法,其特征在于,对标题数据进行预处理包括:将标题数据中的字母统一转化为小写字母,并去除停用词和非法词;将标题中表情符号转换成对应的汉字,并截取文本长度为k,不足k的在后面补0。 3.根据权利要求2所述的一种基于多模态大数据的短视频舆情分类方法,其特征在于,文本长度为k的计算公式为: 4.根据权利要求1所述的一种基于多模态大数据的短视频舆情分类方法,其特征在于,采用视频编码模块对k帧图片进行处理包括:将k帧图片裁剪为224*224的尺寸;对裁剪后的每张图片进行切分,得到patch个16*16像素大小的图片;将切分后的patch个图片输入到预训练模型,得到每帧图片的向量特征。 5.根据权利要求1所述的一种基于多模态大数据的短视频舆情分类方法,其特征在于,计算数据特征向量包括:将标题向量特征t和视频向量特征v进行融合,计算包括: 6.根据权利要求1所述的一种基于多模态大数据的短视频舆情分类方法,其特征在于,高斯噪声向量生成包括:将噪声向量长度与数据特征向量长度一致,计算公式为: 7.根据权利要求1所述的一种基于多模态大数据的短视频舆情分类方法,其特征在于,对数据特征向量添加高斯噪声包括:采用门控机制将高斯噪声加入到数据特性向量中,具体公式包括: 8.根据权利要求1所述的一种基于多模态大数据的短视频舆情分类方法,其特征在于,模型损失函数表达式为: 技术总结本发明涉及自然语言处理领域,具体涉及一种基于多模态大数据的短视频舆情分类方法,该方法包括:获取待处理的短视频数据和对应的标题数据;对标题数据进行预处理,得到标题向量特征;从短视频数据中抽取K帧图片,将K帧图片输入到多个patch输入视频编码模块中,得到视频向量特征;根据标题向量特征和视频向量特征计算数据特征向量;对数据特征向量添加高斯噪声,并输入到分类器,得到分类结果;本发明能够充分融合短视频舆情数据中的视频向量特征和文本向量特征得到数据向量特征,同时向数据向量特征中引入高斯噪声以增强模型的泛化性能。技术研发人员:王进,李翔宇,廖唯皓,刘彬,吴思远受保护的技术使用者:重庆邮电大学技术研发日:技术公布日:2024/1/15 |
【本文地址】
今日新闻 |
推荐新闻 |