spark sql(六)sparksql自定义数据源 |
您所在的位置:网站首页 › 自定义数据源 › spark sql(六)sparksql自定义数据源 |
spark sql(六)sparksql自定义数据源
|
1、背景
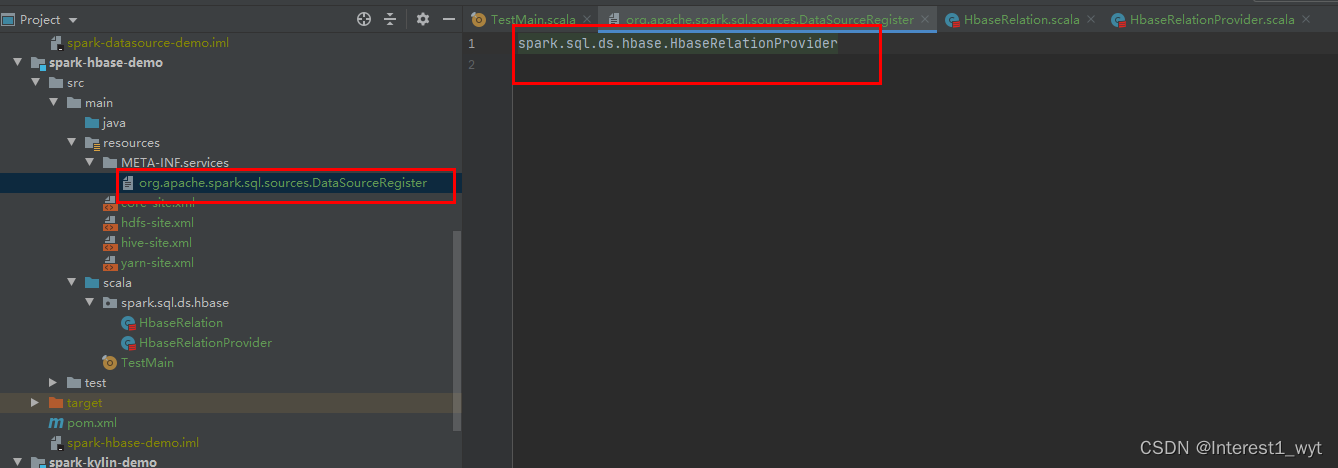
在上一章节我们知道sparksql默认支持avro、csv、json、kafka、orc、parquet、text、jdbc等数据源(hive可以看做是几种文件数据源的集合),如果找不到对应的数据源,则会查找META-INF/services/org.apache.spark.sql.sources.DataSourceRegister文件,并加载其中的数据源类。这篇文章的目的就是想根据sparksql数据源加载的逻辑,自定义实现一个可以查询指定库的数据源。 2、理论介绍要实现自定义数据源,通常要准备: org.apache.spark.sql.sources.DataSourceRegister文件 RelationProvider接口实现类 CreatableRelationProvider接口实现类 DataSourceRegister接口实现类 BaseRelation抽象实现类 TableScan接口实现类 InsertableRelation接口实现类 org.apache.spark.sql.sources.DataSourceRegister文件是自定义数据源被发现的一个入口,如果不创建这个文件,数据源提供类定义为DefaultSource也可以,查看sparksql源码可以知道,它默认也会去查找类名为DefaultSource的数据源提供者。但是一般建议是自己创建文件,引入自定义数据源,而不是使用默认的DefaultSource类名。 RelationProvider接口只有一个需要实现的方法,其方法的功能是提供基础的数据源关系,也就是返回一个BaseRelation对象。CreatableRelationProvider接口也只有一个需要实现的方法,其也是返回BaseRelation对象,但是其提供数据保存功能。DataSourceRegister接口方法只需要定义当前自定义数据源的简称就行。 BaseRelation抽象类定义了需要返回的shcema等信息,一般与scan和insert等接口实现类放在一块进行继承实现(之所以放一块实现,个人感觉是从对象属性与行为的封装性上来考虑的)。TableScan接口方法主要是对目标数据进行完整扫描,返回一个没有过滤的RDD(还有PrunedScan等其它功能丰富的Scan接口,这里为了便于演示,所以只实现最简单的功能)。InsertableRelation接口方法主要功能是实现数据的插入。 3、操作流程 3.1 创建DataSourceRegister文件在resource目录下,创建services文件夹,并在services文件夹中创建org.apache.spark.sql.sources.DataSourceRegister文件。文件中的内容则是自定义数据源提供类的名称。
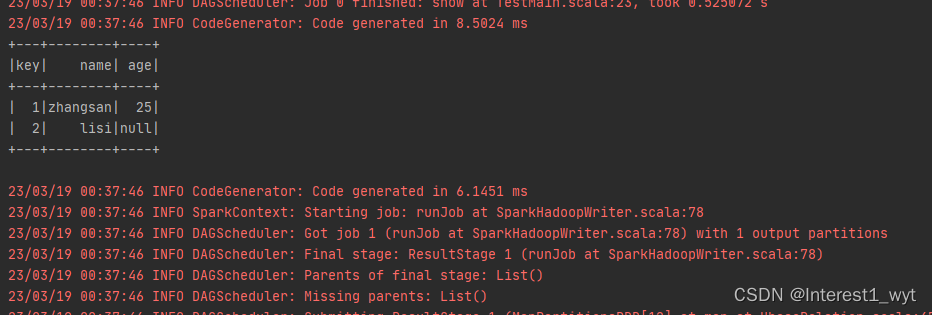
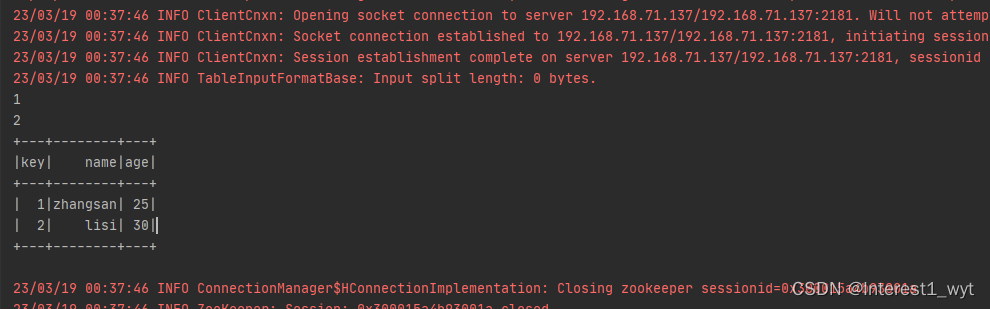
因为RelationProvider、CreatableRelationProvider、DataSourceRegister都属于数据源提供者,所以我们再一个类中进行实现 package spark.sql.ds.hbase import org.apache.spark.sql.{DataFrame, SQLContext, SaveMode} import org.apache.spark.sql.sources.{BaseRelation, CreatableRelationProvider, DataSourceRegister, RelationProvider} import org.apache.spark.sql.types.{StringType, StructField, StructType} class HbaseRelationProvider extends RelationProvider with CreatableRelationProvider with DataSourceRegister { override def shortName(): String = "hbase" override def createRelation(sqlContext: SQLContext, parameters: Map[String, String]): BaseRelation = { //1、从参数中获取列信息,并拼成schema结构化对象 val schema: StructType = StructType(parameters("columns").split(",").map(col => StructField(col, StringType, nullable = true))) //2、创建HbaseRelation对象 HbaseRelation(sqlContext,parameters,schema) } override def createRelation(sqlContext: SQLContext, mode: SaveMode, parameters: Map[String, String], data: DataFrame): BaseRelation = { //1、根据入参创建HbaseRelation对象 val relation = HbaseRelation(sqlContext,parameters,data.schema) //2、调用HbaseRelation对象的数据存储方法 relation.insert(data,true) //3、返回对象 relation } } 3.3创建数据源类数据源提供类需要返回一个BaseRelation对象,这个对象就是我们需要继承抽象BaseRelation类实现的对象。因为scan和insert都属于该对象的操作行为,所以遵循属性和行为封装在一块的规则,这里我们都在一个样例类中进行实现,代码如下: package spark.sql.ds.hbase import org.apache.hadoop.hbase.HBaseConfiguration import org.apache.hadoop.hbase.client.{Put, Result, Scan} import org.apache.hadoop.hbase.io.ImmutableBytesWritable import org.apache.hadoop.hbase.mapreduce.{TableInputFormat, TableOutputFormat} import org.apache.hadoop.hbase.protobuf.ProtobufUtil import org.apache.hadoop.hbase.util.{Base64, Bytes} import org.apache.hadoop.mapred.JobConf import org.apache.hadoop.mapreduce.Job import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame, Row, SQLContext} import org.apache.spark.sql.sources.{BaseRelation, InsertableRelation, TableScan} import org.apache.spark.sql.types.StructType case class HbaseRelation(context: SQLContext, params: Map[String, String], schema: StructType) extends BaseRelation with TableScan with InsertableRelation { override def sqlContext: SQLContext = context override def buildScan(): RDD[Row] = { //1、配置hhbase val conf = HBaseConfiguration.create() conf.set("hbase.zookeeper.quorum", "192.168.71.135,192.168.71.136,192.168.71.137") conf.set("hbase.zookeeper.property.clientPort", "2181") conf.set("zookeeper.znode.parent", "/hbase") conf.set("hbase.mapreduce.inputtable", params.get("tableName").get) val scan: Scan = new Scan() scan.addFamily(Bytes.toBytes(params.get("family").get)) val columns:Array[String] = params.get("columns").get.split(",") columns.foreach(col => scan.addColumn(Bytes.toBytes(params.get("family").get), Bytes.toBytes(col))) conf.set("hbase.mapreduce.scan", Base64.encodeBytes(ProtobufUtil.toScan(scan).toByteArray)) val scanRDD: RDD[(ImmutableBytesWritable, Result)] = sqlContext.sparkContext.newAPIHadoopRDD( conf, classOf[TableInputFormat], classOf[ImmutableBytesWritable], classOf[Result] ) val rdd: RDD[Row] = scanRDD.map { case (_, result: Result) => val key = Bytes.toString(result.getRow) println(key) val values = columns.filter(s => !s.equalsIgnoreCase("key")).map(col => Bytes.toString(result.getValue(Bytes.toBytes(params.get("family").get), Bytes.toBytes(col)))) Row.fromSeq(key +: values) } rdd } override def insert(data: DataFrame, overwrite: Boolean): Unit = { //1、配置hhbase val conf = HBaseConfiguration.create() conf.set("hbase.zookeeper.quorum", "192.168.71.135,192.168.71.136,192.168.71.137") conf.set("hbase.zookeeper.property.clientPort", "2181") conf.set("hbase.mapred.outputtable", params.get("tableName").get) //2、配置mapreduce任务 val jobConf = new JobConf(conf) val job = Job.getInstance(jobConf) job.setOutputKeyClass(classOf[ImmutableBytesWritable]) job.setOutputValueClass(classOf[Result]) job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]]) //3、封装要插入的数据 val columns = data.columns val putsRDD: RDD[(ImmutableBytesWritable, Put)] = data.rdd.map(row => { val put = new Put(Bytes.toBytes(params.get("rowKey").get)) columns.foreach(col => put.add(Bytes.toBytes(params.get("family").get), Bytes.toBytes(col), Bytes.toBytes(row.getAs[String](col)))) (new ImmutableBytesWritable, put) }) //4、通过mapreduce任务将数据插入hbase putsRDD.saveAsNewAPIHadoopDataset(job.getConfiguration) } } 3.4 创建hbase表和相关数据登录hbase shell客户端,执行如下命令: create 'test_tb1','cf1' put 'test_tb1', '1', 'cf1:name', 'zhangsan' put 'test_tb1', '2', 'cf1:name', 'lisi' put 'test_tb1', '1', 'cf1:age', '25' scan 'test_tb1'这里我们定义的一个列簇,其中主键为1的数据name和age都有值,主键为2的数据只有name有值,因此我们的代码目标就是先查出所有的表数据,然后补全主键为2的age字段数据。 3.5创建测试代码测试代码的目标是查询出hbase中的三条数据,并在rowkey=2的那条数据上补充完age字段的值。 import org.apache.spark.rdd.RDD import org.apache.spark.sql.types.{StringType, StructField, StructType} import org.apache.spark.sql.{DataFrame, Dataset, Row, SaveMode, SparkSession} object TestMain { def main(args: Array[String]): Unit = { System.setProperty("hadoop.home.dir", "D:\\hadoop-2.5.2") val sparkSession = SparkSession.builder .appName("wyt01bigdata") .master("local") .config("spark.hadoop.validateOutputSpecs", false) .enableHiveSupport() .getOrCreate // 读取数据 val hbaseDF: DataFrame = sparkSession.read .format("hbase") .option("tableName", "test_tb1") .option("family", "cf1") .option("columns", "key,name,age") .load() hbaseDF.show() // 保存数据 import sparkSession.implicits._ val rdd:RDD[Row] = sparkSession.sparkContext.parallelize(List("30")).map(age=>Row(age)) val insertDF = sparkSession.createDataFrame(rdd,StructType(List(StructField("age", StringType, nullable = true)))) insertDF.write .mode(SaveMode.Overwrite) .format("hbase") .option("tableName", "test_tb1") .option("family", "cf1") .option("columns", "age") .option("rowKey", "2") .save() // 读取最新数据 val newDF: DataFrame = sparkSession.read .format("hbase") .option("tableName", "test_tb1") .option("family", "cf1") .option("columns", "key,name,age") .load() newDF.show() } }结果如下:
本篇文章只是写了最简单的自定义数据源的流程demo,很多特性并没有介绍,比如hbase读写中的一些配置如果放到程序运行时动态传入,就可以提高代码的可复制性。还有hbase读写其实可以跟sql解析计划挂钩,只需要保证在最后物理计划执行时转换成hbase的读写即可(jdbc常规库好写,hbase难度略大),这样就可以针对查询做我们自定义的一些优化策略。在实际工作中的场景和需求比这个复杂很多倍,铺开讲很难描述的条理清晰,后续我也会以工作中解决的一些难点作为切入点进行一些文章的编辑。 最后,如果对自定义数据源不懂或者不太会用的朋友,个人建议可以参考一下sparksql的jdbc自定义数据源实现源码。该源码不仅包含了自定义数据源处理逻辑,还包含自定义RDD的逻辑,是一个很不错的参考模块。 5、代码运行心得整个demo个人感觉最难的部分是引入依赖和排包冲突,前前后后排了将近个把小时,下面是我的maven配置以及遇到的一些问题和参考的文档。 父类pom.xml 4.0.0 org.example wyt01bigdata pom 1.0-SNAPSHOT test-demo spark-kylin-demo spark-datasource-demo spark-clickhouse-demo spark-hbase-demo 3.0.1 2.12 io.netty netty-all 4.1.47.Final org.apache.spark spark-hive_${scala.version} ${spark.version} org.apache.spark spark-core_${scala.version} ${spark.version} org.apache.spark spark-streaming_${scala.version} ${spark.version} org.apache.spark spark-streaming-kafka-0-10_2.12 3.1.3 mysql mysql-connector-java 8.0.23 org.scala-lang scala-compiler 2.12.14 org.scala-tools maven-scala-plugin 2.15.2 compile testCompile子类pom.xml wyt01bigdata org.example 1.0-SNAPSHOT 4.0.0 spark-hbase-demo org.apache.hbase hbase-client 1.4.13 org.apache.hbase hbase-server 1.4.13 org.apache.hbase hbase-mapreduce 2.2.6 com.fasterxml.jackson.module * com.fasterxml.jackson.core *Spark2.3 - 运行异常NoSuchMethodError:io.netty.buffer.PooledByteBufAllocator.metric()_寒沧的博客-CSDN博客 java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset._悠然大月季的博客-CSDN博客 |
 至此我们mysql自定义数据源的功能实现完毕
至此我们mysql自定义数据源的功能实现完毕【本文地址】
今日新闻 |
推荐新闻 |