编译原理初级·新手村学习之二 |
您所在的位置:网站首页 › 自动机工作原理 › 编译原理初级·新手村学习之二 |
编译原理初级·新手村学习之二
|
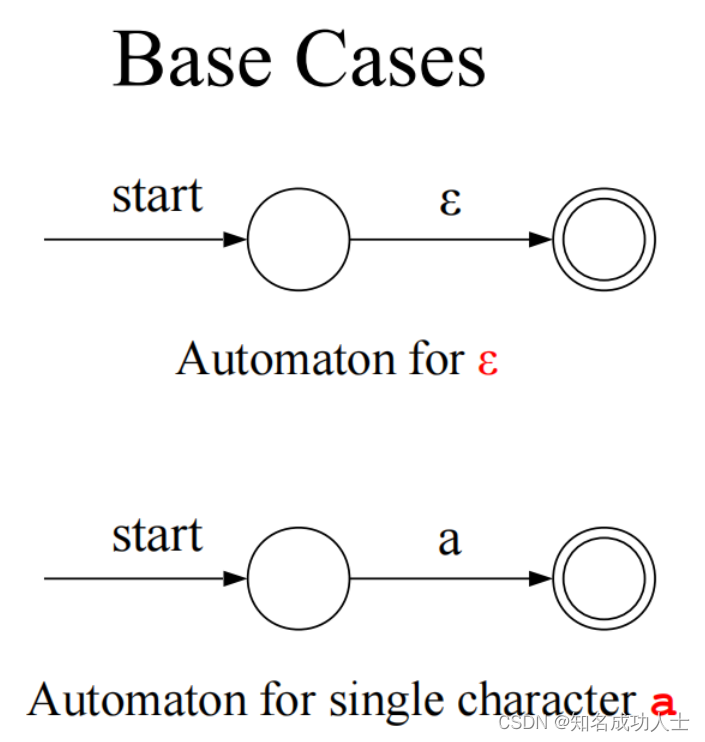
这个系列主要用来分享编译原理入门学习的一些总结。书接上回编译原理的概述部分(编译原理初级·新手村学习(一)-CSDN博客),本文主要介绍有穷自动机的定义以及主要的两种有穷自动机(NFA和DFA)。 2.有穷自动机 1.定义有穷自动机(Finite Automata):具有离散的输入信息和有穷数目的内部状态。两种主要的种类是DFA和NFA。 每个有穷自动机都伴随着转换图,转换图的组成: 初始状态(只有一个):由start箭头指向。 终止状态(接受状态):可以有多个,用双圈来表示。 带标记的有向边(可能为空串)。
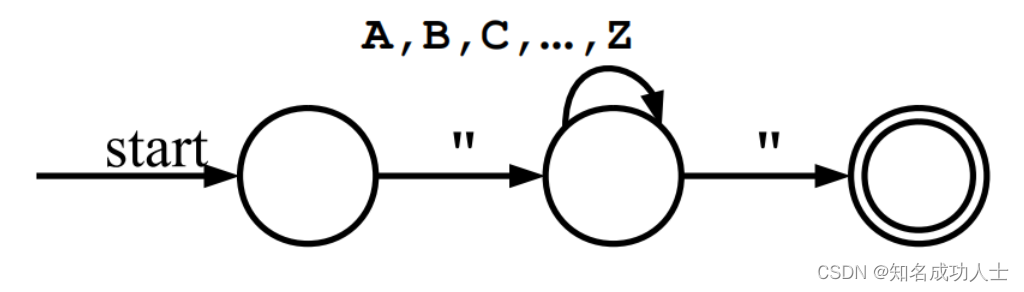
一个简单的自动机例子:
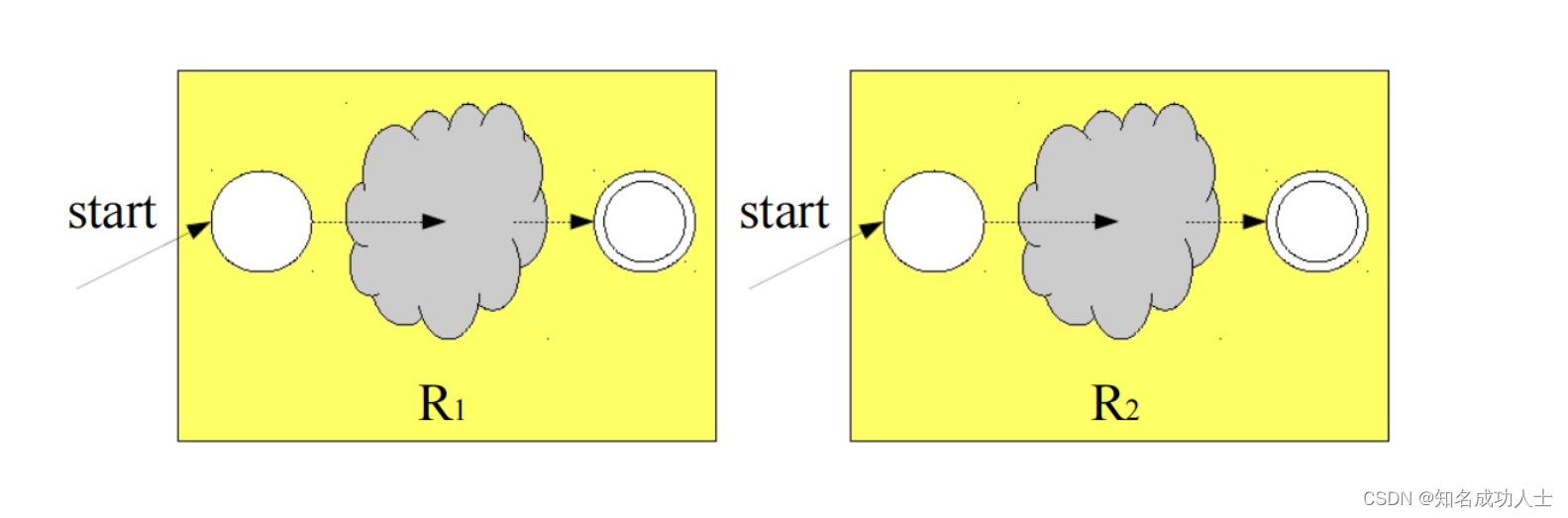
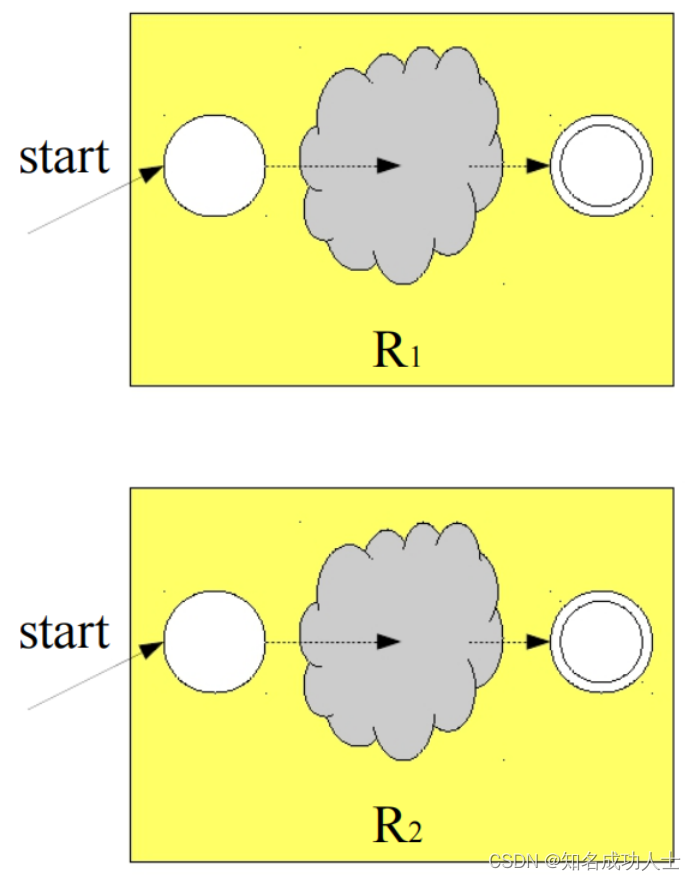
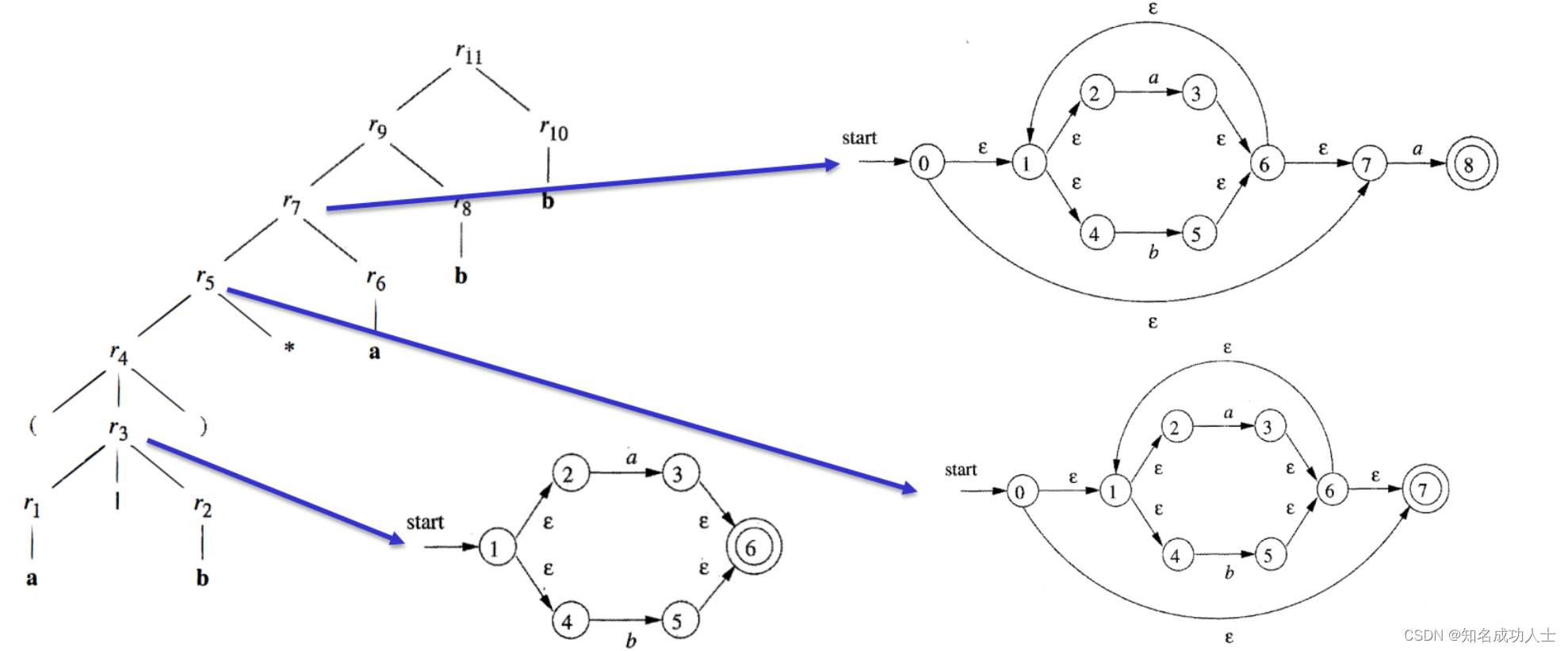
这个自动机就表示:引号里面包含0~∞个大写英文字母的字符串。(如:“HEYA”) 每个圆都是自动机的一种状态。自动机的configurations是它所处的状态决定的。这些箭头被称为transitions,自动机通过transitions来改变它所处的状态。自动机将一个字符串作为输入,并决定是接受还是拒绝该字符串。双圆表示此状态为接受状态。如果该字符串以接受状态结束,则该自动机将接受它,反之就会拒绝。 最长子串匹配原则:当输入串的多个前缀与一个或多个模式匹配时,总是选择最长的前缀进行匹配。 在上一节中我们提到了DFA(Deterministic finite automata)和NFA(Nondeterministic finite automata)的概念。 DFA,即确定的有穷自动机,可以表示为 M=(S,∑, S:有穷状态机, ∑:输入字母表(ε不是∑中的元素), S0:开始状态(初始状态), F:接收状态(终止状态)集合。(S0∈S,F 值得注意的是,每个DFA都有等价的NFA。 正则文法 下面我们先从NFA说起。 2.NFA(Nondeterministic finite automata) 从正则表达式到有穷自动机:下面我们先将正则表达式R1R2构建为FA: R1,R2本来是两个单独的状态,这时候把他们分别表示:
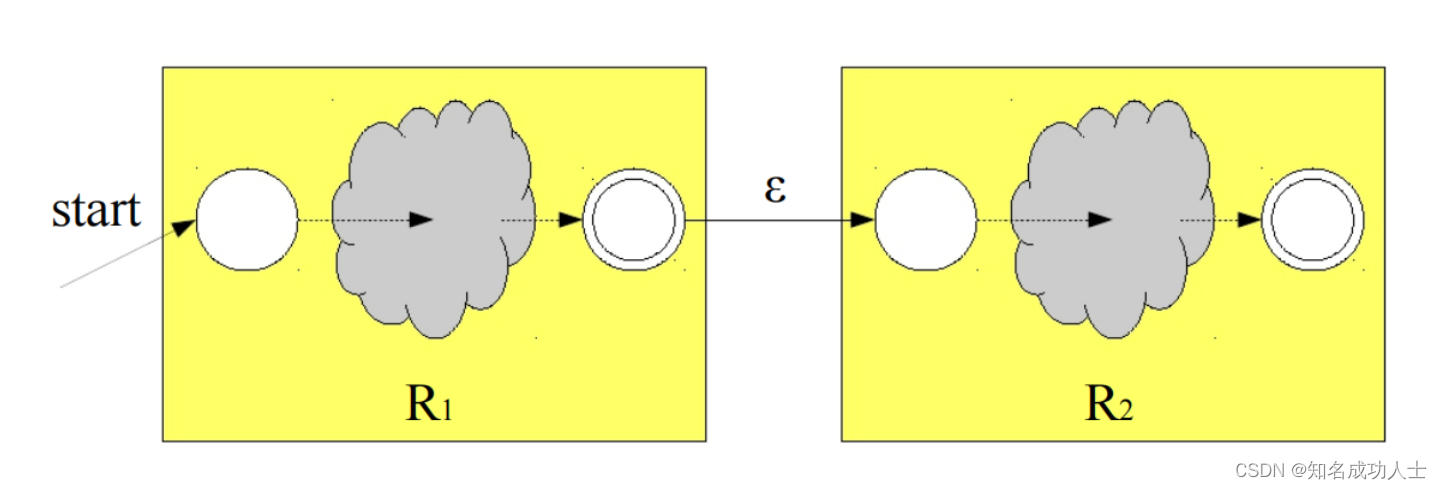
然后再把他们连起来,由于是直接连接的关系,所以中间加一个空串连接:
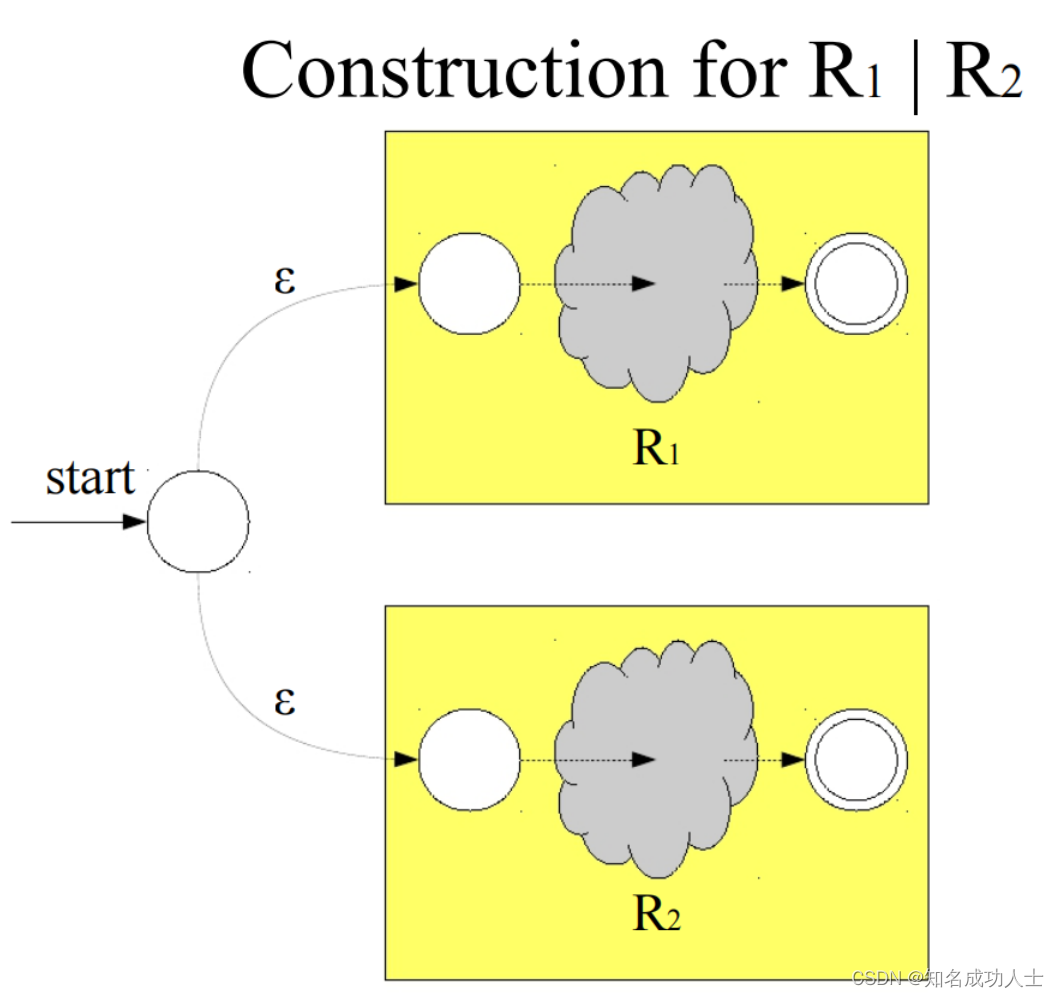
然后我们再将正则表达式R1|R2构建为FA: R1,R2本来是两个单独的状态,还是先把他们分别表示,然后为他们加上共同的start,由于R1R2之间是 | 关系,所以他们与start之间都用空串连接。
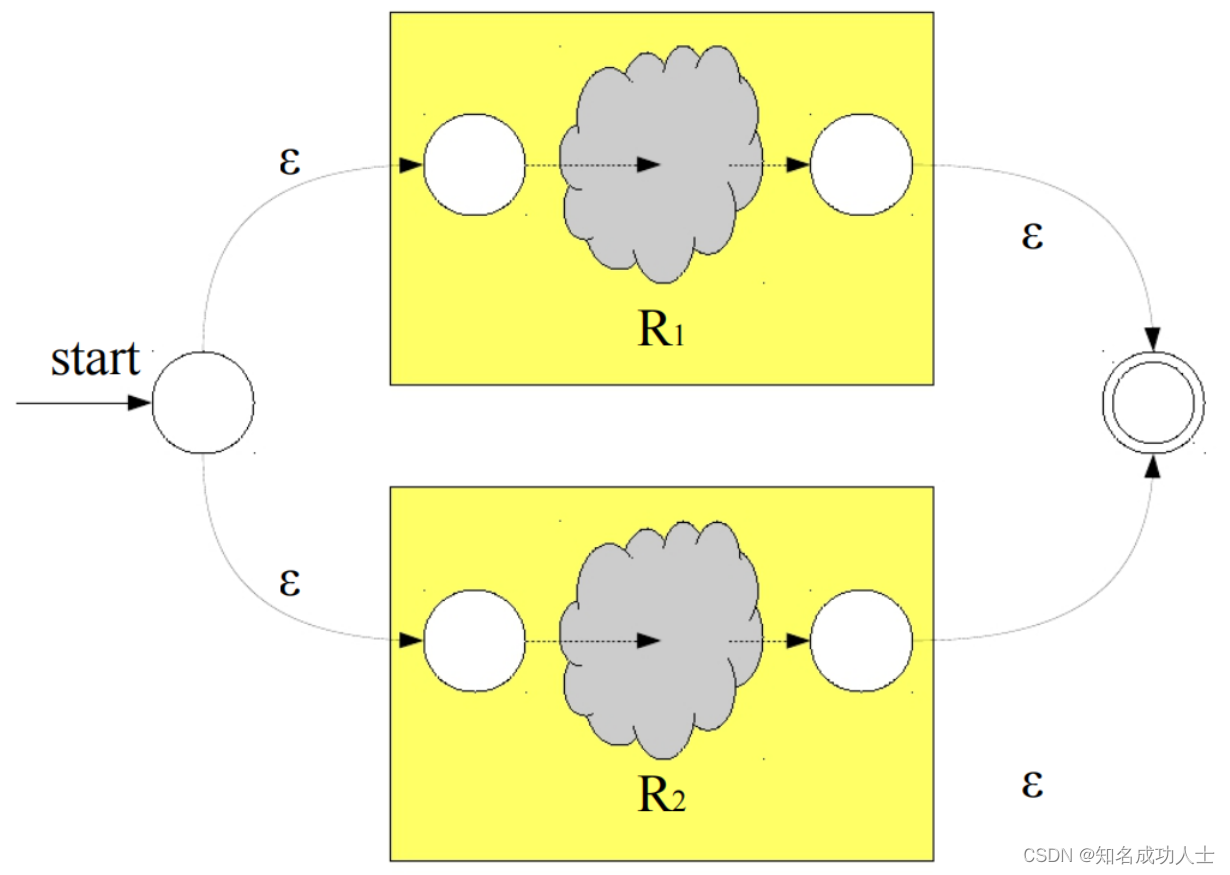
然后最后为他们加上共同的结尾,同理也用空串连接。
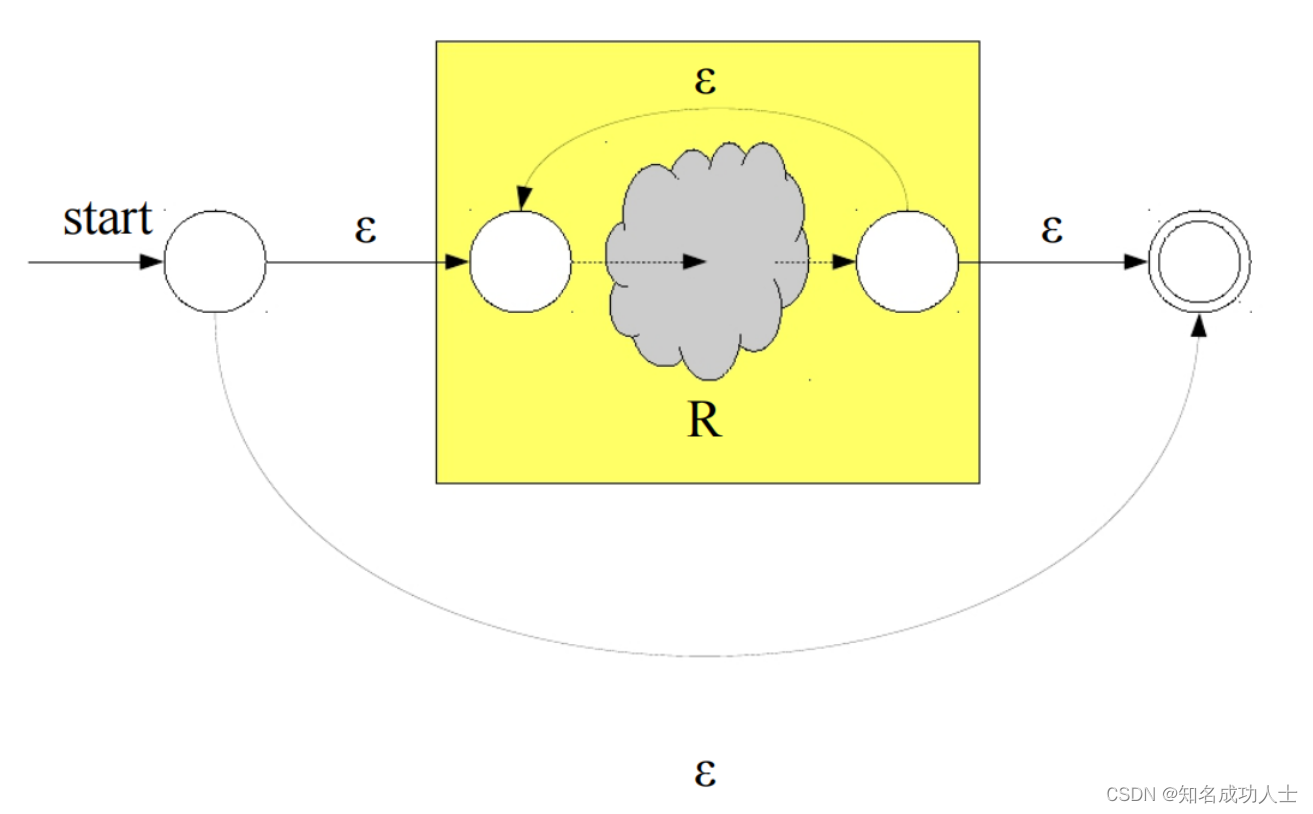
同理可推出对R*(Kleene闭包,即表示0次或多次重复)的构造结果如下:
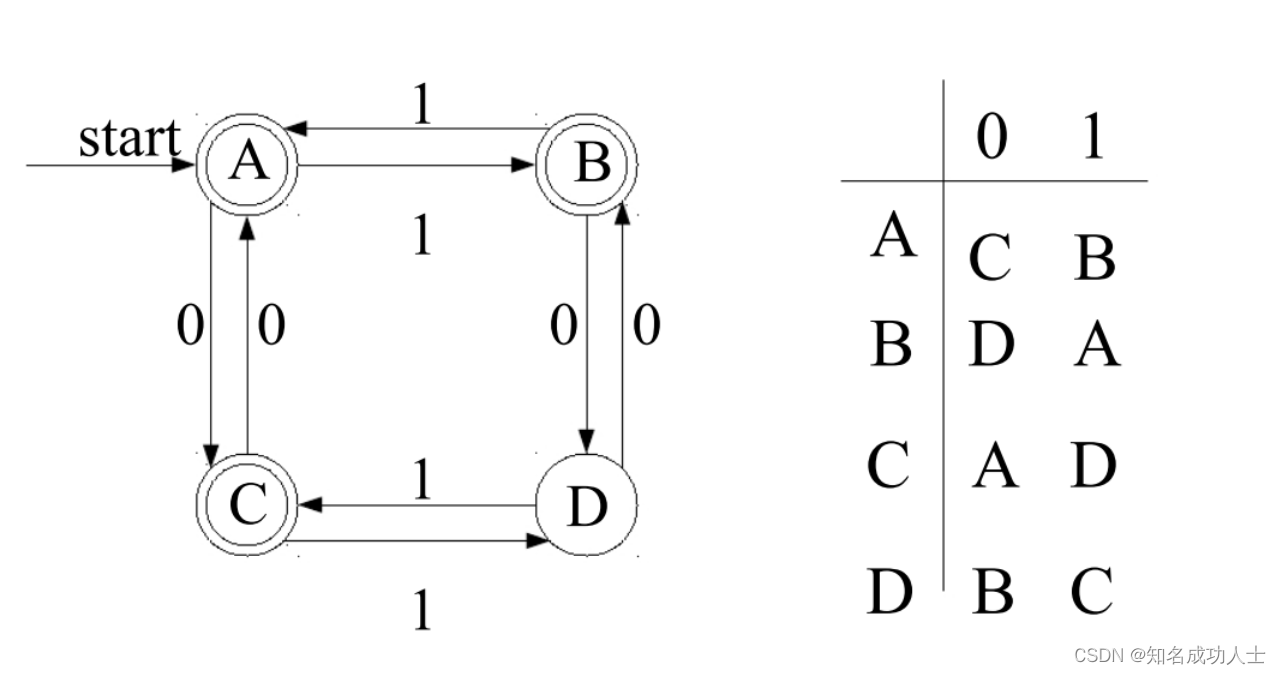
注意:带有“ε-边”的NFA与不带空边的NFA有等价性 模拟NFA的过程: 跟踪一组状态,最初是初始(start)状态和通过ε-moves可到达的所有状态。 对于输入中的每个字符: 建立一个“下一个状态”的集合,即(a set of next states),最初是empty。 然后对于每个current state: 1.跟随所有标记当前字母的所有转换。2.将这些状态添加到新状态集中。 然后将每个能通过一个ε-move所到达的状态添加到the set of next states。 如果:NFA has n states and m transitions,那么:可以在时间O(k(n+m))内确定一个长度为k的字符串是否匹配NFA。 conflict和匹配原则随着scanning的进行,我们很容易发现问题:那就是conflict,也就是我们遇到有多种方法可以扫描输入时,如何知道要选择哪一个的问题。 这时候,为了消解conflict,我们自然就引出了新的方法:Maximal munch.也就是最长子串匹配原则。即当输入串的多个前缀与一个或多个模式匹配时,总是选择最长的前缀进行匹配。 当然,要假设所有标记都被指定为正则表达式且算法为从左到右的扫描。 还有一些其他的规则,比如:当两个正则表达式应用时,选择“优先”的一个;还有Simple priority system:选择首先定义的规则。 如果没有匹配的字符怎么办?添加一个“catch-all”原则。匹配任何字符并报告一个error。 Summary of Conflict Resolution: • 为每个正则表达式构建一个自动机。 • 通过添加一个新的起始状态将它们合并成一个自动机。 • 扫描输入,跟踪最后已知的匹配。 • 通过选择更高优先级的匹配来解决冲突。 • 设置一个“catch-all”规则来处理错误情况。 3.DFA(Deterministic finite automata)回到那个问题:当我们有多种方法可以扫描输入时,我们如何知道要选择哪一个呢?这时候就要提到我们的另一种主要的有穷状态机:DFA。 DFA,即确定的有穷自动机,可以表示为 M=(S,∑, S:有穷状态机, ∑:输入字母表(ε不是∑中的元素), S0:开始状态(初始状态), F:接收状态(终止状态)集合。(S0∈S,F 上面我们看到的都是NFA,那DFA和NFA有什么区别呢? 每个DFA就像NFA,但是更加严格,体现在: 1.每个状态必须为每个字母定义一个确切的转换。 2.不允许使用ε-移动。 DFA的一个例子:
在最坏的情况下,具有n个状态的NFA需要时间O(mn^2) 来匹配长度为m的字符串。但是也有可能只花费O(m)。 NFA到DFA的转换:像上面提到过的,每个DFA都有等价的NFA,因此我们自然可以将NFA转换成DFA。 事实上,NFA的表现形式比DFA更加直观,在转换过程中,我们要让DFA模拟NFA。让DFA的状态对应NFA的状态集,DFA状态之间的转换对应于NFA中状态集之间的转换。 首先要消除的就是ε-transition:
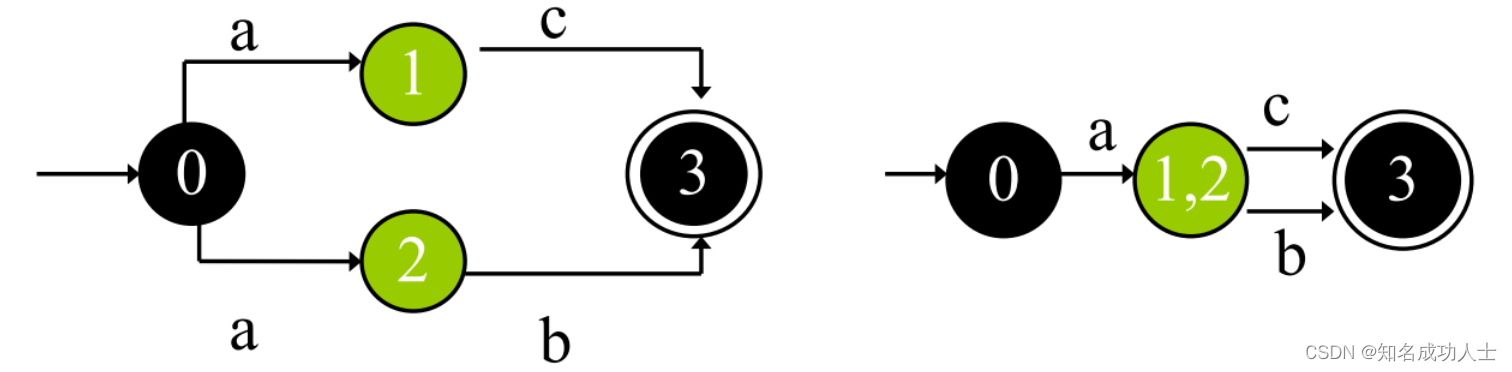
然后消除在单个字符上从一个状态中进行的多个转换:
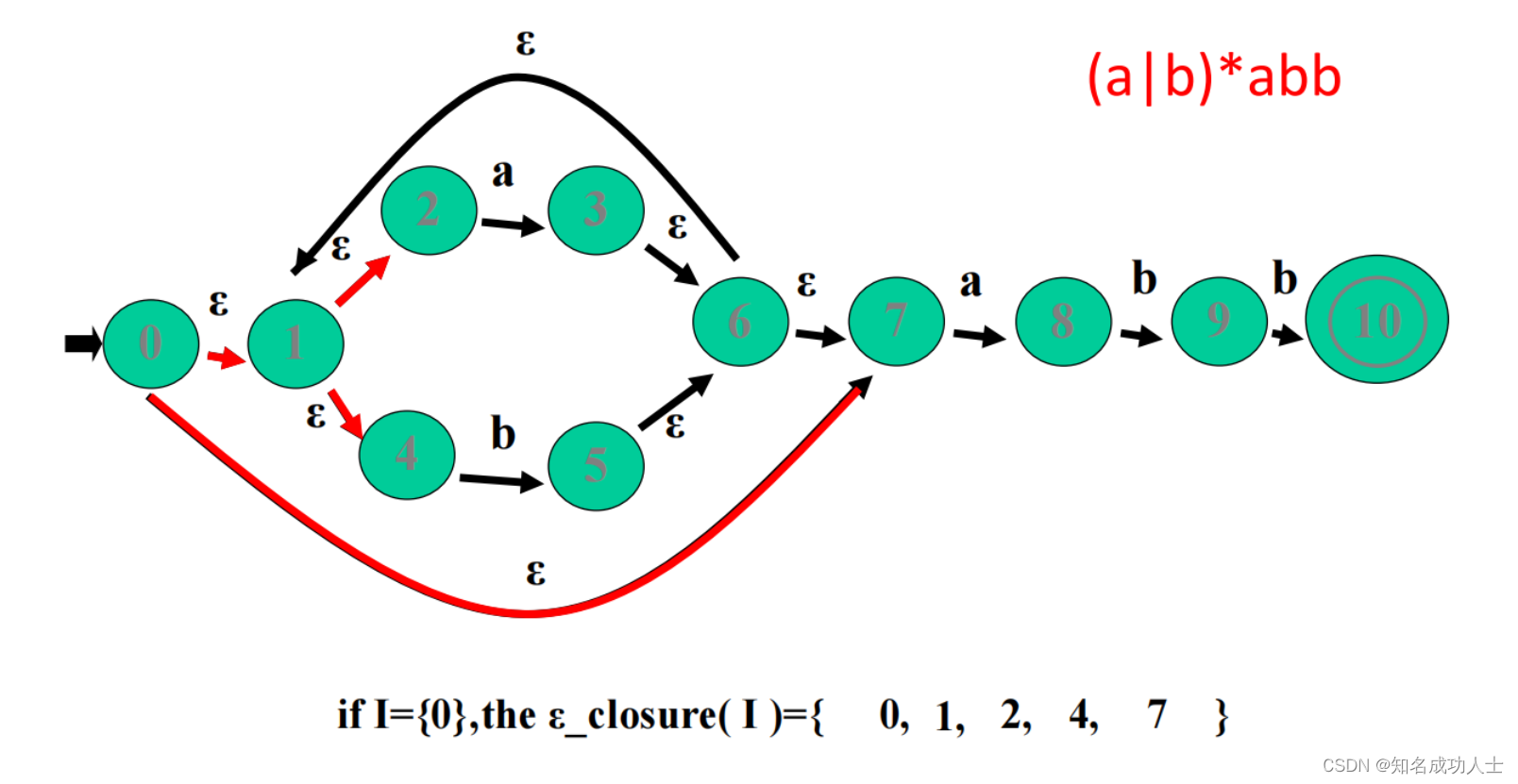
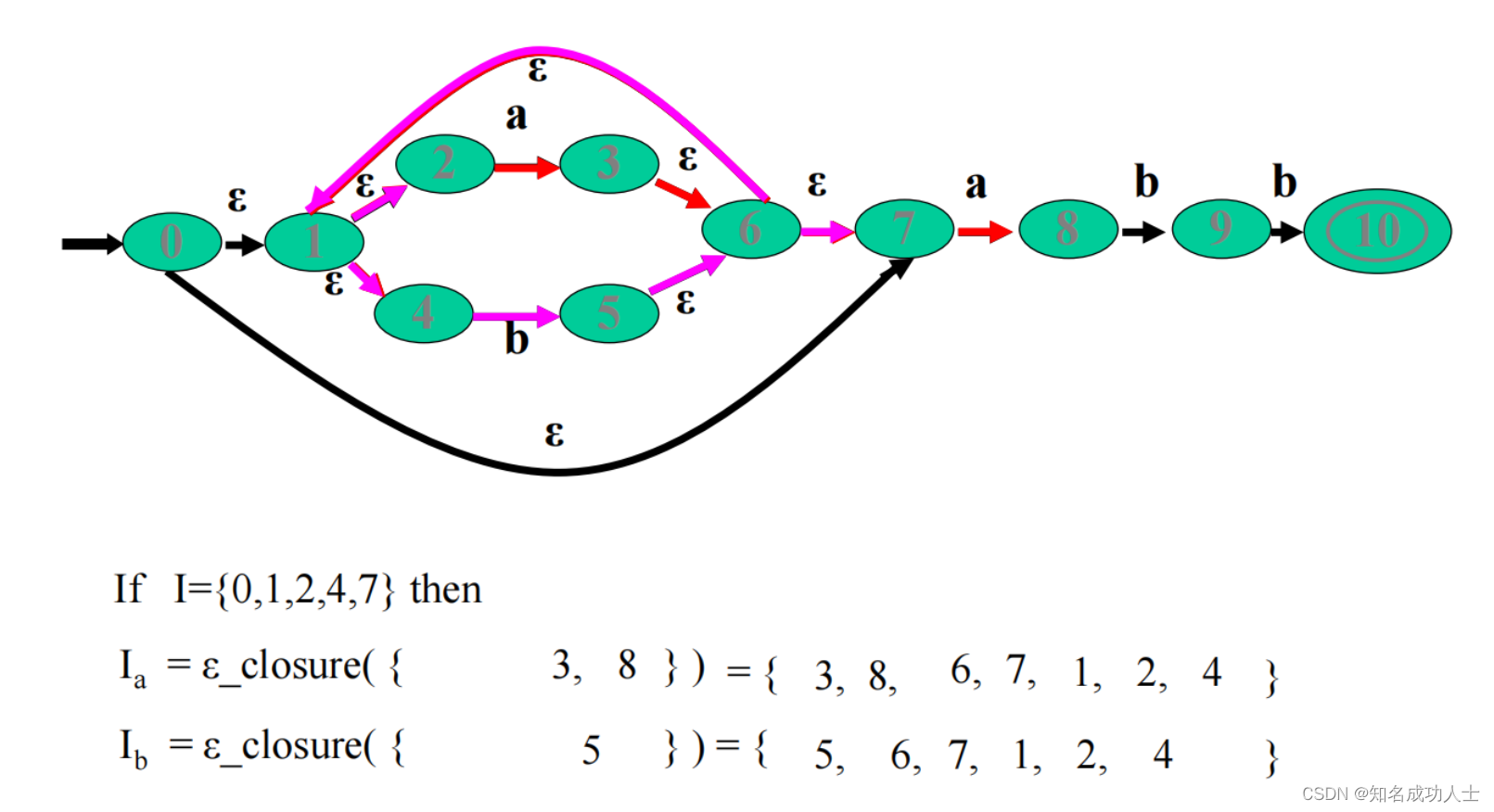
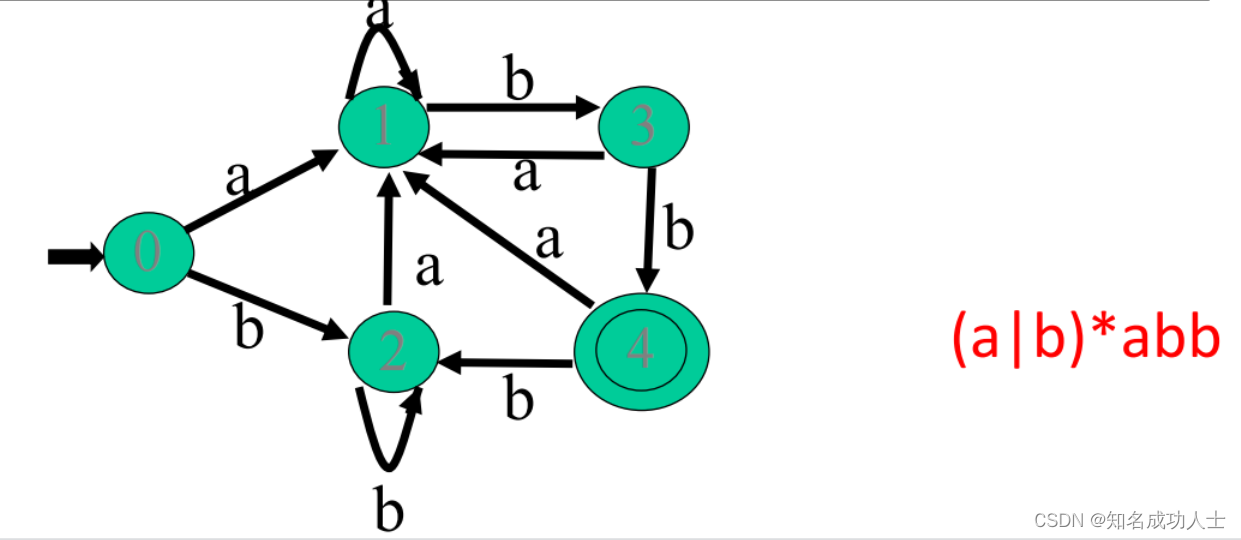
下面我们来了解子集构造法(Subset Construction):DFA的状态是原来对应的NFA的状态集——也就是说,我们使用DFA的一个状态来替换通过从单个输入字符上的状态转换所达到的NFA的状态集。 例如:这里有一个NFA,对应的正则表达式是:(a|b)*abb
从初始状态0开始,第一个接收ε的状态集是{0,1,2,4,7},所以将他们合并成一个状态。然后同理:
之后我们计算每一个新状态Sa,(a∈Σ)。这定义了新的转换:S 对于我们上面的例子,可以得到这样的转换表:
通过重命名DFA的状态集,我们得到:
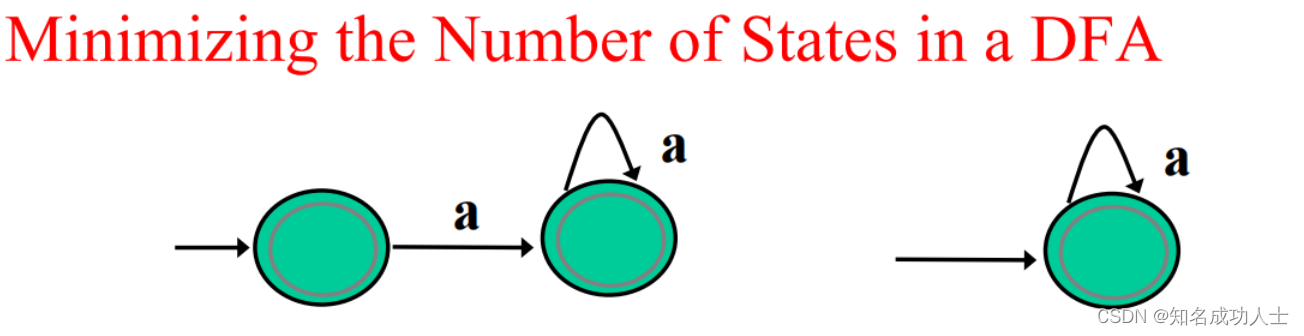
需要注意的是,我们需要最小化DFA的状态数。给定任何DFA,有一个等效的DFA包含最小状态数,并且这个最小状态DFA是唯一的。
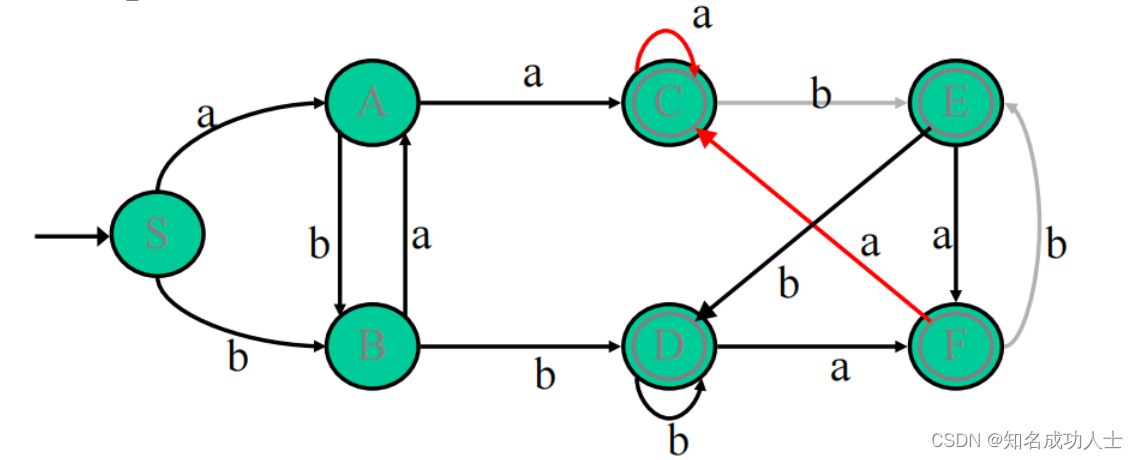
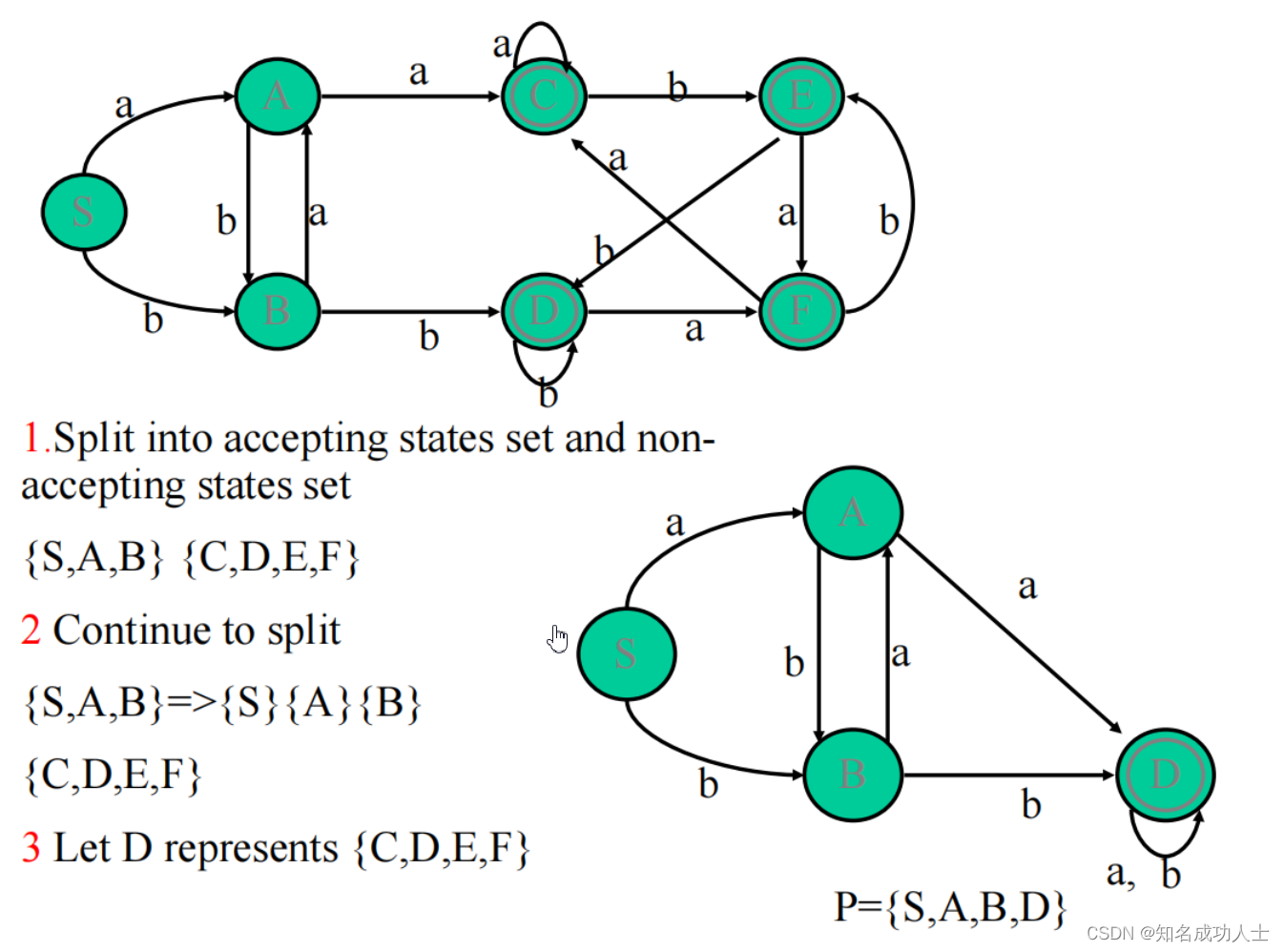
在NFA到DFA中判断等价状态: 如果s和t是两个状态,它们仅在以下情况下等价: s和t都是接受状态或都是非接受状态。对于Σ中的每个字符a,s和t都有连接到等价状态的转换。例如:
C和F都是接受状态。它们在a到C上有转换,在b到E上有转换,所以它们是等价的状态。 Minimizing Algorithm : Minimizing Algorithm :首先,将状态集分成两组,一个由所有接受状态组成,另一个由所有不接受状态组成。然后再确认子集该不该被继续分割,即判断里面的状态是不是都是等价的。 还是我们上面的例子,我们对他进行最小化:
|


【本文地址】