Sora 与文本到视频生成,探索通用人工智能的里程碑与挑战! |
您所在的位置:网站首页 › 腾讯的智能生成视频怎么实现的 › Sora 与文本到视频生成,探索通用人工智能的里程碑与挑战! |
Sora 与文本到视频生成,探索通用人工智能的里程碑与挑战!
 在取得令人印象深刻的成就后,人工智能正朝着通用人工智能的方向迈进。由OpenAI开发的Sora,其具备分钟 Level 的世界模拟能力,可以被视为这一发展路径上的一个里程碑。然而,尽管Sora取得了显著的成功,它仍然遇到了各种需要解决的障碍。 在本次调查中,作者从解构Sora在文本到视频生成方面的角度出发,进行了全面的文献回顾,试图回答这个问题:“从Sora作者能看到什么”。 具体来说,在介绍了关于通用算法的基本预备知识之后,文献从三个相互垂直的维度进行分类:进化生成器、卓越追求和现实全景。随后,详细整理了广泛使用的数据集和评价指标。 最后但同样重要的是,作者识别了该领域内的几个挑战和开放性问题,并提出了潜在的研究和开发未来方向。 本调查中全面的文本到视频生成研究列表可在https://github.com/soraw-ai/Awesome-Text-to-Video-Generation获取。 1 Introduction近期在AI生成内容(AIGC)领域的快速发展标志着向实现人工通用智能(AGI)迈出的关键一步,特别是继OpenAI在2023年初推出大型语言模型(LLM)GPT-4之后。AIGC 吸引了学术界和工业界的广泛关注,例如基于LLM的对话代理ChatGPT[1],以及文本转图像(T2I)模型如DALLLE[2],Midjourney[3]和Stable Diffusion[4]。这些成果对文本转视频(T2V)领域产生了重大影响,OpenAI的Sora[5]在图1中展示的出色能力便是例证。  如[5]所述,Sora被设计为一个复杂的世界模拟器,根据文本指令创作出真实和富有想象力的视频。其卓越的扩展能力使其能够有效地从互联网规模的数据中学习,这是通过整合DiT模型[6]实现的,该模型取代了传统的U-Net架构[7]。这种战略性的整合使Sora与GenTron[8],W.A.L.T[9]和Latte[10]的进展相似,增强了其生成能力。 独特的是,Sora有能力生产高质量的一分钟长视频,这是现有T2V研究尚未实现的。它还在生成分辨率更高、质量更流畅的视频方面表现出色,与现有T2V方法的进展并行。 尽管Sora在生成复杂目标方面显著提高了性能,超过了之前的工作,但在确保这些目标之间的连贯运动方面仍面临挑战。然而,必须认识到Sora在渲染具有复杂细节的场景方面具有卓越的能力,无论是主体还是背景,都优于之前专注于复杂场景和合理布局生成的研究。 据作者所知,有两篇与作者的研究相关的调查文章:涵盖了从视频生成到编辑的广泛主题,提供了一个总体概述,但只关注有限的基于扩散的文本转视频(T2V)技术。同时,[47]对Sora进行了详细的技术分析,提供了相关技术的基本调查,但在T2V领域的深度和广度上有所欠缺。作为回应,作者的工作旨在填补这一空白,通过提供对T2V方法的详尽审查,基准数据集,相关挑战和未解决的问题,以及潜在的未来方向,从而为该领域提供更细腻和全面的观点。 贡献:在这篇调查文章中,作者重点对文本转视频生成领域进行了详尽的审查,通过深入分析OpenAI的Sora。作者系统地追踪和总结了最新文献,提炼出Sora的核心要素。本文还阐释了基础概念,包括这一领域至关重要的生成模型和算法。作者深入探讨了调查文献的具体内容,从所采用的算法和模型到生成高质量视频的技术。此外,本调查还提供了对T2V数据集和相关评估指标的广泛调查。重要的是,作者揭示了T2V研究的当前挑战和未解决的问题,并根据作者的见解提出了未来的发展方向。 章节结构:本文的组织结构如下: 在第2部分,作者提供了一个基础概述,包括T2V生成的目标以及支撑这一技术的核心模型和算法。 在第3部分,作者主要根据对Sora的观察,提供了所有相关领域的广泛概述。 在第4部分,作者进行了详细的分析,强调T2V研究中的挑战和未解决的问题,特别是从Sora中获得的见解。 第5部分专门概述了基于作者对现有研究和Sora关键方面的分析的未来发展方向。论文在第6部分达到高潮,作者提出了作者的结论性观察,综合了从作者全面审查中获得的见解和启示。 2 PreliminariesNotations给定一个由 个视频和相关文本描述集合 组成的集合,每个视频 包含 帧图像 ,其中 是颜色带的数量, 和 是一帧图像的高度和宽度中的像素数量,而 反映了时间维度。 在输入提示 的引导下,文本到视频(T2V)的目标是通过设计的生成器生成合成视频 。 Foundational Models and Algorithms以下是“基础模型与算法”部分的开始: 标题:NLP世界发生了什么变化?基础大模型LLM的出现 摘要:基础大模型LLM的出现是什么意思?自然语言处理(Natural Language Processing, NLP)是计算机科学和人工智能的一个领域,它致力于使计算机能够理解、解释和生成人类语言。 标题:语言学可以为大语言模型(LLM)和自然语言处理(NLP)提供哪些支持 摘要:大型语言模型的介绍:得益于大型语言模型,计算机理解语言的能力得到了极大的提升... 标题:质量的形成机制@无重力模型 (Gravity-free models) 摘要:无重力模型 (Gravity-free models) 术色荷模型通过规范场破坏了电弱对称性,该模型最初在量子色动力学中被定义,并定义了W和Z玻色子的质量形成机制。日期:2018-03-03 柯尔曼温伯格模型 柯尔曼-温伯格模型通过自发对称性破缺和辐射修正产生质量。 2.2.1 Generative Adversarial Networks (GAN)GAN是一种无监督的机器学习模型,通过一个由两个神经网络组成的系统在一个零和游戏框架中相互竞争来实现[48]。GAN由生成器和判别器组成,其中生成器的任务是产生与真实数据(如图像)无法区分的数据,而判别器的任务是区分生成器的假数据和真实数据[49, 50]。 GAN的优化目标涉及两个实体:生成器和判别器之间的最小-最大游戏。总体目标优化函数表述为: 其中价值函数定义为: 在这个框架中,生成器旨在最小化判别器做出正确决策的概率。相反,判别器则努力最大化其正确识别生成器输出的概率。真实数据从数据分布中抽取,生成器的输入从先验分布中抽取,这通常是均匀分布或高斯分布。期望算子表示在相应概率分布上的期望值。 这种对抗过程涉及在优化判别器以区分真实数据与假数据,以及优化生成器以产生判别器将分类为真实的数据之间交替进行。这种训练过程一直持续到生成器产生的数据非常接近真实数据,以至于判别器无法再区分两者为止。 2.2.2 变分自编码器(VAE)VAE是一类深度生成模型的类别,其设计基于贝叶斯推理的原则,为学习数据的潜在表示提供了一种结构化的方法[51]。一个VAE主要由两个组件组成:编码器和解码器。编码器通常通过神经网络实现,通过将输入数据映射到潜在空间中的概率分布来工作。相反,解码器也作为神经网络实现,旨在从这种潜在表示重建输入数据,从而使模型能够捕捉到潜在的数据分布。 考虑一个数据集,它由个从分布中独立同分布(i.i.d.)抽取的样本组成。VAE的目标是使用参数化分布模型来近似这个分布,其中表示模型的参数。通过引入潜在变量,实现了这种近似,联合分布表示为: 这里,是潜在变量的先验分布,通常选择为标准高斯分布。项表示似然,由解码器网络建模。编码器通过将后验近似为变分分布来促进这一过程,其中表示编码器的参数。 训练VAE的根本目的是最大化观察数据的边缘似然的证据下界(ELBO),其表述为: 其中第一项是重建损失,鼓励解码后的样本与原始输入相匹配,第二项是近似后验与先验之间的Kullback-Leibler散度,起规范化的作用。通过优化ELBO,VAEs学会在重建保真度与潜在表示的复杂性之间保持平衡,使它们能够生成与观察数据一致的新样本。 2.2.3 Diffusion Model扩散模型[52]是经过精心设计的生成模型,它们通过反转扩散过程来生成数据,正如Ho等人在他们2020年关于去噪的研究中描述的那样。这些模型逐步向数据中引入噪声,最终通过一系列特定的步骤将其转化为高斯分布。这个转换由一组潜在变量的马尔可夫链表示,其中表示初始数据,表示完全噪声化的数据。正向扩散由一系列转换概率表征,这些概率系统地将在数据中引入噪声: 其中是预先定义的小方差,它们逐渐增强噪声。 **去噪扩散概率模型(DDPM)[52]**,如[52]中所述,是扩散模型的一个突出子集。它们将生成过程解释为一种反向扩散,这种扩散按顺序净化数据,将随机噪声重新转换成预期分布的样本。DDPM确定了一个去噪函数来估计在每一步中加入的噪声,其反向机制由以下公式定义: 图2:不同生成器的说明。 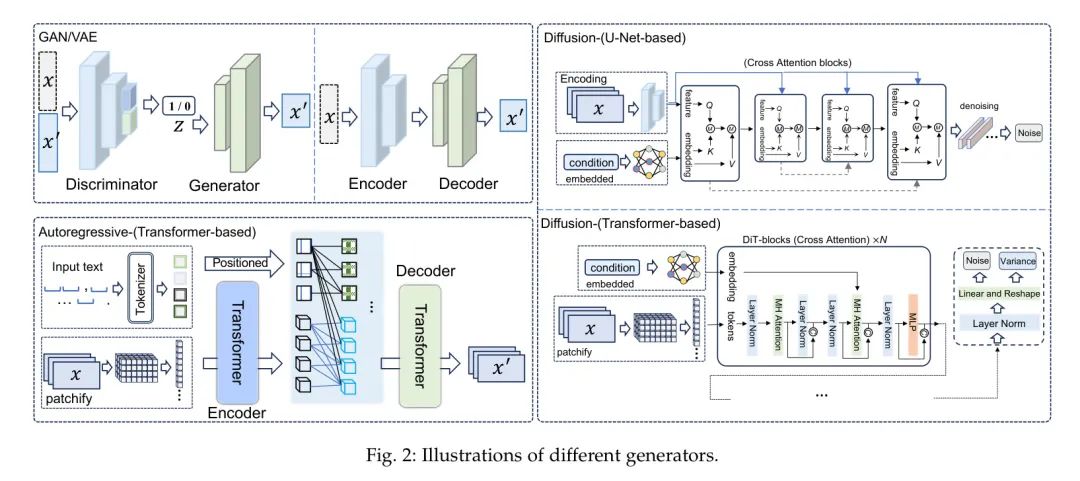 其中和是由神经网络确定的函数,它们逐步净化数据。训练的主要目标是通过优化变分下界来提高神经网络,减少噪声数据与其去噪版本之间的差异。DDPM的关键洞察是扩散过程的反转,这需要估计反向条件概率。通过训练神经网络在各个阶段消除噪声,该模型能够通过重复应用所学的去噪函数,从纯粹的噪声中生成高质量的样本。 2.2.4 Autoregressive Models自回归(AR)模型是一类用于理解和预测时间序列中未来值的统计模型[53]。自回归模型的基本假设是,当前观测值是先前观测值的线性组合加上一些噪声项。阶数为的自回归模型的通用形式,记作AR(),可以表示为: 其中是时间序列的当前值。是模型的参数。是时间序列的前个值。是白噪声,它是一系列具有零均值和恒定有限方差的互不相关随机变量。 在神经网络领域,自回归模型已经被扩展用来模拟数据中的复杂模式。它们是各种架构的基础,特别是在序列建模和生成建模任务中。通过捕获序列中元素之间的依赖关系,自回归模型可以生成或预测序列中的后续元素,这使得它们在语言建模、时间序列预测和生成图像建模等应用中至关重要。 2.2.5 TransformersTransformer模型[54]依据自注意力、多头注意力和位置前馈网络的原则进行操作。 自注意力机制使模型能够优先处理输入序列的不同部分。它使用以下方程计算注意力得分: 在这里,、和分别对应 Query 、键和值矩阵,这些矩阵来源于输入嵌入,是键的维度。 多头注意力机制通过将不同的学习投影应用于 Query 、键和值次,增强了模型关注不同位置的能力,同时执行注意力函数。结果被连接起来并进行线性变换,如下所示: 其中 、、和是学习的参数矩阵。 位置前馈网络包含在Transformer的每一层中,对每个位置同等应用两个线性变换和中间的ReLU激活: 线性变换的权重和偏置由、、和表示。 层归一化和残差连接被使用,Transformer在每个子层周围添加残差连接,然后进行层归一化。输出由以下公式给出: 其中是由子层本身实现的函数。 位置编码被合并到输入嵌入中,以提供位置信息,因为模型缺乏循环或卷积。这些编码与嵌入相加,定义如下: 在这里,_pos_表示位置,是维度。 3 From Sora What We Can See在文本到图像技术取得重大突破之后,人类已经进入了更具挑战性的文本到视频生成领域,这一领域能够传达和封装更丰富的视觉信息。尽管近年来这个领域的研究进展缓慢,但Sora的推出极大地重新点燃了乐观情绪,标志着该领域的重大转变,为研究势头注入了新的活力。 因此,在本节中,作者将作者从Sora特别是T2V生成领域看到的关键洞察系统地分为三个主要类别,并对每个类别提供详细的评论:_进化生成器_(见第3.1节),_卓越追求_(见第3.2节),_真实全景_(见第3.3节)以及_数据集和指标_(见第3.4节)。全面的架构如图3所示。 Evolutionary Generators技术报告展示了前沿的Sora[5]虽然在生成的视频方面相比现有作品有了显著的飞跃,但文本到视频(T2V)生成器的算法设计进步一直是谨慎递增的。Sora主要通过复杂的拼接和精细的优化技术改进现有作品,从而推动了该领域的发展。这一观察强调了全面审视当前可用的T2V算法的重要性。通过检查支撑当代T2V模型的基础算法,作者将它们分为三个主要框架:基于GAN/VAE的、基于扩散的,以及基于自回归的。 3.1.1 GANVAE-based在文本到视频领域的初期探索阶段,研究行人主要致力于基于神经网络(NN)设计生成模型,例如变分自编码器(VAE)[55, 56, 57, 58] 和生成对抗网络(GAN)[59, 60, 58]。这些开创性的努力为从文本描述直接理解和开发复杂的视频内容奠定了基础。 在从文本描述自动生成视频的开创性工作中,文献[55]的作者提出了一种创新方法,将VAE与循环注意力机制相结合。这种方法根据文本输入生成随时间演变的帧序列,独特地关注每个帧同时学习整个视频的潜在分布。尽管这一方法具有创新性,但VAE框架面临一个显著挑战,即“后验崩溃”。为了缓解这一问题,文献[56]引入了VQ-VAE模型,这是一种结合了离散表示的优势和连续模型有效性的创新模型。通过使用向量量化,VQ-VAE在生成高质量图像、视频和语音方面表现出色。同样,基于在HowTo100M[61]数据集上预训练的VQ-VAE架构,GODIWA[57]展示了其能够在下游视频生成任务上进行微调,并具有出色的零样本能力。 与直接从文本输入生成视频不同,文献[60]的作者提出了TGANs-C,这是一种从文本标题创建视频的方法。这种方法融合了一种新颖的方法论,包括3D卷积和一个多组件损失函数,确保视频在时间上连贯并且在语义上与标题保持一致。在扩展这些创新的基础上,文献[58]提出了一种先进的混合模型,结合了VAE和GAN,能够从文本描述中有效地捕捉静态属性(例如,背景设置和目标布局)和动态元素(例如,物体或角色的动作)。这个模型将视频生成从简单的文本输入提升到了基于文本叙述的更复杂、更微妙的视频内容创作。作为这一进展的补充,文献[59]创新地将GAN与长短期记忆(LSTM)[62]网络结合,显著提高了文本生成视频的视觉质量和语义连贯性,确保了生成内容与其文本描述之间的紧密对齐。 3.1.2 Diffusion-based图4:基于基础算法的文本到视频生成器演变时间线。 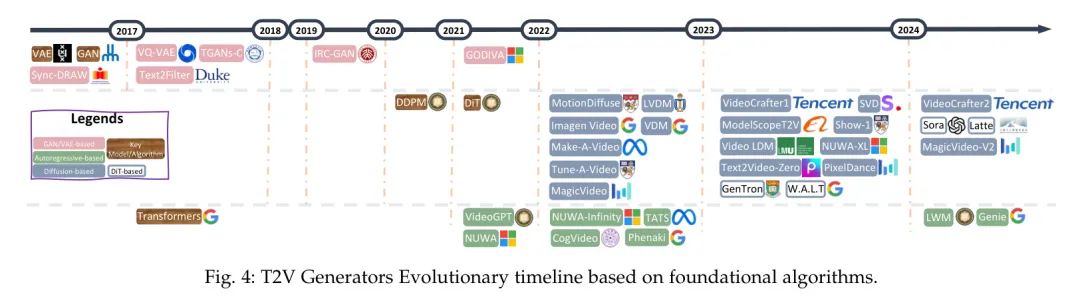 在Ho等人[52]的开创性论文中,引入了扩散模型,这是文本到图像(T2I)生成领域的重大里程碑,推动了如DALLE[2],视频扩散模型(VDM)[64]等开创性模型的发展,这些模型在文本到视频生成方面取得了重大进步,显著提升了标准的图像扩散方法以适应视频数据。VDM解决了在生成高保真视频中时间连贯性的关键挑战。通过创新采用3D U-Net[65]架构,该模型专为视频应用定制,将传统的2D卷积增强到3D,同时整合时间注意力机制以确保生成时间上连贯的视频序列。这一设计保持了空间注意力并融入时间动态,使模型能够生成连贯的视频序列。同样地,MagicVideo[66]及其后续版本MagicVideo-V2[66]在文本到视频生成方面也具有重要意义,它们利用潜在的扩散模型来解决数据稀缺、复杂的时空动态和高计算成本等挑战。MagicVideo采用基于3D U-Net的架构,并通过视频分布 Adapter 和定向时间注意力等增强功能,实现了高效、高质量的视频生成,保持了时间连贯性和真实性。它在一个潜在空间中运行,专注于关键帧生成和高效视频合成。MagicVideo-V2在此基础上构建,采用多阶段流程,包括文本到图像、图像到视频、视频到视频和视频帧插值的模块。 潜在空间的利用是多个模型的共同主题。LVDM[14]提出了一种分层的潜在视频扩散模型,将视频压缩到低维潜在空间中,从而有效生成长视频并减少计算需求。传统的框架局限于生成短视频,其长度由训练阶段提供的输入帧数量预先确定。为了克服这一限制,LVDM引入了条件性潜在扩散方法,根据之前的潜在代码以自回归方式生成未来的潜在代码。Show-1[28],PixelDance[67]和SVD[63]同时利用基于像素和基于潜在的技术生成高分辨率视频。Show-1从基于像素的VDM生成精确的低分辨率关键帧开始,然后使用基于潜在的VDM进行高效的高分辨率视频增强,利用两种方法的优势确保高质量、计算效率高的视频输出。PixelDance建立在潜在扩散框架之上,该框架训练以在预训练VAE的潜在空间中对扰动输入进行去噪,旨在最小化计算需求。其底层结构是一个2D UNet扩散模型,通过融入时间层,包括1D卷积和沿时间维度的注意力,增强为3D变体,使其适用于视频内容同时保持对图像输入的有效性。这个模型能够与图像和视频联合训练,通过有效整合空间和时间分辨率确保高保真输出。SVD将时间卷积和注意力层融入预训练的扩散架构中,使其能够有效地捕捉随时间的变化。Tune-A-Video[68]通过融入时间自注意力来捕捉帧间的一致性,进一步扩展了这些概念,优化了计算资源。特别是,Tune-A-Video旨在解决计算成本问题,并将2D潜在扩散模型(LDM)扩展到时空领域以促进T2V生成。[68]中的研究行人创新地在网络中的每个 Transformer 块中添加了一个时间自注意力层,使模型能够捕捉视频帧之间的时间一致性。这一设计得到了稀疏时空注意力机制和选择性调整策略的补充,后者只更新注意力块中的投影矩阵,优化了计算效率并保留了T2I模型预先学习的特征,同时确保了生成视频中时间上的连贯性。 在视频增强领域,VideoLCM [69]模型被设计为一个潜在一致性模型,通过一致性精馏策略进行优化,旨在减少计算负担并加速训练。它利用大规模预训练的视频扩散模型来提高训练效率。该模型采用DDIM [70]求解器来估计视频输出,并融入无分类器引导来合成高质量内容,使其能够以最少的采样步骤实现快速高效的视频合成。VideoCrafter2 [71]模型独特地设计用来增强视频扩散模型中的时空连贯性,采用了一种创新的数据级解纠缠策略,将运动方面与外观特征仔细分离。这种策略性的设计促进了针对高质量图像的目标性微调过程,旨在大幅提升生成内容的视觉真实性,同时不损害运动动态的精确度。这种方法建立在并显著改进了VideoCrafter1 [72]的基础工作上,后者结构为一个潜在视频扩散模型(LVDM),包含视频变分自编码器(VAE)和视频潜在扩散过程。视频VAE将视频数据压缩到低维潜在表示中,然后由扩散模型处理以生成视频。 像Make-A-Video [73]和Imagen Video [74]这样的模型将文本到图像技术扩展到视频领域。Make-A-Video模型利用T2I技术的进步并将其扩展到视频领域,无需成对的文本-视频数据。 它围绕三个核心组成部分设计:一个T2I模型、时空卷积和注意力层以及一个帧插值网络。 最初,它利用在文本-图像对上训练的T2I模型,然后通过融入新颖的时空层来引入时间动态,最后使用帧插值网络来提高生成视频的帧率和流畅度。Imagen Video采用专为T2V合成设计的复杂级联视频扩散模型架构。这种设计将基础视频扩散模型与后续的空间和时间超分辨率模型精细结合,全部基于文本提示条件,逐步提升生成视频的质量和分辨率。该模型创新的结构使其能够生成不仅在真实性和分辨率上高,而且具有强时间连贯性并与描述性文本对齐的视频。MotionDiffuse [75]:文本驱动的人体动作生成,特别是对生成动作的多样性和细致控制的需求。它利用一个定制设计的扩散模型,通过跨模态线性 Transformer 将文本描述与动作生成结合起来。它能够对生成的动作进行细致控制,允许独立控制身体部位和时间变化序列,确保输出动作多样且真实。Text2Video-Zero [76]建立在稳定扩散T2I模型之上,专为零样本T2V合成而定制。核心改进包括向潜在代码中引入运动动态以保证时间一致性,并采用跨帧注意力机制确保帧间目标外观和身份的保持。这些修改使得能够从文本描述生成高质量、时间上连贯的视频序列,无需额外的训练或微调,利用预训练T2I模型的现有能力。 NUWA-XL [25]引入了一种新颖的“扩散之上扩散”架构,用于生成极长视频。它解决的主要问题是现有方法在长视频生成中的低效和质量差距,NUWA-XL的架构创新地采用了“由粗到精”的策略。它从一个全局扩散模型开始,生成勾勒视频粗结构的的关键帧。随后,局部扩散模型细化这些关键帧,并在它们之间填充详细内容,使系统能够高效生成既有全局连贯性又有细粒度细节的视频。 与微调预训练模型的方法不同,Sora 旨在从零开始训练扩散模型,这是一项更具挑战性的任务。受到 Transformer 架构可扩展性的启发,OpenAI 将 DIT [6] 框架整合到其基础模型架构中,OpenAI 将扩散模型从传统的 U-Net [7] 转变为基于 Transformer 的结构,利用 Transformer 的可扩展能力高效地训练大量数据,并处理复杂的视频生成任务。同样,为了通过整合 Transformer 和扩散模型来提高训练效率,Genton [8] 在 DiT-XL/2 结构的基础上进行构建,将潜在维度转换为通过 Transformer 块处理的非重叠标记。该模型的创新之处在于其文本条件设置,采用自适应层归一化和跨注意力机制来整合文本嵌入,并增强与图像特征交互。GenTron 的一个重要方面是其可扩展性;GenTron-G/2 变体将模型扩展到超过30亿个参数,重点关注 Transformer 块的深度、宽度和MLP宽度。与此同时,W.A.L.T [9] 基于一个两阶段过程,结合了自编码器和一种新颖的 Transformer 架构。最初,自编码器将图像和视频压缩到一个低维潜在空间中,使得在组合数据集上的训练变得高效。 Transformer 采用窗口限制的自注意力层,在空间和时空注意力之间交替,显著降低了计算需求,同时支持图像视频联合处理。这种结构能够从文本描述生成高分辨率、时间上连贯的视频,展示了在 T2V 合成方面的一种创新方法。Latte [10] 进一步通过使用一系列 Transformer 块来处理通过预训练变分自编码器获得的视频数据的潜在空间表示,来扩展这些创新。这种方法有效地建模了视频数据中固有的复杂分布,创新地处理了空间和时间维度。 3.1.3 Autoregressive-based近期在T2V生成领域的进展同样突出了基于自回归的 Transformer 模型,它们因在处理顺序数据和高可扩展性方面的卓越效率而受到认可。这些特性对于建模视频生成任务中复杂的时间动态和高维数据特征至关重要。 Transformer [77]特别有利,因为它们能与现有的语言模型无缝集成,这促进了连贯且情境丰富的多模态输出的创造。这一领域的一个显著发展是NUWA[78],它将一个3D Transformer 编码器-解码器框架与一个专门的3D邻近注意力机制相结合,通过处理1D、2D和3D维度的数据,实现高效和高质量图像与视频的合成,展示了出色的零样本能力。在此基础上,NUWA-Infinity[79]引入了一种创新的自动回归之上的自动回归框架,擅长生成可变大小、高分辨率的视觉内容。它结合了全局块 Level 与局部标记 Level 的模型,通过邻近上下文池和任意方向控制器增强,以确保视觉内容生成的无缝、灵活和高效。 进一步扩展这些能力,Phenaki[13]以其独特的C-ViViT编码器-解码器结构扩展了这一范式,专注于从文本输入生成可变长度的视频。该模型将视频数据高效地压缩成一个紧凑的标记化表示,便于产生连贯、详细且时间上一致的视频。同样,VideoGPT[77]是一个创新性地结合了VQ-VAE和Transformer架构来应对视频生成挑战的模型。它使用VQ-VAE通过3D卷积和轴向注意力学习视频的下采样离散潜在表示,创建了一个紧凑且高效的视频内容表示。这些学到的潜在表示随后用 Transformer 进行自回归建模,使模型能够捕捉视频序列中的复杂时间和空间动态。 大型世界模型(LWM)[80]代表了向前迈出的另一步,它被设计为一个处理长上下文序列的自回归 Transformer ,融合视频和语言数据进行多模态理解和生成。其设计的关键是环注意力机制,它解决了处理多达100万个标记的计算挑战,在最小化内存成本的同时最大化上下文意识。该模型采用了VQGAN进行视频帧标记化,将这些标记与文本整合以进行全面的序列处理。另一方面,Genie[81]模型被设计成一个生成交互式环境工具,它在所有组件中采用了时空(ST) Transformer ,利用新颖的视频标记器和因果动作模型提取潜在动作,然后传递给动力学模型。这个动力学模型自回归地预测下一帧,采用ST- Transformer 架构平衡模型容量与计算效率。该模型的设计利用了 Transformer 在处理视频数据的顺序和时空方面的优势,以生成可控和交互式的视频环境。 TATS[12]是专门为生成长时长视频而设计的,解决了在扩展序列中保持高质量和连贯性的挑战。该模型架构创新地结合了一个时间无关的VQGAN,确保视频帧的质量而不依赖时间,以及一个时间敏感的 Transformer ,捕捉长期的时间依赖关系。这种双重方法使得能够生成高质量、连贯的长视频,为视频合成领域设定了新的标准。 CogVideo[82]集成了一个多帧率分层训练方法,从预训练的T2I模型CogView2[83]适应而来,以增强T2V合成。这个设计继承了CogView2中的文本-图像对齐知识,用它来从文本生成关键帧,然后插值中间帧以创建连贯的视频。该模型的 双通道注意力机制和递归插值过程允许生成详细且语义上一致的视频。 Excellent PursuitSora展示了其出色的视频生成能力,从所展示的演示中可以看出,其具有长时程、高分辨率和流畅性[84]。基于这些优点,作者将当前的研究工作分为三个方向:_扩展时长_、_更高分辨率_和_无缝质量_。 3.2.1 Extended Duration与短视频生成或图像生成任务相比,长期视频生成更具挑战性,因为后者需要建模长期的时间依赖性并在更多帧中保持时间一致性[5]。 具体来说,随着生成视频时长的延长,一个障碍是预测误差会累积。为了应对这样的挑战,引入了回顾机制(LTVR)[11],将回顾帧与观察到的帧保持一致,从而减轻累积的预测误差。TATS[12]通过结合一个时间无关的VQGAN进行高质量帧生成和一个时间敏感的 Transformer 捕捉长期时间依赖,实现了长视频生成的目标。Phenaki[13]被提出用于从开放领域文本描述生成视频。通过结合设计的因果注意力,它能处理可变长度视频并扩展视频以新提示生成更长的序列。LVDM[14]提出了一种用于生成更长视频的分层框架,能够生成超过一千帧的视频。通过利用T2I模型进行视觉学习以及无监督视频数据进行运动理解,Make-A-Video[73]可以在不需要成对的文本-视频数据的情况下生成高保真度、多样性的长视频。StyleInV[15]通过利用稀疏训练方法和运动生成器的有效设计,能够生成长视频。通过限制以初始帧为生成空间并采用时间风格码,该方法在长时间内实现了高单帧分辨率和质量以及时间一致性。最近,通过增强片段中的空间时间一致性,Vlogger[16]成功生成了超过5分钟的vlog,而不会失去关于剧本和演员的视频连贯性。MoonShot[17]利用多模态视频块,整合了空间时间层与解耦的跨注意力进行多模态条件处理,并直接使用预训练的Image ControlNet[18]进行精确的几何控制,从而高效地生成具有高视觉质量和时间一致性的长视频,有效处理多样化的生成任务。 此外,受到隐式神经表示(INR)[19]在建模复杂信号方面成功的启发,各种研究在视频生成中引入了INR。例如,DIGAN[20]利用隐式神经表示(INRs)的紧凑性和连续性,合成长分辨率的长视频,而无需对训练进行大量资源投入,允许对长视频进行高效训练。同样,StyleGAN-V[21]通过将视频视为连续信号,可以高效地产生任何长度、任何帧率的视频。此外,从分解的角度来看,各种研究在视频生成过程中处理长期一致性。在GennL-Video[22]中,长视频首先被视为短片段。开发了双向跨帧注意力来相互影响不同的视频片段,从而促进找到长视频生成的兼容去噪路径。SEINE[23]采用了类似的方法,将长视频视为各种场景和不同长度的镜头级视频的组合。通过合成各种场景的长视频,SceneScape[24]被提出用于从文本描述生成长视频,解决视频生成中3D一致性的挑战。NUWA-XL[25]提供了一个基于由粗到精策略的新解决方案,开发了一个“扩散之上的扩散”架构,能够高效连贯地生成极长的视频。MCVD[26]通过自动回归地生成帧块,生成任意长度的视频,允许生产包括长时长内容在内的各种类型视频的高质量帧。 3.2.2 Superior Resolution与低质量视频相比,高分辨率视频无疑具有更广泛的应用潜力,例如在自动驾驶技术背景下的模拟引擎。 另一方面,高分辨率视频生成也对计算资源提出了挑战。考虑到这一挑战,视频潜在扩散模型(Video Latent Diffusion Models, LDM)[27]将现成的预训练图像LDM引入视频生成中,同时避免了过度的计算需求。通过训练一个时间对齐模型,Video LDM可以生成高达12802048分辨率的视频。 然而,LDM在生成精确的文本-视频对齐方面存在困难。在Show-1[28]中,将基于像素和基于潜在的视频扩散模型(Video Diffusion Models, VDM)的优势结合起来,形成了一个混合模型。Show-1利用基于像素的VDM初始化低分辨率视频生成,然后使用基于潜在的VDM进行放大以获得高分辨率视频(高达572320)。最近,STUNet[29]采用空间超分辨率(Spatial Super-Resolution, SSR)模型对基础模型的输出进行上采样。具体来说,为了避免时间边界伪影并确保时间片段之间的平滑过渡,沿时间轴采用多扩散(Multi-Diffusion),这使得SSR网络能够对视频的短片段进行操作,通过重叠像素的平均预测来生成高分辨率视频。从另一个角度来看,视频生成被视为在MoCoGAN-HD[30]中发现问题的轨迹,该框架利用现代图像生成器渲染高分辨率视频(高达10241024)。在文本驱动的人类视频生成任务中,一个视频生成的子领域,Text2Performer[31]通过分解潜在空间以单独处理人类外观和动作,并利用连续姿态嵌入进行动作建模,实现了生成高分辨率人类视频(高达512256)的目标。这种方法确保了外观在帧间保持一致,同时从文本描述中产生时间上连贯且灵活的人类动作。 3.2.3 Seamless Quality在观感方面,高帧率视频比不流畅的视频更具吸引力,因为它避免了常见的伪影,如时间抖动和运动模糊[32]。 深度感知视频帧插值方法(DAIN)[32]被引入,以利用深度信息在插值过程中检测遮挡并优先处理较近的物体。通过涉及一个深度感知流投影层,该层通过优先采样近距离物体而落后于远距离物体来合成中间流,该方法可以解决视频帧中的遮挡和运动挑战。通过结合循环一致性损失以及运动线性损失和边缘引导训练,CyclicGen [33] 在生成高质量插值帧方面取得了卓越的性能,这对于高帧率视频生成至关重要。Softmax-Splatting [34] 中引入了Softmax splatting,以在任何所需的时间位置插值帧,有效地为高帧率视频的生成做出贡献。目前,FLAVR [35] 通过设计一种利用3D时空卷积进行运动建模的架构来应对生成高帧率视频的挑战。此外,为了减轻计算限制,FLAVR 直接从视频数据中学习运动属性,这简化了训练和部署过程。 Realistic Panorama在T2V生成中的一个关键挑战是实现逼真的视频输出。解决这个问题需要关注对真实性至关重要的元素的整合。分解逼真的全景T2V生成,作者确定了以下应考虑的关键组成部分:1. 动态运动 2. 复杂场景 3. 多个物体 4. 合理布局。 3.3.1 Dynamic Motion近年来,尽管在T2I生成方面取得了显著进展,但许多研究行人已经开始将T2I模型扩展到T2V生成,如LAMP [85] 和 AnimateDiff [86]。动作是视频与图像之间的一个关键区别,也是这个不断发展的研究领域的一个重点[87]。LAMP专注于从有限的数据集中学习动作模式。它采用了一种以第一帧为条件的 Pipeline ,利用预训练的T2I模型创建初始帧,使视频扩散模型能够集中学习后续帧的动作。这个过程通过时空调动学习层得到增强,这些层捕捉时间和空间特征,简化了视频中的动作生成。AnimateDiff将预训练的动作模块集成到个性化的T2I模型中,实现了内容对齐的平滑动画制作。该模块使用一种新颖的策略进行优化,从视频数据中学习动作先验,关注动态而非像素细节。"关键创新是MotionLoRA,一种微调技术,它调整这个模块以适应新的动作模式,增强了其适应不同相机运动的灵活性。 动作一致性和连贯性也是动作生成中的关键挑战。与传统模型先生成关键帧然后填充间隙(常导致不一致)不同,Lumiere [29]使用时空U-Net架构一次性生成整个视频。这种方法通过结合空间和时间上的下采样和上采样确保了全局时间一致性,显著提高了动作生成性能。Dysen-VDM [88]集成了一个动态场景管理器(Dysen),分三个协调步骤运作:从文本中提取关键动作,将这些动作转换为动态场景图(DSG),并用上下文场景细节丰富DSG。这种方法使得可以生成时间连贯且上下文丰富的视频场景,与输入文本中描述的预期动作紧密对齐。ARTV [89]专注于一种创新方法,通过按顺序生成视频帧(每帧都基于前帧条件)来应对建模复杂长距离动作的挑战。这种策略确保了连续和简单动作的产生,保持了相邻帧之间的连贯性。DynamiCrafter [90]专注于双流图像注入机制,集成了文本对齐的上下文表示和视觉细节指导。这种方法确保动画内容在视觉上与输入图像保持一致,同时在文本描述上保持动态一致性。 一些工作集中在提高T2V中的动作生成。PixelDance [67]通过结合首尾帧的图像指令和文本指令来丰富视频动态。这种方法使模型能够捕捉复杂的场景转换和动作,增强了生成视频中动作丰富性和时间连贯性。MoVideo [87]使用从关键帧得到的深度和光流信息来指导视频生成过程。首先从文本生成图像,然后从该图像提取深度和光流。MicroCinema [91]采用两阶段过程,首先从文本生成关键图像,然后使用图像和文本引导视频创作,专注于捕捉动作动态。ConditionVideo [92]将视频动作分为背景和前景组件,提高了生成视频内容的清晰度和控制力。DreamVideo [93]将视频生成任务解耦为主体学习和动作学习。动作学习方面专门针对有效地适应模型到新的动作模式。他们引入了一个动作 Adapter ,与外观指导结合使用,使模型能够仅学习动作,而不受主体外观的影响。TF-T2V [94]使能够在不需要文本标注的情况下学习复杂的动作动态,采用图像条件模型有效地捕捉各种动作模式,包括加强帧间连续性的时间连贯损失。GPT4Motion [95]使用GPT-4生成Blender脚本,然后用来驱动Blender的物理引擎,模拟与给定文本描述相对应的真实物理场景。这些脚本与Blender的模拟能力相结合,确保生成的视频不仅在视觉上与文本提示保持一致,而且遵循物理真实性。然而,挑战依然存在,特别是在人类动作生成方面。Text2Performer [31]偏离传统的基于VQ的离散模型,生成连续的姿势嵌入,提高了生成视频中的动作真实性和时间连贯性。MotionDiffuse [75]专注于一种概率策略,使得可以从文本描述中创建多样化、逼真的动作序列。将去噪扩散概率模型(DDPM)与跨模态 Transformer 架构相结合,系统可以生成与文本输入对齐的复杂、连续的动作序列,确保了结果动画的高保真度和精确可控性。 3.3.2 Complex Scene在复杂场景中生成视频极具挑战性,因为这涉及到元素之间错综复杂的相互作用,需要高保真度地理解和复制详细的环境、动态互动和多变的光照条件。在研究的初期阶段,文献[40]中的作者提出了一个结合了新颖的时空卷积架构的GAN网络。这种架构有效地捕捉了场景中前景和背景元素的动态。通过在大量 未标注 视频数据集上训练模型,它学会了从静态图像预测合理的未来帧,从而创造出具有真实场景动态的视频。这种方法使模型能够通过理解和生成场景内不同组件的时间演变来处理复杂场景。 随后,随着LLM(大型语言模型)的发展,研究行人开始利用它们的能力来增强生成模型在制作复杂场景方面的表现。VideoDirectorGPT [41] 利用LLM进行视频内容规划,生成详细的场景描述和实体及其布局,并确保场景之间的视觉一致性。通过采用新颖的Layout2Vid生成技术来确保场景在空间和时间上的一致性,它产生了丰富的、以叙事驱动的视频内容。同样,FlowZero [42] 通过一种新颖的零样本T2V(文本到视频)合成框架,增强了时空布局与文本提示之间的对齐。融合了LLM和图像扩散模型,FlowZero最初将文本提示转化为详细的动态场景语法(DSS),概述场景描述、目标布局和动作模式。然后,它通过自我精化过程根据文本提示迭代地改进这些布局,从而合成具有复杂动作和转换的时空连贯视频。 VideoDrafter [43] 利用LLM将输入提示转换为全面的脚本,识别常见实体,并为每个实体生成参考图像。VideoDrafter然后通过扩散过程考虑参考图像、描述性提示和摄像机移动来生成视频,确保场景之间的视觉一致性。SceneScape [24] 强调在3D场景合成中为更复杂的情景生成视频。使用预训练的文本到图像和深度预测模型确保通过测试时优化过程生成保持3D一致性的视频。它采用了一种渐进策略,在每一帧中不断构建和更新场景的统一网格表示,从而保证了几何上的合理性。 3.3.3 Multiple Objects对于视频中的每一帧,生成多个物体存在几个挑战,例如属性混合、物体混合和物体消失。属性混合发生时,物体无意中错误地采用了其他物体的特征。物体混合和消失涉及不同物体的融合,这导致产生了奇特的混合体和不准确的物体计数。为了解决这些问题,Detector Guidance(DG)[36]集成了一个潜在的目标检测模型,以增强生成图像中不同物体的分离度和清晰度。他们的方法通过操作跨注意力图来精化目标表示,在没有人为干预的情况下显著提高了生成不同物体的效果。 视频合成的复杂性需要捕捉目标之间的动态时空关系。MOVGAN [37]从布局到图像生成的进展中汲取灵感,创新性地采用了隐式神经表示以及自我推理的布局运动技术。这种方法能够生成不仅描绘单个物体,还能准确表示它们随时间的交互和运动的视频,增强了合成视频内容的真实感和深度。 在T2V生成领域,由于属性绑定问题,处理单帧视频内多个主体的视觉特征至关重要。VideoDreamer [38]利用带有潜在代码运动动态和时序跨帧注意力的稳定扩散,并通过Disen-Mix微调以及可选的人机循环重新微调策略进行进一步定制。它成功地生成了高分辨率视频,保持了时间一致性和主体身份,且没有人工痕迹。 UniVG [39]通过为其基础模型增强多条件交叉注意力来应对多目标生成的挑战,以应对需要高度自由的任务,有效地管理了来自文本和图像输入的复杂场景中涉及多个目标的情况。对于自由度较低的任务,它引入了偏置高斯噪声,以更有效地保持内容,帮助执行如图像动画和超分辨率等任务。这些创新使得UniVG能够在各种生成任务中产生语义对齐、高质量的视频,有效地处理多目标场景的复杂性。 3.3.4 Rational Layout确保在文本到视频(T2V)转换中输出高质量视频的关键在于根据文本指令生成合理的布局。Craft [44]旨在从文本描述生成视频,通过学习视频字幕数据来预测场景内实体的时间布局,从视频数据库中检索时空片段,并将它们融合生成场景视频。它包含了布局作曲器,这是一个通过理解实体间空间关系来生成合理场景布局的模型。Craft采用了一种将文本嵌入和场景上下文结合的顺序方法,准确预测角色和目标的位置和比例,从而促进生成视觉连贯且上下文准确的视频。 FlowZero [42]使用大型语言模型(LLMs)生成布局,将文本提示转换为结构化语法,以指导生成时间上连贯的视频。这个过程包括逐帧场景描述、前景目标布局和背景运动模式。特别是对于前景布局,LLMs生成一系列针对每帧的布局,概述了每帧中前景实体的空间排列。这些布局包括定义提示所引用目标位置和大小的边界框。这种结构化方法确保前景目标遵循文本中提供的视觉和时空线索,从而提高视频的连贯性和保真度。 然而,[45]号文献的作者指出,现有模型面临复杂时空提示的挑战,常常导致有限的或错误的动作,例如,它们无法准确表示从左到右过渡的目标。为了解决这些不足,他们提出了LLM引导的视频扩散(LVD),这是一种新颖的方法,通过首先使用大型语言模型(LLM)生成动态场景布局(DSLs),然后使用这些DSLs指导扩散模型进行视频生成,从而增强了从文本提示生成神经视频的性能。这种方法解决了当前模型在生成具有复杂时空动态视频方面的局限性,并在生成与期望属性和运动模式紧密对齐的视频方面取得了显著更好的性能。 Datasets and Metrics3.4.1 Datasets作者全面回顾了T2V数据集,并根据收集的领域将其主要分为六类:_面部_、_公开_、_电影_、_动作_、_指导_和_烹饪_。表1在12个维度上总结了数据集,以下是对每个数据集详细描述: 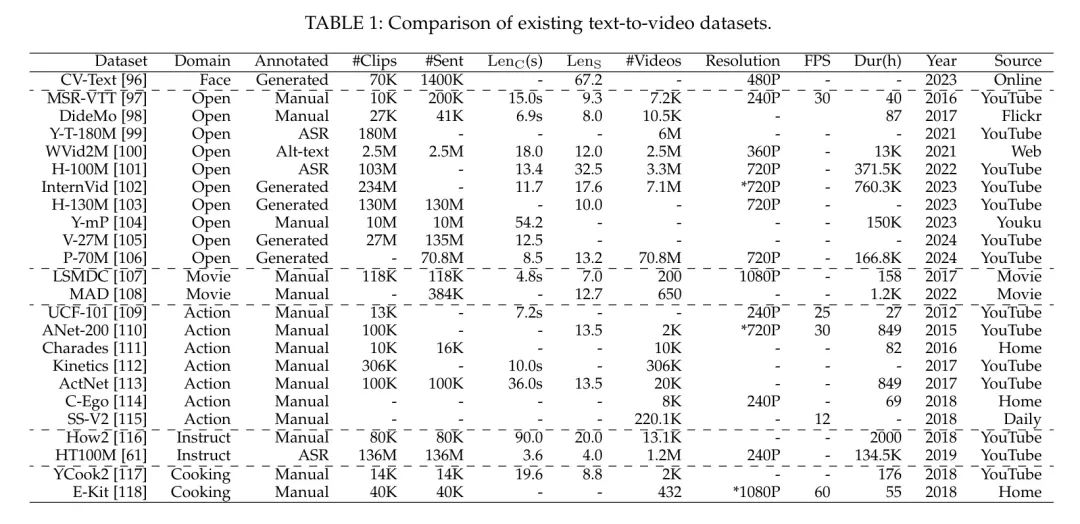 CV-Text [96] 是一个高质量的面部文本视频对数据集,包含70,000个野外面部视频片段,至少有512512的分辨率。每个片段与20个生成的描述配对,平均长度约为67.2。 MSR-VTT [97] 提供了10K个网页视频片段,总共有40小时,200K个片段-句子对。每个片段配有大约20个自然句子进行描述。视频数量约为7.2K,每个片段和句子的平均长度分别为15.0秒和9.3个词。 DideMo [98] 包括超过10,000个未经编辑的个人视频,视觉设置多样,配对有定位的视频片段和参照表达式。 YT-Tem-180M [99] 从600万个公共YouTube视频收集而来,包含1.8亿个片段,并通过自动语音识别(ASR)进行标注。 WebVid2M [100] 包括2.5M个视频-文本对。每个视频和句子的平均长度分别为18.0秒和12.0个词。每个视频的原始描述是从与网页图片关联的Alt-text HTML属性中收集的。 HD-VILA-100M [101] 是一个从YouTube收集的大型文本视频数据集,包含1亿个高分辨率(720P)视频片段和句子对,来自330万个视频,总共有371.5K小时和15个热门类别。 InternVid [102] 是一个以视频为中心的大型多模态数据集,可以用于学习和生成多模态理解和生成的强大且可迁移的视频-文本表示。InterVid包含超过700万个视频,总时长近760K小时,产生2.34亿个视频片段,伴随的总字数达到41亿的详细描述。 HD-VG-130M [103] 包括来自开放领域的高分辨率(1376768)的1.3亿个文本视频对。数据集中的大多数描述约为10个词。 Youku-mPLUG [104] 是首个发布的中文视频语言预训练数据集,从优酷[119]收集,包含从4亿个原始视频中筛选出的1000万个中文视频-文本对,跨越广泛的45个不同类别。每个视频的平均时间约为54.2秒。 VAST-27M [105] 包括总共2.7亿个视频片段,覆盖了多种类别,每个片段配对有11个标题(包括5个视觉、5个音频和1个全模态标题)。视觉、音频和全模态标题的平均长度分别为12.5、7.2和32.4。 Panda-70M [106] 是一个从HD-VILA-100M原始策划的高质量视频-文本数据集。它包括70.8M个视频,总时长为166.8K小时,配有高质量的文本标题。每个视频的时间为8.5秒,每个句子的平均长度为13.2个词。 LSMDC [107] 包含大约118K个与来自200部电影中的句子对齐的视频片段。视频总时长约为158小时,每个片段和句子的平均时长分别为4.8秒和7.0个词。 MAD [108] 来自电影,包含超过384K个句子, Anchor 定在650个视频中的超过1.2K小时上。每个句子的平均长度为13.2个词。 UCF-101 [109] 是一个人体动作数据集,从YouTube [120] 收集的样本包括101个动作类别,包括人体运动、乐器演奏和互动动作。它由超过13K个片段和27小时的视频数据组成。UCF-101的分辨率和帧率为320×240和每秒25帧。 ActNet-200 [110] 提供了总共849小时的视频,其中68.8小时的视频包含203个人体中心活动。大约50%的视频为高清分辨率(1280×720),而大多数视频的帧率为30 FPS。 Charades [111] 来自267个人的家庭活动,包含大约10K个视频,涵盖157个日常动作,平均长度为30.1秒。 Kinetics [112] 包含400个人体动作类别,每个动作至少有400个视频片段。每个片段持续大约10秒,取自不同的YouTube视频。 SS-V2 [115] 是一个大型标记视频片段集合,显示人类使用日常物品执行预定义的174个基本动作。该数据集由大量众包工作者创建,包含大约220.1K个视频。 ActivityNet [113] 包含20K个视频,总计849小时,有100k个总描述,每个描述都有其独特的开始和结束时间。每个句子的长度为13.5个词,描述的平均长度为36秒。 Charades-Ego [114] 总共包含8K个视频(4K对第三人称和第一人称视频)。在这些视频中,超过364对涉及视频中的多个人。每个视频的平均时间为大约31.2秒。 How2 [116] 覆盖了广泛的教学主题。它由80K个片段组成,总计2K小时,每个视频的平均长度约为90秒。 HowTo100M [61] 包含1.36亿个视频片段,收集自1.22M个叙述的教学网页视频,描述人类执行和描述超过23K个不同的视觉任务。每个片段都与自动语音识别(ASR)形式的文本标注配对。 YouCook2 [117] 包含2000个视频,几乎平均分布在89个食谱上,总长度为176小时。这些食谱来自四大菜系(即非洲、美洲、亚洲和欧洲),具有多种烹饪风格、方法、食材和炊具。 Epic-Kitchens [118] 是一个以第一人称视角在厨房环境中由32名参与者录制的视频集。它包含了55小时的视频,总共有大约40.0K个动作片段。大部分视频以全高清分辨率1920×1080录制。 3.4.2 Metrics评估从T2V模型生成的视频质量的标准主要可以分为两个方面:定量和定性。在定量方面,评估者通常会被提供两个或更多生成的视频,以与其他竞争模型合成的视频进行比较。观察者通常参与基于投票的评估,关于视频的真实性、自然连贯性和文本对齐。尽管在多项工作中已经使用了人工评估[68、73、103、121],但耗时且劳动密集型的特点限制了其广泛应用。此外,定性测量有时无法全面评估模型[46]。因此,作者的回顾仅限于定量指标。 这些回顾的指标分为“图像级”和“视频级”。通常,前者用于逐帧评估生成的视频,而后者关注视频质量的综合评估: 峰值信噪比(PSNR)[122]。 通常称为PSNR,用于量化生成视频帧的重建质量。对于一个具有像素的原始图像和生成的图像,PSNR可以计算为: 其中。是原始图像可能的最大值。和表示位置上的像素值。 结构相似性指数(SSIM)[122]。 SSIM通常用于衡量两幅图像之间的相似性,并作为一种从感知角度量化质量的方法。具体来说,SSIM的定义为: 其中用于比较亮度,反映对比度差异,衡量原始图像和生成图像之间的结构相似性。实际上,参数设置为,,。然后,SSIM可以简单地表示为: 其中表示图像的平均值。和分别是和的方差。作者使用表示协方差。最后,是中的最大强度值,并且。 Inception Score (IS) [123]. IS旨在衡量图像生成的质量和多样性。具体来说,采用预训练的Inception网络[124]来获取每个生成图像的条件标签分布。IS可以表示为: 其中KL表示KL散度[125]。 Frechet Inception Distance (FID) [126]. 与IS相比,FID提供了更全面和准确的评估,因为它直接考虑了生成图像与原始图像之间的相似性。 这里,是矩阵的迹。 CLIP Score [127]. CLIP分数被广泛用于衡量图像和句子之间的对齐程度。基于预训练的CLIP嵌入,可以计算为: 其中和分别表示来自图像和句子的嵌入特征,是余弦相似性。 Video Inception Score (Video IS) [128]. 通常,Video IS基于从C3D[129]提取的特征来计算生成视频的IS。 Frechet Video Distance (FVD). 基于从预训练的Inflated-3D Convnets (I3D)[130]提取的特征,可以计算Frechet视频距离(FVD)[131]分数,通过结合均值和协方差矩阵: 这里,作者用和分别表示真实视频和生成视频的期望。 Kernel Video Distance (KVD) [132]. KVD采用核方法来评估生成模型的性能。给定核函数,以及通过预训练的I3D从真实视频和生成视频中提取的特征集合,并结合最大平均差异(MMD),KVD可以表示为: 具体来说,和分别从和中采样。 帧一致性得分(FCS)[68]。 FCS计算视频中所有帧对之间的CLIP图像嵌入的余弦相似度,以衡量编辑视频的一致性。 4 Challenges and Open Problems在本节的开始,作者将概要地回顾所有现有的常见问题,即便是最新的SOTA工作Sora也尚未解决这些问题。 Unsolved Problems from Sora在图5中,基于OpenAI在其网站上展示的视频[84],作者发现了五个弱点。 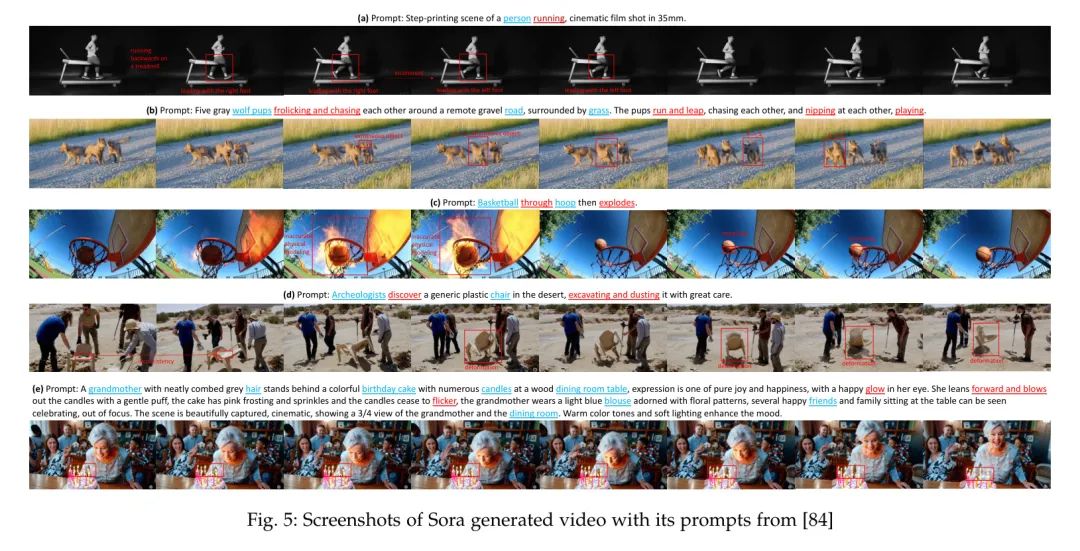 不真实且不连贯的动作:在图5(a)中,作者观察到一个不真实动作的显著例子:一个人似乎在跑步机上向后跑,但矛盾的是,跑步动作实际上是向前的,这在物理上是不可能的情景。通常,跑步机是为向前跑而设计的,如图左侧所示。这种差异突显了T2V合成中的一个普遍问题,即当前的LLM在理解和解释运动物理定律方面表现出色,但在将这些定律准确渲染为视觉或视频格式方面存在困难。 此外,视频还表现出动作的不连贯性;例如,一个人的跑步模式应该显示出一系列连贯的腿部动作。然而,腿部位置却出现了突然的变化,打断了动作的自然流畅。这种帧与帧之间的不一致性又强调了T2V转换中的另一个重大挑战:在整个视频序列中保持动作的连贯性。 物体间歇性出现和消失:在图5(b)中,作者看到一个多物体场景,其特点是物体的间歇性出现和消失,这降低了从文本生成视频的准确性。尽管提示最初指定了“五只小狼”,但只有三只可见。随后,出现了一个异常现象,其中一只狼莫名其妙地长出了两对耳朵。在逐帧播放过程中,一只新的狼突然出现在中间狼的前面,然后另一只出现在最右侧狼的前面。最终,从屏幕中间开始显示的第一只狼从场景中消失了。 特别是在包含众多实体的场景中,这种动物或行人的突然显现构成了重大挑战。当视频需要精确计算物体或角色数量时,这些计划外的元素的出现可能会打断叙述,导致输出既不准确也不符合指定的提示。引入意外的物体,尤其是如果它们与预期的故事情节或内容相矛盾时,可能会误传原本的信息,损害视频的完整性和连贯性。 不真实的现象:图5(c)展示了两组快照帧,说明了不准确物理建模和不自然物体变形的问题。最初,前四个帧序列描绘了一个篮球穿过篮筐并点燃成火焰,如提示所述。然而,与预期的爆炸性互动相反,篮球在穿过篮筐时毫发无损。随后,接下来的四个帧显示另一个篮球穿过篮筐,但这次它直接穿过了在序列中意外变形的篮筐。此外,在这个快照中,篮球没有如提示所述爆炸。 这个场景展示了不准确物理建模和不自然物体变形的挑战。在所示案例中,Sora似乎诱导了一些物体不自然的变化,这可能会显著降低视频的真实感。 对物体和特性的理解有限:图5(d)说明了Sora在准确理解物体及其固有特性方面的局限性,重点是纹理。该序列显示了一把塑料椅子最初看起来很稳定,但随后发生了弯曲,并且在前几帧中形状不一致,同时没有可见支撑地漂浮起来。随后,椅子被描绘为持续进行极端弯曲。 这表示未能正确地将椅子建模为刚性的稳定物体,导致了不切实际的物理互动。这样的不准确可能导致视频看起来很超现实,因此不适合实际使用。尽管可以通过额外的设计工具修正一些小错误,但对于在多帧中显示不现实行为的显著物体等重大错误,可能会使视频失效。因此,要实现预期效果可能需要多次迭代来纠正这些明显的不一致性。 多物体间不正确的互动:图5(d)说明了模型在模拟涉及多个物体的复杂互动时的不准确。该序列旨在展示一个“祖母”角色吹灭蜡烛。理想情况下,蜡烛火焰应该对气流做出反应,要么闪烁要么熄灭。然而,视频未能描绘与外部环境的任何互动,在整个场景中火焰都异常静止。 这突显了Sora在渲染真实互动方面的挑战,特别是在包含多个活动元素或复杂动态的场景中。在涉及众多移动主体、复杂背景或涉及各种纹理的互动场景中,这种困难会被放大。这些不足可能导致不真实,有时是无意中幽默的结果,削弱了视频的效果,尤其是在需要高度现实主义或准确表现物理互动的背景下。 Data access privacy受到大型语言模型(LLM)进展的启发,Sora使用了互联网规模的数据集[5]进行训练。然而,互联网的公共数据虽然庞大,但只是总信息量中的一小部分;大部分是来自个人、公司和机构的私有数据。与公共数据集相比,私有数据集在多样性上更为丰富,且包含较少的重复内容。但是,它们也包含大量的敏感个人信息,尤其是以图像和视频格式存储的内容,这些内容比纯文本更具有个性化。这是一个关键的区分,因为后者主要用于训练LLM。因此,当公共数据资源得到充分利用,目标是进一步提高模型的性能,特别是在泛化能力方面时,设计出能够在严格保护隐私的同时利用非敏感私有数据的策略变得至关重要。 如[133]中引入的联邦学习(FL)提供了一种有前景的解决方案,它使成千上万的客户端能够使用自己的数据协同贡献到一个全局模型中,而无需在任何阶段传输原始数据。最近的研究已经验证了FL在微调LLM[134]和增强扩散模型[135]方面的有效性。尽管FL可以有效解决分布式私有数据访问的挑战,但它仍然面临一些重大问题,包括网络瓶颈、数据异构性、设备间歇性可用性等等。### 同时多镜头视频生成 多镜头视频生成在T2V领域是一个重大挑战,这个领域中的视频生成本身在很大程度上尚未被探索。这种情况一直持续到Sora在该领域展示了其专业能力。凭借其先进的语言理解能力,Sora能够生成包含多个镜头的视频,在整个序列中一致地保持角色和视觉风格。这种能力在视频生成方面具有重要意义,提供连贯和连续的视觉叙述。 尽管取得了这些进步,Sora尚未掌握创建同时包含相同角色和一致视觉风格的多镜头视频的能力。这种能力对于特定领域(如机器人技术,在学习演示中至关重要)以及自动驾驶车辆模拟(其中一致的视觉表示在系统的有效性和可靠性中起着关键作用)至关重要。这一特性的开发将标志着一项重大突破,拓宽了T2V技术在关键现实世界应用中的适用性。 Multi-Agent Co-creation由LLM驱动的智能体可以基于人类知识独立执行任务,而多智能体系统则将单个LLM智能体聚集在一起,通过协作利用它们的集体能力和专业技能[136, 137, 138]。在多智能体系统中,协作和协调至关重要,使得智能体集体能够承担超出单个实体能力的任务,并且智能体被赋予了独特的能力并承担特定的角色,协同工作以实现共同目标[139]。多智能体系统在反映和增强需要协作解决问题的现实世界任务方面的有效性已经在各个领域得到证实。值得注意的是,这包括软件开发[136, 137]和谈判游戏[140]等领域。 尽管具有潜力,但多智能体系统在T2V生成领域的应用仍然在很大程度上未被探索,这是由于它面临独特的挑战。以电影制作为例:智能体承担不同的角色,如导演、编剧和演员。每个演员必须根据导演的指导生成自己的片段,然后将这些片段整合成一个连贯的视频。主要的挑战在于确保每个演员智能体不仅在自身输出中保持帧与帧之间的连贯性,而且还要与集体愿景保持一致,以维持全局视频风格的一致性、合理的屏幕布局和统一性。这尤其困难,因为即使是在相似的提示下,生成模型的输出也可能会有很大的差异。 5 Future DirectionsRobot Learning from Visual Assistance传统编程机器人以执行新任务的方法需要大量的编码专业知识和时间投入[141]。这些方法要求用户细致地定义执行任务所需的每个步骤或动作。尽管运动规划策略减少了必须指定每个微小动作的需求,但它们仍然需要识别更高层次的动作,比如设定目标位置和通过点的序列。为了应对这些挑战,近期的研究转向了从示范中学习(LfD)的范式,在这种范式中,机器人通过观察和模仿专家的动作来学习新技能[141]。然而,正如传统机器人研究在数据集收集方面面临挑战一样,为LfD收集示范视频也遇到了关键的困难。尽管近期在简化数据收集的工具和方法上取得了进展,如UMI[142],但收集相关和全面的数据仍然是一个重大挑战。 更近期的生成模型研究,如大型语言模型(LLM)和视觉语言模型(VLM),在很大程度上缓解了这一障碍。这些创新使机器人能够在零样本的方式下与预训练的LLM和LVM一起工作,如VoxPoser[143],直接应用人类知识完成新的机器人任务,而无需先前的明确训练。 然而,在Sora公布之前,将T2V生成模型直接应用于机器人LfD是具有挑战性的。大多数现有模型在准确模拟复杂场景的物理特性方面存在困难,并且往往缺乏对特定因果实例的理解[5]。这个问题对机器人学习的有效性至关重要;数据与真实世界条件之间的差异会严重影响机器人训练的质量,从而损害机器人精确自主的能力。 另一方面,3D重建技术,如神经辐射场(NeRF)[144]和3D高斯溅射(3DGS)[145],在机器人研究中也受到了很多关注。DFFs[146],捕捉场景图像,通过2D模型提取密集特征并将它们与NeRF集成,映射空间和视角细节以高效创建复杂的3D模型和交互。DFFs表明,它们与NeRF的3D重建信息的集成使机器人能够更好地理解和与其环境互动,从而展示了3D重建信息如何帮助机器人更有效地完成任务。除此之外,Sora的一个显著特点是它能够在单个样本中生成同一角色的多个镜头,确保视频中外观的一致性[5]。这种能力可以通过将3D重建方法与Sora生成的多镜头视频整合,从而通过准确捕捉场景来增强通过示范的机器人学习。 Infinity 3D Dynamic Scene Reconstruction and Generation近年来,三维场景重建受到了广泛关注。[147]中的工作是在视频中从3D感知重建的先驱性尝试之一,通过整合GPS、惯性测量、相机姿态估计以及立体视觉、深度图融合和模型生成的高级算法,取得了显著成果。然而,神经辐射场(NeRF)[144]的出现标志着该领域的一个重大简化。NeRF使用户能够直接从视频中以前所未有的细节重建物体。尽管有了这一进步,重建高质量场景仍然需要付出巨大努力,尤其是在获取众多视角或视频方面,正如[148]所强调的。当物体较大,或环境使得捕获多视角视频变得困难时,这一挑战尤为突出。 一些研究已经证明了从视频流中进行3D重建的有效性,包括DyNeRF [148]和NeuralRecon [149]等显著贡献。特别是,连贯的3D重建研究前沿[149, 150]的特点是强调利用现有场景结构的空间和语义连续性,无缝生成新的场景块。值得注意的是,Sora [5]通过在一个统一视频框架内提供对单一角色多个视角的渲染能力,并整合物理世界模拟而脱颖而出。这些进步预示着无限3D场景重建和生成新时代的到来,有望在各个领域产生深远的影响。例如,在游戏领域,这项技术允许实时生成3D环境,并按照现实世界的物理法则实例化物体,有可能免除对传统游戏物理引擎的需求。 Augmented Digital Twins数字孪生(DT)是物理目标、系统或过程的虚拟副本,旨在在数字平台上模拟现实世界实体[151]。它们被广泛应用于各个行业,用于仿真、分析和控制目的。其概念是,数字孪生从其物理对应物接收数据(通常通过传感器和其他数据收集方法实时进行),并可以预测物理孪生在不同条件下的行为或对其环境变化的反应。数字孪生的关键特点是它们能够准确反映物理世界,使其能够像真实世界对应物一样对外部信号或变化做出响应。这种能力使得可以在不影响物理目标的情况下,优化操作、进行预测性维护并改进决策制定,因为数字孪生可以根据不同的场景模拟结果。 Sora的世界仿真能力有望显著增强当前的数字孪生系统。数字孪生中的一个主要挑战是确保数据的实时准确性,因为不稳定的网络连接可能导致关键数据段的丢失。这种丢失是关键的,可能会削弱系统的有效性。当前的数据补全方法通常缺乏对目标物理属性的深入了解,主要依赖于数据驱动的方法。通过利用Sora在理解物理原理方面的专长,可能生成物理上连贯且与底层真实世界现象更一致的数据。 数字孪生的另一个关键元素是视觉系统响应的准确性,有效地仿真和反映真实世界。目前的方法涉及用户通过编程触发事件,随后应用机器学习算法预测并可视化结果。这个过程是复杂的,通常缺乏对目标物理特性的全面理解。实施Sora可能有望简化这一过程,实现与系统的统一用户交互。用户可以直接与Sora创建的视觉界面交互,该界面将实时预测并考虑涉及目标的物理特性,提供准确且类似真实世界的视觉反馈。 Establish Normative Frameworks for AI applications随着DALL E、Midjourney和Sora等大型生成模型技术的快速进步,这些模型的能力已经显著增强。尽管这些进展可以提高工作效率,激发个人创造力,但也引发了关于这些技术可能被滥用的担忧,包括生成假新闻[152],侵犯隐私[153]和伦理困境[154]。目前,为AI应用建立规范性框架变得必要而紧迫。这些框架应当合法地回答以下问题: 如何解释AI的决策过程. 当前的AI技术大多被视为黑箱。然而,可靠AI的决策过程应该是可以解释的,这对于监督调整和增强信任至关重要。 如何保护用户的隐私. 个人信息保护已经成为社会关注的问题。随着AI这个数据密集型领域的发展,应该建立更细致、更严格的法规。 如何确保公平并避免歧视. AI系统应公平地为所有用户服务,不应加剧现有的社会不平等。实现这一点需要在算法设计和数据收集阶段整合公平原则,并积极避免偏见和歧视。 总体而言,规范性框架将涵盖社会和技术两个维度,以确保AI应用的开发方式能整体上对社会有益。 6 Conclusion基于Sora的分解方法,本研究全面回顾了当前的文本到视频(T2V)工作。具体来说,作者从生成模型的演变角度组织了文献,包括GAN/VAE、基于自回归和基于扩散的框架。 此外,作者根据优秀视频应具备的三个关键品质: 扩展时长、高分辨率和无缝质量,深入探讨并回顾了相关文献。 另外,由于Sora被宣布为现实世界模拟器,作者呈现了一个包含动态运动、复杂场景、多个物体和合理布局的现实全景。此外,根据其来源和应用领域,对视频生成中常用的数据集和评价指标进行了分类。最后,作者识别了T2V中仍存在的挑战和问题,并提出了未来发展的潜在方向。 参考[1].From Sora What We Can See: |
【本文地址】
今日新闻 |
推荐新闻 |