Elastic Stack 实战教程 3:快照备份与恢复 |
您所在的位置:网站首页 › 腾讯云服务器快照备份 › Elastic Stack 实战教程 3:快照备份与恢复 |
Elastic Stack 实战教程 3:快照备份与恢复
|
本系列 Elastic Stack 实战教程总共涵盖 5 个实验,目的是帮助初学者快速掌握 Elastic Stack 的基本技能。 云起实验室在线体验地址:https://developer.aliyun.com/adc/scenarioSeries/24e7a7a4d56741d0bdcb3ee73c9c22f1 实验 1:Elastic Stack 8 快速上手实验 2:ILM 索引生命周期管理实验 3:快照备份与恢复实验 4:使用 Fleet 管理 Elastic Agent 监控应用实验 5:Elasticsearch Java API Client 开发实验 3:快照备份与恢复Elasticsearch 提供快照和恢复功能,我们可以在远程文件系统仓库(比如共享文件系统、S3、HDFS 等)中为部分索引或者整个集群创建快照。快照有以下使用场景: 数据灾备:当发生误删索引数据的情况时,可以使用快照来还原;在主集群无法正常工作时,可以使用快照在备集群上恢复数据。归档数据:随着数据的积累,集群中磁盘存储的压力会越来越大,对于一些时效性高的数据,比如日志、指标,我们往往只关心最近一段时间内的数据。对于时间比较早的数据,我们可以选择以快照的形式归档,以备后续有查询的需求。从 Elasticsearch 7.10 版本开始我们还可以结合 ILM 索引生命周期管理,在 Cold 和 Frozen 数据层使用可搜索快照进一步降低存储成本。迁移数据:当需要将数据从一个集群迁移到另一个集群时,使用快照是一种高效的选择。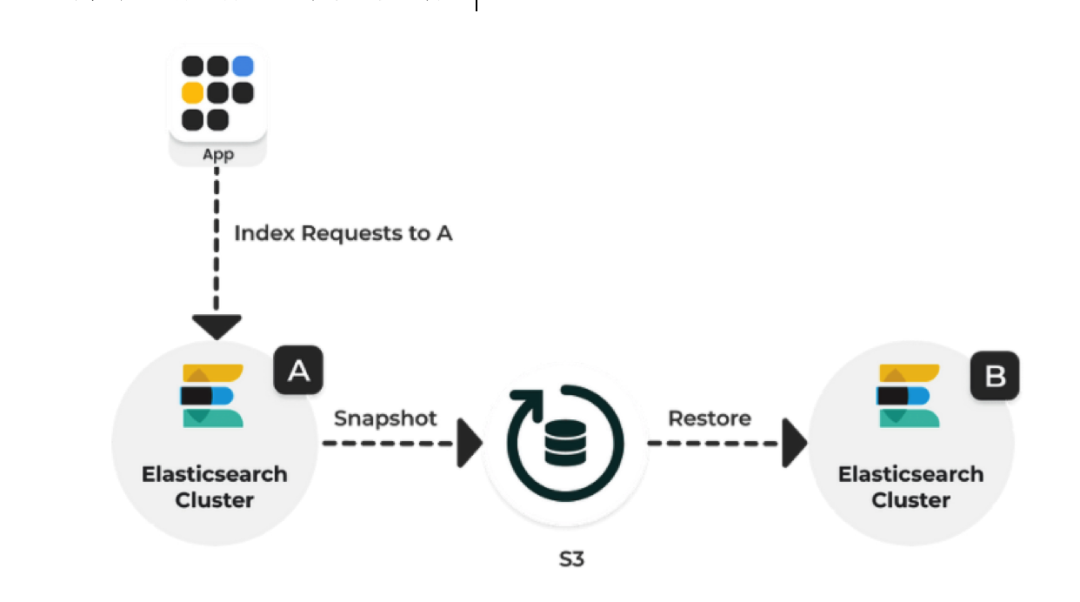 1 部署实验环境 1 部署实验环境实验架构如下所示,包含以下几个组件: MinIO 集群由 4 个节点组成,作为备份快照的存储库。Nginx 提供反向代理的功能,作为 MinIO 集群统一的访问入口。Elasticsearch 是一个开源的搜索和分析引擎。Kibana 提供了可视化的操作界面,方便用户与 Elasticsearch 进行交互。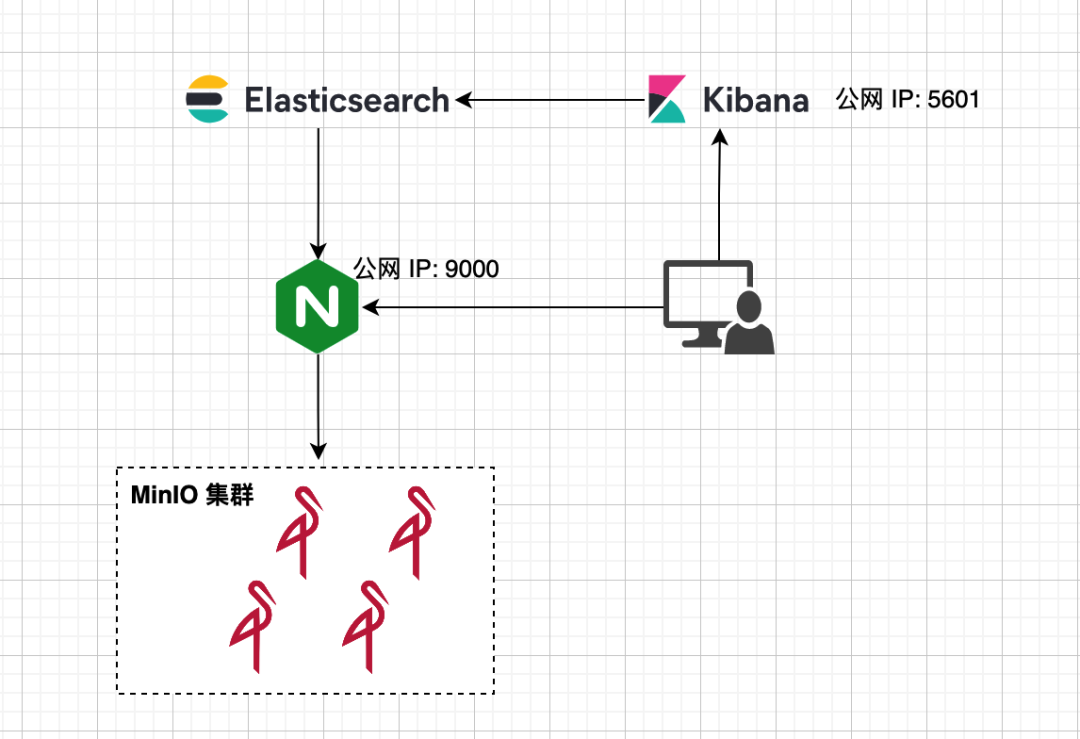 首先执行以下命令修改系统参数以满足 Elasticsearch 的运行条件。 # 增加进程可使用的最大内存映射区域数 cat >> /etc/sysctl.conf > /etc/security/limits.conf Dev Tools -> Console,打开 Kibana Console 界面。执行以下命令重新加载在节点上设置的 keystore。POST _nodes/reload_secure_settings { "secure_settings_password":"" } 4 注册存储库存储库(repository)是用于存储快照的地方,在创建或恢复快照之前先要创建好存储库。执行如下命令注册存储库,在 type 参数中设置存储库类型为 s3,在 settings 参数中填写存储库相关信息。从 Elasticsearch 8.0 版本开始已经内置支持 S3 类型的存储库了,无需再像以前那样安装 S3 Repository 插件了。 PUT _snapshot/my-repository { "type": "s3", "settings": { "bucket": "es-snapshot", // 存储桶名称 "client": "minio", // 和 keystore 中设置的 client_name 一致 "endpoint": "http://:9000" // 存储库 IP 地址 } }在创建存储库时,Elasticsearch 会自动检查存储库是否可用,如果没有报错说明存储库可以正常使用。在创建完成后也以使用 verify snapshot repository API 验证存储库的连接情况,如果验证成功,该请求将返回用于验证存储库的节点列表;如果验证失败,则返回错误信息。 POST _snapshot/my-repository/_verify # 返回结果 { "nodes" : { "jnuDcyy1T_CroiQuBfDASA" : { "name" : "es01" } } } 5 创建快照注册好存储库以后,接下来就可以创建快照(snapshot)对数据进行备份了。在创建快照之前,先准备一个索引 index-1,并往里面插入 3 条文档。 PUT _bulk {"index":{"_index":"index-1"}} {"name":"Mark","age":21} {"index":{"_index":"index-1"}} {"name":"Lisa","age":18} {"index":{"_index":"index-1"}} {"name":"Jack","age":20}然后使用 create snapshot API 手动创建名为 snapshot-1 的快照,根据数据量的大小,快照可能需要等待一段时间才能完成。默认情况下,快照命令在后台启动快照进程后,就会立即向客户端返回响应。如果想要等待快照完成后再响应客户端,可以将 wait_for_completion 参数设置为 true。 PUT _snapshot/my-repository/snapshot-1 # 等待快照完成后再响应客户端 # PUT _snapshot/my-repository/snapshot-1?wait_for_completion=true如上所示,在不做额外设置的情况下,快照默认会备份集群中所有的数据流和打开的索引。如果想要选择性地做快照备份,可以在请求体中设置相应的参数,支持的参数如下: ignore_unavailable(可选,布尔):是否忽略创建快照时不存在的索引,默认值为 false。indices(可选,字符串列表):快照中包含的索引和数据流。include_global_state(可选,布尔):是否备份当前的全局状态,默认值为 true。全局状态包括:persistent cluster settingsindex templatelegacy index templateingest pipelineILM policyfeature statefeature_states(可选,字符串列表): 快照中包含的功能状态列表,feature state 包含用于存储 Elastic Stack 组件(例如 Elasticsearch Security 和 Kibana)的相关配置和历史记录的索引和数据流。metadata(可选,对象):添加任意元数据到快照中,例如谁创建了快照,以及创建快照的原因等等。partial(可选,布尔):是否允许对含有不可用分片的索引进行部分快照,默认值为 false。接下来创建快照 snapshot-2,并在请求体中指定一些参数: indices 参数指明只对索引 index-1 和 index-2 进行备份。在本示例中并没有创建索引 index-2,在这里将 ignore_unavailable 参数设置为 true 可以忽略创建快照时不存在的索引,避免产生索引不存在的报错;将 include_global_state 参数设置为 false 表示不会备份集群状态和功能状态,因此集群的设置、用户权限以及 Kibana 配置等都不会进行备份。将 partial 参数设置为 true 允许当索引存在不可用的分片时,继续进行部分快照。最后在 metadata 参数中添加了一些自定义的内容,说明快照的创建人和创建原因。PUT _snapshot/my-repository/snapshot-2 { "indices": "index-1,index-2",// 备份的索引和者数据流 "ignore_unavailable": true, // 忽略创建快照时不存在的索引 "include_global_state": false, // 不备份集群状态和功能状态 "partial": true, // 允许对含有不可用分片的索引进行部分快照 "metadata": { // 添加自定义元数据到快照 "taken_by": "chengzw", "taken_because": "backup before upgrading" } }在 Stack Management -> Snapshot and Restore -> Snapshots 可以查看创建快照的进度。 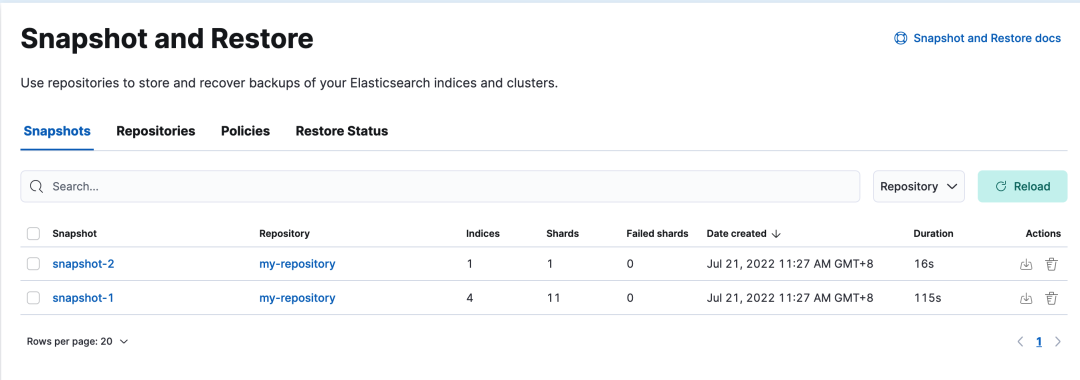 执行如下命令,可以查看快照的信息,其中包含快照的索引和数据流,快照当前的状态,快照开始和结束的时间,创建快照花费的时间,创建快照时的异常信息等等。 GET _snapshot/my-repository/snapshot-2 # 返回结果 { "snapshots" : [ { "snapshot" : "snapshot-2", "uuid" : "3_j5cF85T7CpltOeIzhM4Q", "repository" : "my-repository", "version_id" : 8020399, "version" : "8.2.3", "indices" : [ // 快照中包含的索引 "index-1" ], "data_streams" : [ ], // 快照中包含的数据流 "include_global_state" : false, "metadata" : { "taken_because" : "backup before upgrading", "taken_by" : "chengzw" }, "state" : "SUCCESS", // 快照当前的状态 "start_time" : "2022-07-21T03:27:19.674Z", // 快照开始时间 "start_time_in_millis" : 1658374039674, "end_time" : "2022-07-21T03:27:35.280Z", // 快照结束时间 "end_time_in_millis" : 1658374055280, "duration_in_millis" : 15606, // 创建快照花费的时间 "failures" : [ ], // 创建快照的异常信息 "shards" : { "total" : 1, "failed" : 0, "successful" : 1 }, "feature_states" : [ ] } ], "total" : 1, "remaining" : 0 }在 Minio 的存储桶中可以看到快照的数据。 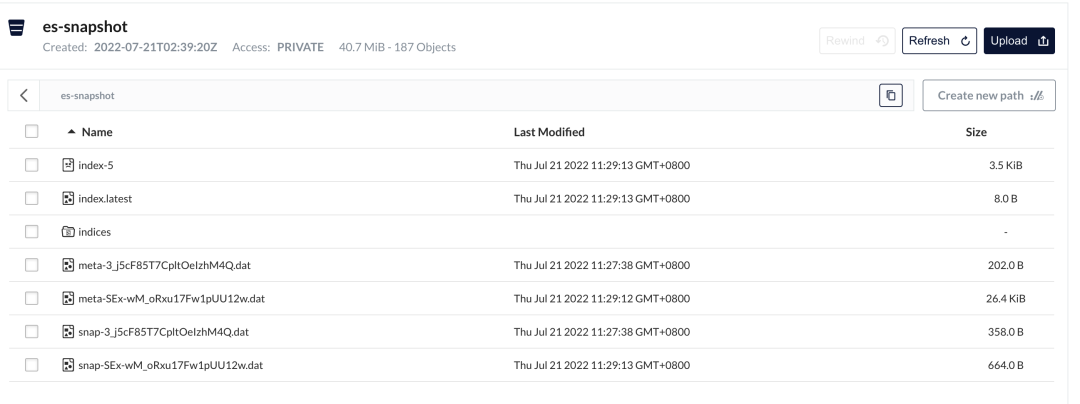 6 恢复快照 6 恢复快照确认快照创建完成后,现在来尝试使用快照来恢复索引。在恢复之前先删除原有的索引 index-1。 DELETE index-1如下所示,使用 restore snapshot API 指定恢复索引 index-1。 POST _snapshot/my-repository/snapshot-1/_restore { "indices": "index-1" }查询索引 index-1,可以看到文档被成功恢复了。 GET index-1/_search # 返回结果 { "took" : 0, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 3, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "index-1", "_id" : "_hjDHoIBKcgbD44DUW4Z", "_score" : 1.0, "_source" : { "name" : "Mark", "age" : 21 } }, { "_index" : "index-1", "_id" : "_xjDHoIBKcgbD44DUW4Z", "_score" : 1.0, "_source" : { "name" : "Lisa", "age" : 18 } }, { "_index" : "index-1", "_id" : "ABjDHoIBKcgbD44DUW8Z", "_score" : 1.0, "_source" : { "name" : "Jack", "age" : 20 } } ] } }默认情况下,快照中所有的索引和数据流都会恢复,除了集群状态相关的索引以外。如果想要恢复集群状态,可以将 include_global_state 参数设置为 true。恢复快照时,目标索引必须处于 close 状态,当快照恢复完成后,会自动将索引 open。如果不指定恢复的目标索引名,默认会将快照中的数据恢复到原索引上,这里需要强调的是,恢复后的索引中只会含有快照中备份的数据,创建快照后的增量数据将会丢失。 在恢复快照时也可以在请求体中指定一些参数: indices 参数指明只对索引 index-1 和 index-2 的快照数据进行恢复。在本示例中并没有创建索引 index-2,在这里将 ignore_unavailable 参数设置为 true 可以忽略快照中不存在的索引,避免产生索引不存在的报错。将 include_global_state 参数设置为 false 表示不恢复集群状态和功能状态,因此集群的设置、用户权限以及 Kibana 配置等都不会进行恢复。rename_pattern 和 rename_replacement 两个参数定义了恢复快照到新索引的匹配模式。include_aliases 参数设置是否恢复别名,默认为 true。执行以下命令,将 index-1 索引的快照数据恢复到新的索引 restored-index-1 上。 POST _snapshot/my-repository/snapshot-1/_restore { "indices": "index-1,index-2", // 备份的索引和者数据流 "ignore_unavailable": true, // 忽略快照中不存在的索引 "include_global_state": false, // 默认为 false,不恢复集群状态 "rename_pattern": "index-(.*)", // 匹配快照中的索引,() 内的内容替换到 $1 中 "rename_replacement": "restored-index-$1", // 恢复的索引名 "include_aliases": false // 不恢复别名 } 7 SLM 快照生命周期管理Elasticsearch 从 7.4 版本开始引入了 SLM(Snapshot Lifecycle Management) 快照生命周期管理功能。我们可以通过设置 SLM 策略来对快照的生命周期进行管理,例如定时创建快照,控制快照的保留时长和数量等等。如下所示,创建了一个 SLM 策略 nightly-snapshots: 在 schedule 参数中可以使用 Cron 表达式来设置定时任务。name 参数用于设置快照的名称,支持日期数学表达式,这样可以方便我们区分快照创建的时间,为了防止命名冲突,SLM 策略会在快照名的末尾附加随机的 UUID 字符串。在retention 参数中可以设置快照的保留规则,避免快照的数量无限制地增长。PUT _slm/policy/nightly-snapshots { "schedule": "0 30 1 * * ?", // 每天凌晨 1:30 (UTC 时间) 创建快照 "name": "", // 快照名称, 使用日期数学表达式添加当前日期 "repository": "my-repository", // 使用的存储库 "config": { "indices": ["index-1", "index-2"], // 备份的索引 "ignore_unavailable": true, // 忽略创建快照时不存在的索引 "include_global_state": false // 不备份集群状态和功能状态 }, "retention": { // 快照保留策略 "expire_after": "30d", // 保留快照 30 天 "min_count": 5, // 保留至少 5 个快照 "max_count": 50 // 保留最多 50 个快照 } }创建完 SLM 策略以后,可以执行 execute snapshot lifecycle policy API 立即创建快照,这便于我们测试新的 SLM 策略,手动执行策略不会影响其快照计划。 POST _slm/policy/nightly-snapshots/_execute我们也可以在 Stack Management -> Snapshot and Restore -> Policies 手动执行 SLM 策略。 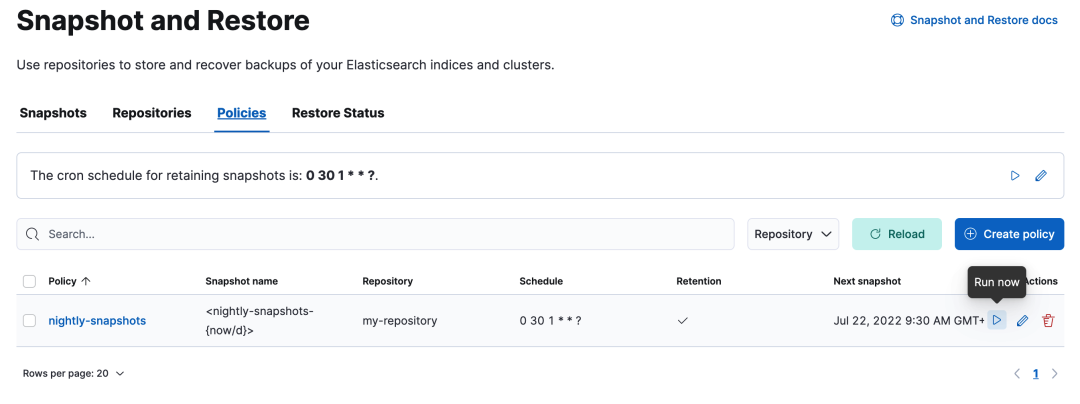
|
【本文地址】
今日新闻 |
推荐新闻 |