图像处理 人脸识别的三种经典算法与简单的CNN 【附Python实现】 |
您所在的位置:网站首页 › 脸型辨别图 › 图像处理 人脸识别的三种经典算法与简单的CNN 【附Python实现】 |
图像处理 人脸识别的三种经典算法与简单的CNN 【附Python实现】
|
一点说明
1. 完成情况
详细阐述了人脸识别中的经典算法与深度学习算法
手动实现了三种人脸识别经典算法 【代码地址】
基于主成分分析(PCA)的Eigenfaces特征脸方法
基于线性判别分析(LDA)的Fisherfaces特征脸方法
局部二进制模式(LBP)直方图方法
实验对比分析了三种人脸识别经典算法 和 CNN 实现人脸识别的特点以及异同点
2. 项目结构
data/(存放项目用到的数据集,如有更改,记得修改代码中的引用地址)
src/(存放源代码,直接运行 src/ 中的 Classical_Methods.py 即可)
README.md (实验报告)
思路分析
0. 人脸识别 综述
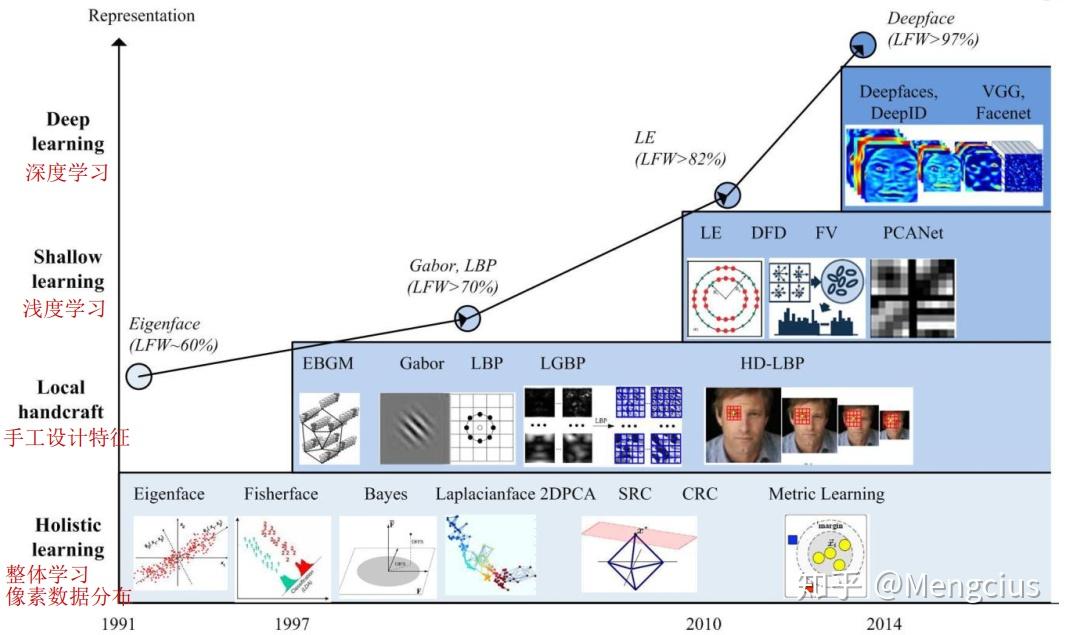
参考链接:《Face Recognition: From Traditional to Deep Learning Methods》,《人脸识别合集 | 人脸识别概述》 人脸识别(Face Recognition)是指 能够识别或验证图像或视频中的主体的身份 的技术。自上个世纪七十年代首个人脸识别算法被提出以来,人脸识别已经成为了计算机视觉与生物识别领域被研究最多的主题之一。究其火爆的原因,一方面是它的挑战性——在无约束条件的环境中的人脸信息,也就是所谓自然人脸(Faces in-the-wild),具有高度的可变性,如下图所示;另一方面是由于相比于指纹或虹膜识别等传统上被认为更加稳健的生物识别方法,人脸识别本质上是非侵入性的,这意味着它是最自然、最符合人类直觉的一种生物识别方法。
现代人脸识别技术的研究热潮,已经从使用人工设计的特征(如边和纹理描述量等)与机器学习技术(如主成分分析、线性判别分析和支持向量机等)组合的传统方法的研究,逐渐转移到使用庞大人脸数据集搭建与在其基础上训练深度神经网络的研究。但是,无论是基于传统方法还是深度神经网络,人脸识别的流程都是相似的,大概由以下四个模块组成: 人脸检测 :提取图像中的人脸,划定边界; 人脸对齐 :使用一组位于图像中固定位置的参考点来缩放和裁剪人脸图像; 人脸表征 :人脸图像的像素值会被转换成紧凑且可判别的特征向量,或称模板; 人脸匹配 :选取并计算两个模板间的相似度分数来度量两者属于同一个主体的可能性。
准确地说,是 基于主成分分析的Eigenfaces特征脸方法 与 基于线性判别分析的Fisherfaces特征脸方法,这是根据整体特征进行人脸辨别的两种方法。 1)算法框架 使用 PCA 或 LDA 进行人脸识别的算法流程十分相似,具体步骤如下。 读取人脸图片数据库的图像及标签,并进行灰度化处理(可以同时进行直方图均衡等) 将读入的二维图像数据信息转为一维向量,然后按列组合成原始数据矩阵 对原始矩阵进行归一化处理,并使用PCA或LDA算法对原始数据矩阵进行特征分析与降维(计算过程中,根据原始数据得到一维均值向量经过维度的还原以后得到的图像为“平均脸”) 读取待识别的图像,将其转化为与训练集中的同样的向量表示,遍历训练集,寻找与待识别图像的差值小于阈值(或差值最小)的图像,即为识别结果 2)PCA 原理参考链接:《PCA的数学原理》 (强烈推荐,讲得非常透彻!) PCA(Principal Component Analysis,主成分分析)是一种常用的数据分析方法。PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降维。 I. 为什么要降维? 数据分析时,原始数据的维度与算法的复杂度有着密切的关系,在保留原始数据特征的情况下,对数据进行降维可以有效地提高时间效率,减少算力损失。 II. PCA降维的原理是什么? 降维意味着信息的丢失,但是由于实际数据内部往往具有相关性,所以我们可以利用这种相关性,通过某些方法使得在数据维度减少的同时保留尽可能多的原始特征,这就是PCA算法的初衷。 那么这一想法如何转化为算法呢?我们知道,在N维空间对应了由N个线性无关的基向量构成的一组基,空间中的任一向量都可用这组基来表示。我们要将一组N维向量降为K维(K大于0,小于N),其实只需要通过矩阵乘法将原N维空间中的向量转化为由K个线性无关的基向量构成的一组基下的表示。 但是,这一组K维的基并不是随便指定的。为了尽可能保留原始特征,我们希望将原始数据向量投影到低维空间时,投影后各字段(行向量)不重合(显然重合会覆盖特征),也就是使变换后数据点尽可能分散,这就自然地联系到了线性代数中的方差与协方差。
所以,综合来看,我们降维的目标为 选择K个基向量(一般转化为单位长度的正交基),使得原始数据变换到这组基上后,各字段两两间协方差为0,而字段的方差则尽可能大(在正交的约束下,取最大的K个方差)。这也就是PCA的原理——PCA本质上是将方差最大的方向作为主要特征,并且在各个正交方向上将数据“离相关”,也就是让它们在不同正交方向上没有相关性。 III. 如何使用PCA进行降维? 在上一个问题中,我们其实已经介绍了PCA的算法流程。转化成具体的数学方法,主要有以下几步(设有 \(m\) 条 \(n\) 维数据,将其降为 \(k\) 维): 将原始数据按列组成 \(n\) 行 \(m\) 列矩阵 \(X\) 矩阵 \(X\) 中每一维的数据都减去该维的均值,使得变换后矩阵 \(X’\) 每一维均值为 \(0\) 求出协方差矩阵 \(C=\frac{1}{m}X'X'^T\),进一步求出矩阵 \(C\) 的特征值及对应的特征向量 将特征向量按对应特征值大小从上到下按行排列成矩阵,取前 \(k\) 行组成矩阵 \(P\) \(Y=PX\) 即为降维到 \(k\) 维后的数据 IV. PCA的缺点与不足 PCA是一种无参数技术,无法进行个性化的优化;PCA可以解除线性相关,但无法处理高阶的相关性;PCA假设数据各主特征分布在正交方向,无法较好应对主特征在非正交方向的情况。 V. PCA 的 python 实现用 Python 语言实现上述算法,代码如下,仅展示代码核心部分,详细代码请见附件。 参考链接:《人脸识别经典算法实现(一)——特征脸法》,《opencv学习之路(40)、人脸识别算法——EigenFace、FisherFace、LBPH》,《经典人脸识别算法小结——EigenFace, FisherFace & LBPH(下)》 def algorithm_pca(data_mat): """ PCA函数,用于数据降维 :param data_mat: 样本矩阵 :return: 降维后的样本矩阵和变换矩阵 """ mean_mat = np.mat(np.mean(data_mat, 1)).T cv2.imwrite('./data/face_test/mean_face.jpg', np.reshape(mean_mat, IMG_SIZE)) diff_mat = data_mat - mean_mat # print('差值矩阵', diff_mat.shape, diff_mat) cov_mat = (diff_mat.T * diff_mat) / float(diff_mat.shape[1]) # print('协方差矩阵', cov_mat.shape, cov_mat) eig_vals, eig_vecs = np.linalg.eig(np.mat(cov_mat)) # print('特征值(所有):', eig_vals, '特征向量(所有):', eig_vecs.shape, eig_vecs) eig_vecs = diff_mat * eig_vecs eig_vecs = eig_vecs / np.linalg.norm(eig_vecs, axis=0) eig_val = (np.argsort(eig_vals)[::-1])[:DIM] eig_vec = eig_vecs[:, eig_val] # print('特征值(选取):', eig_val, '特征向量(选取):', eig_vec.shape, eig_vec) low_mat = eig_vec.T * diff_mat # print('低维矩阵:', low_mat) return low_mat, eig_vec 3)LDA 原理参考链接:《Linear Discriminant Analysis》,《人脸识别经典算法三:Fisherface(LDA)》,《人脸识别系列二 | FisherFace,LBPH算法及Dlib人脸检测》 LDA(Linear Discriminant Analysis,线性判别分析)算法的思路与PCA类似,都是对图像的整体分析。不同之处在于,PCA是通过确定一组正交基对数据进行降维,而LDA是通过确定一组投影向量使得数据集不同类的数据投影的差别较大、同一类的数据经过投影更加聚合。在形式上,PCA与LDA的最大区别在于,PCA中最终求得的特征向量是正交的,而LDA中的特征向量不一定正交。 I. LDA的原理是什么? 在上面我们已经介绍了LDA的目标:不同的分类得到的投影点要尽量分开;同一个分类投影后得到的点要尽量聚合。
为了定量分析这两点,以计算合适的投影矩阵,我们定义了类内散列度矩阵 \(S_{w}\)和 类间散列度矩阵 $S_B $ 。 其中 \(S_w=\sum ^c_{i=1}{\sum _{x\in ω_i}(x-μ_i)(x-μ_i)^T}\), \(c\) 为类别总数,\(μ_i\)代表类别 \(i\) 的均值矩阵;\(S_B=\sum ^c_{i=1}N_i(μ_i-μ)(μ_i-μ)^T\),\(N_i\) 为类别\(i\) 的数据点数。定义 \(J(w)=\frac{|W^TS_BW|}{|W^TS_wW|}\) 为目标函数,其中矩阵 \(W\) 是投影矩阵,那么我们就是要求出使 \(J(w)\) 取最大值的投影矩阵 \(W\) 。该最大值可由拉格朗日乘数法求得,不再赘述。最终问题可化简为,\(S_w^{-1}S_Bw_i=λw_i\) ,即求得矩阵的特征向量,然后取按特征值从大到小排列的前 \(k\) 个特征向量即为所需的投影矩阵。 II. LDA 与 PCA 的比较LDA与PCA算法的不同之处: 从数学角度来看,LDA选择分类性能最好的投影方向,而PCA选择样本投影点具有最大方差的方向; LDA是有监督的降维方法,而PCA是无监督的; 对于 \(K\) 维的数据,LDA只能将其降到 \(K-1\) 维度,而 PCA 不受此限制。LDA与PCA算法的相同之处: 在降维的时候,两者都使用了矩阵的特征分解思想; 两种算法都假设数据集中原始数据符合高斯分布。 III. LDA 的 python 实现用python语言实现上述算法,代码如下,仅展示代码核心部分,详细代码请见附件。 参考链接:《人脸识别经典算法实现(二)——Fisher线性判别分析》,《opencv学习之路(40)、人脸识别算法——EigenFace、FisherFace、LBPH》,《经典人脸识别算法小结——EigenFace, FisherFace & LBPH(下)》 def algorithm_lda(data_list): """ 多分类问题的线性判别分析算法 :param data_list: 样本矩阵列表 :return: 变换后的矩阵列表和变换矩阵 """ n = data_list[0].shape[0] Sw = np.zeros((n, n)) u = np.zeros((n, 1)) Sb = np.zeros((n, n)) N = 0 mean_list = [] sample_num = [] for data_mat in data_list: mean_mat = np.mat(np.mean(data_mat, 1)).T mean_list.append(mean_mat) sample_num.append(data_mat.shape[1]) data_mat = data_mat - mean_mat Sw += data_mat * data_mat.T for index, mean_mat in enumerate(mean_list): m = sample_num[index] u += m * mean_mat N += m u = u / N for index, mean_mat in enumerate(mean_list): m = sample_num[index] sb = m * (mean_mat - u) * (mean_mat - u).T Sb += sb eig_vals, eig_vecs = np.linalg.eig(np.mat(np.linalg.inv(Sw) * Sb)) eig_vecs = eig_vecs / np.linalg.norm(eig_vecs, axis=0) eig_val = (np.argsort(eig_vals)[::-1])[:DIM] eig_vec = eig_vecs[:, eig_val] trans_mat_list = [] for data_mat in data_list: trans_mat_list.append(eig_vec.T * data_mat) return trans_mat_list, eig_vec 3. 传统算法——局部二进制模式直方图(LBPH)LBPH算法“人”如其名,采用的识别方法是局部特征提取的方法,这是与前两种方法的最大区别。类似的局部特征提取算法还有离散傅里叶变换(DCT)与盖伯小波(Gabor Waelets)等。 LBPH(Local Binary Pattern Histograms,局部二进制模式直方图)人脸识别方法的核心是 LBP算子。LBP是一种用来描述图像局部纹理特征的算子,它反映内容是每个像素与周围像素的关系。 I. LBP 的原理是什么?参考链接:《LBP简介》,《人脸识别经典算法二:LBP方法》 原始 LBP 最初的LBP是定义在像素3x3邻域内的,以邻域中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3x3邻域内的8个点经比较可产生8位二进制数(通常转换为十进制数即LBP码,共256种),即得到该邻域中心像素点的LBP值,并用这个值来反映该区域的纹理信息。如下图所示:
均匀 LBP(本次作业中代码采用的LBP算子) 研究者发现根据原始LBP计算出来的90%以上的值具有某种特性,即属于 均匀模式(Uniform Pattern)——二进制序列(这个二进制序列首尾相连)中数字从0到1或是从1到0的变化不超过2次。比如,01011111的变化次数为3次,那么该序列不属于均匀模式。根据这个算法,所有的8位二进制数中共有58(变化次数为0的有2种,变化次数为1的有0种,变化次数为2的有56种)个均匀模式。 所以,我们可以根据这一数据分布特点将原始的LBP值分为59类,58个均匀模式为一类,其余为第59类。这样就将直方图从原来的256维变成了59维,起到了降维的效果。 III. LBPH 的算法流程LBPH的算法其实非常简单,只有两步: LBP特征提取:根据上述的均匀LBP算子处理原始图像; LBP特征匹配(计算直方图):将图像分为若干个的子区域,并在子区域内根据LBP值统计其直方图,以直方图作为其判别特征。 III. LBP 的特点? LBP的优点是对光照不敏感。根据算法,每个像素都会根据邻域信息得到一个LBP值,如果以图像的形式显示出来可以得到下图。相比于PCA或者LDA直接使用灰度值去参与运算,LBP算子是一种相对性质的数量关系,这是LBP应对不同光照条件下人脸识别场景的优势所在。但是对于不同角度、遮挡等场景,LBP也无能为力。
用python语言实现上述算法,代码如下,仅展示代码核心部分,详细代码请见附件。 参考链接:《人脸识别经典算法实现(三)——LBP算法》,《opencv学习之路(40)、人脸识别算法——EigenFace、FisherFace、LBPH》,《经典人脸识别算法小结——EigenFace, FisherFace & LBPH(下)》 class AlgorithmLbp(object): def load_img_list(self, dir_name): """ 加载图像矩阵列表 :param dir_name:文件夹路径 :return: 包含最原始的图像矩阵的列表和标签矩阵 """ # 请见附件 def get_hop_counter(self, num): """ 计算二进制序列是否只变化两次 :param num: 数字 :return: 01变化次数 """ bin_num = bin(num) bin_str = str(bin_num)[2:] n = len(bin_str) if n < 8: bin_str = "0" * (8 - n) + bin_str n = len(bin_str) counter = 0 for i in range(n): if i != n - 1: if bin_str[i + 1] != bin_str[i]: counter += 1 else: if bin_str[0] != bin_str[i]: counter += 1 return counter def get_table(self): """ 生成均匀对应字典 :return: 均匀LBP特征对应字典 """ counter = 1 for i in range(256): if self.get_hop_counter(i) = center) * (1 |





【本文地址】