卷积神经网络(CNN)自学笔记1:全连接层 |
您所在的位置:网站首页 › 胶囊网络主要作用是什么 › 卷积神经网络(CNN)自学笔记1:全连接层 |
卷积神经网络(CNN)自学笔记1:全连接层
|
一、全连接层的定义
全连接层(fully connected layers,FC)是神经网络的一种基本层类型,通常位于网络的最后几层,用于分类任务的输出层。全连接层的主要特点是每一个神经元与前一层的每一个神经元都相连接,这意味着每个输入都影响每个输出。在全连接层中,输入向量通过一个权重矩阵进行线性变换,然后加上一个偏置项,最后通过激活函数(如ReLU、Sigmoid、Tanh等)进行非线性变换。 公式表达: 其中, 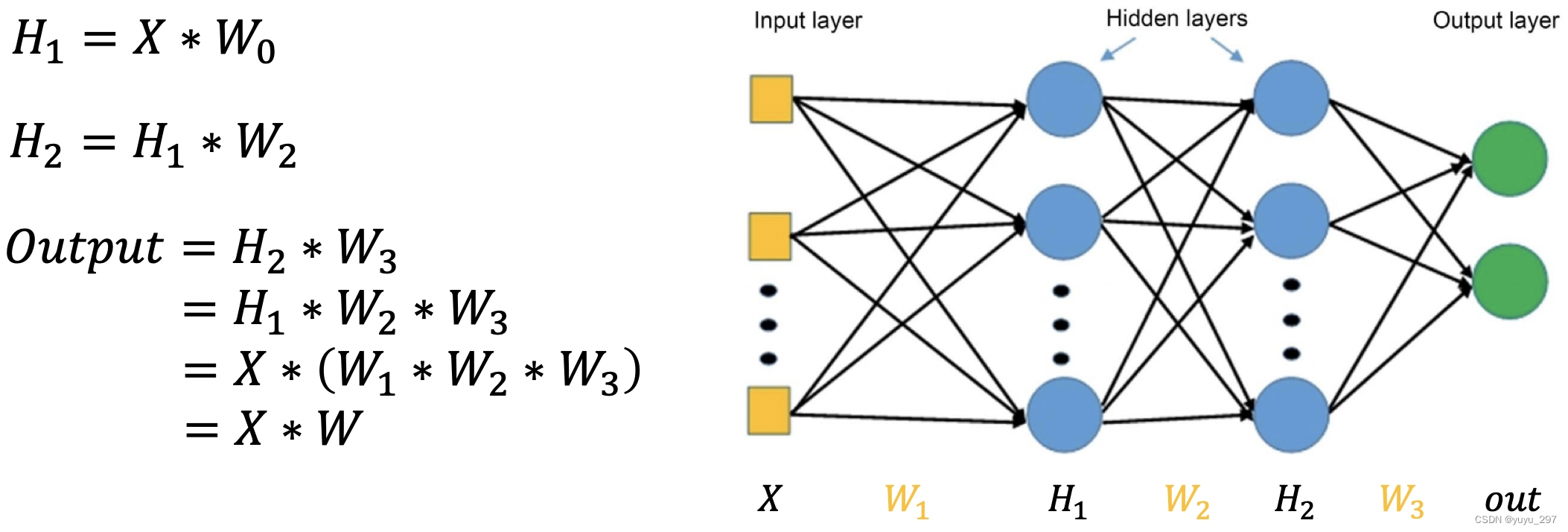 图1 多层全连接层的前向传播过程
二、全连接层的作用
图1 多层全连接层的前向传播过程
二、全连接层的作用
1.在整个卷积神经网络中起到“分类器”的作用。 在分类任务中,全连接层通常作为网络的最后一层,直接将全连接层的维度设为类别数量或通过Softmax函数输出每个类别的概率分布,从而实现对输入数据的分类。如果说卷积层、池化层和激活函数等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。 2.维度变换 可以把高维变到低维,或者把低维变到高维,同时把有用的信息保留下来。 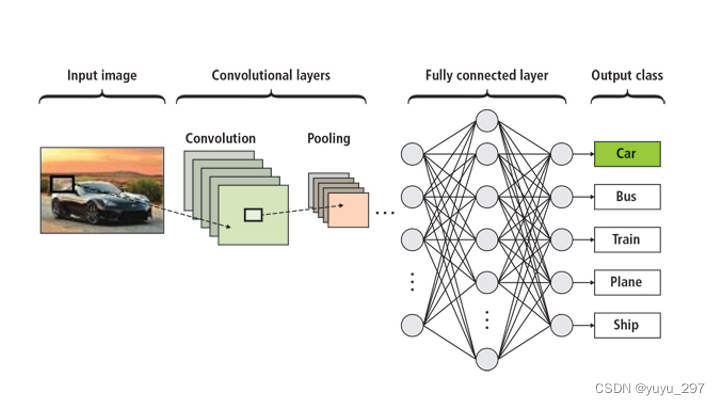 图2 全连接层的作用
三、全连接层的实现
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
# 定义神经网络模型
class SimpleNN(nn.Module):
def __init__(self, input_size, num_classes):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(input_size, 64) # 第一个全连接层
self.fc2 = nn.Linear(64, 32) # 第二个全连接层
self.fc3 = nn.Linear(32, num_classes) # 输出层,维度为类别数量
def forward(self, x):
x = F.relu(self.fc1(x)) # ReLU激活函数
x = F.relu(self.fc2(x))
x = self.fc3(x) # 最后一层不需要激活函数,因为我们会在损失函数中应用Softmax
return x
# 模型实例化
input_size = 128 # 假设输入数据的特征维度为128
num_classes = 10 # 假设有10个类别
model = SimpleNN(input_size, num_classes)
# 打印模型结构
print(model)
# 损失函数和优化器
criterion = nn.CrossEntropyLoss() # CrossEntropyLoss包含了Softmax
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 假设有一些数据用于训练
# inputs: shape (batch_size, input_size)
# labels: shape (batch_size)
inputs = torch.randn(32, input_size) # 32个样本,输入特征维度为128
labels = torch.randint(0, num_classes, (32,)) # 32个样本的标签,范围在0到9之间
# 训练步骤
outputs = model(inputs) # 前向传播
loss = criterion(outputs, labels) # 计算损失
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 打印损失
print(f'Loss: {loss.item()}')
图2 全连接层的作用
三、全连接层的实现
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
# 定义神经网络模型
class SimpleNN(nn.Module):
def __init__(self, input_size, num_classes):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(input_size, 64) # 第一个全连接层
self.fc2 = nn.Linear(64, 32) # 第二个全连接层
self.fc3 = nn.Linear(32, num_classes) # 输出层,维度为类别数量
def forward(self, x):
x = F.relu(self.fc1(x)) # ReLU激活函数
x = F.relu(self.fc2(x))
x = self.fc3(x) # 最后一层不需要激活函数,因为我们会在损失函数中应用Softmax
return x
# 模型实例化
input_size = 128 # 假设输入数据的特征维度为128
num_classes = 10 # 假设有10个类别
model = SimpleNN(input_size, num_classes)
# 打印模型结构
print(model)
# 损失函数和优化器
criterion = nn.CrossEntropyLoss() # CrossEntropyLoss包含了Softmax
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 假设有一些数据用于训练
# inputs: shape (batch_size, input_size)
# labels: shape (batch_size)
inputs = torch.randn(32, input_size) # 32个样本,输入特征维度为128
labels = torch.randint(0, num_classes, (32,)) # 32个样本的标签,范围在0到9之间
# 训练步骤
outputs = model(inputs) # 前向传播
loss = criterion(outputs, labels) # 计算损失
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 打印损失
print(f'Loss: {loss.item()}')
在实际使用中,全连接层也可由卷积操作实现: 当前一层是全连接层时,全连接层可以被 1×1 卷积层替代。原因在于 1×1 卷积层会对输入的每一个位置进行一个全连接操作,同时保持输入特征图的空间维度不变。 当前一层是卷积层时,全连接层可以被一个卷积核为 ℎ×𝑤 的卷积层替代,其中 ℎ 和 𝑤 是前一层卷积结果的高和宽。这种全局卷积操作实际上是对整个特征图进行一次全连接操作,实现与全连接层相同的效果。 |
【本文地址】