PYTHON密度聚类的例子 |
您所在的位置:网站首页 › 聚类算法例子 › PYTHON密度聚类的例子 |
PYTHON密度聚类的例子
|
密度聚类(density-based clustering)通过样本分布的紧密程度来进行分类,连续的密集区域将被视为一个类。 DBSCAN(Density-Based Spatial Clustering of Application with Noise)算法是密度聚类的经典算法,能在具有噪声的空间数据集中发现任意形状的簇。正面是DBSCAN中常见的概念: 核心点( Core point):当一个数据点在指定半径(eps)内至少包含了min_samples个样本,则是核心点。边界点( Border point):当一个数据点不是核心点,但在个核心点的半径范围内,则是边界点。噪音点( Noise):既不是核心点也不是边界点的点。密度直达:核心点对于其半径(eps)内的点是密度直达的。密度可达:一个核心点半径(eps)内有其他核心点,这些连续的核心点及其半径范围组成区域的数据点之间均是密度可达的。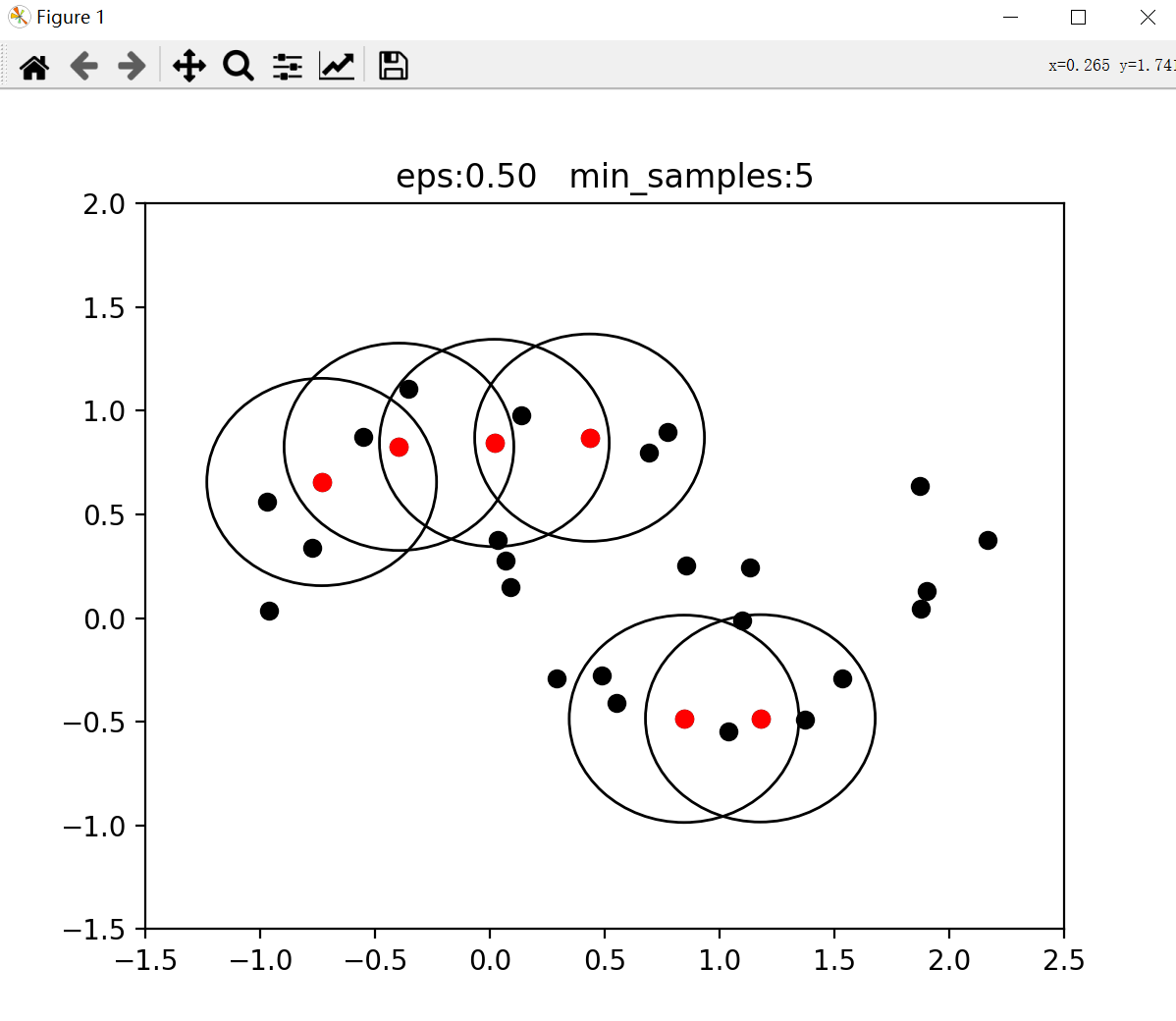 算法过程选择任意一个尚未分类的数据点。如果为核心点,则标记一个新的簇标签。遍历这个核心点密度可达的样本集合,分配之前标记的簇标签。迭代1,2步,直到所有核心点都有标签为止。参数 算法过程选择任意一个尚未分类的数据点。如果为核心点,则标记一个新的簇标签。遍历这个核心点密度可达的样本集合,分配之前标记的簇标签。迭代1,2步,直到所有核心点都有标签为止。参数core_samples,cluster_ids = dbscan(X, eps =0.5, min_samples=5) X是数据eps:计算密度点数的半径。可间接控制聚类数。 min_samples=5:半径内点数大于此值,则是核心点。core_samples表示核心点下标组成的列表。cluster_ids 是分类标签。举例import pandas as pd from sklearn import datasets from sklearn.cluster import dbscan from matplotlib import pyplot as plt size=200 半径=0.2 min_samples=5 X,y = datasets.make_moons(size,noise = 0.05,random_state=1) df = pd.DataFrame(X,columns = ['x1','x2']) core_samples,cluster_ids = dbscan(X, eps =半径, min_samples=min_samples) print("核心点:",core_samples) print("标签:",cluster_ids) for i in range(size): if cluster_ids[i]==0: plt.scatter(X[i, 0], X[i, 1], c='red') elif cluster_ids[i]==1: plt.scatter(X[i, 0], X[i, 1], c='blue') plt.xlim(-1.5,2.5) plt.ylim(-1.5,2) plt.title("eps:%.2f min_samples:%d"%(半径,size)) plt.show()结果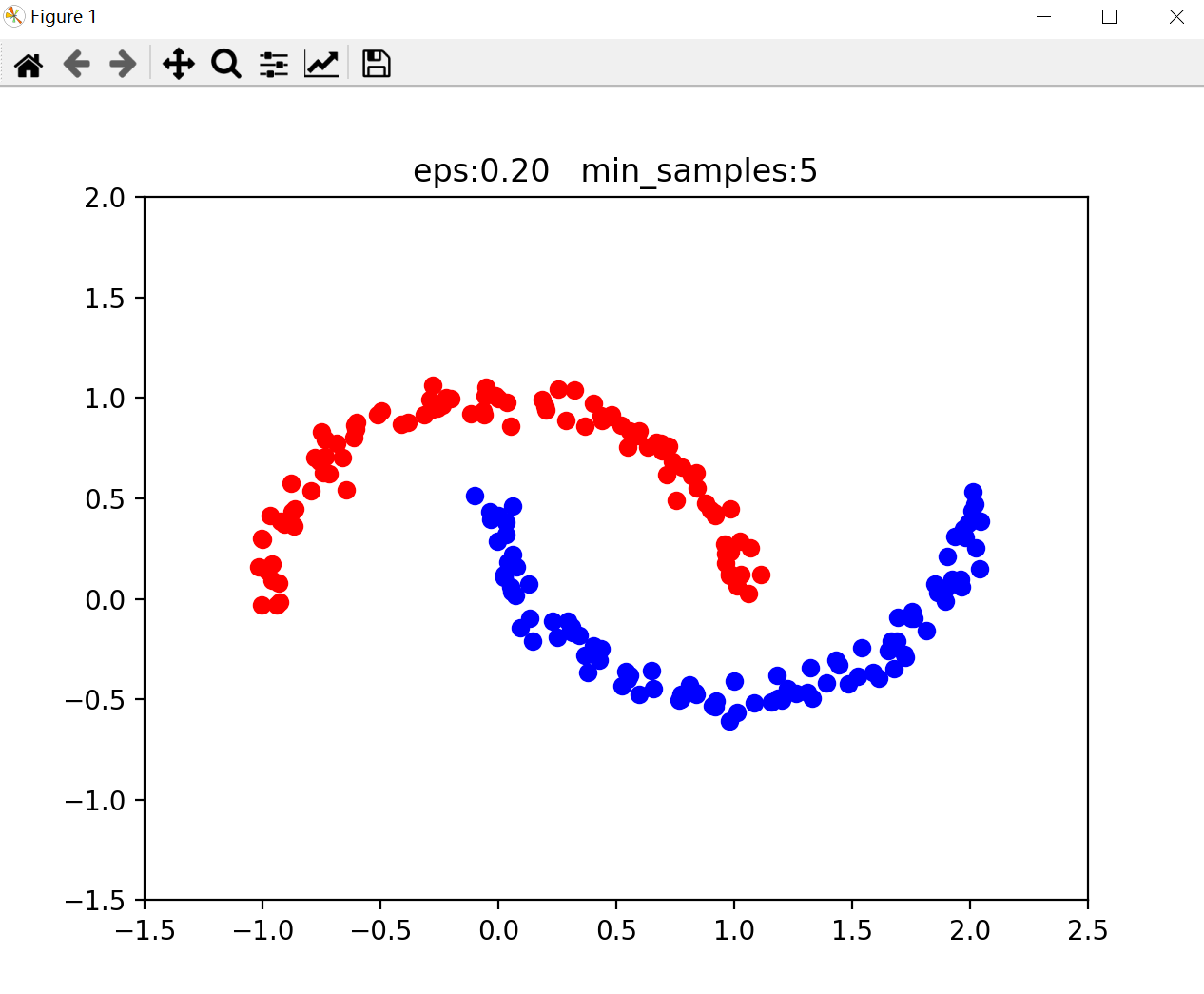
|
【本文地址】
今日新闻 |
推荐新闻 |