聚类分析(超全超详细版) |
您所在的位置:网站首页 › 聚类的数学定义 › 聚类分析(超全超详细版) |
聚类分析(超全超详细版)
|
聚类分析基础
聚类分析的概念聚类的过程良好聚类算法的特征聚类分析的要求
聚类分析的度量外部指标内部指标
聚类的分类基于划分的聚类K-means聚类K-means++聚类代码1(鸢尾花的三个特征聚类)代码2(31省市居民家庭消费水平的聚类)拓展:KNN和K-means的不同KNNKNN和K-means的区别
k‐medoids算法PAM算法CLARA算法CLARANS算法
k‐prototype算法总结基于划分的几种算法
基于层次的聚类自底向上的聚合聚类AGNESBIRCH(平衡迭代削减聚类法)CURE算法(使用代表点的聚类法)ROCK代码
总结基于划分的几种算法
基于密度的聚类DBSCAN 算法WS-DBSCAN 算法MDCA 算法(密度最大值聚类算法)总结基于密度的几种算法代码
基于网格的聚类(gird-based methods)网格聚类算法对比总结基于网格的几种算法
基于模型的聚类基于神经网络模型的聚类自组织神经网络SOM(Self Organized Maps)
基于概率模型的聚类高斯混合模型(GMMs,Gaussian Mixture Models )
总结基于模型的聚类
应用参考文献
聚类分析是一种典型的无监督学习, 用于对未知类别的样本进行划分,将它们按照一定的规则划分成若干个类族,把相似(距高相近)的样本聚在同一个类簇中, 把不相似的样本分为不同类簇,从而揭示样本之间内在的性质以及相互之间的联系规律聚类算法在银行、零售、保险、医学、军事等诸多领域有着广泛的应用
聚类分析的概念
聚类分析是根据在数据中发现的描述对象及其关系的信息,将数据对象分组。目的是,组内的对象相互之间是相似的(相关的),而不同组中的对象是不同的(不相关的)。组内相似性越大,组间差距越大,说明聚类效果越好。 也就是说, 聚类的目标是得到较高的簇内相似度和较低的簇间相似度,使得簇间的距离尽可能大,簇内样本与簇中心的距离尽可能小 聚类得到的簇可以用聚类中心、簇大小、簇密度和簇描述等来表示 聚类中心是一个簇中所有样本点的均值(质心)簇大小表示簇中所含样本的数量簇密度表示簇中样本点的紧密程度簇描述是簇中样本的业务特征 聚类的过程 数据准备:包括特征标准化和降维;特征选择:从最初的特征中选择最有效的特征,并将其存储于向量中;特征提取:通过对所选择的特征进行转换形成新的突出特征;聚类(或分组):首先选择合适特征类型的某种距离函数(或构造新的距离函数)进行接近程度的度量,而后执行聚类或分组;聚类结果评估:是指对聚类结果进行评估,评估主要有3种:外部有效性评估、内部有效性评估和相关性测试评估。 良好聚类算法的特征 良好的可伸缩性处理不同类型数据的能力处理噪声数据的能力对样本顺序的不敏感性约束条件下的表现易解释性和易用性 聚类分析的要求不同的聚类算法有不同的应用背景,有的适合于大数据集,可以发现任意形状的聚簇;有的算法思想简单,适用于小数据集。总的来说,数据挖掘中针对聚类的典型要求包括: (1)可伸缩性:当数据量从几百上升到几百万时,聚类结果的准确度能一致。 (2)处理不同类型属性的能力:许多算法针对的数值类型的数据。但是,实际应用场景中,会遇到二元类型数据,分类/标称类型数据,序数型数据。 (3)发现任意形状的类簇:许多聚类算法基于距离(欧式距离或曼哈顿距离)来量化对象之间的相似度。基于这种方式,我们往往只能发现相似尺寸和密度的球状类簇或者凸型类簇。但是,实际中类簇的形状可能是任意的。 (4)初始化参数的需求最小化:很多算法需要用户提供一定个数的初始参数,比如期望的类簇个数,类簇初始中心点的设定。聚类的结果对这些参数十分敏感,调参数需要大量的人力负担,也非常影响聚类结果的准确性。 (5)处理噪声数据的能力:噪声数据通常可以理解为影响聚类结果的干扰数据,包含孤立点,错误数据等,一些算法对这些噪声数据非常敏感,会导致低质量的聚类。 (6)增量聚类和对输入次序的不敏感:一些算法不能将新加入的数据快速插入到已有的聚类结果中,还有一些算法针对不同次序的数据输入,产生的聚类结果差异很大。 (7)高维性:有些算法只能处理2到3维的低纬度数据,而处理高维数据的能力很弱,高维空间中的数据分布十分稀疏,且高度倾斜。 (8)可解释性和可用性:我们希望得到的聚类结果都能用特定的语义、知识进行解释,和实际的应用场景相联系。 几种常用的聚类算法从可伸缩性、适合的数据类型、高维性(处理高维数据的能力)、异常数据的抗干扰度、聚类形状和算法效率6个方面进行了综合性能评价 算法名称算法类型可伸缩性适合的数据类型高维性异常数据的抗干扰性聚类形状算法效率ROCK层次聚类很高混合型很高很高任意形状一般BIRCH层次聚类较高数值型较低较低球形很高CURE层次聚类较高数值型一般很高任意形状较高CLARANS划分聚类较低数值型较低较高球形较低DENCLUE密度聚类较低数值型较高一般任意形状较高DBSCAN密度聚类一般数值型较低较高任意形状一般WaveCluster网格聚类很高数值型很高较高任意形状很高OptiGrid网格聚类一般数值型较高一般任意形状一般CLIQUE网格聚类较高数值型较高较高任意形状较低 聚类分析的度量聚类分析的度量指标用于对聚类结果进行评判,分为内部指标和外部指标两大类 外部指标指用事先指定的聚类模型作为参考来评判聚类结果的好坏内部指标是指不借助任何外部参考,只用参与聚类的样本评判聚类结果好坏 外部指标对于含有݊n个样本点的数据集ܵS,其中的两个不同样本点 ( x i , y j ) (x_i,y_j) (xi,yj)假设C是聚类算法给出的簇划分结果,ܲP是外部参考模型给出的簇划分结果。那么对于样本点 x i , y j x_i,y_j xi,yj来说,存在以下四种关系: SS: x i , y j x_i,y_j xi,yj在C和P中属于相同的簇ܲSD: x i , y j x_i,y_j xi,yj在C中属于相同的簇ܲ,在P中属于不同的簇ܲDS: x i , y j x_i,y_j xi,yj在C中属于不同的簇ܲ,在P中属于相同的簇ܲDD: x i , y j x_i,y_j xi,yj在C和P中属于不同的簇ܲ 令 a , b , c , d a,b,c,d a,b,c,d分别表示 S S , S D , D S , D D SS,SD,DS,DD SS,SD,DS,DD所对应的关系数目, 由于 x i , y j x_i,y_j xi,yj所对应的关系必定存在于四种关系中的一种,且仅能存在一种关系 Rand统计量(Rand Statistic) R = a + d a + b + c + d R=\frac{a+d}{a+b+c+d} R=a+b+c+da+dF值(F‐measure) P = a a + b P=\frac{a}{a+b} P=a+ba , R = a a + c R=\frac{a}{a+c} R=a+ca,(ܲP表示准确率,ܴR表示召回率) F = ( β 2 + 1 ) P R β 2 P + R , β F=\frac{(\beta^2+1)PR}{\beta^2P+R} ,\beta F=β2P+R(β2+1)PR,β是参数,当 β = 1 \beta=1 β=1时,就是最常见的 F 1 ‐ m e a s u r e F1‐measure F1‐measure Jaccard系数(Jaccard Coefficient) J = a a + b + c J=\frac{a}{a+b+c} J=a+b+caFM指数(Fowlkes and Mallows Index) F M = a a + b ∗ a a + c = P ∗ R FM=\sqrt{\frac{a}{a+b}*\frac{a}{a+c}}=\sqrt{P*R} FM=a+ba∗a+ca =P∗R 以上四个度量指标的值越大,表明聚类结果和参考模型直接的划分结果越吻合,聚类结果就越好 内部指标在聚类分析中,对于两个݉m维样本 x i = ( x i 1 , x i 2 , . . . , x i m ) x_i=(x_{i1},x_{i2},...,x_{im}) xi=(xi1,xi2,...,xim)和 x j = ( x j 1 , x j 2 , . . . , x j m ) x_j=(x_{j1},x_{j2},...,x_{jm}) xj=(xj1,xj2,...,xjm) 常用的距离度量有欧式距离、曼哈顿距离、切比雪夫距离和明可夫斯基距离等 欧式距离(Euclidean Distance)是计算欧式空间中两点之间的距离,是最容易理解的距离计算方法,其计算公式如下: d i c t e d = ∑ k = 1 m ( x i k − x j k ) 2 dict_{ed}=\sqrt{\sum_{k=1}^{m}(x_{ik}-x_{jk}})^2 dicted=k=1∑m(xik−xjk )2 曼哈顿距离(Manhattan Distance)也称城市街区距离,欧式距离表明了空间中两点间的直线距离,但是在城市中,两个地点之间的实际距离是要沿着道路行驶的距离,而不能计算直接穿过大楼的直线距离,曼哈顿距离就用于度量这样的实际行驶距离 d i c t m a n d = ∑ k = 1 m ∣ x i k − x j k ∣ dict_{mand}=\sum_{k=1}^m|x_{ik}-x_{jk}| dictmand=k=1∑m∣xik−xjk∣ 切比雪夫距离(Chebyshev Distance)是向量空间中的一种度量,将空间坐标中两个点的距离定义为其各坐标数值差绝对值的最大值。切比雪夫距离在国际象棋棋盘中,表示国王从一个格子移动到此外一个格子所走的步数 d i c t c d = lim t → ∞ ( ∑ k = 1 m ∣ x i k − x j k ∣ t ) 1 t dict_{cd}=\underset{t\to \infty}{\mathop{\lim }}\, (\sum_{k=1}^m|x_{ik}-x_{jk}|^t)^{\frac{1}{t}} dictcd=t→∞lim(k=1∑m∣xik−xjk∣t)t1 明可夫斯基距离(Minkowski Distance)是欧式空间的一种测度,是一组距离的定义,被看作是欧式距离和曼哈顿距离的一种推广 d i c t m i n d = ∑ k = 1 m ∣ x i k − x j k p ∣ p dict_{mind}=\sqrt[p]{\sum_{k=1}^{m}|x_{ik}-x_{jk}}|^p dictmind=pk=1∑m∣xik−xjk ∣p 其中p是一个可变的参数,根据p取值的不同,明可夫斯基距离可以表示一类距离。当p=1时,明可夫斯基距离就变成了曼哈顿距离;当p=2时,明可夫斯基距离就变成了欧式距离;当 p → ∞ p\to \infty p→∞时,明可夫斯基距离就变成了切比雪夫距离我们知道,很多时候数据的不同变量标度是不一样的,比如x1是(2000,3000)之间的变量,而x2是(10-20)之间的变量,那么,我们需要对数据进行标准化,一般情况下我们都是对数据进行Z-score标准化: Z f = X f − m e a n f S f Z_f=\frac{X_f-mean_f}{S_f} Zf=SfXf−meanf根据空间中点的距离度量,可以得出以下聚类性能度量内部指标紧密度(Compactness)是每个簇中的样本点到聚类中心的平均距离。对于有݊n个样本点的簇C来说,该簇的紧密度为:
C
P
c
=
=
1
n
∑
i
=
1
n
∣
∣
x
i
−
C
∣
∣
CP_c==\frac{1}{n}\sum_{i=1}{n}||x_i-C||
CPc==n1∑i=1n∣∣xi−C∣∣, 其中
w
c
w_c
wc为簇ܿc的聚类中心; 对于聚类结果,需要使用所有簇紧密度的平均值来衡量聚类结果的好坏,假设总共有݇k个簇:
C
P
=
1
k
∑
i
=
1
k
C
P
i
CP=\frac{1}{k}\sum_{i=1}{k}CP_i
CP=k1∑i=1kCPi, 紧密度的值越小,表示簇内样本点的距离越近,即簇内样本的相似度越高 分隔度(Seperation)是各簇的聚类中心ܿc_i,c_j两两之间的平均距离,其计 算公式如下:
D
P
=
2
k
2
−
k
∑
i
=
1
k
∑
j
=
i
+
1
k
∣
∣
c
i
−
c
j
∣
∣
DP=\frac{2}{k^2-k}\sum^{k}_{i=1}\sum_{j=i+1}^{k}||c_i-c_j||
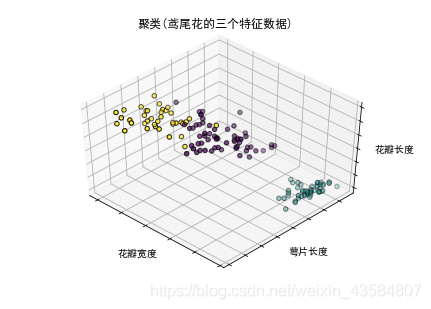
DP=k2−k2∑i=1k∑j=i+1k∣∣ci−cj∣∣, 分隔度的值越大,表示各聚类中心相互之间的距离越远,即簇间相似度越低 基于划分的方法是简单、常用的一种聚类方法,它通过将对象划分为互斥的簇进行聚类, 每个对象属于且仅属于一个簇;划分结果旨在使簇之间的相似性低,簇内部的相似度高;基于划分的方法常用算法有k均值、k‐medoids、k‐prototype等 K-means聚类k‐均值聚类是基于划分的聚类算法,计算样本点与类簇质心的距离,与类簇质心相近的样本点划分为同一类簇。k‐均值通过样本间的距离来衡量它们之间的相似度,两个样本距离越远,则相似度越低,否则相似度越高 k-均值算法: 选择 K 个初始质心(K需要用户指定),初始质心随机选择即可,每一个质心为一个类对剩余的每个样本点,计算它们到各个质心的欧式距离,并将其归入到相互间距离最小的质心所在的簇。计算各个新簇的质心。在所有样本点都划分完毕后,根据划分情况重新计算各个簇的质心所在位置,然后迭代计算各个样本点到各簇质心的距离,对所有样本点重新进行划分重复2. 和 3.,直到质心不在发生变化时或者到达最大迭代次数时优缺点及拓展: k‐均值算法原理简单,容易实现,且运行效率比较高(优点)k‐均值算法聚类结果容易解释,适用于高维数据的聚类(优点)k‐均值算法采用贪心策略,导致容易局部收敛,在大规模数据集上求解较慢(缺点)k‐均值算法对离群点和噪声点非常敏感,少量的离群点和噪声点可能对算法求平均值产生极大影响,从而影响聚类结果(缺点)k‐均值算法中初始聚类中心的选取也对算法结果影响很大,不同的初始中心可能会导致不同的聚类结果。对此,研究人员提出k‐均值++算法,其思想是使初始的聚类中心之间的相互距离尽可能远 K-means++聚类k‐均值++算法: 从样本集߯X 随机选择一个样本点ܿ c 1 c_1 c1作为第1个聚类中心;计算其它样本点x到最近的聚类中心的距离݀d(x);以概率 d ( x ) 2 ∑ ∈ x d ( x ) 2 \frac{d(x)^2}{\sum_{∈x}d(x)^2} ∑∈xd(x)2d(x)2 选择一个新样本点ܿ c i c_i ci加入聚类中心点集合中,其中距离值݀ d ( x ) d(x) d(x)越大,被选中的可能性越高;重复步骤(2)和(3)选定k个聚类中心;基于这k个聚类中心进行k‐均值运算k‐均值++算法的优缺点 优点: 提高了局部最优点的质量 收敛更快缺点: 相比随机选择中心点计算较大sklearn.cluster.KMeans¶(官网)函数默认使用k-means++算法(init=‘k-means++’): class sklearn.cluster.KMeans(n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distances=‘auto’, verbose=0, random_state=None, copy_x=True, n_jobs=None, algorithm=‘auto’) 代码1(鸢尾花的三个特征聚类) # -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D from sklearn.cluster import KMeans from sklearn import datasets plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 def visual(X,y): fig = plt.figure(1, figsize=(6, 4)) ax = Axes3D(fig, rect=[0, 0, .95, 1], elev=48, azim=134) ax.scatter(X[:, 3], X[:, 0], X[:, 2],c=labels.astype(np.float), edgecolor='k') ax.w_xaxis.set_ticklabels([]) ax.w_yaxis.set_ticklabels([]) ax.w_zaxis.set_ticklabels([]) ax.set_xlabel('花瓣宽度') ax.set_ylabel('萼片长度') ax.set_zlabel('花瓣长度') ax.set_title("聚类(鸢尾花的三个特征数据)") ax.dist = 12 plt.show() if __name__=='__main__': np.random.seed(5) iris = datasets.load_iris() X = iris.data y = iris.target est = KMeans(n_clusters=3) est.fit(X) labels = est.labels_ visual(X,y)
对k值的选取,主要有以下几种: 与层次聚类算法结合,先通过层次聚类算法得出大致的聚类数目,并且获得一个初始聚类结果,然后再通过k‐均值算法改进聚类结果基于系统演化的方法,将数据集视为伪热力学系统,在分裂和合并过程中,将系统演化到稳定平衡状态从而确定k值 拓展:KNN和K-means的不同写到这里,让我想起了k-近邻算法(KNN),那么他们之间存在着哪些异同点? KNN首先,KNN是什么? KNN是通过测量不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离。 下面通过一个简单的例子说明一下: 如右图,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。由此也说明了KNN算法的结果很大程度取决于K的选择。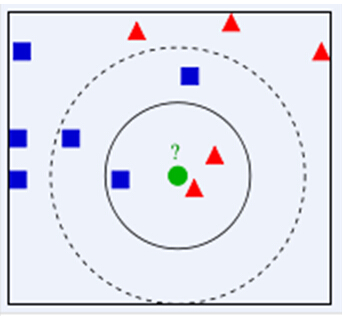
KNN算法:在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为: 1)计算测试数据与各个训练数据之间的距离; 2)按照距离的递增关系进行排序; 3)选取距离最小的K个点; 4)确定前K个点所在类别的出现频率; 5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。 KNN和K-means的区别K-means算法把一个数据集分割成簇,使得形成的簇是同构的,每个簇里的点相互靠近。该算法试图维持这些簇之间有足够的可分离性。由于无监督的性质,这些簇没有任何标签。 KNN算法尝试基于其k(可以是任何数目)个周围邻居来对未标记的观察进行分类。它也被称为懒惰学习法,因为它涉及最小的模型训练。因此,它不用训练数据对未看见的数据集进行泛化 KNN算法原理 分类算法 监督学习 数据集是带标签的数据 没有明显的训练过程,基于Memory-based learning K值含义 - 对于一个样本X,要给它分类,首先从数据集中,在X附近找离它最近的K个数据点,将它划分为归属于类别最多的一类K-means算法原理 聚类算法非监督学习数据集是无Label,杂乱无章的数据有明显的训练过程K值含义- K是事先设定的数字,将数据集分为K个簇,需要依靠人的先验知识 k‐medoids算法 K-means 算法,它是基于“质心”的聚类方法。算法快速高效,但也面临一些短板,特别是样本中的异常数据,可能会使聚类结果产生严重偏离。k‐medoids 算法克服了k‐均值算法的这一缺点, k ‐medoids算法不通过计算簇中所有样本的平均值得到簇的中心,而是通过选取原有样本中的样本点作为代表对象代表这个簇,计算剩下的样本点与代表对象的距离,将样本点划分到与其距离最近的代表对象所在的簇中。1、任意选取 k 个点作为 medoids 2、按照与medoids最近的原则,将剩余点分配到当前最佳的medoids代表的类中 3、在每一类中,计算每个成员点对应的准则函数,选取准则函数最小时对应的点作为新的 medoids(其中准则函数为,一类中,某个成员点和其他成员点的距离之和) 4、重复2、3、的过程,直到所有的 medoids 点不再发生变化,或已达到设定的最大迭代次数 k‐medoids算法的距离计算过程与k均值算法的计算过程类似,只是将距离度量中的中心替换为代表对象,绝对误差标准: E = ∑ i = 1 k ∑ ( j ) ∈ C i ∣ ∣ x j − o c ( i ) ∣ ∣ 2 E=\sum^k_{i=1}\sum_{(j)\in C_i}||x^{j}-o_c(i)||^2 E=∑i=1k∑(j)∈Ci∣∣xj−oc(i)∣∣2,式中 o c ( i ) o_c(i) oc(i)表示第݅ i i i簇 C i C_i Ci的中心, x j x^{j} xj 表示 C i C_i Ci簇中的点, E E E最小表示最小化所有簇中点与点之间距离优缺点 优点:当存在噪音和孤立点时, K-medoids 比 K-means 更健壮。 缺点:K-medoids 对于小数据集工作得很好, 但不能很好地用于大数据集,计算质心的步骤时间复杂度是O(n^2),运行速度较慢 PAM算法k ‐medoids聚类的一种典型实现是围绕中心点划分(Partitioning Around Mediods, PAM)算法 。PAM 算法中簇的中心点是一个真实的样本点而不是通过距离计算出来的中心。PAM算法与k均值一样,使用贪心策略来处理聚类过程 k‐均值迭代计算簇的中心的过程,在PAM算法中对应计算是否替代对象 o ′ o' o′比原来的代表对象o能够具有更好的聚类结果,替换后对所有样本点进行重新计算各自代表样本的绝对误差标准。若替换后,替换总代价小于0,即绝对误差标准减小,则说明替换后能够得到更好的聚类结果,若替换总代价大于0,则不能得到更好的聚类结果,原有代表对象不进行替换。在替换过程中,尝试所有可能的替换情况,用其他对象迭代替换代表对象,直到聚类的质量不能再被提高为止(贪心算法)PAM算法基本流程如下: 首先随机选择k个对象作为中心,把每个对象分配给离它最近的中心。 然后随机地选择一个非中心对象替换中心对象,计算分配后的距离变化量 如果总的损失减少,则交换中心对象和非中心对象; 如果总的损失增加,则不进行交换 聚类的过程就是不断迭代,进行中心对象和非中心对象的反复替换过程,直到目标函数不再有改进为止。 通常,如果能够迭代所有情况,那么最终得到的划分一定是最优的划分,即聚类结果最好,这通常适用于聚类比较小的点的集合。但是如果待聚类的点的集合比较大,则需要通过限制迭代次数来终止迭代计算,从而得到一个能够满足实际精度需要的聚类结果。 不得不说,K-means和PAM算法都不可避免有一个弱点,就是计算量上都是随着初始数据量的增大而几何增长的,它适用于小型数据集,那么有什么算法是可以用于大规模的数据集呢?接下来我们将了解CLARA算法以及他衍生出来的算法 CLARA算法CLARA(Clustering LARge Applications)是应用于大规模数据的聚类,它弥补了k-mediod / PAM算法只能应用于小规模数据的缺陷。 当面对一个大样本量时,CLARA首先通过运用类似于randomforest的随机抽样的方法,每次随机选取样本量中的一小部分进行PAM聚类,然后将剩余样本按照最小中心距离进行归类。在各次重复抽样聚类的结果中,选取误差最小,即中心点代换代价最小的结果作为最终结果。核心是,先对大规模数据进行多次采样,每次采样样本进行k-mediod聚类,然后将多次采样的样本聚类中心进行比较,选出最优的聚类中心. CLARA算法基本流程如下: 1.对大规模数据进行多次采样得到采样样本 2.对每次采样的样本进行PAM聚类,得到多组聚类中心 3.求出每组聚类中心到其他所有点距离和. 4.找出这几组距离和的最小值,距离和最小的那组就是最优的聚类中心. 5.然后将大规模数据按照距离聚类到这组最优聚类中心 CLARA的有效性依赖于样本的大小,分布及质量,所以该算法一定程度上会依赖于初始抽样的质量。另外,CLARA的算法是确定了中心后不在改变,这会有一定的运气成分,假设确定的k个对象离最佳中心很远,那么CLARA最后怎样选择中心,都得不到最优秀的聚类中心。 CLARANS算法CLARANS算法是在CLARA的基础上发展而来的,在CLARA确定中心之后,按照PAM中的方法,在子集上选取一个与当前中心x(Medoid)不一样的对象y(New Medoid),计算用y(New Medoid)替换x(Medoid)后绝对误差是否下降,下降则替换否则不变,重复一定的次数后,我们可以认为此时的中心点为局部中心最优解;整体数据集所有子集均重复m次后,得出的中心点为全局局部最优解。CLARANS算法融合了PAM和CLARA两者的优点,是第一个用于空间数据库的聚类算法。除了这个算法,还有CLARANS+算法,感兴趣的盆友可以阅读这位大佬的文章:大数据量下的划分聚类方法 k‐prototype算法K-prototype是处理混合属性聚类的典型算法。它继承K-means算法和K-modes算法的思想,适用于数值类型与字符类型集合的数据。K-prototype是在聚类过程中引入参数 γ \gamma γ来控制数值属性和分类属性的权重。 对于݉ m m m维样本 x i = ( x i 1 r , x i 2 r , x i p r , x i ( p + 1 ) r , x i m r ) x_i=(x_{i1}^r, x_{i2}^r,x_{ip}^r,x_{i(p+1)}^r,x_{im}^r) xi=(xi1r,xi2r,xipr,xi(p+1)r,ximr),),其中标号为 1 1 1至 p p p下标的属性为数值型, p + 1 p+ 1 p+1到 m m m下标的属性为分类型。.请看下面的公式: 定义样本与簇的距离为: d ( x i , Q i ) = ∑ j = 1 p ( x i j r − q i j r ) 2 + γ i ∑ j = p + 1 m δ ( x i j c , q i j c ) d(x_i,Q_i)=\sum^p_{j=1}(x_{ij}^r-q^r_{ij})^2+\gamma_i\sum^m_{j=p+1}\delta(x_{ij}^c,q_{ij}^c) d(xi,Qi)=∑j=1p(xijr−qijr)2+γi∑j=p+1mδ(xijc,qijc)(其中 x i j r x_{ij}^r xijr和 x i j c x_{ij}^c xijc分别是 x i x_i xi第݆ j j j个属性的数值属性取值和分类属性取值, q i j r q^r_{ij} qijr和 q i j c q^c_{ij} qijc分别是聚类݈ l l l的原型ܳ Q i Q_i Qi的数值属性取值和分类属性取值, δ \delta δ为符号函数) 总结 度量具有混合属性的方法是,数值属性采用K-means方法得到P1,分类属性采用K-modes方法P2,那么D=P1+a*P2,a是权重。如果觉得分类属性重要,则增加a,否则减少a,a=0时即只有数值属性【结合上面的公式可知, P 1 = ∑ j = 1 p ( x i j r − q i j r ) 2 P1=\sum^p_{j=1}(x_{ij}^r-q^r_{ij})^2 P1=∑j=1p(xijr−qijr)2 , a = γ i a=\gamma_i a=γi, P 2 = ∑ j = p + 1 m δ ( x i j c , q i j c ) P2=\sum^m_{j=p+1}\delta(x_{ij}^c,q_{ij}^c) P2=∑j=p+1mδ(xijc,qijc)】更新一个簇的中心的方法,方法是结合K-means与K-modes的更新。 总结基于划分的几种算法k-means 是一种典型的划分聚类算法,它用一个聚类的中心来代表一个簇,即在迭代过程中选择的聚点不一定是聚类中的一个点,该算法只能处理数值型数据 k-modes K-Means算法的扩展,采用简单匹配方法来度量分类型数据的相似度 k-prototypes 结合了K-Means和K-Modes两种算法,能够处理混合型数据 k-medoids 在迭代过程中选择簇中的某点作为聚点,PAM是典型的k-medoids算法 CLARA CLARA算法在PAM的基础上采用了抽样技术,能够处理大规模数据 CLARANS CLARANS算法融合了PAM和CLARA两者的优点,是第一个用于空间数据库的聚类算法 PCM(点击跳转链接了解PCM) 模糊集合理论引入聚类分析中并提出了PCM模糊聚类算法 基于层次的聚类层次聚类的应用广泛程度仅次于基于划分的聚类,核心思想是通过对数据集按照层次,把数据划分到不同层的簇,从而形成一个树形的聚类结构。层次聚类算法可以揭示数据的分层结构,在树形结构上不同层次进行划分,可以得到不同粒度的聚类结果。按照层次聚类的过程分为自底向上的聚合聚类和自顶向下的分裂聚类。聚合聚类以AGNES、BIRCH、ROCK等算法为代表,分裂聚类以DIANA算法为代表。 自底向上的聚合聚类将每个样本看作一个簇,初始状态下簇的数目等于样本的数目,然后然后根据一定的算法规则,例如把簇间距离最小的相似簇合并成越来越大的簇,直到满足算法的终止条件。自顶向下的分裂聚类先将所有样本看作属于同一个簇,然后逐渐分裂成更小的簇,直到满足算法终止条件为止。 目前大多数是自底向上的聚合聚类,自顶向下的分裂聚类比较少AGNES 算法最初将每个对象作为一个簇,然后这些簇根据某些准则被一步步地合并。两个簇间的相似度有多种不同的计算方法。聚类的合并过程反复进行直到所有的对象最终满足簇数目。 AGNES算法步骤 输入:包含n个对象的数据库。 输出:满足终止条件的若干个簇。 (1) 将每个对象当成一个初始簇; (2) 重复 (3) 计算任意两个簇的距离,并找到最近的两个簇; (4) 合并两个簇,生成新的簇的集合; (5) 直到 终止条件得到满足。 优缺点 简单,理解容易 合并点/分裂点选择不太容易 合并/分类的操作不能进行撤销 大数据集不太适合 执行效率较低 BIRCH(平衡迭代削减聚类法)BIRCH(Balanced Iterative Reducingand Clustering Using Hierarchies利用层次方法的平衡迭代规约和聚类)主要是在数据量很大的时候使用,而且数据类型是numerical。首先利用树的结构对对象集进行划分,然后再利用其它聚类方法对这些聚类进行优化; BIRCH算法的优缺点: 适合大规模数据集,线性效率 只适合分布呈凸形或者球形的数据集,需要给定聚类个数和簇直径的限制 CURE算法(使用代表点的聚类法)CURE算法先把每个数据点看成一类,然后合并距离最近的类直至类个数为所要求的个数为止。但是和AGNES算法的区别是:取消了使用所有点或用中心点+距离来表示一个类,而是从每个类中抽取固定数量、分布较好的点作为此类的代表点,并将这些代表点乘以一个适当的收缩因子,使它们更加靠近类中心点。代表点的收缩特性可以调整模型可以匹配那些非球形的场景,而且收缩因子的使用可以减少噪音对聚类的影响。 CURE算法的优缺点: 能够处理非球形分布的应用场景 采用随机抽样和分区的方式可以提高算法的执行效率 ROCKROCK(A Hierarchical ClusteringAlgorithm for Categorical Attributes)主要用在categorical的数据类型上;Chameleon(A Hierarchical Clustering AlgorithmUsing Dynamic Modeling)里用到的linkage是kNN(k-nearest-neighbor)算法,并以此构建一个graph,Chameleon的聚类效果被认为非常强大,比BIRCH好用,但运算复杂度很高,O(n^2)。 代码AgglomerativeClustering是scikit-learn提供的层级聚类算法模型。一般只需要设置参数linkage和n_clusters, 其中n_clusters是一个正整数,指定分类簇的数量; linkage是一个字符串,用于指定链接算法 :当其值为“ward”时表示采用单链接方法,值为“complete”时表示采用全链接方法,若取值为“average”时则使用均连接方法。 # -*- coding: utf-8 -*- from sklearn import datasets from sklearn.cluster import AgglomerativeClustering import matplotlib.pyplot as plt from sklearn.metrics import confusion_matrix import pandas as pd iris = datasets.load_iris() irisdata = iris.data clustering = AgglomerativeClustering(linkage='ward', n_clusters=3) res = clustering.fit(irisdata) print "各个簇的样本数目:" print pd.Series(clustering.labels_).value_counts() print "聚类结果:" print confusion_matrix(iris.target,clustering.labels_) plt.figure() d0 = irisdata[clustering.labels_==0] plt.plot(d0[:,0],d0[:,1],'r.') d1 = irisdata[clustering.labels_==1] plt.plot(d1[:,0],d1[:,1],'go') d2 = irisdata[clustering.labels_==2] plt.plot(d2[:,0],d2[:,1],'b*') plt.xlabel("Sepal.Length") plt.ylabel("Sepal.Width") plt.title("AGNES Clustering") plt.show() #输出: #各个簇的样本数目: #0 64 #1 50 #dtype: int64 #聚类结果: #[[ 0 50 0] # [49 0 1] # [15 0 35]]
CURE 采用抽样技术先对数据集D随机抽取样本,再采用分区技术对样本进行分区,然后对每个分区局部聚类,最后对局部聚类进行全局聚类 ROCK 也采用了随机抽样技术,该算法在计算两个对象的相似度时,同时考虑了周围对象的影响 CHEMALOEN(变色龙算法) 首先由数据集构造成一个K-最近邻图Gk ,再通过一个图的划分算法将图Gk 划分成大量的子图,每个子图代表一个初始子簇,最后用一个凝聚的层次聚类算法反复合并子簇,找到真正的结果簇 SBAC SBAC算法则在计算对象间相似度时,考虑了属性特征对于体现对象本质的重要程度,对于更能体现对象本质的属性赋予较高的权值 BIRCH BIRCH算法利用树结构对数据集进行处理,叶结点存储一个聚类,用中心和半径表示,顺序处理每一个对象,并把它划分到距离最近的结点,该算法也可以作为其他聚类算法的预处理过程 BUBBLE BUBBLE算法则把BIRCH算法的中心和半径概念推广到普通的距离空间 BUBBLE-FM BUBBLE-FM算法通过减少距离的计算次数,提高了BUBBLE算法的效率 基于密度的聚类基于划分聚类和基于层次聚类的方法在聚类过程中根据距离来划分类簇,因此只能够用于挖掘球状簇。但往往现实中还会有各种形状,这时上面的两大类算法将不适用了。 DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。 该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。 看了赵卫东老师和嵩天老师关于这部分的介绍,我可以说,不是很容易懂,不过,下面这两个网站可以让我们看懂很DBSCAN 算法:首先先看第一个,看了之后再看下面这个配套动画讲解DBSCAN算法的国外网站,你会发现看我下面写的东西原来也不是那么难理解了 DBSCAN聚类算法——机器学习(理论+图解+python代码),Visualizing DBSCAN Clustering关于DBSCAN密度聚类算法,它聚类的时候不需要预先指定簇的个数,最终的簇的个数不定 参数选择 半径:半径是最难指定的 ,大了,圈住的就多了,簇的个数就少了;反之,簇的个数就多了,这对我们最后的结果是有影响的。我们这个时候K距离可以帮助我们来设定半径r,也就是要找到突变点,比如: MinPts:这个参数就是圆能够圈住的点的个数,也相当于是一个密度,一般这个值都是偏小一些,然后进行多次尝试DBSCAN算法将数据点分为三类:
核心点:在半径Eps内含有超过MinPts数目的点边界点:在半径Eps内点的数量小于MinPts,但是落在核心点的邻域内噪音点:既不是核心点也不是边界点的点 MinPts:这个参数就是圆能够圈住的点的个数,也相当于是一个密度,一般这个值都是偏小一些,然后进行多次尝试DBSCAN算法将数据点分为三类:
核心点:在半径Eps内含有超过MinPts数目的点边界点:在半径Eps内点的数量小于MinPts,但是落在核心点的邻域内噪音点:既不是核心点也不是边界点的点
取半径为3,MinPts为3(圆圈能够圈住的最小的数目),则可以得到如下的分类结果,其中,P9为噪声点,P10为噪声点 DBSCAN算法的主要缺点在于其欧氏距离计算的复杂性,提高该算法的效率,同时保证聚类的精度,Kieu等人提出了WS-DBSCAN (Weighted-Stop Density-Based Scanning Algorithm with Noise)算法。 算法特征 与典型的DBSCAN算法相比,WS-DBSCAN算法有如下特征: ① DBSCAN在分析数据时,属于一次性分析,每组不同的数据需要重新分析;而WS-DBSCAN会充分利用现存(旧)数据的特征分析新数据。 ② DBSCAN会对所有点的邻近区域搜索,从而确定该点归属;而WS-DBSCAN只在必要时才对该点邻近区域实施搜索。 ③ WS-DBSCAN在聚类时,会给予点属性,以该点邻近区域所有点属性值之和是否超过MinPts,作为判断是否为核心点的标准。 Kieu等人在DBSCAN算法定义的基础上,定义了点p的权重ε邻域(weighted ε-neighborhood):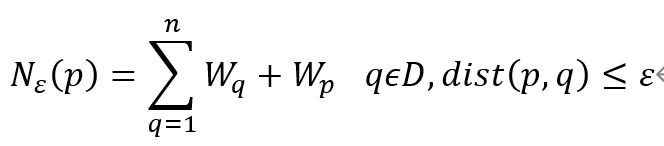 MDCA 算法(密度最大值聚类算法)
MDCA 算法(密度最大值聚类算法)
MDCA(Maximum Density Clustering Application)算法基于密度的思想引入划分聚类中,使用密度而不是初始点作为考察簇归属情况的依据,能够自动确定簇数量并发现任意形状的簇。另外MDCA一般不保留噪声,因此也避免了阈值选择不当情况下造成的对象丢弃情况。 MDCA算法的基本思路是寻找最高密度的对象和它所在的稠密区域 总结基于密度的几种算法DBSCAN DBSCAN算法是一种典型的基于密度的聚类算法,该算法采用空间索引技术来搜索对象的邻域,引入了“核心对象”和“密度可达”等概念,从核心对象出发,把所有密度可达的对象组成一个簇 GDBSCAN 算法通过泛化DBSCAN算法中邻域的概念,以适应空间对象的特点 OPTICS OPTICS算法结合了聚类的自动性和交互性,先生成聚类的次序,可以对不同的聚类设置不同的参数,来得到用户满意的结果 FDC FDC算法通过构造k-d tree把整个数据空间划分成若干个矩形空间,当空间维数较少时可以大大提高DBSCAN的效率 代码 # -*- coding: utf-8 -*- #============================================================================== # 基于sklearn实现DBSCAN算法 #============================================================================== import numpy as np import pandas as pd from sklearn import datasets from sklearn.cluster import dbscan data,_ = datasets.make_moons(500,noise = 0.1,random_state=1) #创建数据集 df = pd.DataFrame(data,columns = ['feature1','feature2']) #将数据集转换为dataframe #第二步:创建数据集并作可视化处理 ##绘制样本点,s为样本点大小,aplha为透明度,设置图形名称 #看下面第1个图 df.plot.scatter('feature1','feature2', s = 100,alpha = 0.6, title = 'dataset by make_moon') #DBSCAN算法 # eps为邻域半径,min_samples为最少点数目 core_samples,cluster_ids = dbscan(data, eps = 0.2, min_samples=20) # cluster_id=k,k为非负整数时,表示对应的点属于第k簇,k为簇的编号,当k=-1时,表示对应的点为噪音点 # np.c_用于合并按行两个矩阵,可以看下面第3个图 #(要求两个矩阵行数相等,这里表示将样本数据特征与对应的簇编号连接) df = pd.DataFrame(np.c_[data,cluster_ids],columns = ['feature1','feature2','cluster_id']) # astype函数用于将pandas对象强制转换类型,这里将浮点数转换为整数类型 df['cluster_id'] = df['cluster_id'].astype('int') # 绘图,c = list(df['cluster_id'])表示样本点颜色按其簇的编号绘制 # cmap=rainbow_r表示颜色从绿到黄,colorbar = False表示删去显示色阶的颜色栏 #看下面第2个图 df.plot.scatter('feature1','feature2', s = 100, c = list(df['cluster_id']),cmap = 'rainbow_r',colorbar = False, alpha = 0.6,title = 'DBSCAN cluster result')图1:未运用DBSCAN算法进行处理的数据图: 基于划分和层次聚类方法都无法发现非凸面形状的簇,真正能有效发现任意形状簇的算法是基于密度的算法,但基于密度的算法一般时间复杂度较高,1996年到2000年间,研究数据挖掘的学者们提出了大量基于网格的聚类算法,网格方法可以有效减少算法的计算复杂度,且同样对密度参数敏感。 基于网格的聚类通常将数据空间划分成有限个单元的网格结构,所有的处理都是以单个的单元为对象。这样做起来处理速度很快,因为这与数据点的个数无关,而只与单元个数有关。代表算法有:STING,CLIQUE,WaveCluster。 STING:基于网格多分辨率,将空间划分为方形单元,对应不同分辨率CLIQUE:结合网格和密度聚类的思想,子空间聚类处理大规模高维度数据WaveCluster:用小波分析使簇的边界变得更加清晰这些算法用不同的网格划分方法,将数据空间划分成为有限个单元(cell)的网格结构,并对网格数据结构进行了不同的处理,但核心步骤是相同的: 1、 划分网格 2、 使用网格单元内数据的统计信息对数据进行压缩表达 3、 基于这些统计信息判断高密度网格单元 4、 最后将相连的高密度网格单元识别为簇 网格聚类算法对比
STING 利用网格单元保存数据统计信息,从而实现多分辨率的聚类 WaveCluster 在聚类分析中引入了小波变换的原理,主要应用于信号处理领域。(备注:小波算法在信号处理,图形图像,加密解密等领域有重要应用,是一种比较高深和牛逼的东西) CLIQUE 是一种结合了网格和密度的聚类算法 OPTIGRID 基于模型的聚类基于模型的方法(Model-based methods)主要是指基于概率模型的方法和基于神经网络模型的方法,尤其以基于概率模型的方法居多。这里的概率模型主要指概率生成模型(generative Model),同一”类“的数据属于同一种概率分布。这中方法的优点就是对”类“的划分不那么”坚硬“,而是以概率形式表现,每一类的特征也可以用参数来表达;但缺点就是执行效率不高,特别是分布数量很多并且数据量很少的时候。其中最典型、也最常用的方法就是高斯混合模型(GMM,Gaussian Mixture Models)。基于神经网络模型的方法主要就是指SOM(Self Organized Maps)了,也是我所知的唯一一个非监督学习的神经网络了。 基于神经网络模型的聚类 自组织神经网络SOM(Self Organized Maps)该算法假设在输入对象中存在一些拓扑结构或顺序,可以实现从输入空间(n维)到输出平面(2维)的降维映射,其映射具有拓扑特征保持性质,与实际的大脑处理有很强的理论联系。 SOM网络包含输入层和输出层。输入层对应一个高维的输入向量,输出层由一系列组织在2维网格上的有序节点构成,输入节点与输出节点通过权重向量连接。学习过程中,找到与之距离最短的输出层单元,即获胜单元,对其更新。同时,将邻近区域的权值更新,使输出节点保持输入向量的拓扑特征。 算法流程: 网络初始化,对输出层每个节点权重赋初值;将输入样本中随机选取输入向量,找到与输入向量距离最小的权重向量;定义获胜单元,在获胜单元的邻近区域调整权重使其向输入向量靠拢;提供新样本、进行训练;收缩邻域半径、减小学习率、重复,直到小于允许值,输出聚类结果。 基于概率模型的聚类基于概率模型的聚类技术已被广泛使用,并且已经在许多应用中显示出有希望的结果,从图像分割,手写识别,文档聚类,主题建模到信息检索。基于模型的聚类方法尝试使用概率方法优化观察数据与某些数学模型之间的拟合。 高斯混合模型(GMMs,Gaussian Mixture Models )可以说,K-means只考虑更新质心的均值,而GMMs则考虑更新数据的均值和方差 “高斯混合模型假设存在一定数量的高斯分布,并且每个分布代表一个簇。高斯混合模型倾向于将属于同一分布的数据点分组在一起。”它是一种概率模型,采用软聚类方法将数据点归入不同的簇中,或者说,高斯混合模型使用软分类技术将数据点分配至对应的高斯分布(正态分布)中。 假设我们有三个高斯分布——GD1、GD2和GD3,它们分别具有给定的均值(μ1,μ2,μ3)和方差(σ1,σ2,σ3)。对于给定的一组数据点,GMMs将计算这些数据点分别服从这些分布的概率。 对于具有d个特征的数据集(多元高斯模型),我们将得到k个高斯分布(其中k相当于簇的数量),每个高斯分布都有一个特定的均值向量和方差矩阵,但是——这些高斯分布的均值和方差值是如何给定的?这些值可以用一种叫做期望最大化(Expectation-Maximization ,EM)的技术来确定,在深入研究高斯混合模型之前,我们需要了解EM这项技术。“期望最大化就是寻找正确模型参数的统计算法,当数据有缺失值(数据不完整)时,我们通常使用EM。” 高斯模型中的期望最大化 假设我们需要做K维聚类,这意味着存在k个高斯分布,平均值和协方差值为μ1、μ2、…、μk和∑1、∑2、…、∑k,此外,还有一个用于决定分布所用数据点数量的参数,换句话说,分布的密度用∏i表示。 现在,我们需要确定这些参数的值来定义高斯分布。我们已经确定簇数量,并随机分配了均值、协方差和密度的值,接下来,我们将执行E和M步骤 E步骤:根据模型参数估计样本 i i i到类别 k k k的概率 r i k r_{ik} rik r r c = X i 属 于 c 的 概 率 X i 属 于 c 1 , c 2 , . . . C k 的 概 率 之 和 = π c N ( x i ∣ μ c , ∑ c ) ∑ c ′ π c ′ N ( x i ∣ μ c , ∑ c ′ ) r_{rc}=\frac{X_i属于c的概率}{X_i属于c_1,c_2,...C_k的概率之和}=\frac{\pi_cN(x_i|μ_c,\sum_c)}{\sum_{c'}\pi_{c'}N(x_i|μ_c,\sum_{c'})} rrc=Xi属于c1,c2,...Ck的概率之和Xi属于c的概率=∑c′πc′N(xi∣μc,∑c′)πcN(xi∣μc,∑c) (该值 r i c r_{ic} ric高时表示点被分配至正确的簇,反之则低。)M步骤:根据样本 i i i到类别 k k k的概率 r i k r_{ik} rik最大似然模型参数 完成E步后,我们返回并更新 ∏ ∏ ∏, μ μ μ和 ∑ ∑ ∑值。更新方式如下: 新分布密度由簇中的点数与总点数的比率定义: ∏ = 分 配 给 簇 的 点 数 总 点 数 ∏ = \frac{分配给簇的点数}{总点数} ∏=总点数分配给簇的点数 平均值和协方差矩阵根据分配给分布的值进行更新,与数据点的概率值成比例。因此,具有更高概率成为该分布一部分的数据点将贡献更大的比例: μ = 1 分 配 给 簇 的 点 数 ∑ i r i c x i μ=\frac{1}{分配给簇的点数}\sum_ir_{ic}x_i μ=分配给簇的点数1∑iricxi ∑ c = 1 分 配 给 簇 的 点 数 ∑ i r i c ( x i − μ c ) T ( x i − μ c ) \sum_c=\frac{1}{分配给簇的点数}\sum_ir_{ic}(x_i-μ_c)^T(x_i-μ_c) ∑c=分配给簇的点数1∑iric(xi−μc)T(xi−μc) 基于此步骤生成的更新值,我们计算每个数据点的新概率值并迭代更新。为了最大化对数似然函数,重复该过程 总结基于模型的聚类SOM 该方法的基本思想是--由外界输入不同的样本到人工的自组织映射网络中,一开始时,输入样本引起输出兴奋细胞的位置各不相同,但自组织后会形成一些细胞群,它们分别代表了输入样本,反映了输入样本的特征 COBWeb COBWeb是一个通用的概念聚类方法,它用分类树的形式表现层次聚类 CLASSIT AutoClass 是以概率混合模型为基础,利用属性的概率分布来描述聚类,该方法能够处理混合型的数据,但要求各属性相互独立 应用 在销售领域,利用聚类分析对客户历史数据进行分析,对客户划分类别,刻画不同客户群体的特征,从而深入挖掘客户潜在需求,改善服务质量,增强客户黏性在医学领域,对图像进行分析,挖掘疾病的不同临床特征,辅助医生进行临床诊断。聚类算法被用于图像分割,把原始图像分成若干个特定的、具有独特性质的区域并提取目标在生物领域,将聚类算法用于推导动植物分类,以往对动植物的认知往往是基于外表和习性,应用聚类分析按照功能对基因聚类,获取不同种类物种之间的基因关联 参考文献KNN和K-mean有什么不同?• 毕加索·陈 • 知乎 机器学习(一)——K-近邻(KNN)算法 • Yabea • 博客园 聚类分析 • 赵卫东 • 中国大学mooc 聚类 • 嵩天 • 中国大学mooc 数据挖掘之clara算法原理及实例(代码中有bug) • 小刘 • csdn DBSCAN聚类算法——机器学习(理论+图解+python代码)• 云南省高校数据化运营管理工程研究中心 • csdn Visualizing DBSCAN Clustering 机器学习:基于网格的聚类算法 • segmentfault思否 聚类算法研究总结 • Harry_sir • OSCHINA 使用高斯混合模型,让聚类更好更精确(附数据&代码&学习资源) • AISHWARYA SINGH • 数据派THU 机器学习算法-层次聚类AGNES • AI_BigData_WH • csdn K-Means算法、层次聚类、密度聚类及谱聚类方法详述 • 魏晓蕾 • 云+社区 sklearn.cluster.AgglomerativeClustering 函数(官网) DBSCAN算法在出行行为分析中的应用及改进模型(WS-DBSCAN 算法) • 交通科研Lab • 微信公众号 |


 使用k‐均值聚类的注意事项:
使用k‐均值聚类的注意事项: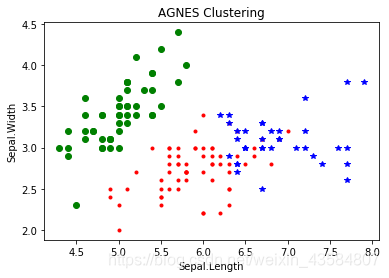
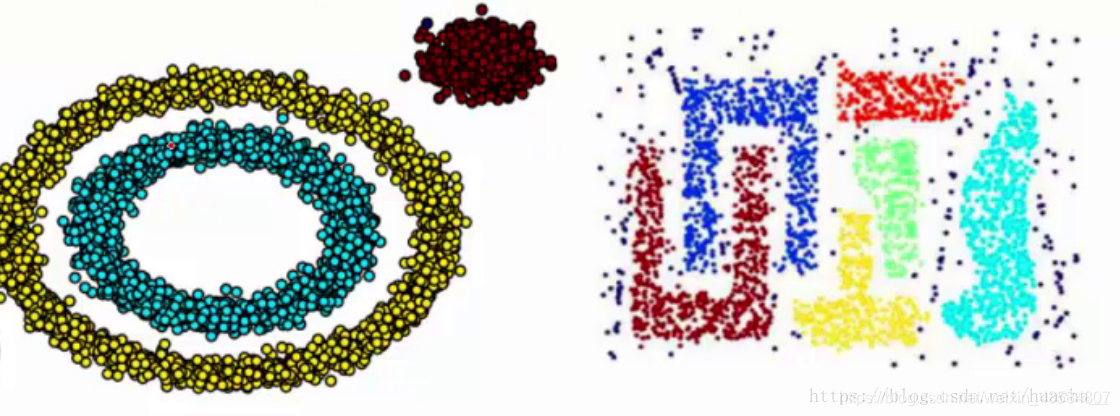 为了解决这一缺陷,基于密度聚类算法利用密度思想,将样本中的高密度区域(即样本点分布稠密的区域)划分为簇,将簇看作是样本空间中被稀疏区域(噪声)分隔开的稠密区域。 这一算法的主要目的是过滤样本空间中的稀疏区域,获取稠密区域作为簇基于密度的聚类算法是根据密度而不是距离来计算样本相似度,所以基于密度的聚类算法能够用于挖掘任意形状的簇,并且能够有效过滤掉噪声样本对于聚类结果的影响。 常见的基于密度的聚类算法有DBSCAN、OPTICS和DENCLUE等。其中,OPTICS 对DBSCAN算法进行了改进,降低了对输入参数的敏感程度。DENCLUE算法综合了基于划分、基于层次的方法
为了解决这一缺陷,基于密度聚类算法利用密度思想,将样本中的高密度区域(即样本点分布稠密的区域)划分为簇,将簇看作是样本空间中被稀疏区域(噪声)分隔开的稠密区域。 这一算法的主要目的是过滤样本空间中的稀疏区域,获取稠密区域作为簇基于密度的聚类算法是根据密度而不是距离来计算样本相似度,所以基于密度的聚类算法能够用于挖掘任意形状的簇,并且能够有效过滤掉噪声样本对于聚类结果的影响。 常见的基于密度的聚类算法有DBSCAN、OPTICS和DENCLUE等。其中,OPTICS 对DBSCAN算法进行了改进,降低了对输入参数的敏感程度。DENCLUE算法综合了基于划分、基于层次的方法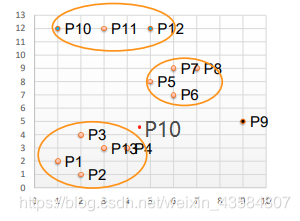
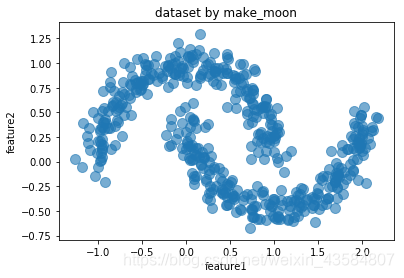 图2:运用DBSCAN算法进行处理的数据图:
图2:运用DBSCAN算法进行处理的数据图: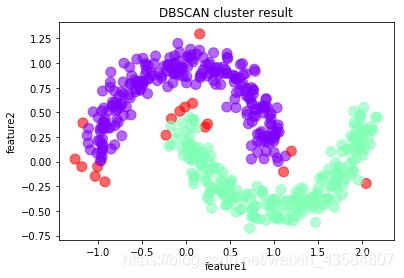 图3:通过np.c_[data,cluster_ids]处理获得带有标签的数据集df
图3:通过np.c_[data,cluster_ids]处理获得带有标签的数据集df 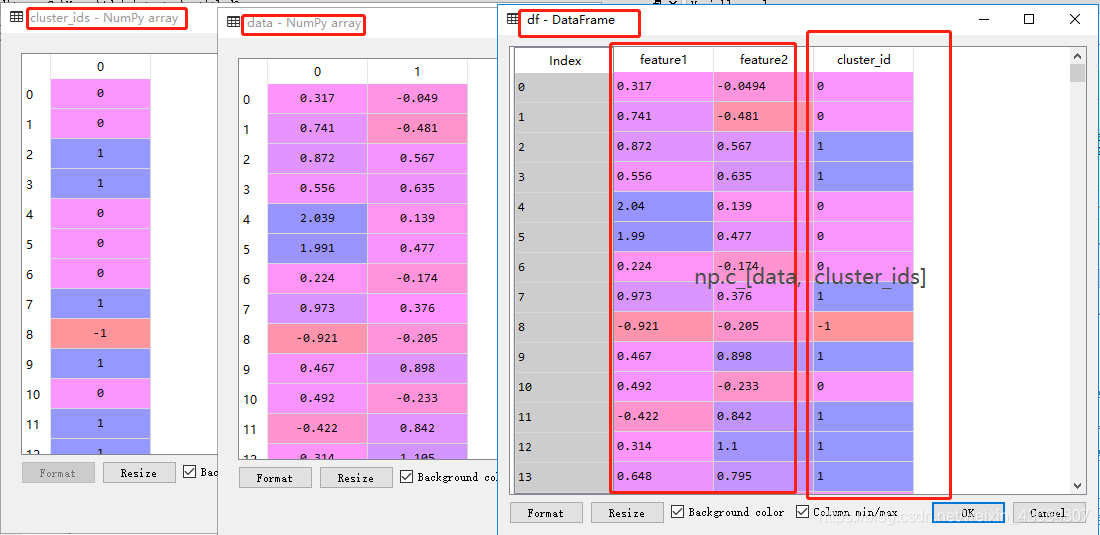
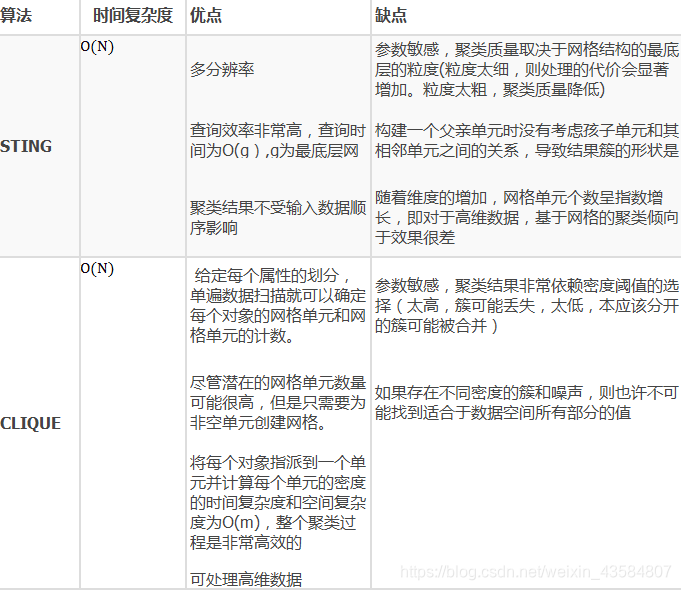
 其他关于网格的聚类,可阅读,机器学习:基于网格的聚类算法 (https://segmentfault.com/)
其他关于网格的聚类,可阅读,机器学习:基于网格的聚类算法 (https://segmentfault.com/)【本文地址】
今日新闻 |
推荐新闻 |