sklearn之高斯混合模型 |
您所在的位置:网站首页 › 聚类sklearn › sklearn之高斯混合模型 |
sklearn之高斯混合模型
|
什么是高斯分布? 高斯分布也叫正态分布,也就是常态分布,什么意思呢?比如说男性的身高,假如说有10000个男性的身高,如果再坐标系上标记出来就是一个正态分布,如果形状还不是和上面的图形一样,那说明数据量还不够,如果数据量足够多的情况下, 就会生成上面的正态分布图。事实上任何一种单一的概率分布都符合正态分布,正态分布的形状由平均值 μ \muμ和方差σ 2 \sigma^2σ2所决定。
一维正态分布公式:正态分布有两个参数,即期望(均数)μ和标准差σ,σ2为方差。
标准正态分布:
面积分布:一个sigmas是68%,俩个sigma是95%,三个sigma是99%(如上图)
举个例子:
公式是概率密度函数,也就是在已知参数的情况下,输入变量指x,可以获得相对应的概率密度。还要注意一件事,就是在实际使用前,概率分布要先进行归一化,也就是说曲线下面的面积之和需要为1,这样才能确保返回的概率密度在允许的取值范围内。
高斯混合模型(GMM) 高斯混合模型是对高斯模型进行简单的扩展,GMM使用多个高斯分布的组合来刻画数据分布。
但高斯不仅局限于一维,很容易将均值扩展为向量,标准差扩展为协方差矩阵,用n-维高斯分布来描述多维特征。 使用sklearn机器学习方法对高斯混合模型编程练习: from sklearn import mixture def test_GMM(dataMat, components=3,iter = 100,cov_type="full"): clst = mixture.GaussianMixture(n_components=n_components,max_iter=iter,covariance_type=cov_type) clst.fit(dataMat) predicted_labels =clst.predict(dataMat) return clsans_,predicted_labels # clsans_返回均值GaussianMixture的超参数介绍: sklearn.mixture.GaussianMixture(n_components=1, covariance_type='full', tol=0.001, reg_covar=1e-06, max_iter=100, n_init=1, init_params='kmeans', weights_init=None, means_init=None, precisions_init=None, random_state=None, warm_start=False, verbose=0, verbose_interval=10) n_components: 混合高斯模型个数,默认为 1covariance_type: 协方差类型,包括 {‘full’,‘tied’, ‘diag’, ‘spherical’} 四种,full 指每个分量有各自不同的标准协方差矩阵,完全协方差矩阵(元素都不为零), tied 指所有分量有相同的标准协方差矩阵(HMM 会用到),diag 指每个分量有各自不同对角协方差矩阵(非对角为零,对角不为零), spherical 指每个分量有各自不同的简单协方差矩阵,球面协方差矩阵(非对角为零,对角完全相同,球面特性),默认‘full’ 完全协方差矩阵tol:EM 迭代停止阈值,默认为 1e-3.reg_covar: 协方差对角非负正则化,保证协方差矩阵均为正,默认为 0max_iter: 最大迭代次数,默认 100n_init: 初始化次数,用于产生最佳初始参数,默认为 1init_params: {‘kmeans’, ‘random’}, defaults to ‘kmeans’. 初始化参数实现方式,默认用 kmeans 实现,也可以选择随机产生weights_init: 各组成模型的先验权重,可以自己设,默认按照 7 产生means_init: 初始化均值,同 8precisions_init: 初始化精确度(模型个数,特征个数),默认按照 7 实现random_state : 随机数发生器warm_start : 若为 True,则 fit()调用会以上一次 fit()的结果作为初始化参数,适合相同问题多次 fit 的情况,能加速收敛,默认为 False。verbose : 使能迭代信息显示,默认为 0,可以为 1 或者大于 1(显示的信息不同)verbose_interval : 与 13 挂钩,若使能迭代信息显示,设置多少次迭代后显示信息,默认 10 次。参数介绍: aic(X) 输入 X 上当前模型的 aic(X)Akaike 信息标准。 bic(X) 输入 X 上当前模型的 bic(X)贝叶斯信息准则。 fit(X[, y]) fit(X [,y])使用 EM 算法估算模型参数。 get_params([deep]) 获取此估算器的参数。 predict(X) 预测(X)使用训练模型预测 X 中数据样本的标签。 predict_proba(X) 预测给定数据的每个组件的后验概率。 sample([n_samples]) 从拟合的高斯分布生成随机样本。 score(X[, y]) 计算给定数据 X 的每样本平均对数似然。 score_samples(X) 计算每个样本的加权对数概率。 set_params(**params) 设置此估算器的参数。 最主要的步骤是fit,然后内部在用em算法进行迭代求参数了。 首先,初始随机选择各参数的值。然后,重复下述两步,直到收敛。 E步骤。根据当前的参数,计算每个点由某个分模型生成的概率。M步骤。使用E步骤估计出的概率,来改进每个分模型的均值,方差和权重。
高斯混合模型与K均值算法的相同点是: 它们都是可用于聚类的算法;都需要 指定K值;都是使用EM算法来求解;都往往只能收敛于局部最优。而它相比于K 均值算法的优点是,可以给出一个样本属于某类的概率是多少;不仅仅可以用于聚类,还可以用于概率密度的估计;并且可以用于生成新的样本点。 KMEANs聚类首先,我们先确定目标分组数量,这是K的数值,根据需要划分的族或分组的数量,随机初始化k个质心。然后将数据点指定给最近的质心,形成一个簇,接着更新质心,重新分配数据点。这个过程不断重复,直到质心的位置不再改变。 高斯混合模型(Gaussian Mixture Models ,GMMs)假设存在一定数量的高斯分布,并且每个分布代表一个簇。高斯混合模型倾向于将属于同一分布的数据点分组在一起。
参考:https://www.cnblogs.com/dahu-daqing/p/9456137.html 参考:https://www.cnblogs.com/nuochengze/p/12541550.html 参考:https://www.jianshu.com/p/94943da6102d
|

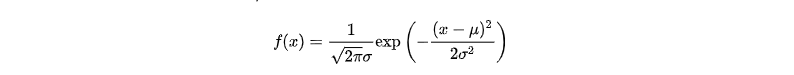



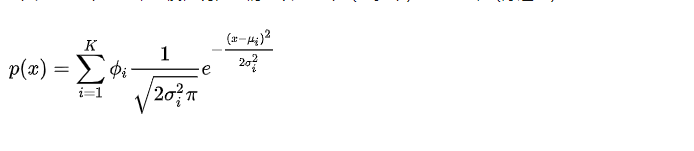


【本文地址】
今日新闻 |
推荐新闻 |