分群思维(五)特殊的分群思维 |
您所在的位置:网站首页 › 群论思维导图 › 分群思维(五)特殊的分群思维 |
分群思维(五)特殊的分群思维
|
分群思维(五)特殊的分群思维-同期群分析
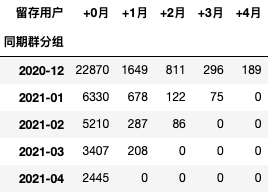
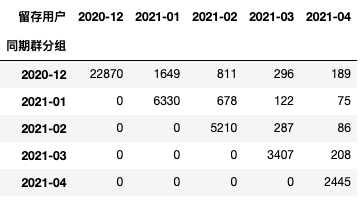
小P:小H,用户留存率降了,增长也缓慢了,这是什么原因啊,会不会是新用户出了问题啊,还是说老用户不满意了? 小H:可以尝试同期群分析,看看新老用户的差异。 import pandas as pd import matplotlib.pyplot as plt import numpy as np # 初始化设置 plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号以下数据如果有需要的同学可关注公众号HsuHeinrich,回复【分群思维05】自动获取~ df = pd.read_csv('paid.csv', encoding="gbk") df.head() 日期付费金额uid02021/4/30 9:50300973466812021/4/30 9:42150994779922021/4/30 9:41680905843132021/4/30 9:3230994779942021/4/30 9:251502412798 cohort # 生成用户每月数据 df['购买月份'] = pd.to_datetime(df['日期']).dt.to_period("M") order = df.groupby(["uid", "购买月份"], as_index=False).agg( 月付费总额=("付费金额", "sum"), 月付费次数=("uid", "count"), ) # 计算同期群分组:用户首次购买月份 order["同期群分组"] = order.groupby("uid")['购买月份'].transform("min") # 计算cohort月 order["cohort月"] = (order.购买月份-order.同期群分组).apply(lambda x:f"+{x.n}月")常见的cohort展示方式有两种,一种是按照日期差呈现出左上角数据;一种是按照实际日期呈现出右上角数据 # 留存cohort方式1 order.pivot_table(index="同期群分组", columns="cohort月", values="uid", aggfunc="count", fill_value=0).rename_axis(columns="留存用户")
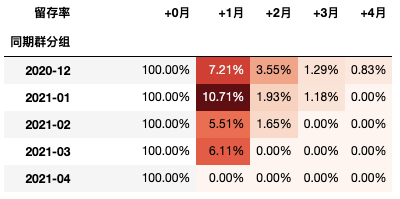
以下数据如果有需要的同学可关注公众号HsuHeinrich,回复【分群思维05】自动获取~ # 模拟的数据,部分数据较前期多可忽略 df_sp2 = pd.read_excel('留存cohort.xlsx', index_col=0) df_sp2.head()
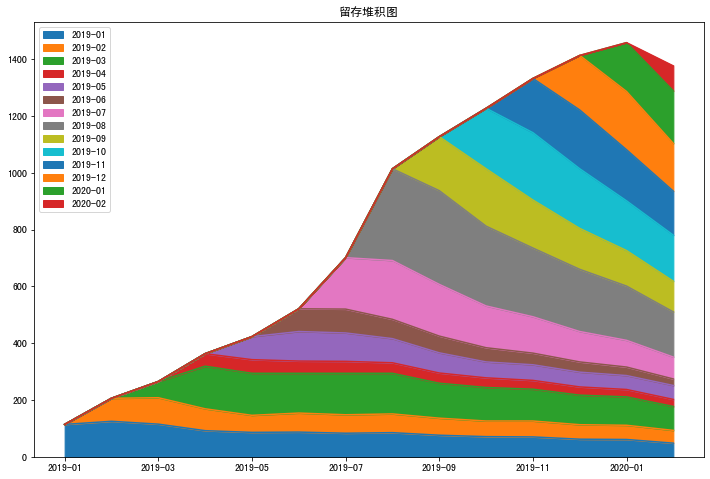
留存堆积图能很好的展示留存信息和增长信息,当新增用户显著高于前期的流失时,用户活跃规模是增长的。如上图,我们可以看到在2019.1月至6月用户呈现缓慢的增长,此时各月的流失也比较缓慢。之后直至8月迎来快速增长期,这段时期的新用户增长明显较大。此后到2022.1月新用户增增长略可,用户流失也略可,所以也呈现出了缓慢的增长,到2022.2月则开始下滑了。 共勉~ |

【本文地址】
今日新闻 |
推荐新闻 |