让Python为你的美食图片打分?朋友圈食物拍照水平大赏 |
您所在的位置:网站首页 › 美食图片100张 › 让Python为你的美食图片打分?朋友圈食物拍照水平大赏 |
让Python为你的美食图片打分?朋友圈食物拍照水平大赏
|
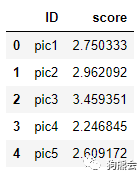
importpandas aspd MasterFile=pd.read_csv('../case3-food/FoodScore.csv') print(MasterFile.shape) MasterFile[0:5]
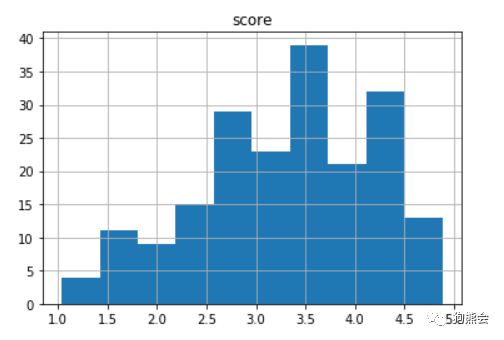
可以看到,除了第3张图片,其他图片的得分都在2.5左右,正好是满分的一半,也有得到3.45分的图片。有人说,只看5张图片的得分不过瘾,想要看看所有得分的分布情况呢。众所周知,查看一个连续型变量的分布情况需要使用“直方图”,它描述了数据落在各个区间的个数。由于MasterFile已经是一个DataFrame实例,我们可以使用.hist的方法查看该组数据的分布。 MasterFile.hist
从上图可以看到平均分在3.5左右的图片较多,图片的得分以3.5为中心大致呈现出正态分布的情况(尾部在左侧,稍微有一些左偏),说明评委们还是倾向于给高分的,毕竟是美食图片,人人都爱~ 之后是一件数据处理上的事情,我们需要把得分score单独分离出来,用到numpy包里的array格式。除了pandas以外,在Python中最重要的另一个数据处理包就是numpy,它提供了一种名为array(数组)的格式来储存数据。array的优势之一是可以储存多维度的数据。比如说一张照片,就涉及到三个维度,长宽以及通道数,彩色照片的通道数一般是3。 同样的,我们先import numpy as np,在这个程序里就使用np这个简称来替代numpy,接着FileNames=MasterFile['ID']是把ID这一列提取,得到图片的名字。N=len(FileNames)获取了FileName变量的长度,即图片的个数。然后要得到一个array格式的因变量。 Y=np.array(MasterFile['score']).reshape([N,1]),这句话的意思是说,将score这一列提取出来之后,使用np.array转换为数组格式,再使用.reshape方法变成N行1列的形状,这就完成了因变量的数据处理。 importnumpy asnp FileNames=MasterFile['ID'] N=len(FileNames) Y=np.array(MasterFile['score']).reshape([N,1]) 读入数据:自变量 在Python中,我们可以用Image类读取图片数据(这又接触了一个新的包,像Python和R这类开源语言就很依赖各行各业的使用者的贡献,光是别人写的包就成千上万个T_T),我们使用from PIL import Image得到Image这个类。 以下代码的目的是,首先指定图片统一的像素大小。这里定义为IMSIZE=128,我们希望把大小不一致的图片都转换为长宽为128像素的图片。接下来先初始化一个X,这个X有四个维度,包括【储存数据个数,图片长度,图片宽度,通道数】,分别将【N, IMSIZE, IMSIZE, 3】的值传递给X,作为四个维度。np.zeros是说这个X在各个位置上的值都是0。 fromPIL importImage IMSIZE=128 X=np.zeros([N,IMSIZE,IMSIZE,3]) fori inrange(N): MyFile=FileNames[i] Im=Image.open('../case3-food/data/'+MyFile+'.jpg') Im=Im.resize([IMSIZE,IMSIZE]) Im=np.array(Im)/255 X[i,]=Im 接下来通过for循环一步步把图片存到X中去。MyFile=FileNames[i]是将FileNames的第i个变量赋值给MyFile,也就是第i个图片的名字。Im=Image.open('../case3-food/data/'+MyFile+'.jpg')引号里面是图片储存的路径,在Python里可以用符号“+”来连接字符串。Image.open也就是打开这张图片啦,赋值给IM这个变量。接着,使用IM.resize来将图片变为统一的大小,也就是IMSIZE×IMSIZE大小的图片。最后将IM转换为array格式,在将这张图片每个像素上值的大小除以255。这是因为,在原始的图片中,这些图片的每个像素点大小的取值范围是0~255,而TensorFlow只能处理0~1之间的数据,所以我们把所有数都除以255以满足要求。最后,在X的第i个位置上放置好IM这张图片,使用X[i,]=Im语句就可以实现。 美食图片数据展示 现在让我们看看这些美食照片都长什么样子吧!在Python里,数据的可视化一般是使用matplotlib这个包。从这个包里导入pyplot这个类,取个简称叫plt。首先用plt.figure方法创建一张画布。然后将其划分为两行五列,总共展示10张图片。把要展示的图片的高度和宽度分别设置为7.5和15,分别用fig.set_figheight(7.5)和fig.set_figwidth(15)实现。用flatten将ax这个2×5的向量拉直为长度为10的向量,方便我们指定图片放置的位置。最后,用for循环一张张把图片放上去,ax[i].imshow(X[i,:,:,:])是说在画布ax的第i个位置展示X的第i张图片,ax[i].set_title(np.round(Y[i],2))表示把美食图片的评分设置为标题。np.around是让这些分数只取到两位小数。 frommatplotlib importpyplot asplt plt.figure fig,ax=plt.subplots(2,5) fig.set_figheight(7.5) fig.set_figwidth(15) ax=ax.flatten fori inrange(10): ax[i].imshow(X[i,:,:,:]) ax[i].set_title(np.round(Y[i],2))
照片来啦!部分图片不太清晰,是因为有一些图片是经过压缩处理的。其中得分最高的是第2行第1个图片,得到了4.63分,这应该是一个食材丰富的披萨,在经过压缩后有些模糊,相信原始的图片还是很优秀的!得分最低的是第1行第4张图片,像是什么奇怪的炒菜,小编也没看明白是啥,这可能也是它得分比较低的原因。 建 模 在建模之前,需要把数据划分为训练集和测试集。在Python中有一个专门做机器学习的包,名为sklearn(或者scikit-learn),使用这个包里的一个函数train_test_split,可以把数据集随机划分为训练集和测试集。在这个函数里,从左到右四个参数分别是X,自变量;Y,因变量;test_size,也就是要百分之多少的数据作为测试集;random_state是一个随机数种子,可以任给一个数字,保证了结果是可重复的。 fromsklearn.cross_validation importtrain_test_split X0,X1,Y0,Y1=train_test_split(X,Y,test_size=0.5,random_state=0) 然后,使用TensorFlow建立线性回归模型,自变量是一张图片上所有像素点的值,用Flatten函数把图片拉直成一列向量。首先把模型的框架搭好,用Input函数告诉计算机传入的图片的大小维度,这里等于[IMSIZE, IMSIZE, 3],接着把图像拉直,再用Dense(1)全连接层把这个拉直的数据聚合到一个值上,即因变量Y,也就是图像的得分。最后,把这个模型取名为model,再用model.summary查看每一层的具体情况,如下所示。 fromkeras.layers importDense, Flatten, Input fromkeras importModel input_layer=Input([IMSIZE,IMSIZE,3]) x=input_layer x=Flatten(x) x=Dense(1)(x) output_layer=x model=Model(input_layer,output_layer) model.summary
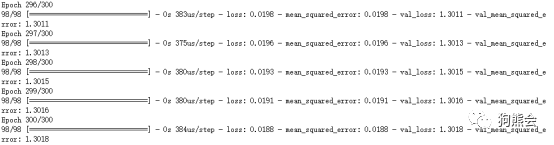
模型设计好之后,接下来就是编译运行。使用MSE作为模型评价的标准,MSE的全称是Mean Square Error,中文名是均方误差(大部分情况下也就是预测值和实际值做差的平方和),在因变量是连续变量时这是很常用的一个评价指标,通过loss=`mse`来实现,我们的目的就是最小化这个均方误差,设置metrics=[`mse`],这是我们优化过程中要监督的指标,选取优化器optimizer=Adam,其中lr=0.001是学习率。 fromkeras.optimizers importAdam model.compile(loss='mse',optimizer=Adam(lr=0.001),metrics=['mse']) 接下来通过model.fit进行模型拟合,传入训练集数据X0,Y0,交叉验证的测试集数据是X1,Y1,batch_size是指我每次优化要使用多少张图片,epochs是要循环多少次,也就是遍历多少次数据集。 model.fit(X0,Y0, validation_data=[X1,Y1], batch_size=100, epochs=300)
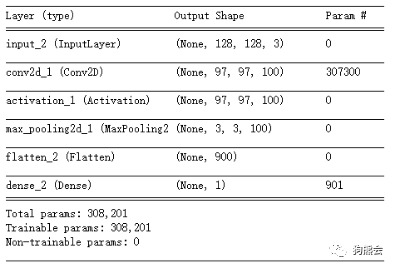
这里补充一句,前面提到的lr, batch_size, epochs取值是需要调试的,我们一开始并不知道大小多少才合适(事实上写这篇推送的时候也不知道最优值是啥),这也是为什么说深度学习是一个调参的过程。 可能有人说,线性回归实在是太简单的模型了,用在这里效果是不是不太好?确实是这样的,当处理图像数据的时候,一般不适用线性回归模型,而是使用CNN相关的模型,CNN的全称是Convolutional Neural Network,中文名是卷积神经网络。关于卷积这个方法有太多需要讲的内容,这里我们就不展开讲啦,直接看代码吧~ fromkeras.layers importInput,Conv2D,MaxPooling2D,Dense,Flatten,Activation fromkeras importModel input_layer=Input((IMSIZE,IMSIZE,3)) x=input_layer x=Conv2D(100,(32,32))(x) x=Activation('relu')(x) x=MaxPooling2D((32,32))(x) x=Flatten(x) output_layer=Dense(1)(x) modelextend=Model(input_layer,output_layer) modelextend.summary
与之前不同的是,我们在输入层之后,紧跟的是一个Conv2D层,也就是卷积层,之后是Activation,激活函数层,然后是MaxPooling2D层,即最大池化层。这些层都是深度学习里最基础的一些概念,要了解的话也需要花一些功夫,这里我们对概念性的内容也不多做讲解啦,欲了解详情可以自行检索~ modelextend.compile(loss='mse',optimizer=Adam(lr=0.001),metrics=['mse']) modelextend.fit(X0,Y0, batch_size=100, epochs=300, validation_data=(X1,Y1))
拟合的方法与之前是完全一样的。这里我们看一下结果,测试集的mse是0.7771,相比于使用线性回归的1.3018是一个不小的提升,看来CNN在这里还是更有优势的嘛。 模型预测:这张早餐多少分
我们来做一个有趣的尝试,当初静静老师读博士的时候,有一天在寝室吃早餐,拍了一张照片,自己也不知道拍的这是啥水平。于是我们读到Python里,让它来告诉我们。 首先给这张照片取名为mypic.jpg,使用Image.open方法打开,然后变形到128×128像素,像素点的数值除以255,再放到我们的model模型里,使用model.predict预测,看一看预测的结果如何。 MyPic=Image.open('mypic.jpg') MyPic=MyPic.resize((IMSIZE,IMSIZE)) MyPic=np.array(MyPic)/255 MyPic=MyPic.reshape((1,IMSIZE,IMSIZE,3)) model.predict(MyPic) modelextend.predict(MyPic) 2.76分!大概是中等稍微偏下的水平,对于自己随手拍的照片能拿到这样的分数还是很满意滴~各位看官们想知道自己拍的美食照片能得多少分吗? ✦ 案例来源:本案例改编自中国人民大学统计学院2016级本科生统计软件课程小组作业 ✦ 小组成员:王蕾 沈雨薇 牛聆宇 韩雨锦 李卜诺 ✦ 案例的后期制作:漆岱峰返回搜狐,查看更多 |



【本文地址】
今日新闻 |
推荐新闻 |