2023年美赛C题 预测Wordle结果Predicting Wordle Results这题太简单了吧 |
您所在的位置:网站首页 › 美赛成绩有哪些 › 2023年美赛C题 预测Wordle结果Predicting Wordle Results这题太简单了吧 |
2023年美赛C题 预测Wordle结果Predicting Wordle Results这题太简单了吧
|
代码更新完毕啦
更新时间 2023-2-18 16:30 问题一、二建模方案、代码、数据、图片 2023-2-19 13:00 问题三、四建模方案、代码、数据、图片 2023-2-25 14:00 发布完整论文 (1)2023年美赛C题Wordle预测问题一建模及Python代码详细讲解 (2)2023年美赛C题Wordle预测问题二建模及Python代码详细讲解 (3)2023年美赛C题Wordle预测问题三、四建模及Python代码详细讲解 (4)2023年美赛C题Wordle预测问题27页中文论文 1 题目 2023年MCM 问题C:预测Wordle结果
Wordle是纽约时报目前每天提供的一个流行的谜题。玩家尝试在6次或更少的时间内猜出一个5个字母的单词来解决这个谜题,每猜一次都会收到反馈。在这个版本中,每次猜出的单词必须是一个真实的英语单词。没有被比赛认定为单词的猜测是不允许的。Wordle继续流行,现在有60多种语言的版本。 纽约时报网站directions for Wordle指出,在你提交文字后,瓷砖的颜色将发生变化。黄色的瓦片表示字母在那个瓦片里,但它在错误的位置。绿色瓦片表示该瓦片中的字母在单词中,并且在正确的位置。灰色瓦片表示该瓦片中的字母根本不包含在单词中(见附件2)[2]。图1是一个示例解决方案,在三次尝试中找到了正确的结果。
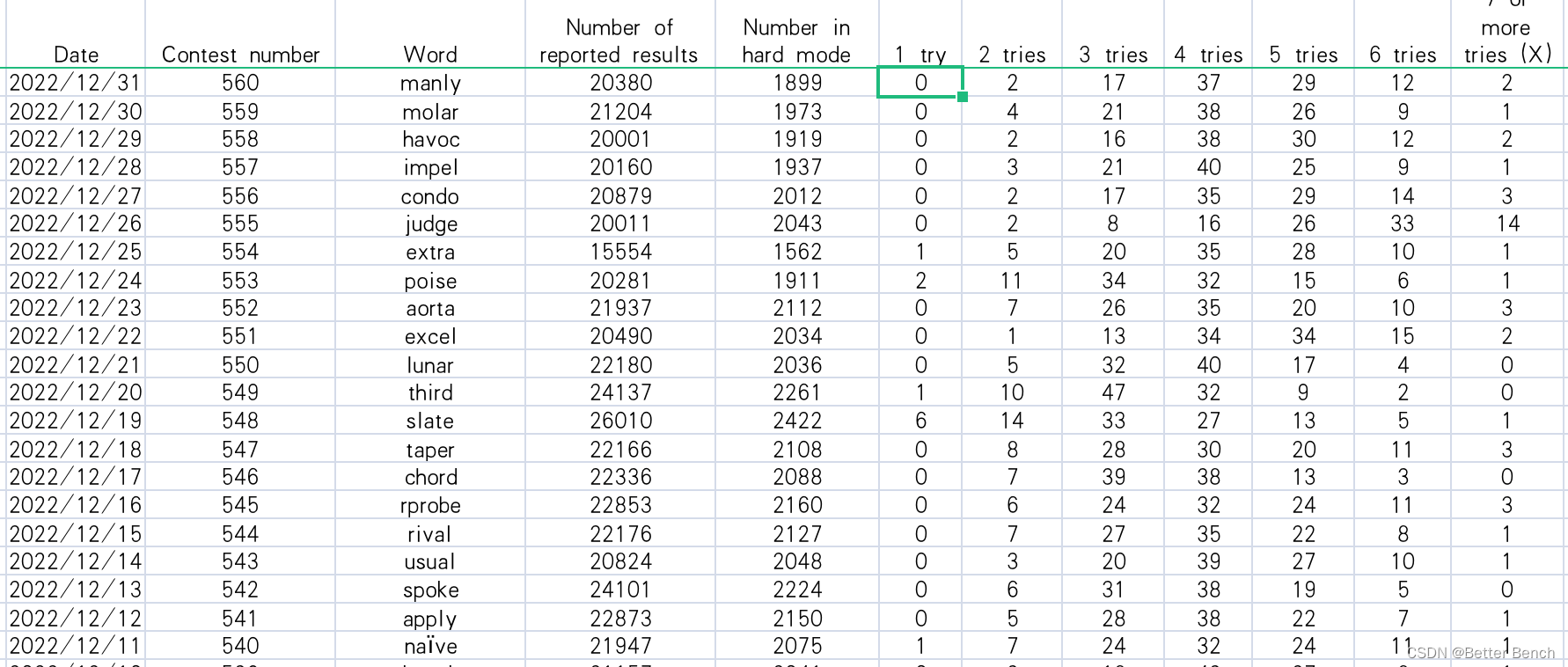
图1:2022年7月21日[3]Wordle谜题的示例解决方案 玩家可以在常规模式或”困难模式”中玩。《Wordle》的困难模式要求玩家在一个单词中找到一个正确的字母(方块是黄色或绿色),这些字母必须用于随后的猜测,从而增加了游戏的难度。图1中的示例是在困难模式下播放的。 许多(但不是全部)用户在推特上报告他们的分数。这个问题,MCM生成的一个文件的日常结果1月7日,从2022年12月31日,2022(见附件1),这个文件包含了日期,比赛号码,词的一天,那天报告分数的人数,在困难模式的玩家数量,和猜测这个词的比例在一个尝试,两次,三次,四个尝试5次,六个尝试,或者无法解决的难题(X)。例如,在图2中7月20日,这个词2022年是”陈腐的”,结果是通过挖掘推特获得的。虽然图2中的百分比总和为100%,但在某些情况下,由于四舍五入的原因,这可能并不正确。 图2:2022年7月20日报告结果向推特[4]的分布 要求 《纽约时报》要求您对这个文件中的结果进行分析,以回答几个问题。 (1)报告结果的数量每天都在变化。开发一个模型来解释这一变化,并使用您的模型为2023年3月1日报告的结果数量创建一个预测区间。单词的任何属性是否会影响困难模式下玩家得分的百分比?如果有,是如何影响的?如果不是,为什么不是? (2)对于一个给定的未来解决方案Word,在未来的日期,开发一个模型,使您能够预测报告结果的分布。换句话说,预测未来日期(1,2,3,4,5,6,X)的相关百分比。你的模型和预测有哪些不确定性?请给出一个具体的例子,说明你对2023年3月1日“EERIE”一词的预测。你对模型的预测有多大信心? (3)开发并总结一个模型,根据难度对解决方案单词进行分类。识别与每个分类相关的给定单词的属性。使用你的模型,EERIE这个词有多难?讨论你的分类模型的准确性。 (4)列出并描述这个数据集的其他一些有趣的特征。 (5)最后,给《纽约时报》的字谜编辑写一封一到两页的信,总结你的研究结果。 总页数不超过25页的PDF解决方案应包括: 一页汇总表。目录。您的完整解决方案。一封一到两页的求职信。参考名单。 注意:MCM大赛的篇幅限制为25页。您提交的所有内容(汇总表、目录、报告、参考名单和任何附录)都应在25页的限制范围内。你必须引用你的想法、图像和报告中使用的任何其他材料的来源。附件 1.数据文件。Problem_C_Data_Wordle.xlsx 2 思路方案分析 2.1 分析数据(1)第一步了解游戏规则 【爱与私语,一款文字游戏为何风靡美国|wordle的玩法和故事】 https://www.bilibili.com/video/BV1iu411U7LJ/?share_source=copy_web&vd_source=d2dd5fcbeeeec396792650b25c110a13 (2)第二步,理解提供的excel内容
Date:给定Wordle字谜的日期,格式为mm-dd-yyyy(月日-年)。 Contest number:Wordle谜题的索引,从2022年1月7日的202开始。 Word:单词 Number of reported results:当天记录的总分数。 Number in hard mode:当天在hard模式得分。 1try:玩家一次猜中谜题的百分比。 2tries:玩家两次猜中谜题的百分比。 3tries:玩家三次猜中谜题的百分比。 4tries:玩家在四次猜测中解决谜题的百分比。 5tries:玩家在5次猜测中解决谜题的百分比。 6tries:玩家在6次猜测中解决谜题的百分比。 7 on tries more(X):在6次或更少的尝试中无法解决谜题的玩家的百分比。 2.2 思路(1)问题一: 报告结果的数量每天都在变化。开发一个模型来解释这一变化,并使用您的模型为2023年3月1日 Number of reported results创建一个预测区间。单词的任何属性是否会影响困难模式下玩家得分的百分比?如果有,是如何影响的?如果不是,为什么不是? 分析:第一小问,Number of reported results这一列是一个时间序列,创建一个时间序列预测预测模型,采用线性回归或者非线性回归方法来预测3月1号的数据。有一定的误差,将预测结果结合误差设置一个预测区间。 单词的属性有元音和辅音以及字母。将字母数量、元音、辅音编码后分析与7种百分比的分析相关性,可视化相关性,得出结论。 元音字母有5个:A、E、I、O、U;辅音字母有21个:B、C、D、F、G、H、J、K、L、M、N、P、Q、R、S、T、V、W、X、Z、Y (2)问题二: 对于一个给定的未来解决方案Word,在未来的日期,开发一个模型,使您能够预测报告结果的分布。换句话说,预测未来日期(1,2,3,4,5,6,X)的相关百分比。你的模型和预测有哪些不确定性?请给出一个具体的例子,说明你对2023年3月1日“EERIE”一词的预测。你对模型的预测有多大信心? 分析:针对1-7种尝试,建立7个回归模型,将单词进行编码,并提取特征,采用机器学习的回归模型,进行预测7种情况的百分比。 回归模型以下几种: 线性回归多项式回归逐步回归岭回归套索回归弹性回归分位数回归贝叶斯线性回归偏最小二乘回归题目问有多大信心,就是对回归模型进行评价,回归模型的评价指标有 均方误差(Mean Squared Error,MSE) 观测值与真值偏差的平方和与观测次数的比值:M S E = 1 m ∑ i = 1 n ( y i − y i ^ 2 ) MSE= \frac{1}{m} \sum_{i=1}^n (y_i-\hat{y_i}^2) MSE=m1i=1∑n(yi−yi^2) 这就是线性回归中最常用的损失函数,线性回归过程中尽量让该损失函数最小。那么模型之间的对比也可以用它来比较。 MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。 def rmse(y_test, y_true): return sp.mean((y_test - y_true) ** 2) 均方根误差(标准误差)(Root Mean Squard Error,RMSE) 标准差是方差的算术平方根。 标准误差是均方误差的算术平方根。 标准差是用来衡量一组数自身的离散程度,而均方根误差是用来衡量观测值同真值之间的偏差,它们的研究对象和研究目的不同,但是计算过程类似。R M S E = 1 m ∑ i = 1 n ( y i − y i ^ 2 ) RMSE= \sqrt{\frac{1}{m} \sum_{i=1}^n (y_i-\hat{y_i}^2)} RMSE=m1i=1∑n(yi−yi^2) 它的意义在于开个根号后,误差的结果就与数据是一个级别的,可以更好地来描述数据。标准误差对一组测量中的特大或特小误差反映非常敏感,所以,标准误差能够很好地反映出测量的精密度。这正是标准误差在工程测量中广泛被采用的原因。 python 实现 def rmse(y_test, y_true): return sp.sqrt(sp.mean((y_test - y_true) ** 2)) 平均绝对误差(Mean Absolute Error,MAE)平均绝对误差是绝对误差的平均值 : M A E = 1 m ∑ i = 1 n ∣ y i − y i ^ ∣ MAE= \frac{1}{m} \sum_{i=1}^n |y_i-\hat{y_i}| MAE=m1i=1∑n∣yi−yi^∣ 平均绝对误差能更好地反映预测值误差的实际情况. python 实现如下 def mae(y_test, y_true): return np.sum(np.absolute(y_test - y_true)) / len(y_test)(3)问题三: 开发并总结一个模型,根据难度对解决方案单词进行分类。识别与每个分类相关的给定单词的属性。使用你的模型,EERIE这个词有多难?讨论你的分类模型的准确性。 分析:对单词进行编码后,采用聚类方法,可以将单词难度分为三类或者更多,如困难、一般、简单。然后对每一类的单词可视化分析,并描述数据得出结论。 聚类算法较多,在论文中可以使用改进的聚类算法 K-Means(K均值)聚类Python聚类案例代码 # K-Means(K均值)聚类 import numpy as np from sklearn.cluster import KMeans data = np.random.rand(100, 3) #生成一个随机数据,样本大小为100, 特征数为3 #假如我要构造一个聚类数为3的聚类器 estimator = KMeans(n_clusters=3)#构造聚类器 estimator.fit(data)#聚类 label_pred = estimator.labels_ #获取聚类标签 centroids = estimator.cluster_centers_ #获取聚类中心 inertia = estimator.inertia_ # 获取聚类准则的总和 均值漂移聚类 """ 聚类 均值漂移算法 量化带宽,决定每次调整概率密度函数的步进量 """ import numpy as np import sklearn.cluster as sc import matplotlib.pyplot as mp # 加载数据 x = np.loadtxt("./multiple3.txt", delimiter=",") # 量化带宽 quantile 量化宽度 bw = sc.estimate_bandwidth(x, n_samples=len(x), quantile=0.1) # 均值漂移算法 模型 model = sc.MeanShift(bandwidth=bw, bin_seeding=True) model.fit(x) centers = model.cluster_centers_ print(centers) # 分类边界数据 n = 500 l, r = x[:, 0].min() - 1, x[:, 0].max() + 1 b, t = x[:, 1].min() - 1, x[:, 1].max() + 1 grid_x = np.meshgrid(np.linspace(l, r, n), np.linspace(b, t, n)) flat_x = np.column_stack((grid_x[0].ravel(), grid_x[1].ravel())) flat_y = model.predict(flat_x) grid_y = flat_y.reshape(grid_x[0].shape) prd_y = model.predict(x) # 绘制结果 mp.figure('MeanShift Cluster', facecolor='lightgray') mp.title('MeanShift Cluster', fontsize=20) mp.xlabel('x', fontsize=14) mp.ylabel('y', fontsize=14) mp.tick_params(labelsize=10) # 分类边界 mp.pcolormesh(grid_x[0], grid_x[1], grid_y, cmap='gray') # 点数据 mp.scatter(x[:, 0], x[:, 1], c=prd_y, cmap="jet", s=80) # 分类中心点 mp.scatter(centers[:, 0], centers[:, 1], marker='+', c='gold', s=1000, linewidth=3) mp.show() 基于密度的聚类方法(DBSCAN) # DBSCAN 算法 print(__doc__) import numpy as np from sklearn.cluster import DBSCAN from sklearn import metrics from sklearn.datasets.samples_generator import make_blobs from sklearn.preprocessing import StandardScaler # Generate sample data centers = [[1, 1], [-1, -1], [1, -1]] X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4, random_state=0) X = StandardScaler().fit_transform(X) # Compute DBSCAN db = DBSCAN(eps=0.1, min_samples=10).fit(X) core_samples_mask = np.zeros_like(db.labels_, dtype=bool) core_samples_mask[db.core_sample_indices_] = True labels = db.labels_ # Number of clusters in labels, ignoring noise if present. n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0) print('Estimated number of clusters: %d' % n_clusters_) print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels)) print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels)) print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels)) print("Adjusted Rand Index: %0.3f" % metrics.adjusted_rand_score(labels_true, labels)) print("Adjusted Mutual Information: %0.3f" % metrics.adjusted_mutual_info_score(labels_true, labels)) print("Silhouette Coefficient: %0.3f" % metrics.silhouette_score(X, labels)) # import matplotlib.pyplot as plt # Black removed and is used for noise instead. unique_labels = set(labels) colors = [plt.cm.Spectral(each) for each in np.linspace(0, 1, len(unique_labels))] for k, col in zip(unique_labels, colors): if k == -1: # Black used for noise. col = [0, 0, 0, 1] class_member_mask = (labels == k) xy = X[class_member_mask & core_samples_mask] plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col), markeredgecolor='k', markersize=14) xy = X[class_member_mask & ~core_samples_mask] plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col), markeredgecolor='k', markersize=6) plt.title('Estimated number of clusters: %d' % n_clusters_) plt.show() 层级聚类算法 from sklearn.cluster import AgglomerativeClustering #导入sklearn的层次聚类函数 model = AgglomerativeClustering(n_clusters = k, linkage = 'ward') model.fit(data) #训练模型 #详细输出原始数据及其类别 r = pd.concat([data, pd.Series(model.labels_, index = data.index)], axis = 1) #详细输出每个样本对应的类别 import matplotlib.pyplot as plt from scipy.cluster.hierarchy import linkage,dendrogram #这里使用scipy的层次聚类函数 Z = linkage(data, method = 'ward', metric = 'euclidean') #谱系聚类图 P = dendrogram(Z, 0) #画谱系聚类图 plt.show()用高斯混合模型(GMM)的最大期望(EM)聚类 图团体检测(Graph Community Detection) (4)问题四: 列出并描述这个数据集的其他一些有趣的特征。 对数据集的Number of reported results:当天记录的总分数、Number in hard mode:当天在hard模式得分、Tries进行可视化分析,以朱庄头、饼状图、散点图等方式进行可视化分析,得出结论。 3 python实现加我扣扣 |





【本文地址】
今日新闻 |
推荐新闻 |