python爬虫 |
您所在的位置:网站首页 › 美团评价页面 › python爬虫 |
python爬虫
|
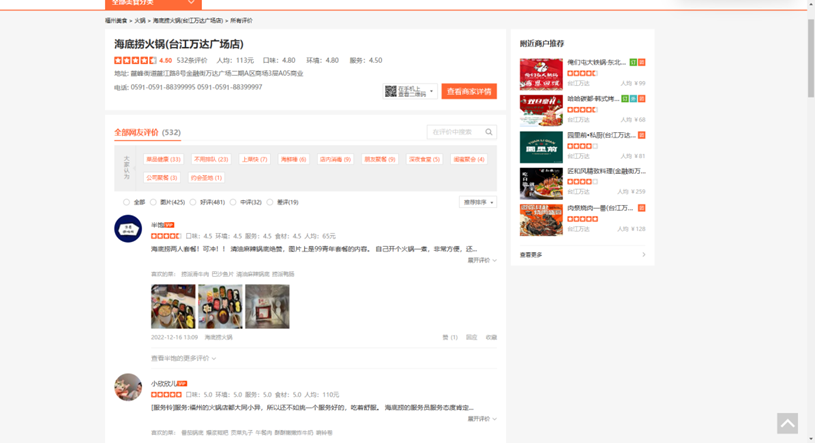
美团海底捞评论及评分数据爬取和分析 一、选题背景 通过网络请求的方式获取响应数据,再对获取的数据进行分析提取和汇总,并储存到xlsx表格中。在进入互联网存储海量数据的新时代,如何快速且准确的获取需要的数据,爬虫无疑是最佳的解决方案之一。 美团商家评论中包含着大量用户留下的信息,对这些信息进行采集和分析,了解用户对商家的评价和喜好情况,是本文所要研究的主要内容之一。 二.爬虫设计方案 1.爬虫名称 美团福州万达海底捞评论爬虫。 2.爬取的内容和数据特征分析 本次爬取的数据为:用户昵称、发布时间、用户评分、用户评论 数据的特征分析为:分词、评分等级饼状图、评分内容词云、可视化分析 3.爬虫设计方案概述 实现思路:通过爬取美团海底捞火锅评论及评分的数据,通过requests模块进行翻页爬取,利用xpath进行解析,提取用户名称,用户评论,用户评分及用户评星数据,通过pandas模块对数据进行保存,随后对数据进行清洗和处理,通过jieba、wordcloud分词、matplotlib库对文本数据进行分析并呈现。 技术难点 评论信息的定位和存储、css反爬技术的破解。 三.主题页面的结构特征分析1.主题页面的结构和特征分析 评论详情页:
翻页信息: 2.Htmls页面解析 一共532条评价,每次对一页15条数据进行爬取,利用xpath解析每条评论中的用户昵称、发布时间、用户评分、用户评论,爬取完毕后进行翻页,直到最后一页。
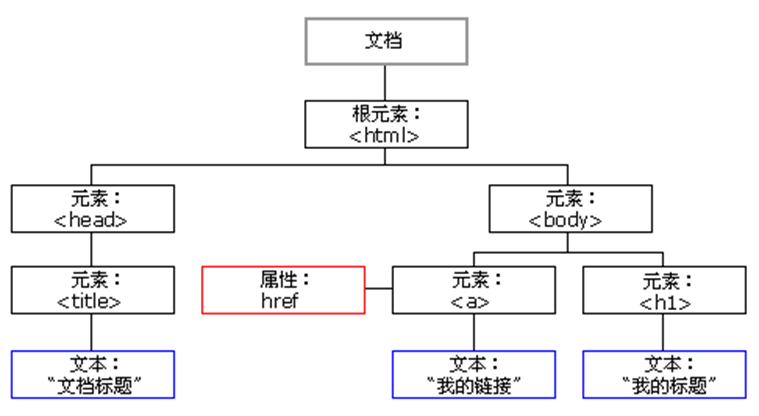
可以发现爬取的评论内容并不完整,很多评论内容是通过前端的精灵图实现的,这时候需要进行css反爬的破解工作,对css字体页面进行请求,然后在按照坐标一一对应到评论内容之中。 3.节点(标签)查找方法与遍历方法 查找方法:lxml库的xpath函数 lxml库是一个python的xml解析库,它支持HTML和xml的解析,并且支持Xpath解析方式。相比于原生的xml解析而言,lxml的接下效率相当高。 Xpath是一门在xml文档中查找信息的语言,虽然它最早是用来搜寻XML文档的,但它也可以用于查找html语言。它的选择功能十分强大,提供了非常简单明了的路径选择表达式,另外他还提供了超过100个内建函数用于数据处理。 Html示例图:
四.网络爬虫程序设计 1.数据的爬取与采集 import requests from lxml import etree import pandas as pd from time import sleep import re #css反爬 def decrypt(html): print('-' * 100) cssHref = 'http://s3plus.meituan.net/v1/' + html.split('href="//s3plus.meituan.net/v1/')[1].split('.css">')[0] + '.css' print(f'cssHref: {cssHref}') cssText = requests.get(cssHref).text svgHref = 'http:' + cssText.split('class^="uhy"')[1].split('url(')[1].split(')')[0] print(f'svgHref: {svgHref}') svgText = requests.get(svgHref).text heightDic = {} ex = '' for hei in re.compile(ex).findall(svgText): heightDic[hei[0]] = hei[1] print(f'heightDic: {str(heightDic)[:500]}') wordDic = {} ex = '(.*?)' for row in re.compile(ex).findall(svgText): for word in row[2]: wordDic[((row[2].index(word) + 1) * -14 + 14, int(heightDic[row[0]]) * -1 + 23)] = word print(f'wordDic: {str(wordDic)[:500]}') cssDic = {} ex = '.(.*?){background:(.*?).0px (.*?).0px;}' for css in re.compile(ex).findall(cssText): cssDic[css[0]] = (int(css[1]), int(css[2])) print(f'cssDic: {str(cssDic)[:500]}') decryptDic = {'': wordDic.get(cssDic[i], '?') for i in cssDic} print(f'decryptDic: {str(decryptDic)[:500]}') for key in decryptDic: html = html.replace(key, decryptDic[key]) print('-' * 100) return html #解析函数 def anaHtml(url): global resLs res = getHtml(url) tree = etree.HTML(res) for li in tree.xpath('//div[@class="reviews-items"]/ul/li'): name = li.xpath('.//a[@class="name"]/text()')[0].strip() date = li.xpath('.//span[@class="time"]/text()')[0].strip() score = '.'.join(li.xpath('.//div[@class="review-rank"]/span[1]/@class')[0].split()[1][-2:]) comment = ''.join(li.xpath('.//div[contains(@class,"review-words")]/text()')).replace('\n', '').strip() dic = { '昵称': name, '时间': date, '评分': score, '评论': comment } print(dic) resLs.append(dic) def main(): global resLs shop = input('shop: ').strip() page = input('page: ').strip() for p in range(eval(page)): p += 1 anaHtml(f'https://www.dianping.com/shop/{shop}/review_all/p{p}') print('-' * 100) print(f'page {p} finish') df = pd.DataFrame(resLs) writer = pd.ExcelWriter(f'{shop}.xlsx') df.to_excel(writer, index=False, encoding='utf-8') writer.save() if __name__ == '__main__': resLs = [] ck = '_lxsdk_cuid=184e04ba9bec8-0c18ce585c56e7-7d5d5476-1fa400-184e04ba9bec8; _lxsdk=184e04ba9bec8-0c18ce585c56e7-7d5d5476-1fa400-184e04ba9bec8;_hc.v=9817594e-b987-3951-6b4f-8e9a75f144b7.1670210366;WEBDFPID=3w12y6209uwv5xwx12487vv52u9z8z9w815v94vz64z9795894x88798-1985571610676-1670211609896UGKGGKSfd79fef3d01d5e9aadc18ccd4d0c95072884;dper=369157a9d63981701cd1efbf8e69ae87bfcd40ff958501250787c1068f5c9e1af4dace6f57be64fcfc46deea5deda02fda19e4007b1d90f5240d2f1cf2386a61;s_ViewType=10; ll=7fd06e815b796be3df069dec7836c3df;Hm_lvt_602b80cf8079ae6591966cc70a3940e7=1670210366,1671189319,1671415653;_lx_utm=utm_source%3Dbing%26utm_medium%3Dorganic;fspop=test;cy=14;cye=fuzhou;Hm_lpvt_602b80cf8079ae6591966cc70a3940e7=1671415751;_lxsdk_s=1852822e3a5-dcd-29d-093%7C%7C38' ua = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.46' main()
2.项目数据进行清洗和处理 (1)缺失值处理与重复值处理 由于数据信息的不完整,在数据爬取过程中经常会遇到NaN(数据缺少情况),因此首先需要对缺少数据进行剔除和过滤,Pandas库的dropna函数提供了快速删除空值函数的方法,设置axis=0,subset = df.columns即可快速删除含有空值的全部行。如下图经过预处理后的完成数据清洗的第一步。但发现没有重复值与缺失值
(2)异常值处理 通过为评分一列分类得到以下结果,结果发现存在r.5数据,因此需要对其进行剔除
剔除后的结果
结果显示剔除后的数据量减少到518个
剔除后的总数据
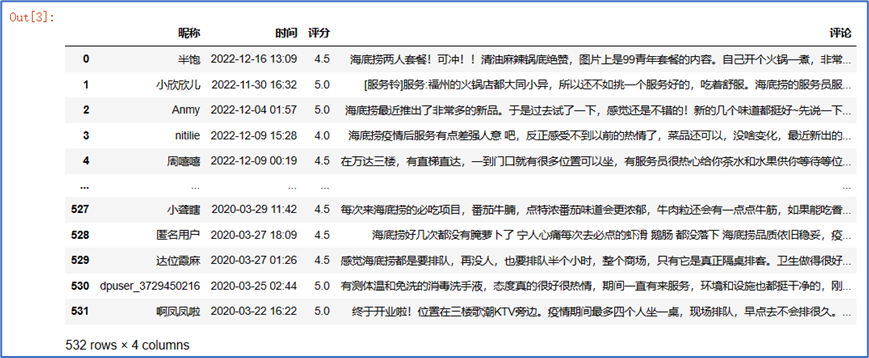
代码: in_path = r'福州万达海底捞评论.xlsx' #设置文件路径 df = pd.read_excel(in_path, header=0) count = df['评分'].value_counts() print('预处理前结果', df) df1 = df.dropna(axis=0, subset=df.columns) # 丢弃有缺失值的列 df1 = df1.reset_index() df1 = df1[df.columns] df1.drop_duplicates() # 异常值的删除 Outliers = [] # 记录异常值的行 for i in range(len(df)): a = str(df1.iloc[i, 2]).replace('.', '') if not a.isdigit(): Outliers.append(i) df1.drop(index=Outliers, axis=0, inplace=True) df1 = df1.reset_index() df1 = df1[df.columns] print("预处理后结果",df1) count = df1['评分'].value_counts() print("开始进行文本处理") print(count)
3.数据分析与可视化 通过对评分进行分类得到以下结果:
随后对评分进行可视化分析:代码如下: #绘制饼状图 plt.rcParams["font.sans-serif"] = ["SimHei"] plt.rcParams["axes.unicode_minus"] = False labels = 5.0, 4.5, 4, 3.5, 3.0, 2.5, 2.0, 1.5 sizes = 250, 161, 70, 18, 4, 10, 2, 3 colors = 'lightgreen', 'gold', 'lightskyblue', 'lightcoral', 'red', 'darkred', 'mediumblue', 'green' explode = 0, 0, 0, 0, 0, 0, 0, 0 plt.pie(sizes, explode=explode, labels=labels,colors=colors, autopct='%1.1f%%', shadow=True, startangle=50) plt.axis('equal') plt.title(u'福州万达海底捞评论分值分布图') plt.show()
得到以下结果:
使用结巴分词精准模式对文本进行分词处理,将所以文本进行合并,并进行分词得到以下结果: 发现分词结果存在很多符号,将其进行剔除即可。
剔除完特殊符号的结果如下:
结巴分词结果统计
随后基于worldcloud包对结果进行可视化:
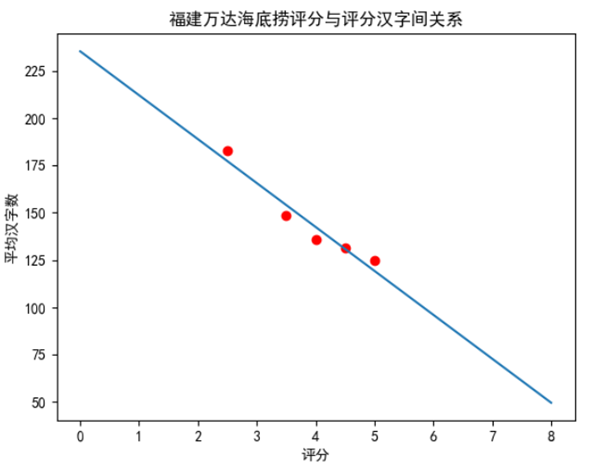
本次测试评分数与汉字评价长度的关系,探索其关系: 首先对数据进行分类得到,随后按照不同类别进行计算得到不同星级的平均评价长度,如下图所示 随后对其进行线性拟合得到以下方程:
随后将其可视化得到以下结果:
线性拟合部分代码 def linefit(x, y): N = float(len(x)) sx, sy, sxx, syy, sxy = 0, 0, 0, 0, 0 for i in range(0, int(N)): sx += x[i] sy += y[i] sxx += x[i] * x[i] syy += y[i] * y[i] sxy += x[i] * y[i] a = (sy * sx / N - sxy) / (sx * sx / N - sxx) b = (sy - a * sx) / N r = abs(sy * sx / N - sxy) / math.sqrt((sxx - sx * sx / N) * (syy - sy * sy / N)) return a, b, r x = [5.0, 4.5, 4.0, 3.5, 2.5] y = [124.748, 131.61490683229815, 136.0142857142857, 148.55555555555554, 183.0] a, b, r = linefit(x, y) print(" y = %10.5f x + %10.5f , r=%10.5f" % (a, b, r))
五.源码 import requests from lxml import etree import pandas as pd from time import sleep import re #css反爬 def decrypt(html): print('-' * 100) cssHref = 'http://s3plus.meituan.net/v1/' + html.split('href="//s3plus.meituan.net/v1/')[1].split('.css">')[0] + '.css' print(f'cssHref: {cssHref}') cssText = requests.get(cssHref).text svgHref = 'http:' + cssText.split('class^="uhy"')[1].split('url(')[1].split(')')[0] print(f'svgHref: {svgHref}') svgText = requests.get(svgHref).text heightDic = {} ex = '' for hei in re.compile(ex).findall(svgText): heightDic[hei[0]] = hei[1] print(f'heightDic: {str(heightDic)[:500]}') wordDic = {} ex = '(.*?)' for row in re.compile(ex).findall(svgText): for word in row[2]: wordDic[((row[2].index(word) + 1) * -14 + 14, int(heightDic[row[0]]) * -1 + 23)] = word print(f'wordDic: {str(wordDic)[:500]}') cssDic = {} ex = '.(.*?){background:(.*?).0px (.*?).0px;}' for css in re.compile(ex).findall(cssText): cssDic[css[0]] = (int(css[1]), int(css[2])) print(f'cssDic: {str(cssDic)[:500]}') decryptDic = {'': wordDic.get(cssDic[i], '?') for i in cssDic} print(f'decryptDic: {str(decryptDic)[:500]}') for key in decryptDic: html = html.replace(key, decryptDic[key]) print('-' * 100) return html # 响应函数与滑块验证码反爬 def getHtml(url): sign = '验证中心' headers = { 'Cookie': ck, 'Referer': url, 'User-Agent': ua } while True: res = requests.get(url=url, headers=headers).content.decode('utf-8') if sign in res: input('出现滑块,解锁回车: ') else: break sleep(5) return decrypt(res) #解析函数 def anaHtml(url): global resLs res = getHtml(url) tree = etree.HTML(res) for li in tree.xpath('//div[@class="reviews-items"]/ul/li'): name = li.xpath('.//a[@class="name"]/text()')[0].strip() date = li.xpath('.//span[@class="time"]/text()')[0].strip() score = '.'.join(li.xpath('.//div[@class="review-rank"]/span[1]/@class')[0].split()[1][-2:]) comment = ''.join(li.xpath('.//div[contains(@class,"review-words")]/text()')).replace('\n', '').strip() dic = { '昵称': name, '时间': date, '评分': score, '评论': comment } print(dic) resLs.append(dic) def main(): global resLs shop = input('shop: ').strip() page = input('page: ').strip() for p in range(eval(page)): p += 1 anaHtml(f'https://www.dianping.com/shop/{shop}/review_all/p{p}') print('-' * 100) print(f'page {p} finish') df = pd.DataFrame(resLs) writer = pd.ExcelWriter(f'{shop}.xlsx') df.to_excel(writer, index=False, encoding='utf-8') writer.save() if __name__ == '__main__': resLs = [] ck = '_lxsdk_cuid=184e04ba9bec8-0c18ce585c56e7-7d5d5476-1fa400-184e04ba9bec8; _lxsdk=184e04ba9bec8-0c18ce585c56e7-7d5d5476-1fa400-184e04ba9bec8; _hc.v=9817594e-b987-3951-6b4f-8e9a75f144b7.1670210366; WEBDFPID=3w12y6209uwv5xwx12487vv52u9z8z9w815v94vz64z9795894x88798-1985571610676-1670211609896UGKGGKSfd79fef3d01d5e9aadc18ccd4d0c95072884; dper=369157a9d63981701cd1efbf8e69ae87bfcd40ff958501250787c1068f5c9e1af4dace6f57be64fcfc46deea5deda02fda19e4007b1d90f5240d2f1cf2386a61; s_ViewType=10; ll=7fd06e815b796be3df069dec7836c3df; Hm_lvt_602b80cf8079ae6591966cc70a3940e7=1670210366,1671189319,1671415653; _lx_utm=utm_source%3Dbing%26utm_medium%3Dorganic; fspop=test; cy=14; cye=fuzhou; Hm_lpvt_602b80cf8079ae6591966cc70a3940e7=1671415751; _lxsdk_s=1852822e3a5-dcd-29d-093%7C%7C38' ua = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.46' main() import jieba from matplotlib import pyplot as plt import math import numpy as np import pandas as pd from wordcloud import WordCloud, ImageColorGenerator from PIL import Image in_path = r'福州万达海底捞评论.xlsx' #设置文件路径 df = pd.read_excel(in_path, header=0) count = df['评分'].value_counts() print('预处理前结果', df) df1 = df.dropna(axis=0, subset=df.columns) # 丢弃有缺失值的列 df1 = df1.reset_index() df1 = df1[df.columns] df1.drop_duplicates() # 异常值的删除 Outliers = [] # 记录异常值的行 for i in range(len(df)): a = str(df1.iloc[i, 2]).replace('.', '') if not a.isdigit(): Outliers.append(i) df1.drop(index=Outliers, axis=0, inplace=True) df1 = df1.reset_index() df1 = df1[df.columns] print("预处理后结果",df1) count = df1['评分'].value_counts() print("开始进行文本处理") print(count) b = list(jieba.cut(df1.iloc[6, 3], cut_all=False)) ##分词 list_words = [] for i in range(len(df1)): b = list(jieba.cut(df1.iloc[i, 3], cut_all=False)) list_words += b data1 = pd.DataFrame(data=None, columns=['ID', 'world'], index=range(len(list_words))) for i in range(len(data1)): data1.iloc[i, 0] = i data1.iloc[i, 1] = list_words[i] count1 = data1['world'].value_counts() data2 = pd.DataFrame(data=None, columns=['word', 'number'], index=range(len(count1))) list11 = list(count1) list22 = list(count1.index) print('正在绘制') for i in range(len(data2)): data2.iloc[i, 1] = list11[i] data2.iloc[i, 0] = list22[i] print(data2) print('分词结果为', data2) print('开始进行线性拟合') # data2.to_csv(r'F:\Desktop\分词统计结果.csv', encoding="utf_8_sig") # 保存结果 # 第三步线性拟合 result_count = list(df1['评分'].value_counts()) result_count1 = list(df1['评分'].value_counts().index) result_list = [] print(result_count1) print(result_count) result_word_name = [0, 0, 0, 0, 0, 0, 0, 0] for i in range(len(df1)): for j in range(8): if df1.loc[i, '评分'] == result_count1[j]: result_word_name[j] += len(df1.loc[i, '评论']) result_word_name[5] += 300 result_word_name[6] += 300 result_word_name[6] += 300 for i in range(len(result_word_name)): result_word_name[i] = result_word_name[i] / result_count[i] print(result_word_name) print('完成线性拟合统计') print('正在绘制图片1') plt.rcParams["font.sans-serif"] = ["SimHei"] plt.rcParams["axes.unicode_minus"] = False labels = 5.0, 4.5, 4, 3.5, 3.0, 2.5, 2.0, 1.5 sizes = 250, 161, 70, 18, 4, 10, 2, 3 colors = 'lightgreen', 'gold', 'lightskyblue', 'lightcoral', 'red', 'darkred', 'mediumblue', 'green' explode = 0, 0, 0, 0, 0, 0, 0, 0 plt.pie(sizes, explode=explode, labels=labels,colors=colors, autopct='%1.1f%%', shadow=True, startangle=50) plt.axis('equal') plt.title(u'福州万达海底捞评论分值分布图') plt.show() "" print('正在绘制图片2') def linefit(x, y): N = float(len(x)) sx, sy, sxx, syy, sxy = 0, 0, 0, 0, 0 for i in range(0, int(N)): sx += x[i] sy += y[i] sxx += x[i] * x[i] syy += y[i] * y[i] sxy += x[i] * y[i] a = (sy * sx / N - sxy) / (sx * sx / N - sxx) b = (sy - a * sx) / N r = abs(sy * sx / N - sxy) / math.sqrt((sxx - sx * sx / N) * (syy - sy * sy / N)) return a, b, r x = [5.0, 4.5, 4.0, 3.5, 2.5] y = [124.748, 131.61490683229815, 136.0142857142857, 148.55555555555554, 183.0] a, b, r = linefit(x, y) print(" y = %10.5f x + %10.5f , r=%10.5f" % (a, b, r)) plt.plot(x, y, 'ro') plt.plot([0, 8], [b, a * 8 + b]) plt.xlabel("评分") plt.ylabel("平均汉字数") plt.title('福建万达海底捞评分与评分汉字间关系') plt.show() def draw_cloud(read_name): image = Image.open(r'E:\rdy\Desktop\海底捞.jpg') # 作为背景轮廓图 graph = np.array(image) # 参数分别是指定字体、背景颜色、最大的词的大小、使用给定图作为背景形状 wc = WordCloud(font_path=r'simhei.ttf',background_color='white',max_words=100, mask=graph)#设置ttf文件路径 data = pd.read_csv(r'分词统计结果.csv', encoding='utf-8') # 读取词频文件 name = list(data['word'])[0:150] # 词 value = list(data['number'])[0:150] # 词的频率 for i in range(len(name)): name[i] = str(name[i]) dic = dict(zip(name, value)) # 词频以字典形式存储 wc.generate_from_frequencies(dic) # 根据给定词频生成词云 image_color = ImageColorGenerator(graph)#生成词云的颜色 wc.to_file('词云.png') # 图片命名 draw_cloud('1.csv')
六.总结 经过数据的分析和可视化,可以发现用户的评论和评分存在联系不大,用户的体验可能存在不明因素干扰,总体来说,这家店的评价还不错,可以尝试。 经过一学期的网络爬虫学习,我意识到在生活中或是未来工作中,网络爬虫是我可以利用的一种高效工具。网络爬虫技术在科学研究、Web安全、产品研发等方面都起着重要作用。在数据处理方面,如果没有数据就可以通过爬虫从网上筛选抓取自己想要的数据。并且伴随着网络技术的发展,我们早已进入信息爆炸的时代,面对繁冗的数据,我们很难从里面提取到有价值的数据,为了解决传统人工收集数据的不便的问题,通过利用爬虫技术就可以轻松找到自己想要的数据。在本学期的学习中虽然遇到了很多困难,通过一次次的纠正,不断地找出问题所在,最后解决问题。这仿佛是一条登山之路,比起唾手可得的成功,向上攀登的路程更加令我振奋,我相信这也是学习爬虫技术的意义之一。 本次课程设计,让我学会了爬虫的基本原理,数据清洗和处理的方式。其中,爬虫常用requests模拟请求网页,获取数据。同时使我熟悉了文本数据分析的基本流程,在词云可视化和线性拟合方面也有了诸多的体悟。 我会在接下来的日子继续钻研爬虫的知识,强化数据分析和可视化的能力。 |










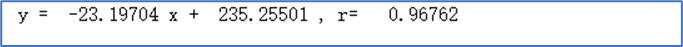 、
、
【本文地址】