java使用HttpURLConnection检索网站时403错误处理方式 |
您所在的位置:网站首页 › 网页提示403错误 › java使用HttpURLConnection检索网站时403错误处理方式 |
java使用HttpURLConnection检索网站时403错误处理方式
|
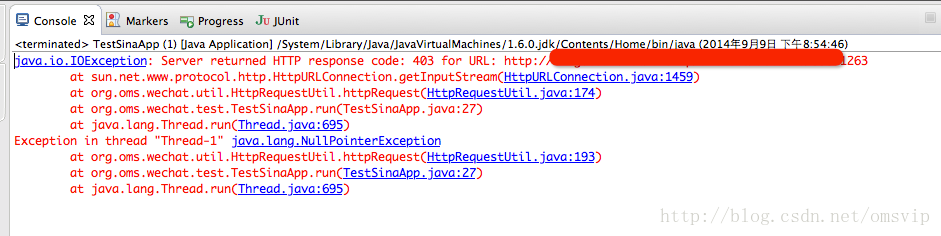
java使用HttpURLConnection检索网站时403错误处理方式: 我们通过代码方式访问网站时会报错:
此种情况分2中类型, 1.需要登录才可以访问; 2.需要设置User-Agent来欺骗服务器。 connection.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");User Agent说明: User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。 一些网站常常通过判断 UA 来给不同的操作系统、不同的浏览器发送不同的页面,因此可能造成某些页面无法在某个浏览器中正常显示,但通过伪装 UA 可以绕过检测。java访问网站代码: /** * 发起http get请求获取网页源代码 * @param requestUrl * @param isUserAgent 是否设置欺骗服务器 * @return */ public static String httpRequest(String requestUrl,boolean isUserAgent) { StringBuffer buffer = null; try { // 建立连接 URL url = new URL(requestUrl); HttpURLConnection httpUrlConn = (HttpURLConnection) url.openConnection(); httpUrlConn.setDoInput(true); httpUrlConn.setRequestMethod("GET"); if(isUserAgent){ httpUrlConn.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)"); } // 获取输入流 InputStream inputStream = httpUrlConn.getInputStream(); InputStreamReader inputStreamReader = new InputStreamReader(inputStream, "utf-8"); BufferedReader bufferedReader = new BufferedReader(inputStreamReader); // 读取返回结果 buffer = new StringBuffer(); String str = null; while ((str = bufferedReader.readLine()) != null) { buffer.append(str); } } catch (Exception e) { e.printStackTrace(); }finally{ // 释放资源 bufferedReader.close(); inputStreamReader.close(); inputStream.close(); httpUrlConn.disconnect(); } return buffer.toString(); } 执行结果:顺利获取到网页代码。
|

【本文地址】
今日新闻 |
推荐新闻 |