浏览器插件:WebScraper基本用法和抓取页面内容(不会编程也能爬取数据) |
您所在的位置:网站首页 › 网页提取文字工具 › 浏览器插件:WebScraper基本用法和抓取页面内容(不会编程也能爬取数据) |
浏览器插件:WebScraper基本用法和抓取页面内容(不会编程也能爬取数据)
|
Web Scraper 是一个浏览器扩展,用于从页面中提取数据(网页爬虫)。对于简单或偶然的需求非常有用,例如正在写代码缺少一些示例数据,使用此插件可以很快从类似的网站提取内容作为模拟数据。从 Chrome 的插件市场安装后,页面 F12 打开开发者工具会多出一个名 Web Scraper 的面板,接下来以此作为开始。 快速上手写个例子:提取百度首页底部几个导航按钮的文字,了解下 Web Scraper 是如何工作。 创建任务创建任务,即创建 SiteMap(这词不常用,还是用我们熟悉的词吧,意思大致一样就行)。打开 百度首页,再打开开发者面板如下操作,其中URL可以使用特殊语法,这个后面再谈。 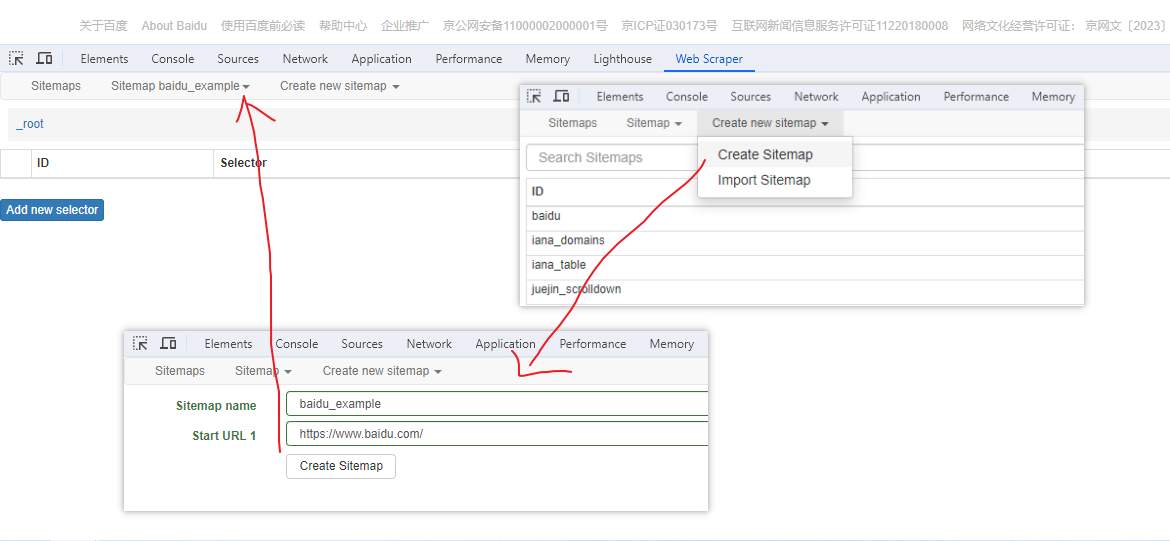 b0d7f7928b505140cf054e413c752ee4.png选择内容 b0d7f7928b505140cf054e413c752ee4.png选择内容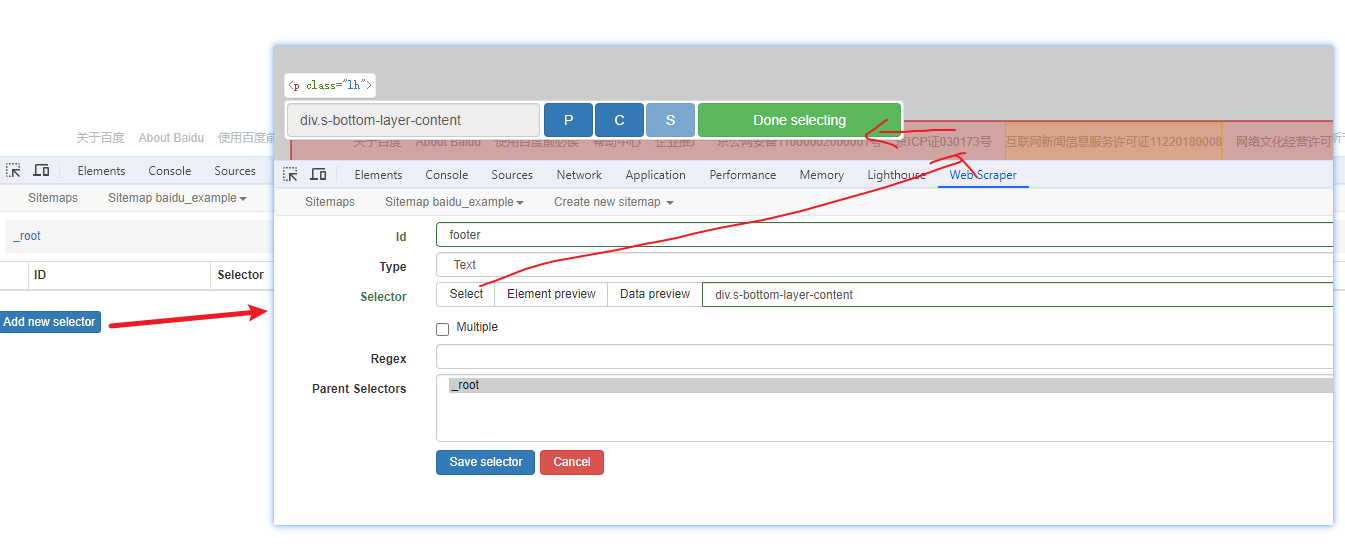 814c40674387447440b221236529fc3b.png开始抓取 814c40674387447440b221236529fc3b.png开始抓取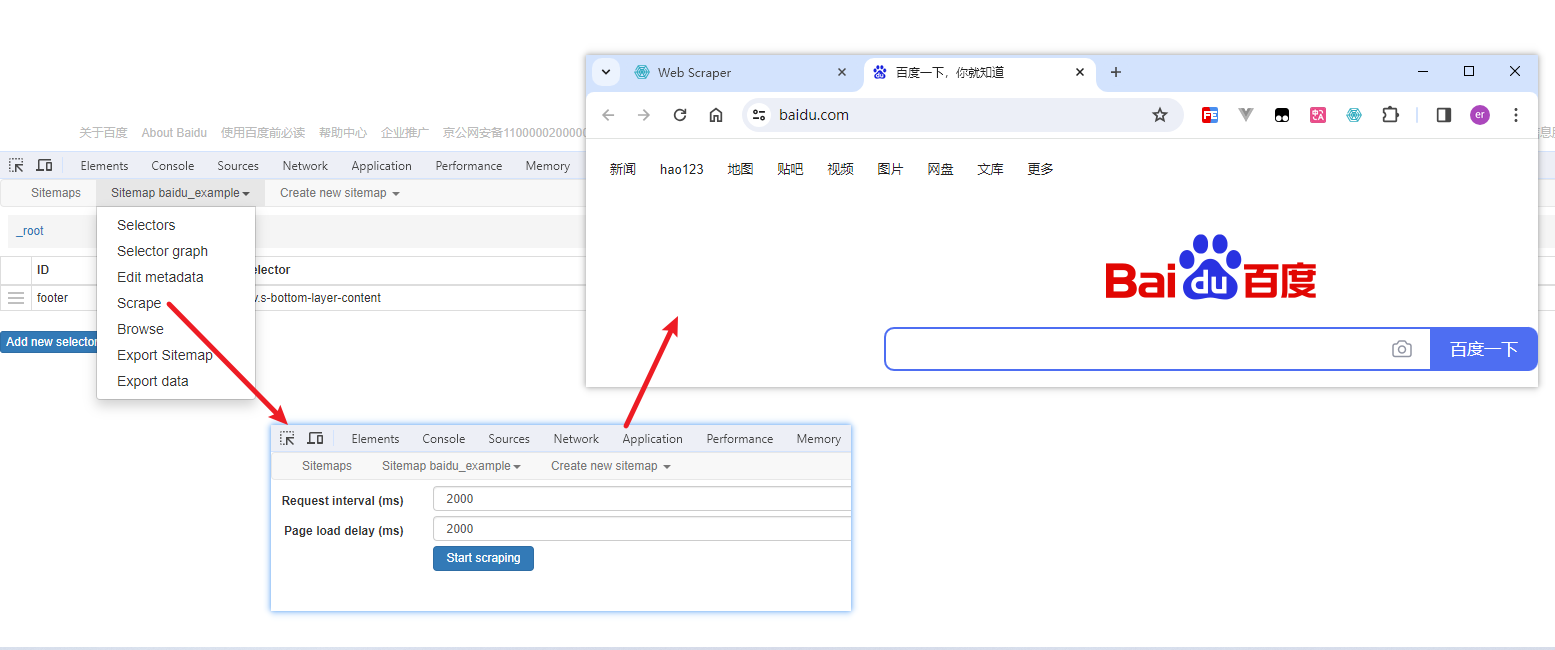 47d98beeeaa3febab10ba37c343375c9.png浏览数据 47d98beeeaa3febab10ba37c343375c9.png浏览数据抓取完肯定要确认数据是否正确,格式不正确需要重新调整选择器,浏览数据的步骤如下: 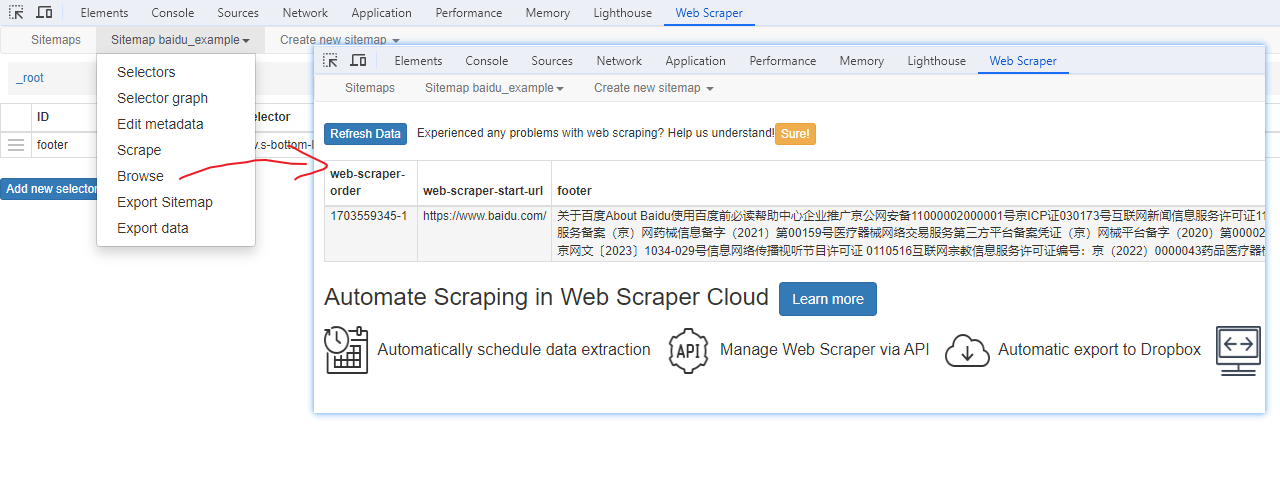 23a2fb6279806fab7ac17981134474ee.png保存数据 23a2fb6279806fab7ac17981134474ee.png保存数据确认无误后,就可以进行保存(如下)。目前只能导出 excel 或 csv 格式,json 需要充值(会员),不过也不是啥大问题,随便找个在线网站转一下就行。 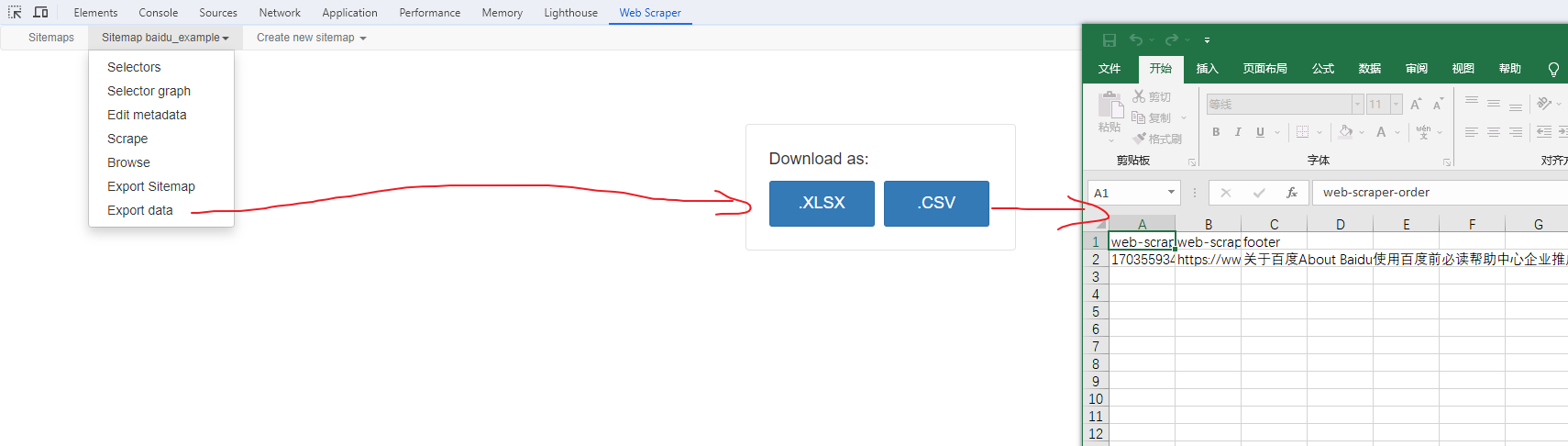 4552af220ff300891ca4072fb2db6ce8.png浏览数据 4552af220ff300891ca4072fb2db6ce8.png浏览数据抓取完肯定要确认数据是否正确,格式不正确需要重新调整选择器,浏览数据的步骤如下: 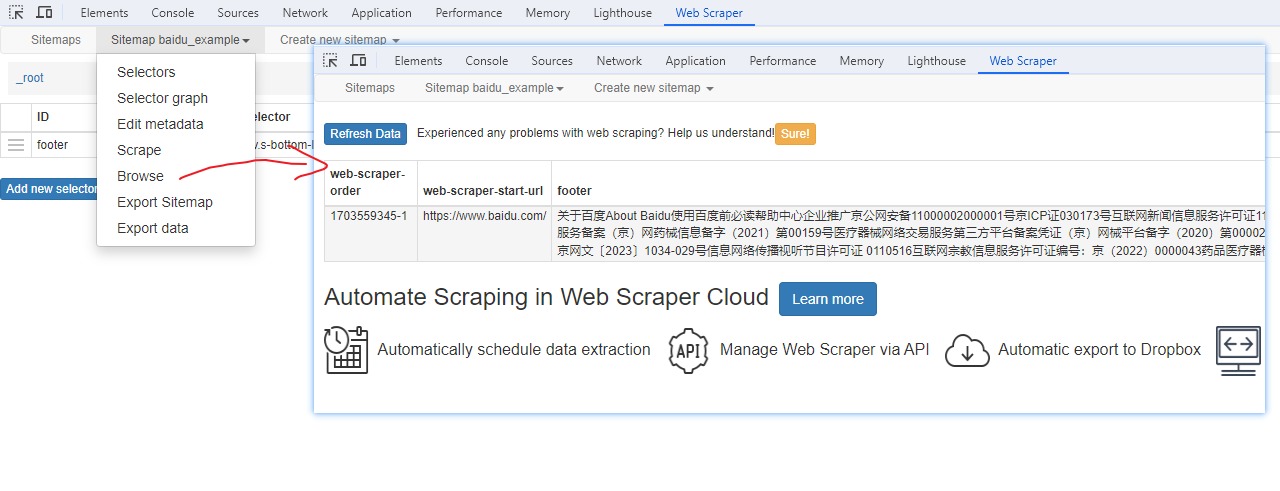 5984c937f0dd40deb1e810253cf0a4d1.png保存数据 5984c937f0dd40deb1e810253cf0a4d1.png保存数据确认无误后,就可以进行保存(如下)。目前只能导出 excel 或 csv 格式,json 需要充值(会员),不过也不是啥大问题,随便找个在线网站转一下就行。 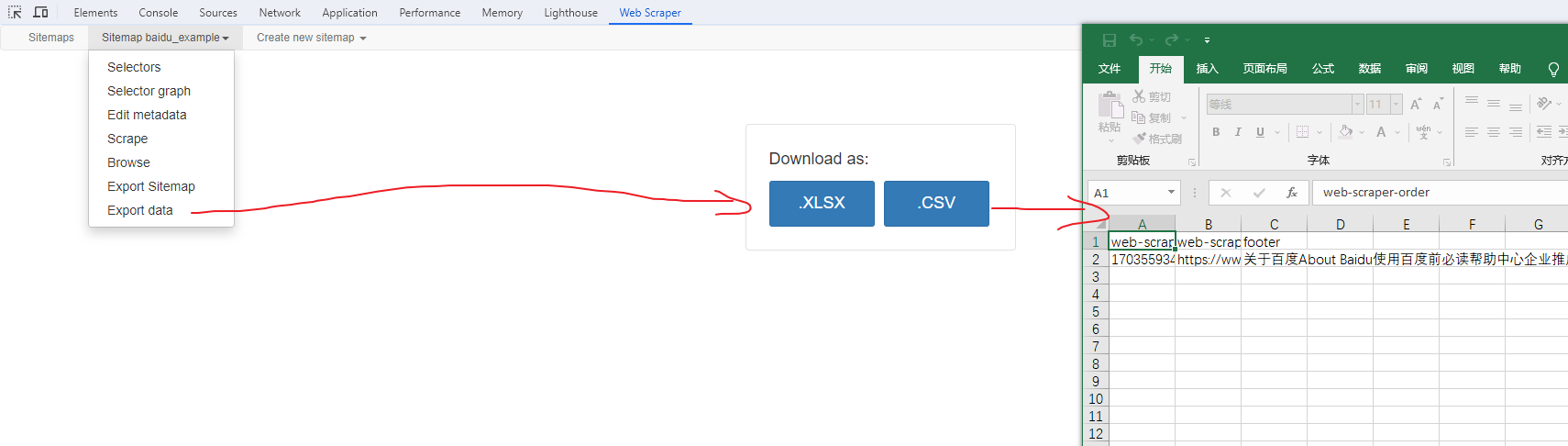 22c067fd4a9a45569675020f49c19e43.png小结 22c067fd4a9a45569675020f49c19e43.png小结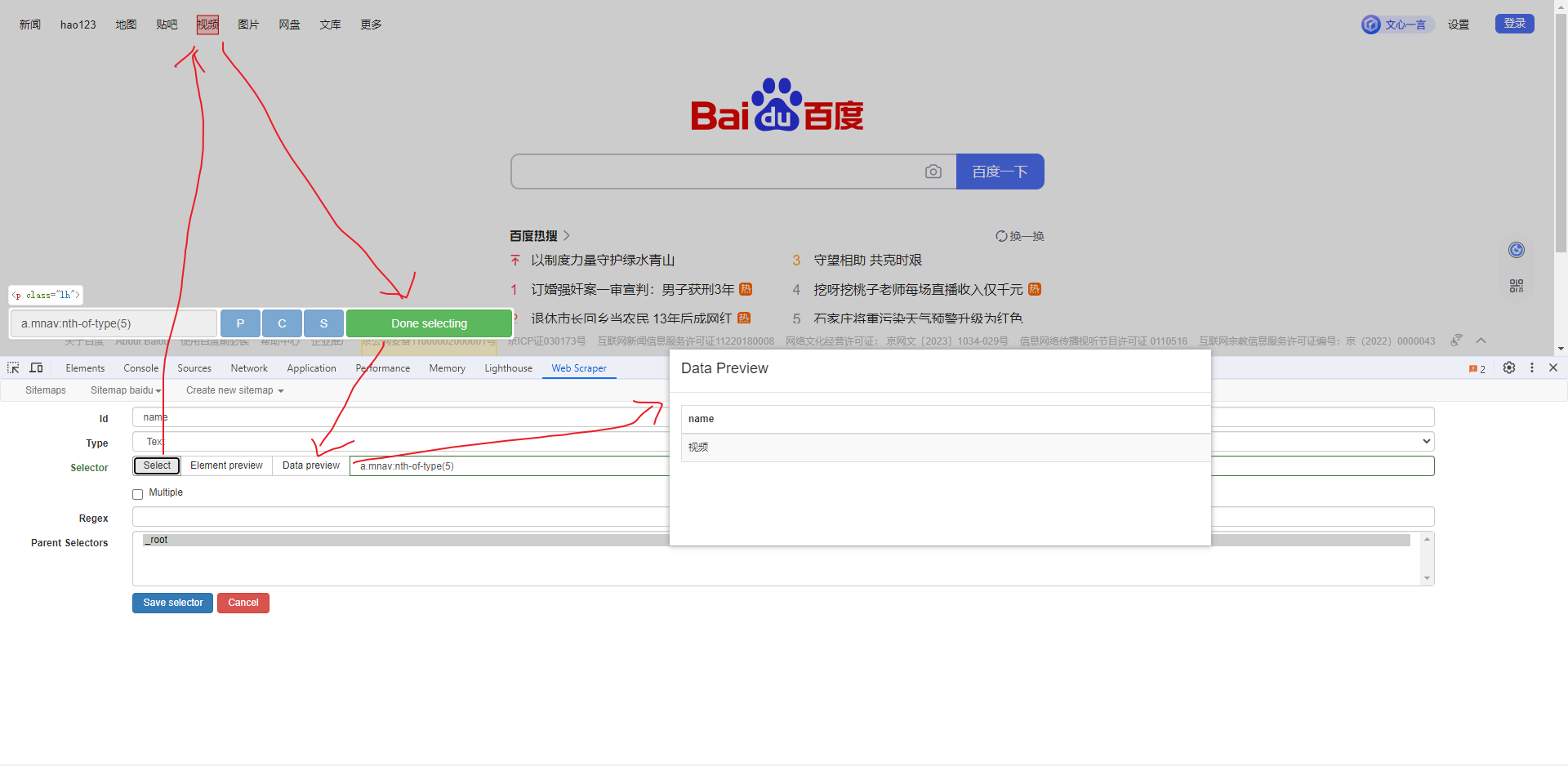 3ad5e4ba9b2c38c5c6b8957266f1fc73.png图片选择器 3ad5e4ba9b2c38c5c6b8957266f1fc73.png图片选择器抓取的URL支持特殊语法,如果页面分页体现在URL上的话还是非常有用的。如下: 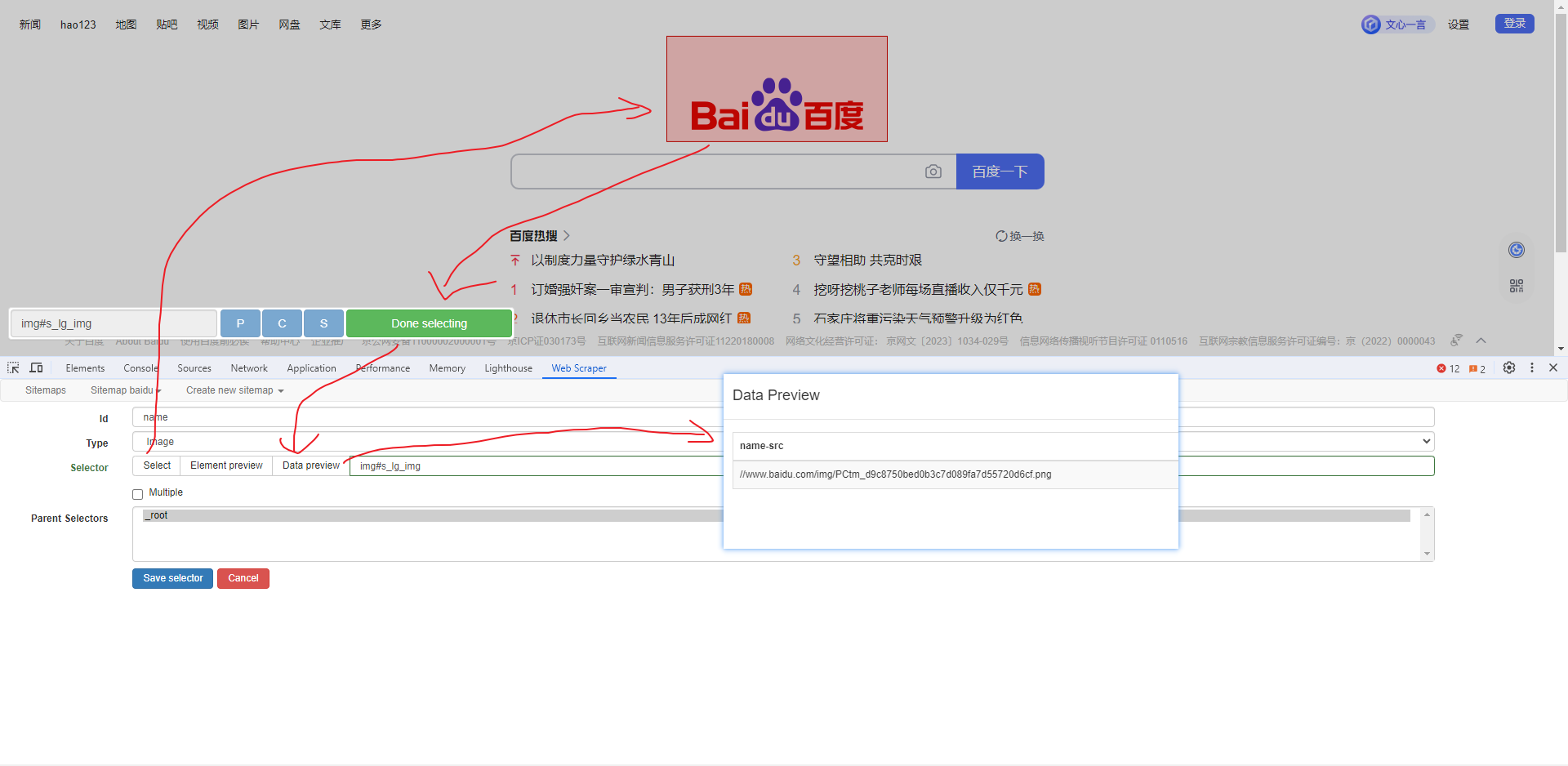 b108cf37595d13804748c553e2bb84f1.png表格选择器 b108cf37595d13804748c553e2bb84f1.png表格选择器提取表格数据,以 IANA的域名列表 为例,如下: 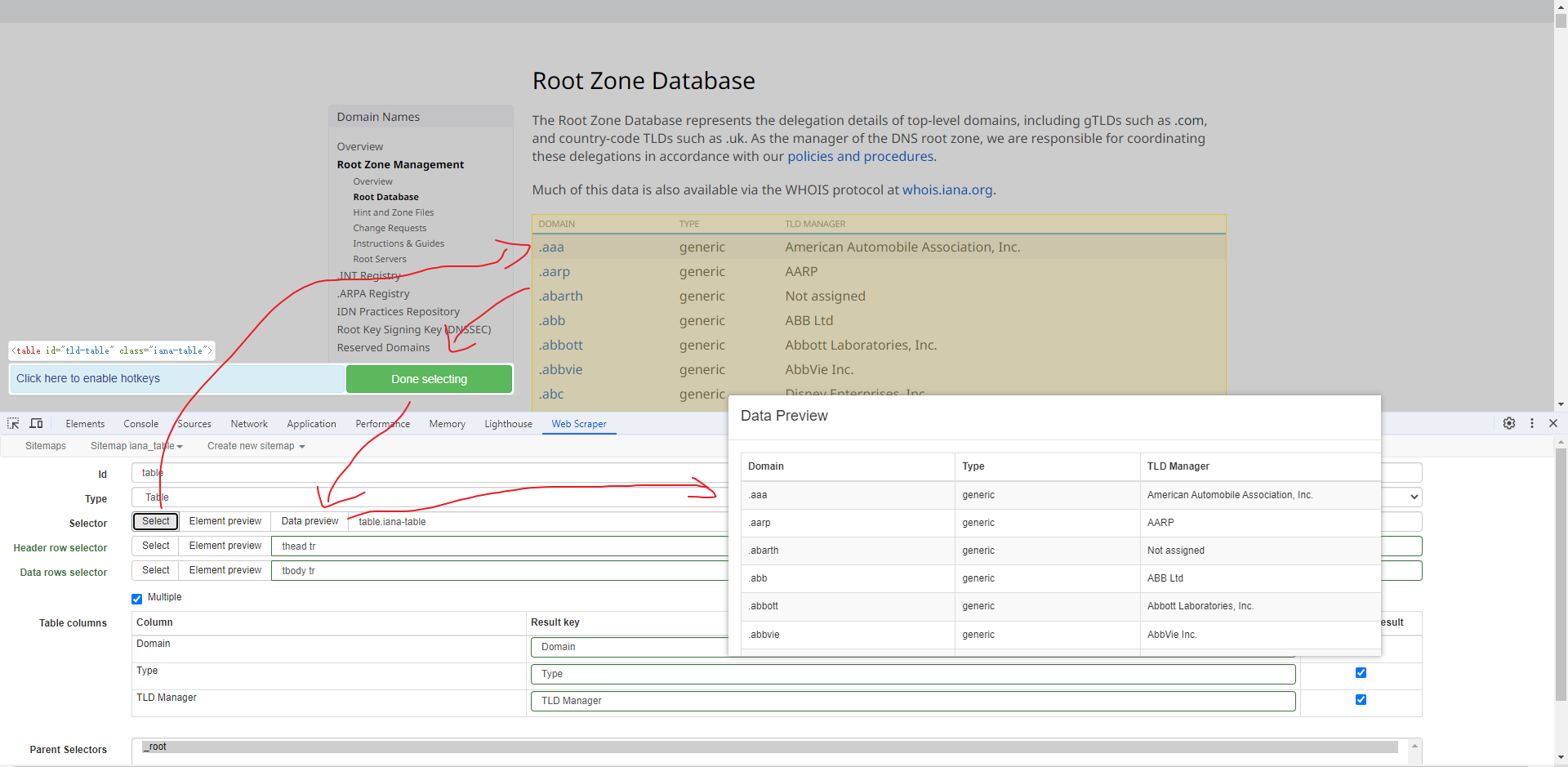 1944f739bec9c3904b09203750684bc2.png链接选择器 1944f739bec9c3904b09203750684bc2.png链接选择器提取链接名字和地址,以 百度首页 为例, 如下: 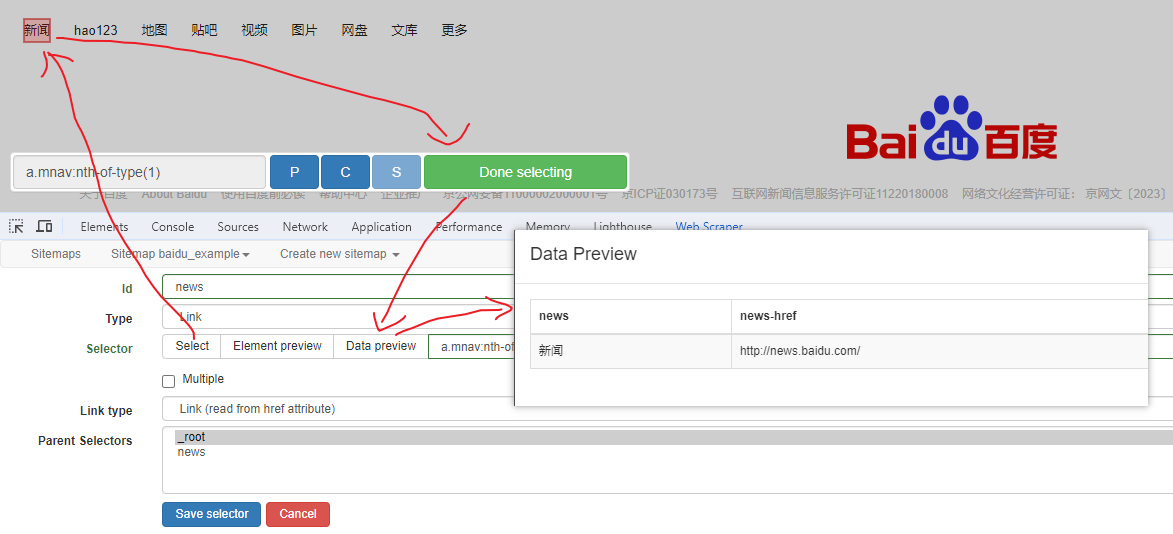 662d56bb5d95c5d6887914e97f489fd9.png 662d56bb5d95c5d6887914e97f489fd9.png百度首页 为例, 如下: 属性选择器提取属性值,以 百度首页 为例, 如下: 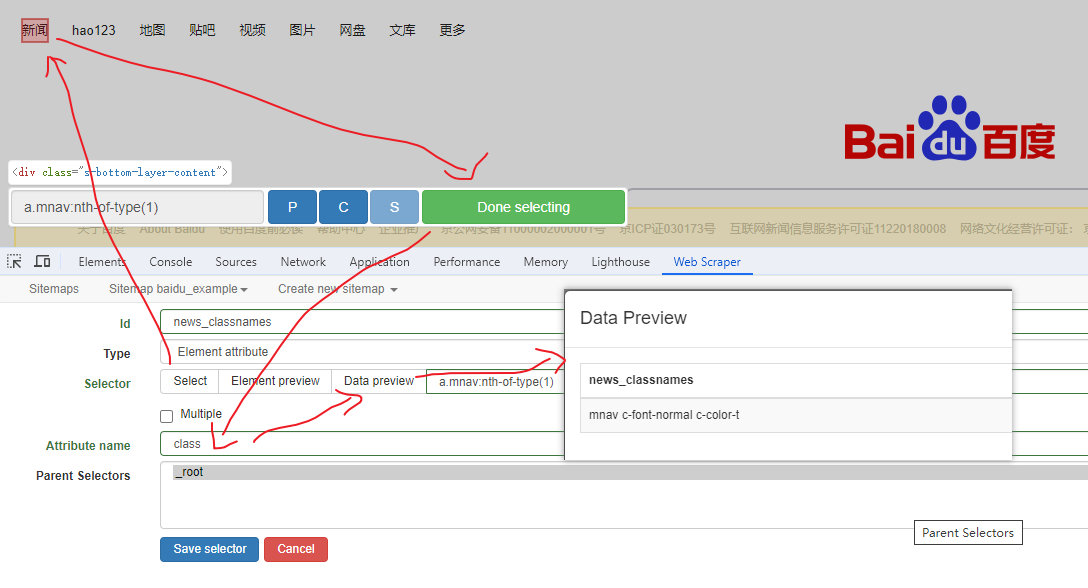 d6aadd12fae845ba7c8e5ebd85b03515.png图片选择器 d6aadd12fae845ba7c8e5ebd85b03515.png图片选择器提取图片地址,以 百度首页 为例, 如下: 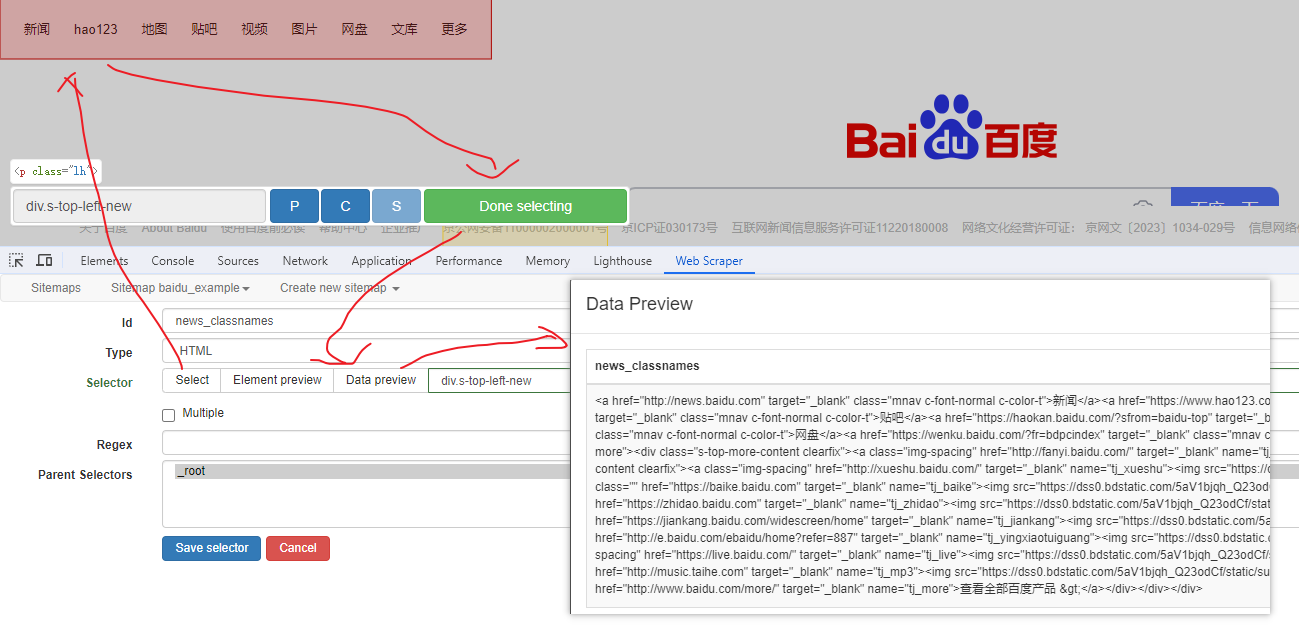 add1faca0f5ca8dc6698c1baec2280d5.png元素选择器 add1faca0f5ca8dc6698c1baec2280d5.png元素选择器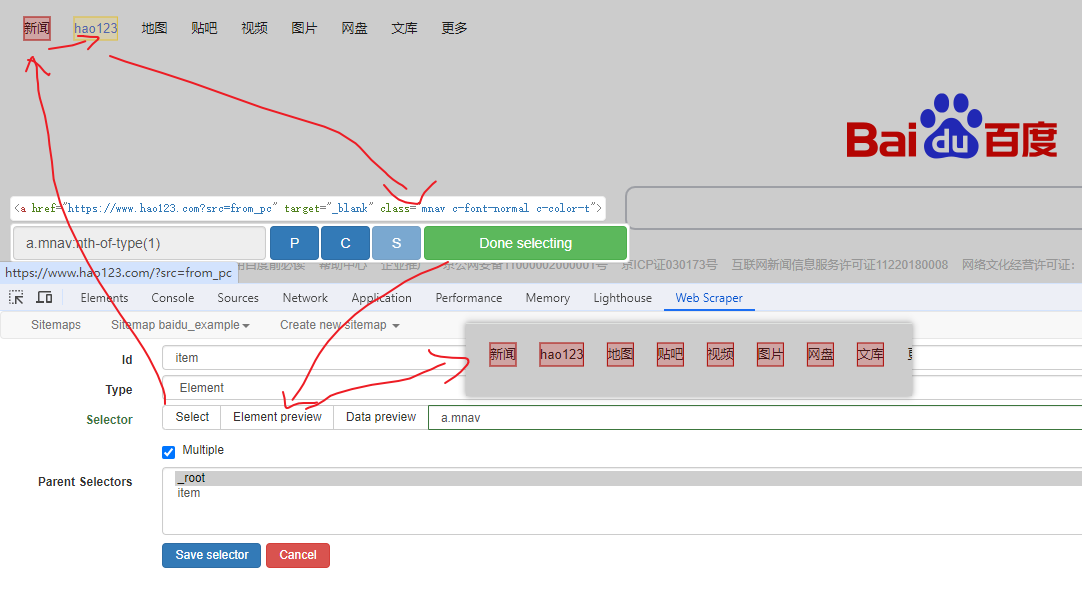 a383cb0664a86e25ba4ea8d89c088046.png a383cb0664a86e25ba4ea8d89c088046.png提取表格数据,以 IANA的域名列表 为例,如下: 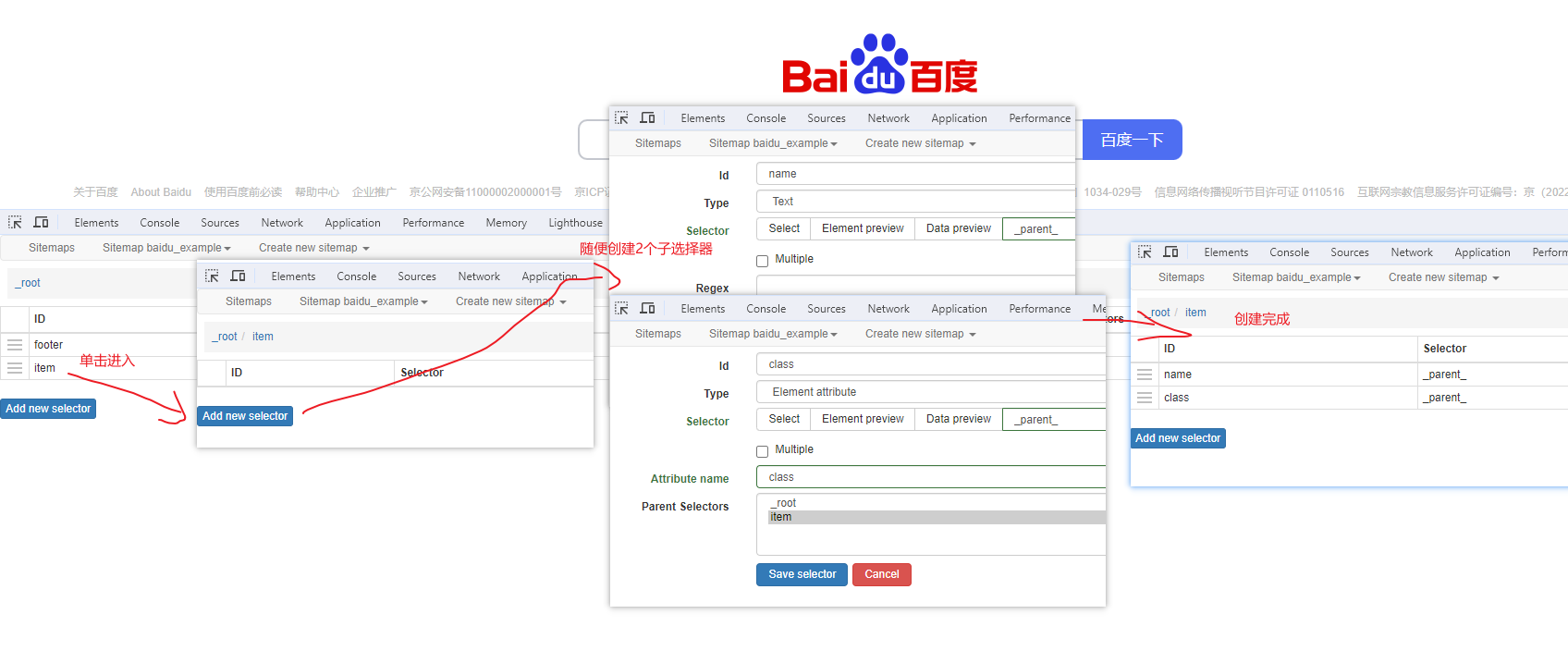 ea96851b459ac0e3645a0fe4c5275abf.png ea96851b459ac0e3645a0fe4c5275abf.png元素和子选择器创建好就可以了,以下是预览到的数据: 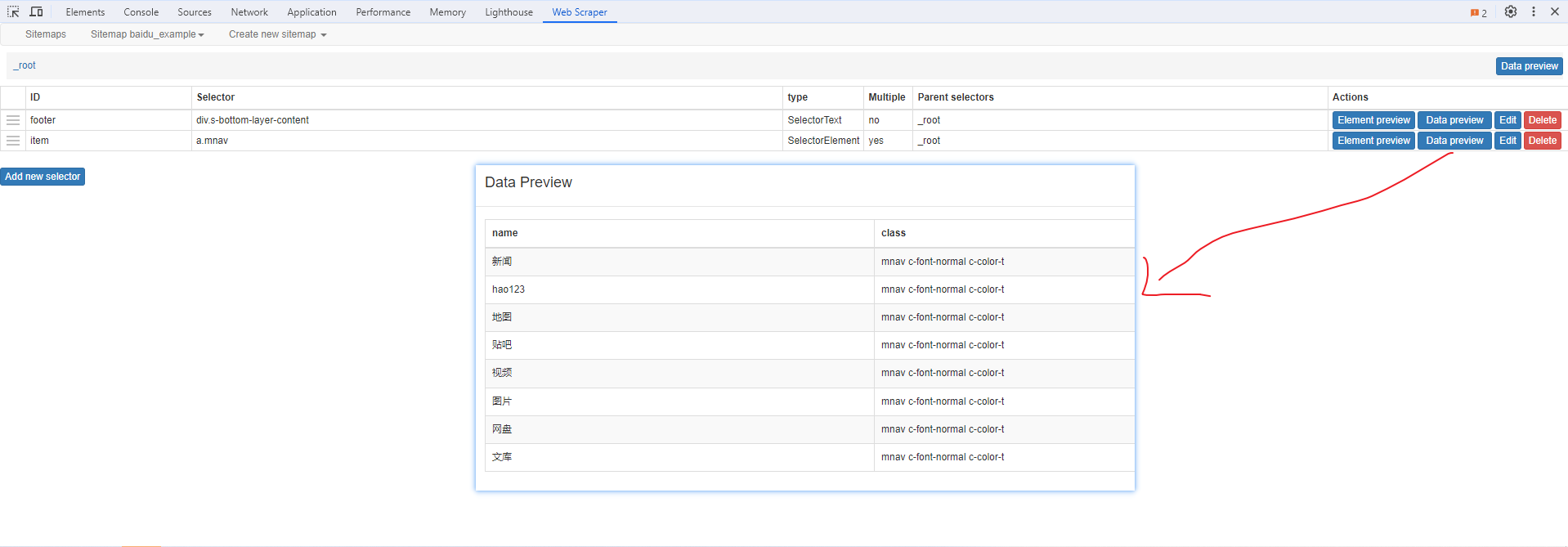 faf11deed5aa3155aa557e9c6d91bc0f.png链接选择器 faf11deed5aa3155aa557e9c6d91bc0f.png链接选择器提取链接名字和地址,以 百度首页 为例, 如下: 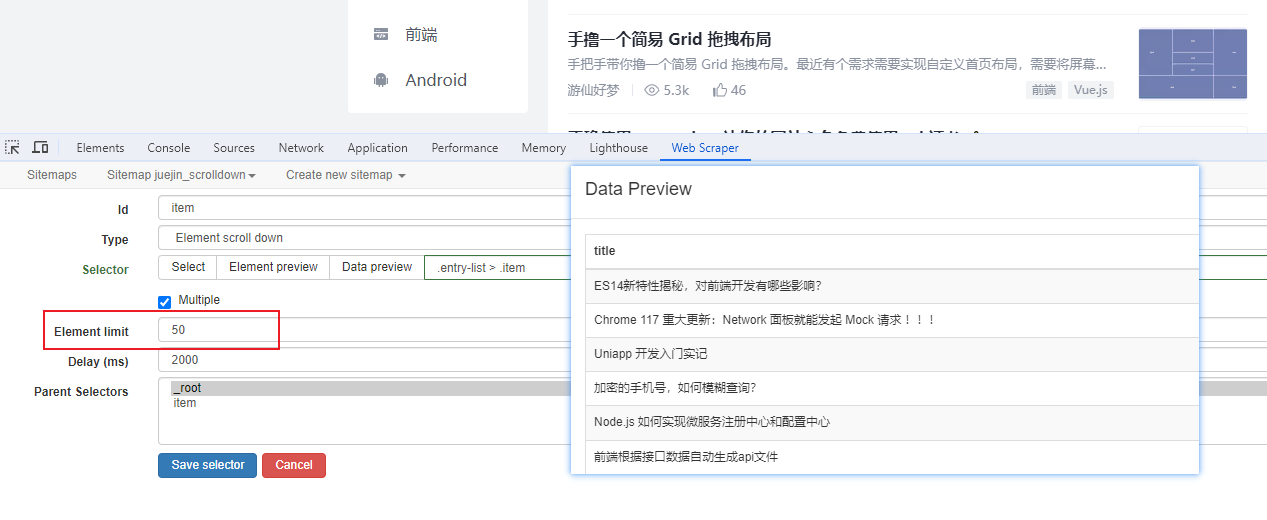 393776e014368ee70dd894cc746c92c0.png元素点击选择器 393776e014368ee70dd894cc746c92c0.png元素点击选择器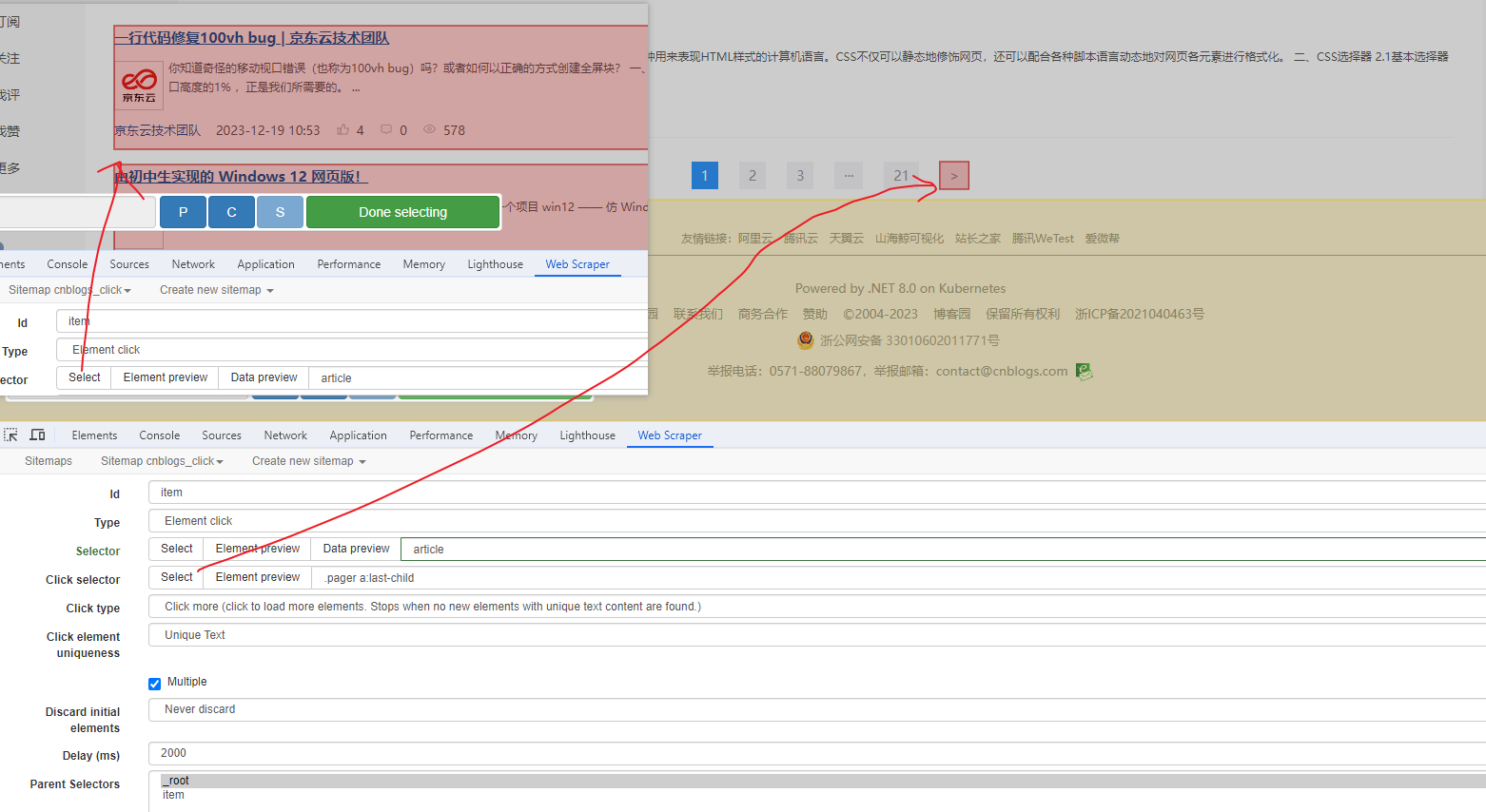 777433bd831c554f3284010f94cbc680.png分组选择器 777433bd831c554f3284010f94cbc680.png分组选择器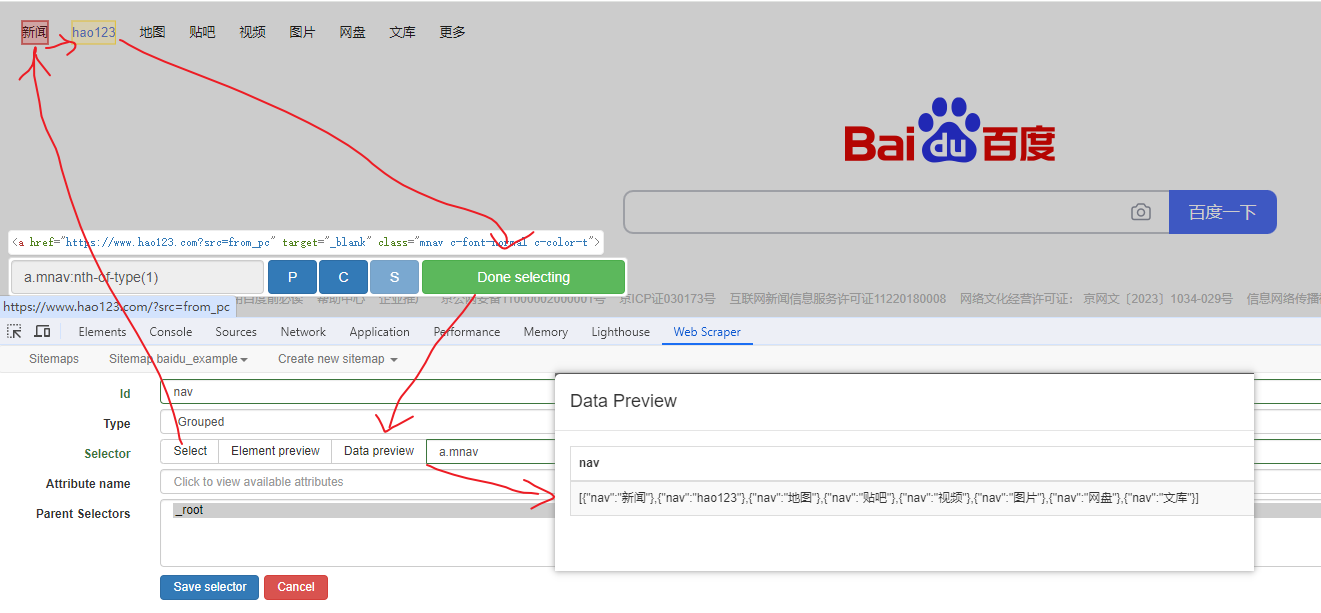 a398dcb36ecb4401ea87cb3800ff4ee2.png分页选择器 a398dcb36ecb4401ea87cb3800ff4ee2.png分页选择器分页查询数据,支持多种类型,比元素滚动选择器、元素点击选择器更强大。值得注意的是,子选择器需放在分页选择器内部。以 博客园WEB分页 为例,模拟上面元素点击选择器的效果,如下: 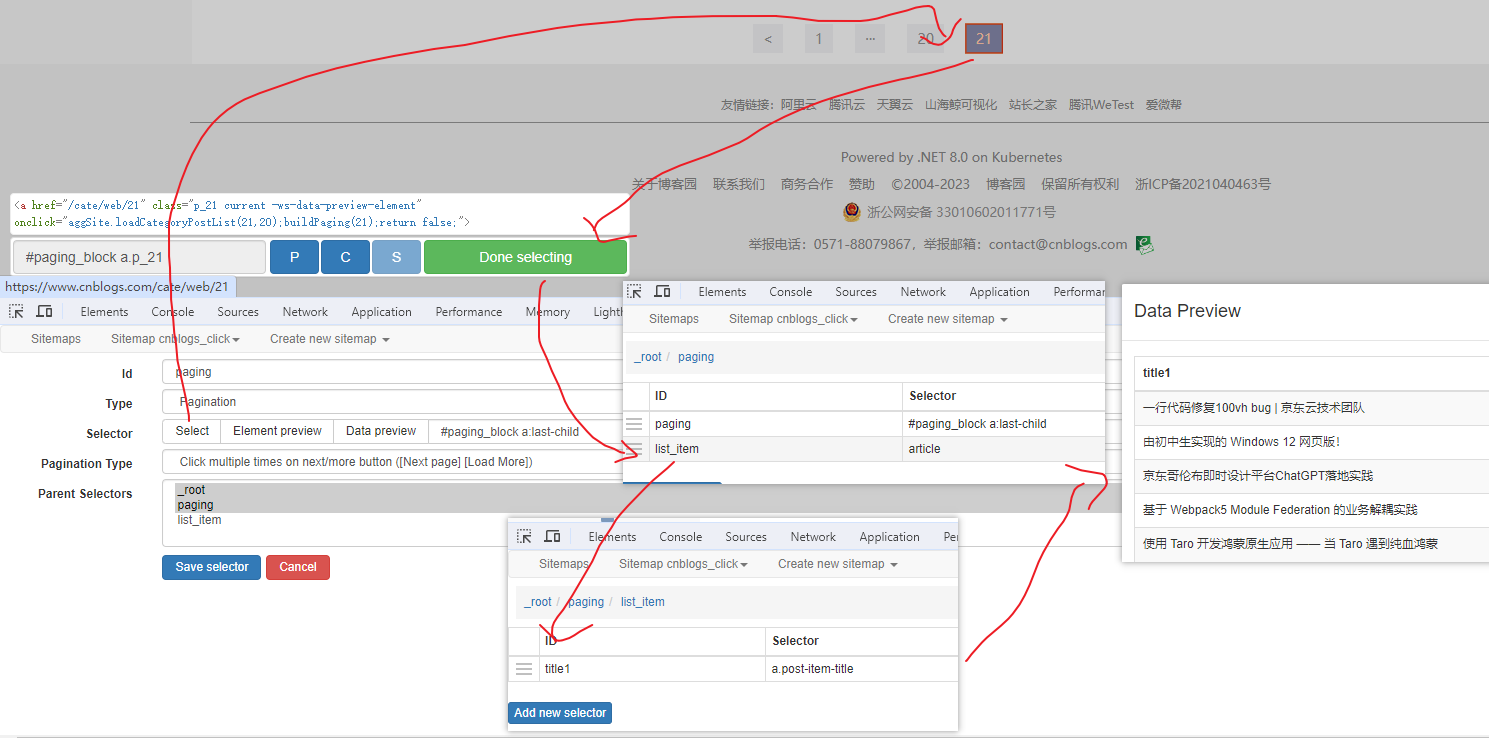 060b4c211fe4628c7a68e32229f75fff.png 060b4c211fe4628c7a68e32229f75fff.png百度首页 为例, 如下: 站点地图选择器这几个比较简单,输入 sitemap.xml 的地址即可,如下: 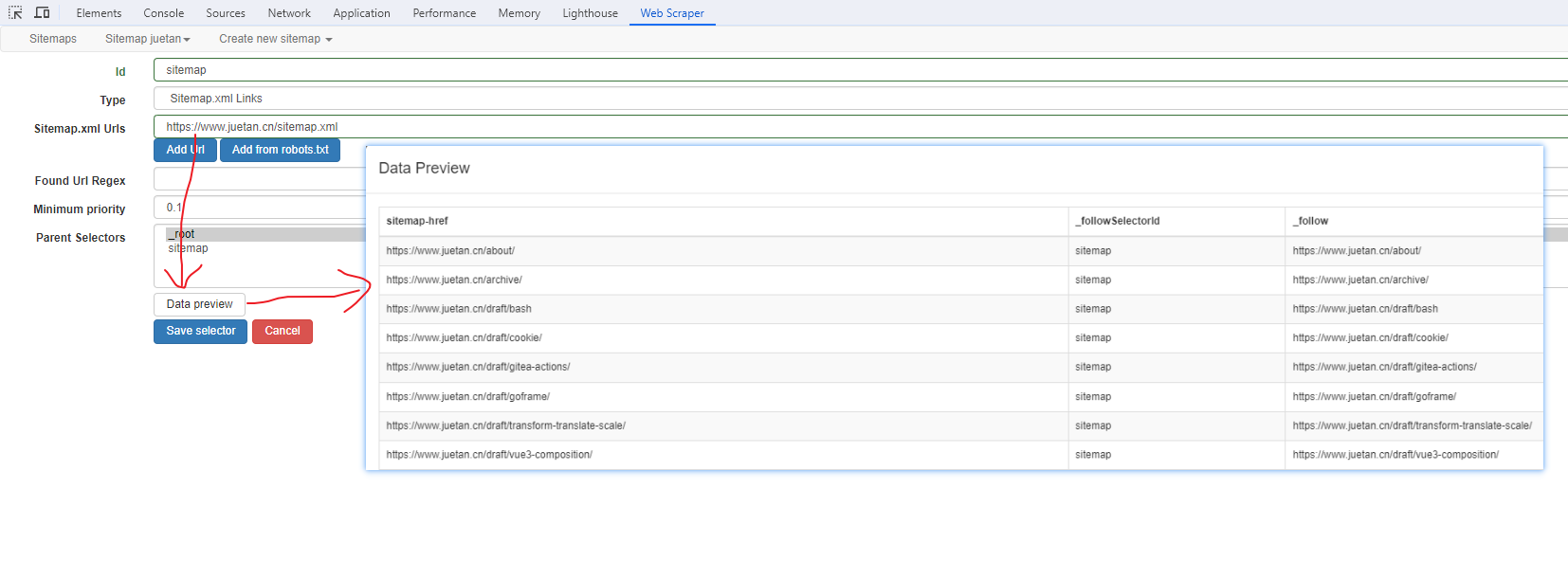 52bc7531dc072936ec5de168d57f4d8c.pngtips 52bc7531dc072936ec5de168d57f4d8c.pngtips提取元素,实际是个分组功能。例如,有个列表,每个子项都有名字、链接地址等属性,元素就是包裹这些属性的盒子,可以理解 JS 中的对象。 结语OK,以上本片的所有内容,你可以利用它去爬取知乎、百度、豆瓣等等网页上的数据。 如果本文对你有帮助,不要忘记一键三连,你的支持是我最大的动力! |
【本文地址】
今日新闻 |
推荐新闻 |