python词云 wordcloud库详细使用教程 |
您所在的位置:网站首页 › 网页中很少使用的图片格式 › python词云 wordcloud库详细使用教程 |
python词云 wordcloud库详细使用教程
|
文章目录
前言使用wordcloud生成词云的步骤API参考分词简介英文分词中文分词,jieba
matplotlib库简介实例从一段文本建立词云根据蒙版建立词云从词频建立词云从图片颜色建立词云
传入中文字体路径解决乱码问题
前言
“词云”这个概念由美国西北大学新闻学副教授、新媒体专业主任里奇·戈登(Rich Gordon)于提出,词云是一种可视化描绘单词或词语出现在文本数据中频率的方式,它主要是由随机分布在词云图的单词或词语构成,出现频率较高的单词或词语则会以较大的形式呈现出来,而频率越低的单词或词语则会以较小的形式呈现。词云主要提供了一种观察社交媒体网站上的热门话题或搜索关键字的一种方式,它可以对网络文本中出现频率较高的“关键词”予以视觉上的突出,形成“关键词云层”或“关键词渲染”,从而过滤掉大量的文本信息,使浏览网页者只要一眼扫过文本就可以领略文本的主旨。 例如:(图片来自于网络) 你也想做出这么具有视觉震撼效果的词云吗?借助python的wordcloud库便可实现。 wordcloud库不是python内置库,需要安装。windows+R,打开cmd,然后在命令行输入: pip install wordcloud等待安装完成即可。 关于wordcloud库最详细的使用教程,可参考: wordcloud官方文档 本文是在作者参考官网后,然后结合自己的示例整理出。源代码和相关资料下载资源(0积分下载): https://download.csdn.net/download/weixin_55697913/87697233 使用wordcloud生成词云的步骤读取文件,分词整理 可能会用到字符串相关函数、jieba库等。 配置对象参数,加载词云文本 创建一个WordCloud对象,使用.generate()方法加载文本。 计算词频,输出词云文件 使用to_file()方法输出到文件。或者利用其他库(如pyplot)展示图像。 生成词云时,wordcloud 默认会以空格或标点为分隔符对目标文本进行分词处理。 对于中文文本,分词处理需要由用户来完成,jieba库是常见的中文分词库。 一般步骤是先将文本分词处理,然后以空格拼接,再调用wordcloud库函数。 处理中文时还需要指定中文字体,见本文末尾传入中文字体路径解决乱码问题。 API参考最重要的一个API: class wordcloud.WordCloud(font_path=None, width=400, height=200, margin=2, ranks_only=None, prefer_horizontal=0.9, mask=None, scale=1, color_func=None, max_words=200, min_font_size=4, stopwords=None, random_state=None, background_color='black', max_font_size=None, font_step=1, mode='RGB', relative_scaling='auto', regexp=None, collocations=True, colormap=None, normalize_plurals=True, contour_width=0, contour_color='black', repeat=False, include_numbers=False, min_word_length=0, collocation_threshold=30)重要参数详解: font_path:字体路径。使用中文很可能产生乱码,需要下载专门的中文字体,然后将路径传入。width, height:画布的大小。mask:蒙版(熟悉ps的小伙伴应该很清楚),可以传入一个图像当做蒙版,这时width,height会被忽略。蒙版的纯白色部分将没有文字,其他颜色部分将有文字。min_font_size:词云最小字体的大小。max_font_size同理。max_words:最大词语的数量。stopwords:set of strings or None,出现在停用词里的词将不会出现在词云中。如果None,则使用默认的stopwords。如果使用.generate_from_frequencies方法,则会被忽略。background_color:背景颜色,可以直接用white、black等字符串。repeat:bool, default=False。是否可以重复单词。color_func:callable, default=None。可以传入一个函数或者后面提到的ImageColorGenerator,用于给词云上色。方法: 方法用法generate(text)根据给定的text产生词云,text一般是用空格或者标点符号分割的单词generate_from_text(text)跟generate(text)完全等效generate_from_frequencies(frequencies[, …])根据词频建立词云,词频越大字体越大。参数frequencies是一个字典,从单词到频率的映射fit_words(frequencies)跟generate_from_frequencies完全等效to_file(filename)将产生的词云保存至文件 class wordcloud.ImageColorGenerator(image, default_color=None)参数: image:nd-array, shape (height, width, 3)作用: 基于一张图片建立的ImageColorGenerator,可以当做WordCloud类的color_func参数,用于给词云上色。传入一张RGB图片即可,是一个numpy格式的图片。词云上的每个词的染色,是这张图片上对应的矩形区域的颜色平均值。 分词简介分词,简单来说就是将一段长句子分成一个个的词语。要生成词云肯定是需要以词语为单位的,所以我们需要提前完成分词操作。 英文分词对于英文句子,其本身就有空格和标点符号,所以很多情况下我们直接传入句子即可。例如: import wordcloud sentence='Long ago, there was a big cat in the house. He caught many mice while they were stealing food.' wc=wordcloud.WordCloud() wc.generate(sentence) wc.to_file('img1.jpg')效果展示: 对于中文句子,词与词之间没有分隔符,分词需要我们自己完成。jieba库是一个优秀的中文分词库,如果没有安装,请: pip install jieba在jieba中最常用的函数就是jieba.lcut()函数,我们传入一个句子,返回分词后的词语列表。几个最常用的函数是: 方法用法jieba.lcut(s)精确模式,词与词之间没有重合,返回一个列表类型jieba.lcut(s, cut_all=True)全模式,得到所有可能的词,返回一个列表类型jieba.lcut_for_search(s)搜索引擎模式,返回一个列表类型例如: import jieba list0=jieba.lcut('真正的勇士,敢于直面惨淡的人生,敢于正视淋漓的鲜血这是怎样的哀痛者和幸福者?') print(list0) sentence="中华人民共和国" list1=jieba.lcut(sentence) list2=jieba.lcut(sentence, cut_all=True) list3=jieba.lcut_for_search(sentence) print(list1) print(list2) print(list3) 输出: ['真正', '的', '勇士', ',', '敢于', '直面', '惨淡', '的', '人生', ',', '敢于', '正视', '淋漓', '的', '鲜血', '这是', '怎样', '的', '哀痛', '者', '和', '幸福', '者', '?'] ['中华人民共和国'] ['中华', '中华人民', '中华人民共和国', '华人', '人民', '人民共和国', '共和', '共和国'] ['中华', '华人', '人民', '共和', '共和国', '中华人民共和国'分词完成后,一般是利用空格连接分词之后的词语,然后传入wordcloud对象: list1=jieba.lcut('真正的勇士,敢于直面惨淡的人生,敢于正视淋漓的鲜血这是怎样的哀痛者和幸福者?') sentence=" ".join(list1) # 注意,需要传入中文字体路径,不然很可能出现乱码。 wc=wordcloud.WordCloud(font_path='C:\Windows\Fonts\simhei.ttf') wc.generate(sentence) wc.to_file('img1.jpg')
maplotlib是一个优秀的python绘图库,经常用在科学绘图中。二维图、三维图、折线图、柱状图、饼状图、热力图……它都能绘制。最常用到的是其子库matplotlib.pyplot。 如果未安装,请: pip install matplotlib我们可以利用matplotlib库将生成的词云方便地展示出来。但是这一步不是必须的,因为wordcloud就自带了保存至文件的方法to_file。但是涉及到多子图绘制等,就必须用到它了。 一般来说我们之间调用plt.imshow函数,将生成的wordcloud对象传入,然后调用plt.show函数将图展示出来即可,例如: import matplotlib.pyplot as plt import wordcloud import jieba list1=jieba.lcut('真正的勇士,敢于直面惨淡的人生,敢于正视淋漓的鲜血这是怎样的哀痛者和幸福者?') sentence=" ".join(list1) # 注意,需要传入中文字体路径,不然很可能出现乱码。 wc=wordcloud.WordCloud(font_path='C:\Windows\Fonts\simhei.ttf') wc.generate(sentence) # wc.to_file('img1.jpg') plt.imshow(wc) # 传入wordcloud对象 plt.axis('off') # 关闭坐标轴 plt.show() # 将图片展示出来效果: 本文会用到wordcloud库,除此之外,还会用到jieba和matplotlib。 jieba库是一个优秀的中文分词库,matplotlib是一个常用的Python 2D绘图库,其子库matplotlib.pyplot提供了多种绘图方法,这两个库不是python内置的库,需要自行安装: pip install matplotlib pip install jieba在jieba库中,常用的是jieba.lcut()函数,传入一个中文字符串,返回分词后的单词列表。 关于jieba库和matplotlib库的使用不是本文的重点内容,大家可自行在网上查阅相关资料。 下文的实例将会用到下面的库: import matplotlib.pyplot as plt import wordcloud import jieba 从一段文本建立词云从一段文本建立词云时,默认单词是以空格或者标点分开的。使用generate或generate_from_text这两种方法,完全等价。 '''从一段文本建立词云''' text='''面对世界经济复苏乏力、局部冲突和动荡频发、全球性问题加剧的外部环境, 面对我国经济发展进入新常态等一系列深刻变化,我们坚持稳中求进工作总基调,迎难而上,开拓进取, 取得了改革开放和社会主义现代化建设的历史性成就。''' # 宋体 words=jieba.lcut(text) # 使用jieba库进行中文分词 text=' '.join(words) # wordcloud 默认会以空格或标点为分隔符对目标文本进行分词处理 wd=wordcloud.WordCloud(font_path='C:\Windows\Fonts\simsun.ttc') wd.generate(text) # 生成词云 plt.imshow(wd) plt.axis("off") # 关闭坐标轴 plt.show() # 将图展示出来结果: 这部分根据可口可乐的广告建立词云(cocacola快给我打钱) 先用ps自己画一个蒙版(准确来说是抠图) 然后网上辛苦搜集了广告语: 结果: 还是可口可乐广告。使用generate_from_frequencies或者fit_words方法,完全等价。 generate_from_frequencies(frequencies: Any,max_font_size: Any | None = None) -> WordCloudfrequencies:dict from string to float,从单词到频率的映射。 '''从频率建立词云''' str1='' with open('./data/cocacola.txt','r',encoding='utf-8') as f: for line in f: str1+=line[4:] # 去掉前面四个数字年份 words=jieba.lcut(str1) # 统计词频 fre={} stopwords=['你','的','和','是','了','会','才','\n','---','!','—','----','只'] for word in words: if word not in stopwords: # 除去停用词 fre[word]=fre.get(word,0)+1 # 可选用停用词。发现fre中有大量无关的词汇, # 如'你','的','和','是','了','会','才','\n','---','!','—','----','只' # 但是需要注意,如果使用generate_from_frequencies,会忽略stopwords,所以要在传入的字典中去掉停用词 mask=plt.imread('./imgs/可口可乐.jpg') wc=wordcloud.WordCloud(font_path='C:\Windows\Fonts\simhei.ttf',mask=mask, background_color='white',stopwords=stopwords) # 这里传入stopwords其实没用,得去掉fre中的停用词 wc.generate_from_frequencies(fre) wc.to_file('./imgs/from_frequency.jpg') '''或者这样做''' # wc.fit_words(fre) # wc.to_file('./imgs/from_fit_words.jpg') '''或者不用统计,直接来''' # text=' '.join(words) # wc.generate(text) #wc.to_file('./imgs/from_gene.jpg')结果: 可见'可口可乐'出现得实在太多了,挤掉了其他字的空间,并且第二名居然是个中文逗号,。 为了让图更加“好看一些”,我们可以去掉'可口可乐'和中文逗号,: del fre[','] del fre['可口可乐'] wc=wordcloud.WordCloud(font_path='C:\Windows\Fonts\simhei.ttf',mask=mask, background_color='white') # 这里传入stopwords其实没用,得去掉fre中的停用词 wc.fit_words(fre) plt.axis('off') plt.imshow(wc)
如果又想词云保存某种形状,同时还附带上图片的颜色,可以从图片颜色建立词云。 例如,用一张王者荣耀李元芳的图片建立词云:(图片来自于网络) 效果:
wordcloud在产生中文文本词云时会出现乱码(产生的汉字是方框),如下图: '''中文字体乱码''' text='中文 字体 乱码' wc=wordcloud.WordCloud() wc.generate(text) wc.to_file('./imgs/中文字体乱码.jpg')
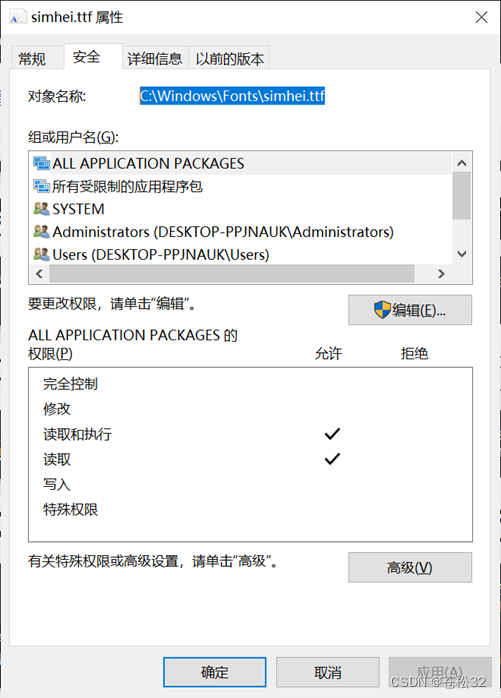
为了解决这个问题,需要传入电脑中安装的中文字体路径,font_path。 以我们常用的windows系统为例,系统中一般已经安装了中文字体,可进入C:\Windows\Fonts文件夹下,查看可用的中文字体。如下图: 例如,想要使用黑体,可对黑体右键-属性-安全,复制其路径即可: 问题成功解决: |


 需要特别注意传入中文很可能产生乱码,最好传入中文字体路径,详情见本文末尾传入中文字体路径解决乱码问题。
需要特别注意传入中文很可能产生乱码,最好传入中文字体路径,详情见本文末尾传入中文字体路径解决乱码问题。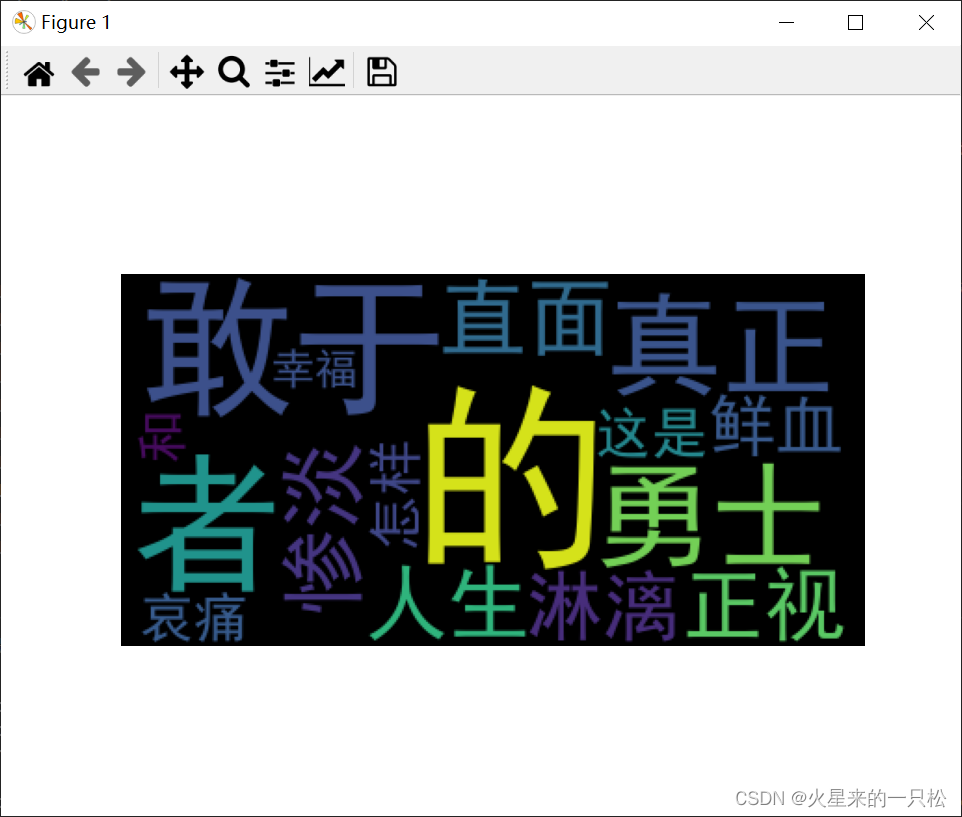 需要说明的是,可以直接将生成的词云利用to_file方法保存至文件,并不一定需要使用到matplotlib库,仅仅是个人习惯而已。
需要说明的是,可以直接将生成的词云利用to_file方法保存至文件,并不一定需要使用到matplotlib库,仅仅是个人习惯而已。


 可见统计词频后,除了一些关键词,其他词的大小明显变小了。 注意,上图中除了可口可乐,其他字都变得很小,是因为可口可乐出现的次数太多了,而此前词语出现的次数只有它的零头:
可见统计词频后,除了一些关键词,其他词的大小明显变小了。 注意,上图中除了可口可乐,其他字都变得很小,是因为可口可乐出现的次数太多了,而此前词语出现的次数只有它的零头: 这样词云终于正常了。 要想做出好看的词云,数据预处理非常重要!!!我们需要去掉标点符号、空白、停用词等可能会影响词云的无关元素。
这样词云终于正常了。 要想做出好看的词云,数据预处理非常重要!!!我们需要去掉标点符号、空白、停用词等可能会影响词云的无关元素。



【本文地址】
今日新闻 |
推荐新闻 |