TLD算法详解(一)前言 + 跟踪器与检测器的设计 |
您所在的位置:网站首页 › 网络跟踪器的用途 › TLD算法详解(一)前言 + 跟踪器与检测器的设计 |
TLD算法详解(一)前言 + 跟踪器与检测器的设计
|
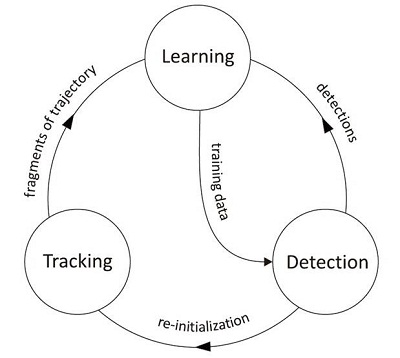
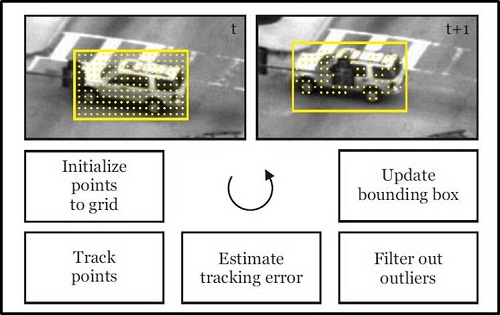
原文:http://blog.csdn.net/wood_water/article/details/9017681。本文略微做了增减等修改。 TLD是英国Surrey大学的Zdenek Kalal发表在PAMI2012年七月刊的一篇文章,主要贡献在于将跟踪与检测结合在一起,实现了工程上可应用的实时跟踪程序。而本篇文章其实是对ZK 在 2009年的paper:Online learning of robust object detectors during unstable tracking的扩展和改善。在这篇文章里作者提出了,Tracking-Modeling-Detection,而在PAMI中则修改为TLD,然而基本的思想却仍旧保持一致。TMD中的pruning和growing过程即是TLD中的P-expert与N-expert,而TMD中的Local 2bit Binary Patterns则对应TLD中的Pixel Comparison。中间的对应关系还是比较容易发现。 这篇文章是去年这个时候准备组会的时候看的,结果为了看懂这篇文章,杂七杂八又看了作者的其他五六篇文章,一直没有时间写,最近发现这个问题如此之火,所以不揣鄙陋,在此献丑,如有纰漏,欢迎各位指正。 论 文:http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6104061&tag=1个人主页:http://scholar.google.com/citations?user=u7EBngoAAAAJ&hl=enOpenTLD :https://groups.google.com/forum/?hl=zh-CN&fromgroups#!forum/opentld算法效果:http://v.youku.com/v_show/id_XMjU2MzA2MDcy.htmlcvchina :http://www.cvchina.info/2011/04/05/tracking-learning-detection/开源代码:1. Matlab官方版本 https://github.com/zk00006/OpenTLD2.其他版本可到 GitHub 上进行搜寻https://github.com/search?p=1&q=tld&ref=cmdform&type=Repositories 我将分若干部分说明一下我对tld的理解,呃,欢迎大家指正。 其一 Tracking-Learning-Detection TLD解析一 - 前言 其二 Tracking-Learning-Detection TLD解析二 - 跟踪器及检测器设计 其三 Tracking-Learning-Detection TLD解析三 - Learning学习(跟踪与检测的协调与更新) 其四 Tracking-Learning-Detection TLD解析四 - 扩展及局限 首先,介绍一下TLD的特点: 1.开源。有多种OpenTLD版本传播,作者主页有MatLab版本的源码,但是现在作者主页好像删掉了。 2.实时。实时性主要是由于使用的特征和分类器相对简单,并且实时性也仅是在QVGA (240×320) 视频流上实现。 3.仅需要一帧初始化。无须线下训练,检测与跟踪同时进行,分类器实时进行更新,综合检测和跟踪的结果输出最终结果。 4.可以解决跟踪对象失联及重入问题。跟踪效果是目前相对来说较好的state of art,可以实现长时跟踪。 5.与当今跟踪现状相比,更加注重工程实现,且效果惊艳。 6.将检测与跟踪相结合。 跟踪利用在帧与帧之间的信息,只需要初始化,可以产生平滑的路线,耗时较短,但是会产生漂移。 检测会逐帧独立的检测物体位置,不会发生偏移,但是需要线下训练,而且只能寻找已知的物体。 博客地址:http://blog.csdn.net/outstandinger/article/details/9017681 据称已经在如下场景中得到应用,而作者本人也已是TLD vIsion的老总: 公司网站:http://tldvision.com/ 相关文章: Tracking-learning-detection. Pattern Analysis and Machine Intelligence, 2012 Online learning of robust object detectors during unstable tracking. ICCV Workshops, 2009 Face-tld: Tracking-learning-detection applied to faces. ICIP, 2010 Forward-Backward Error: Automatic Detection of Tracking Failures. ICPR, 2010 P-N Learning: Bootstrapping Binary Classifiers by Structural Constraints. CVPR, 2010 原文:http://blog.csdn.net/wood_water/article/details/9019505 TLD论文中指出,单靠跟踪或单靠检测都无法完成现实的任务,而TLD的任务即在于结合两者的优势。 跟踪与检测的结合点即在于Learning学习过程。图示如下: 论文中将整个方案分为三部分,检测,跟踪,及学习。学习将综合检测与跟踪的结果输出,输出的结果可以作为检测子的训练数据,也可以作为对跟踪器重新初始化。 下面我们具体讲解一下跟踪子与检测子的实现方法。这也是TLD中主要的两部分,下一篇我将介绍一下我对学习过程的理解。 博客地址:http://blog.csdn.net/outstandinger/article/details/9019505 一,跟踪器 1,综述跟踪器的实现主要基于作者的论文《Forward-Backward Error: Automatic Detection of Tracking Failures》。 该论文基于改进了基于Lucas-Kanade tracker光流的跟踪的方法,提出一种所谓的中指流(Median Flow)跟踪方法,这也是应用于TLD之中的跟踪器。 该跟踪器将在帧与帧之间估计物体运动,利用偏移和尺度的变化中值对整体效果进行更新。 具体框图如下:
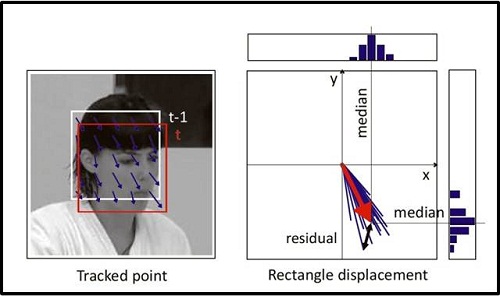
结合上图,在第 t 帧与 t+1 帧 之间的运行情况,我们在第 t 帧中初始化跟踪点框,然后利用经典的Lucas-Kanade tracker对各点进行跟踪,对跟踪得到的点进行错误估计(具体的错误估计方法下面介绍),去除跟踪效果不好的点,利用剩余的点对下一帧的跟踪结果进行更新(更新方法见下)。 2.错误估计具体的错误估计准则,则依据Forward-Backward Error(FB,前后向错误) 及 Normalized Correlation Coefficient (NCC,归一化相关系数)。
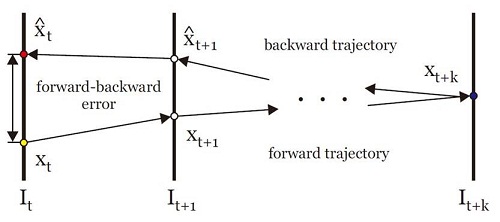
所谓的FB错误即如上图所示,我们在估计第 t 帧与 t+k 帧之间的错误时,首先由第 t 帧出发跟踪某点到 t+k 帧,在得到的 t+k 帧 再往前反跟踪回放至第 t 帧,利用回溯点与原点之间的欧氏距离作为前后向错误。当然实际中是逐帧比较,也只是计算 t 与 t+1 帧之间的情况。 而所谓的归一化相关参数则表示,其中f1,f2表示两个特征块。 对结果的输出将综合所有剩余置信度较高的点的偏移情况,利用剩余的点来估计目标的移动情况。利用每个点空间维度移动的中值作为目标的移动情况。然后对于每一个 点,都会计算其与前一点移动情况的比率,以各个点比率的中值作为当前框图相对前一框图scale幅度的变化。然后更新当前框图。至此,则跟踪器各部分介绍完毕,具体图示如下:
如上图所示,以 di 代表像素的位移,以 dm 表示目标的位移中值,如果 余量 residual = |di - dm| > 10 ,则认为目标移动过快或者被遮挡而未跟踪到结果。 二,检测器设计 1.综述 检测器主要基于简化的随机森林的方法实现。 检测器采用滑动窗(sliding window)的方法在图像中寻找目标,利用级联分类器输出结果,级联分类器包含三部分,方差比较,组合分类器及最近邻分类。 滑动窗的扫描策略为,每次尺度变化1.2,水平和垂直位移 分别为宽度和高度的10%,最小框图大小为 20 pixels。对QVGA图像将产生50k个滑动结果。 每一部分都将筛选出更加可能的结果输入下一部分进行继续甄别,从而加快运行速度。 具体示意如下: 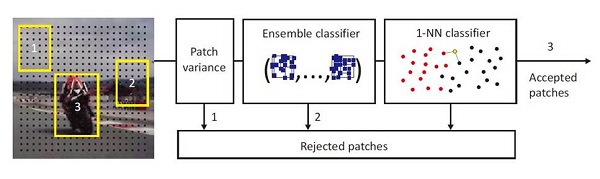 2.方差比较
方差比较,顾名思义,将对滑框图像与目标图像计算灰度值方差,将结果低于原图50%的结果均抛弃,本阶段可以去除大部分干扰的背景,如上图中的1和2。具方差可由:E(p^2 ) −(E(p))^2 计算。期望可以使用积分图实现。
3.组合分类器
(1)实现
组合分类器基于随机森林方式实现,由n个基分类器组成。
据笔者理解,所谓的随机森林只有一层实现,所谓的n个基分类器是由n棵只有一层的树组成,n棵树实际上是n个13对位置,输出结果为n个后验概率。
论文中说是13对像素比较,但是图中只有十个,于是俺发了一封信给作者问他图是不是画错了,伊木有理我。
具体运行示意如下:
2.方差比较
方差比较,顾名思义,将对滑框图像与目标图像计算灰度值方差,将结果低于原图50%的结果均抛弃,本阶段可以去除大部分干扰的背景,如上图中的1和2。具方差可由:E(p^2 ) −(E(p))^2 计算。期望可以使用积分图实现。
3.组合分类器
(1)实现
组合分类器基于随机森林方式实现,由n个基分类器组成。
据笔者理解,所谓的随机森林只有一层实现,所谓的n个基分类器是由n棵只有一层的树组成,n棵树实际上是n个13对位置,输出结果为n个后验概率。
论文中说是13对像素比较,但是图中只有十个,于是俺发了一封信给作者问他图是不是画错了,伊木有理我。
具体运行示意如下:
 首先对于输入图像进行平滑滤波处理降噪,而后在图像内部生成13个像素比较对,最终的像素比较结果输出为一个13位的二进制像素编码。该二进制编码将映射到某后验概率。依据各基分类器输出的后验概率结果平均,如果其得分大于0.5,将送入下一步,否则将被舍弃。
(2)初始化
上文提到的后验概率结果由初始化时实现,并在运行过程中更新。
在工程起始阶段我们仅输入目标位置,仅有一幅图像,在初始阶段,在选中位置附近,利用滑框选择10个与目标位置最近的位置作为输入目标的扩展,并对其进行扭曲加噪处理(包含仿射变换,加噪声等),最终形成200个正样本。而负样本由框附近获得,获得的负样本不进行扭曲处理。
所有的基分类器初始化时均设置为0,而后将正负样本送入分类其中计算,每个节点均是13位二进制编码,最终每个节点均会停留若干正样本和负样本,而最终的节点后验概率由 Pi(y|x) =#p/(#p+#n) 获得,#p 代表正样本数目, #n 代表负样本数目。
4.最近邻分类器
首先对于输入图像进行平滑滤波处理降噪,而后在图像内部生成13个像素比较对,最终的像素比较结果输出为一个13位的二进制像素编码。该二进制编码将映射到某后验概率。依据各基分类器输出的后验概率结果平均,如果其得分大于0.5,将送入下一步,否则将被舍弃。
(2)初始化
上文提到的后验概率结果由初始化时实现,并在运行过程中更新。
在工程起始阶段我们仅输入目标位置,仅有一幅图像,在初始阶段,在选中位置附近,利用滑框选择10个与目标位置最近的位置作为输入目标的扩展,并对其进行扭曲加噪处理(包含仿射变换,加噪声等),最终形成200个正样本。而负样本由框附近获得,获得的负样本不进行扭曲处理。
所有的基分类器初始化时均设置为0,而后将正负样本送入分类其中计算,每个节点均是13位二进制编码,最终每个节点均会停留若干正样本和负样本,而最终的节点后验概率由 Pi(y|x) =#p/(#p+#n) 获得,#p 代表正样本数目, #n 代表负样本数目。
4.最近邻分类器
组合分类器的输出结果再经过最近邻分类器输出检测子的结果。 相关文章:Tracking-learning-detection. Pattern Analysis and Machine Intelligence, 2012Online learning of robust object detectors during unstable tracking. ICCV Workshops, 2009 Face-tld: Tracking-learning-detection applied to faces. ICIP, 2010Forward-Backward Error: Automatic Detection of Tracking Failures. ICPR, 2010P-N Learning: Bootstrapping Binary Classifiers by Structural Constraints. CVPR, 2010 |

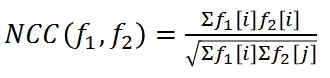
【本文地址】
今日新闻 |
推荐新闻 |